【PyTorch】动手学深度学习-梳理与笔记小结|深度学习计算
动手学深度学习-梳理与笔记小结
Refs:
参考书籍-动手学深度学习
课程主页与资源汇总
层和块
【小结】
- 一个块可以由许多块组成,也可以由许多层组成;
- 块中可以包含自定义的代码;
- 块负责大量的内部处理,包括参数初始化和梯度反向传播;
- 层和块的顺序连接由Sequential块来处理
Tips
①不管是一个单一的神经元,还是一个网络层,或者是一个模型,其都含有三个结构特性——
- 接收一些输入;
- 生成相应的输出;
- 结构由一组可调整的参数来控制
②研究比“单个层”大且比“整个模型”小的组件更有价值,如ResNet-152的数百层就是由层组(groups of layers)的重复模式来组成的;
为此我们提出神经网络块的定义,它对单个神经元、网络层和整个模型有了统一的描述,并且可以通过递归组合的形式搭建出更大的组件。
③在继承
nn.Module类对网络块进行定义的时候,除非是定义一个新的运算符,否则不需要额外考虑参数初始化和反向传播(系统会自动生成)
Codes&Homework
关于顺序块
class Mysequential(nn.Module):
①在重写__init__()初始化方法时,每一个模块都要有一个有序字典的属性self._modules(),这是因为在初始化参数的时候系统知道在有序字典中查找需要初始化参数的模块;
②当顺序块的前向传播函数被调用时,每个被添加的块按照其被添加的顺序来执行;
③顺序块的实现使得我们可以对已有的网络进行组建形成新的结构,而不需要定义新的类
关于控制代码和网络定义的组合:
①通过在初始化函数中定义常量权值,实现固定的运算,self.rand_weight = torch.rand((20,20),requires_grad = False)
②若在初始化函数中只实例化了一个网络层,但是在前向传播函数多次进行了调用,则是对网络结构进行了复用,即共享参数;
在前向传播函数中可以按照自定义的运算过程和逻辑加入一些控制语句,如循环块或条件判断块
#coding:gbk
import torch
from torch import nn
from torch.nn import functional as F
#EX1:生成一个网络,输入维度为20,其中包含一个具有256个单元和ReLU激活函数的全连接隐层,然后是一个具有10个隐层单元且不带有激活函数的全连接输出层
net = nn.Sequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
X = torch.rand(2,20)
print(X)
print(net(X))
#EX2:从零开始编写一个多层感知机的网络块
#含有256个隐层和一个10维的输出层
class MLP(nn.Module):
def __init__(self):
#调用父类Module的构造函数来执行必要的初始化
super().__init__()
self.hidden = nn.Linear(20,256)
self.out = nn.Linear(256,10)
#定义模型的前向传播,根据输入返回模型的输出
def forward(self,x):
return self.out(F.relu(self.hidden(x)))
net2 = MLP()
print(net2(X))
#EX3:实例化或自定义Sequential类实现顺序块的定义
class MySequential(nn.Module):
#需定义的函数1:将块逐个追加到列表中
def __init__(self,*args):
super().__init__()
for idx, module in enumerate(args):
#上面的module是Module子类的一个实例
self._modules[str(idx)] = module
#上面_modules是一个OrderedDict
#需定义的函数2:前向传播函数,将输入按照追加块的顺序传递给块组成的“链条
def forward(self,x):
#OrderedDict的结构保证了可以按照成员添加的顺序遍历子网络
for block in self._modules.values():
x = block(x)
return x
net3 = MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
print(net3(X))
#Homework
##1.将MySequential中存储块的方式更改为Python列表
class MySequential2(nn.Module):
def __init__(self,*args):
super().__init__()
self.modules = []
for m in args:
self.modules.append(m)
def forward(self,x):
for m in self.modules:
x = m(x)
return x
net4 = MySequential2(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
print("new",net4(X))
##2.平行块构造——以两个块为参数并返回其前向传播中的串联输出
class ParallelBlock(nn.Module):
def __init__(self,*args):
super().__init__()
for idx, module in enumerate(args):
self._modules[str(idx)] = module
def forward(self,x):
res = []
#print(type(self._modules))
for block in self._modules.values():
res.append(block(x))
return torch.cat((res[0],res[1]),1)
net5 = ParallelBlock(nn.Linear(20,20),nn.Linear(20,56))
print("parallel",net5(X).shape,net5(X))
##3.连接同一网络的多个实例,实现一个生成同一网络多个实例的函数,并基于此构建更大的网络
class SuperNet(nn.Module):
def __init__(self,unit,times):
super().__init__()
self.block = unit
self.times = times
def forward(self,x):
for i in range(self.times):
x = self.block(x)
return x
net6 = SuperNet(nn.Linear(20,20),3)
print("Super",net6(X).shape,net6(X))
class SuperNet(nn.Module):
def __init__(self,unit,times):
super().__init__()
self.block = unit
self.times = times
self.blocks = []
for i in range(self.times):
self.blocks.append(unit)
def forward(self,x):
for i in range(self.times):
x = self.blocks[i](x)
return x
net7 = SuperNet(nn.Linear(20,20),3)
print("Super+",net7(X).shape,net7(X))
print(net6.parameters)
print(net7.parameters)
【Homework】
T1:在对顺序块(Sequential)进行实现时使用列表而非内置的_modules()的区别在于——
使用_Modules使其他Pytorch函数/方法能够自动查找添加的网络层,也就是对这些网络层进行了注册。例如,如果要打印网络的参数,则可以简单地调用State_dicts(),但如果采用列表,则equation_dict等方法不起作用
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net.state_dicts()
T2:要想实现两个网络输出的串联,则在dim = 1的维度上对两个网络的输出结果进行torch.cat操作;
T3:要对同一个网络结构多次进行实例化,那么在初始化init函数中就不能只是定义一个self.block结构写死再多次调用,那样本质上是对同一网络实例进行多次调用。
参数管理
Tips
【参数访问】
①使用Sequential定义的网络块好比是一个列表,可以通过下标索引来访问网络的不同层,e.g.sequential_net[idx].state_dict()
②参数是一个复合对象类,包含值、梯度和其他额外信息;
③因为网络块可以分层嵌套,所以我们也可以使用多级下标索引来逐层访问网络块中的每一个子层的参数和状态
【参数初始化】
PyTorch官方文档中包含若干内置的初始化方法
①nn.weight.data或者nn.bias.data都是可以直接进行运算或者修改的tensor,在自定义的init方法中可以根据自己的需要对参数进行一定的修改和运算来达到目标的初始化方法;
②参数初始化方法↔梯度数值稳定性↔网络收敛速度↔非线性激活函数的选择
Codes&Homework
一些练习和示例
import torch
from torch import nn
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1))
X = torch.rand(2,4)
## 参数访问(逐一访问)
print('输出参数对象:',net[2].state_dict())
print('输出参数数值:',net[2].bias.data)
print('输出参数的梯度:',net[2].weight.grad)
##通过键值对来访问某一层或者所有层的网络参数(整体访问)
print(*[(name,param.shape) for name, param in net[0].named_parameters()])
print(*[(name,param.shape) for name, param in net.named_parameters()])
#因为state_dict是以字典形式保存着module中的所有状态,所以可以通过键来访问相应的参数值
print(net.state_dict()['2.bias'].data)
#可以往nn.Sequential中传入一系列网络块/生成网络块的函数/有关网络块的有序字典
def block1():
return nn.Sequential(
nn.Linear(4,8),nn.ReLU(),
nn.Linear(8,4),nn.ReLU()
)
def block2():
net = nn.Sequential()
for i in range(4):
net.add_module(f'block{i}',block1())
return net
net2 = nn.Sequential(block2(),nn.Linear(4,1))
print('网络结构:',net2,'运算结果:',net2(X))
## 参数初始化
# 设置初始化方法并应用到指定的网络中
def init_normal(layer):
if type(layer) == nn.Linear:
nn.init.normal_(layer.weight,mean = 0,std = 0.01)
nn.init.zeros_(layer.bias)
net.apply(init_normal)
print('手动初始化参数后网络net第一层的参数为:',net[0].weight.data,net[0].bias.data)
#其他初始化方法:nn.init.constant_(tensor,value)
#nn.init.zeros_(tensor) nn.init.xavier_uniform_(tensor)
## 参数共享
shared = nn.Linear(8,8)#使用一个单独的对象指向需要被共享的网络层,方便后续的引用
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),shared,
nn.ReLU(),shared,nn.ReLU(),nn.Linear(8,1))
print('检查第三层和第五层的参数是否是同一个对象:',net[2].weight.data == net[4].weight.data)
课后练习
T4:共享参数的好处
参数共享最常出现在卷积神经网络中,因为[卷积]和[卷积核]概念的提出最早就是为了解决全连接层参数过多、网络体量过大的问题;当然在自定义和自己设计的网络结构中,也可以通过叠加同一个实例化网络层来达到参数共享的目的——
①有效减少网络参数数量,精简网络模型,抑制过拟合;
②对于网络时空变化中的相同模式可以进行有效提取和识别;
③参数共享在网络设计中往往意味着结构的对称,有助于潜层空间的共享;
④因为相同参数往往是为了同一目标或任务而设计,因此可以将背后的网络运算过程很好地在不同时空进行泛化(时间对应于1D-CONV或者RNN,空间对应着CNN)
T1:net.state_dict()这个方法传回的是有关网络参数的键值对,字典的键值是由用户在对网络进行自定义的__init__()方法中确立的;
T3:共享参数MLP进行训练时对参数进行监督和可视化:定义了一个网络对MNIST手写数据进行一个分类器的训练,对不冻结共享层的参数、冻结第一个共享层的参数和冻结第二个共享层的参数这三种情况分别进行可视化——
①不冻结共享层的梯度传播
②冻结第一个共享层的参数
③冻结第二个共享层的参数
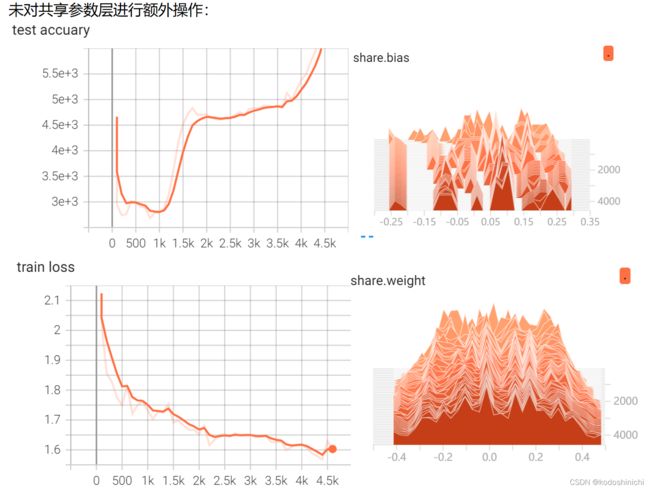
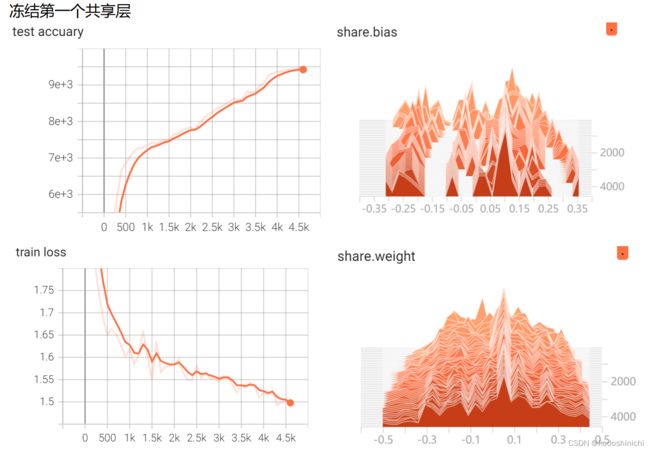
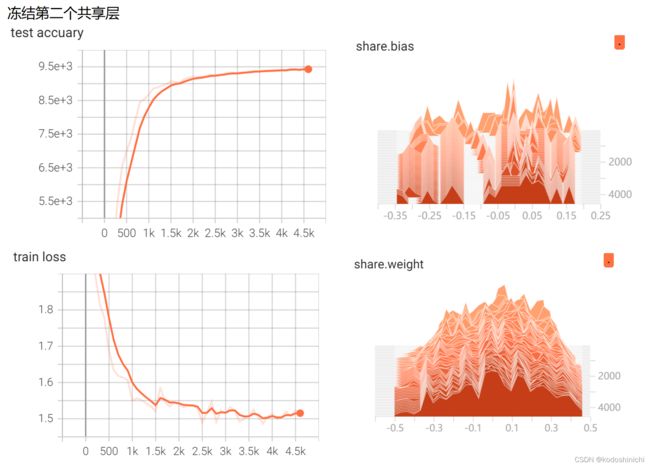
#T1:对MLP结构中各层参数进行打印输出
class MLP(nn.Module):
# 用模型参数声明层。这里,我们声明两个全连接的层
def __init__(self):
# 调用MLP的父类Module的构造函数来执行必要的初始化。
# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)
super().__init__()
self.hidden = nn.Linear(20, 256) # 隐藏层
self.out = nn.Linear(256, 10) # 输出层
# 定义模型的前向传播,即如何根据输入X返回所需的模型输出
def forward(self, X):
# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。
return self.out(F.relu(self.hidden(X)))
X = torch.rand(2,20)
net = MLP()
#逐层对参数进行访问
print('隐层的权值:',net.state_dict()['hidden.weight'],'隐层的偏置:',net.state_dict()['hidden.bias'])
print('输出层的权值:',net.state_dict()['out.weight'],'输出层的偏置',net.state_dict()['out.bias'])
#批量对参数进行访问
print([(name,param) for name,param in net.named_parameters()])
# T3:构建包含共享参数层的多层感知机,并观察其训练过程中各层的参数和梯度的变化
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
from visdom import Visdom
from torch.utils.tensorboard import SummaryWriter
import numpy as np
class SharedMLP(nn.Module):#模型构建
def __init__(self):
super(SharedMLP,self).__init__()
self.share = nn.Linear(16,16)
self.model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 16),
nn.ReLU(),
self.share,
nn.ReLU(),
self.share,
nn.ReLU(),
nn.Linear(16, 10),
nn.Sigmoid()
)
self.model[8].requires_grad = False#冻结第二个共享层的参数
def forward(self,x):
x = self.model(x)
return x
#数据准备
mnist_train = datasets.MNIST('D:\\coding\pycharm\\动手学-DL\\AE_VAE_MNSIT\\DATA\\train',train = True,transform=transforms.Compose([transforms.ToTensor()]),download=False)
mnist_train = DataLoader(mnist_train,batch_size=128,shuffle=True)
mnist_test = datasets.MNIST('D:\\coding\pycharm\\动手学-DL\\AE_VAE_MNSIT\\DATA\\test',train=False,transform=transforms.Compose([transforms.ToTensor()]),download=False)
mnist_test = DataLoader(mnist_test,batch_size=128,shuffle=False)
batch_sz = 64
logger = SummaryWriter(log_dir="data/log")
# 获取优化器和损失函数
optimizer = torch.optim.Adam(filter(lambda p : p.requires_grad, net.parameters()), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # 记录的步数间隔
for epoch in range(10):
print("epoch:", epoch)
# 每一轮都遍历一遍数据加载器
for step, (x, y) in enumerate(mnist_train):
# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络
x = x.view(-1,28*28)
predict = net(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # 清空梯度(可以不写)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络
global_iter_num = epoch * len(mnist_train) + step + 1 # 计算当前是从训练开始时的第几步(全局迭代次数)
if global_iter_num % log_step_interval == 0:
# 控制台输出一下
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
# 添加的第一条日志:损失函数-全局迭代次数
logger.add_scalar("train loss", loss.item(), global_step=global_iter_num)
# 在测试集上预测并计算正确率
test_loss = 0
correct = 0
for data, target in mnist_test:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.to(device)
logits = net(data)
test_loss += loss_func(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
# 添加第二条日志:正确率-全局迭代次数
logger.add_scalar("test accuary", correct, global_step=global_iter_num)
# 添加第三条日志:这个batch下的128张图像
img = torchvision.utils.make_grid(x, nrow=12)
logger.add_image("train image sample", img, global_step=global_iter_num)
# 添加第三条日志:网络中的参数分布直方图
for name, param in net.named_parameters():
logger.add_histogram(name, param.data.numpy(), global_step=global_iter_num)
延后初始化
Tips
【延后初始化】
网络框架直到数据第一次通过模型传递时,才会动态地推断出每个层的大小——
①使得在定义网络架构的时候可以不指定输入维度;
②添加网络层时也可以不指定前一层的输出维度;
③在初始化参数的时候可以不事先知道模型应该包含多少参数
Codes&Homework
PyTorch官方文档-LAZYLINEAR
torch.nn.Linear的模块中输入维度是明确指定的,但是在LazyLinear这个模块,它的权重和偏置项都是torch.nn.UninitializedParameter的类别,它们只有在第一次对forward调用完成后,这个模块就会转变成一个常规的torch.nn.Linear的模块,其中它的输入维度是由input.shape[-1]的数值来确定的。
import torch
from torch import nn
net = nn.Sequential(nn.LazyLinear(256), nn.ReLU(),nn.Linear(256,10))
print(net)
print([net[i].state_dict() for i in range(len(net))])
low = torch.finfo(torch.float32).min/10
high = torch.finfo(torch.float32).max/10
X = torch.zeros([2,20],dtype=torch.float32).uniform_(low, high)
net(X)
print(net)
print([net[i].state_dict() for i in range(len(net))])
自定义层
Tips
- 可以通过基本层类的设计自定义层——可以灵活地得到与库中现有的神经网络结构和行为不同的新结构;
- 可以在任意环境和网络架构中调用定义完成的自定义层;
- 可以通过内置函数(提供基本的管理功能:管理访问、初始化、共享、保存和加载模型参数)对自定义层中的局部参数进行创建——即不需要为每个自定义层编写自定义的序列化程序
Codes&Homework
PyTorch官方文档-LAZYLINEAR
torch.nn.Linear的模块中输入维度是明确指定的,但是在LazyLinear这个模块,它的权重和偏置项都是torch.nn.UninitializedParameter的类别,它们只有在第一次对forward调用完成后,这个模块就会转变成一个常规的torch.nn.Linear的模块,其中它的输入维度是由input.shape[-1]的数值来确定的。
import torch
import torch.nn.functional as F
from torch import nn
#不带参数的层
class CentredLayer(nn.Module):#实现对输入数据的去中心化(即从输入中减去均值)
def __init__(self):
super(CentredLayer,self).__init__()
def forward(self,x):
return x-x.mean()
net1 = CentredLayer()
print(net1(torch.FloatTensor([1,2,3,4,5])))
net2 = nn.Sequential(nn.Linear(8,128),CentredLayer())
print(net2(torch.rand(4,8)).mean())#通过检查经过网络输出的数据均值情况判断网络是否正常工作
#带参数的层
class MyLinear(nn.Module):
def __init__(self,in_units,units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units,units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self,x):
linear = torch.matmul(x,self.weight.data)+self.bias.data
return F.relu(linear)
net3 = MyLinear(5,3)
#查看自定义层的参数
print(net3.weight)
#使用自定义的网络层进行前向传播
print(net3(torch.rand(2,5)))
#使用自定义层灵活构建模型
net4 = nn.Sequential(MyLinear(64,8),MyLinear(8,1))
print(net4(torch.rand(2,64)))
#T1:设计层——接受输入并计算张量降维的层
class RD(nn.Module):
def __init__(self,k,i,j):#k就是待降低至的维度
super(RD,self).__init__()
self.weight = nn.Parameter(torch.rand(k,i,j))
def forward(self,x):#默认x输入的是一个列向量
x_matrix = torch.matmul(x,torch.transpose(inp,1,2))#[b,i,j]
#print(x_matrix.shape)
batch = []
for d in range(x_matrix.shape[0]):#分批取batch中的一组数据出来进行运算
batch.append(torch.sum(torch.mul(x_matrix[d],self.weight.data),dim = [1,2]))
#因为数据随机初始化时选择batch为2,因此这里直接取列表中两个元素出来即可
print(batch[0])
return torch.cat((batch[0].unsqueeze(0),batch[1].unsqueeze(0)),dim = 0)
inp = torch.ones(2,10,1)
net5 = RD(5,10,10)
print('RD网络的结构',net5)
print('降维输出的结果:',net5(inp))
#T2:设计一个返回输入数据的傅里叶系数前半部分的层
class HalfFFT(nn.Module):
def __init__(self):
super(HalfFFT,self).__init__()
def forward(self,x):
x_fft = torch.fft.fft(x)
return x_fft[:, :round(x.shape[1]/2)]
net6 = HalfFFT()
t = torch.tensor(list(range(-10,10,1))).float()
print('FFT系数前半部分输出结果:',net6(torch.cos(t).unsqueeze(0)))
读写文件
Tips
【小结】
- 可以通过使用
save和load函数对张量对象的文件进行读写操作;- 通过参数字典可以保存和加载网络的全部参数;
- 若要对网络架构进行保存,需要使用代码生成架构,然后从磁盘加载参数——深度学习框架中提供的内置函数只能保存模型的参数而非保存整个模型,因为模型本身可以包含任意代码,所以模型本身难以序列化。
【Points】
- 因为可以写入或读取从字符串映射到张量的字典,这个对象模式与模型的参数字典很类似,因此可以同样方便地读取或写入模型中的所有权重。
Codes&Homework
T1:即使不需要对训练好的模型进行不同设备的部署,存储模型参数的好处——
①防止断电或硬件故障导致训练结果丢失的情况;
②有利于后续对不同阶段的模型性能进行评测分析,从而保存最优模型的参数,后续方便由此构建出最新模型;
③存储模型参数就能够为重构模型提供依据,且消耗的存储资源更少。
T2:只对网络的一部分进行复用并将其合并到不同的网络架构中——
①如果是基于nn.Sequential或者nn.Modulelist构建的网络,可以直接通过索引访问到某一特定层,从而保存这一层的模型;
②如果是一般化定义的网络结构,可以通过参数字典通过键值对来访问某一特定层的参数。
Ref:pytorch提取神经网络模型层结构和参数初始化
T3:若需要同时保存网络架构和参数——
- 使用
torch.save(model,PATH)即可以同时对模型和参数进行保存,模型文件采取.pt或者.pth的后缀名;- 使用这种方式保存的模型是基于Python的
Pickle模块来操作,这使得序列化的模型数据是和特定的类别进行绑定的,而且使用特定的目录结构才能正常读取使用模型——因为Pickle模块在保存模型的时候没有保存数据本身,而是存储了包含这个类文件的路径,记载模型时同样会使用这个路径。- 因此当在别的工程文件或者重构该模型时路径不匹配时都会出现报错。
Ref:torch文档-Save/Load
import torch
from torch import nn
from torch.nn import functional as F
#对单个张量对象(张量、张量列表、张量字典)进行保存和加载
x = torch.arange(4)
torch.save(x,'x-file')
x_dup = torch.load('x-file')
print(x_dup)
y = torch.zeros(5)
torch.save([x,y],'xy-file')
tensorl = torch.load('xy-file')
print(tensorl,tensorl[0],tensorl[1])
tensordic = {'x':x,'y':y}
torch.save(tensordic,'dic-file')
print(torch.load('dic-file'))
#保存和加载模型参数
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20,256)
self.output = nn.Linear(256,10)
def forward(self,x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
torch.save(net.state_dict(),'mlp.params')#保存模型的参数
net_clone = MLP()
net_clone.load_state_dict(torch.load('mlp.params'))#重新实例化一个模型并将保存的模型参数读进去
inp = torch.randn((2,20))
print('net输出结果',net(inp))
print('net_clone输出结果',net_clone(inp))
#----------------Homework-----------------------------------
#T2 值复用网络的部分层参数
#构建一个输入层的参数和MLP网络相同的NewMLP网络
class NewMLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = next(iter(MLP().children()))
self.model = nn.Sequential(nn.Linear(256,128),
nn.ReLU(),nn.Linear(128,10) )
# print(type(next(iter(MLP().children()))))
# self.model.add_module('hidden1',next(iter(MLP().children())))
# self.model.add_module('hidden2',nn.Linear(256,128))
# self.model.add_module('output',nn.Linear(128,10))
def forward(self,x):
x = F.relu(self.hidden1(x))
return self.model(x)
net2 = NewMLP()
all_dic = torch.load('mlp.params')#读取所有的参数字典
weight_need = {'weight':all_dic['hidden.weight'],'bias':all_dic['hidden.bias']}
torch.save(weight_need,'hidden.params')#将所需的那一层参数单独保存成一个参数文件
net2.hidden1.load_state_dict(torch.load('hidden.params'))
print('net中隐层参数:',net.state_dict()['hidden.weight'])
print('net2中隐层参数:',net2.hidden1.state_dict()['weight'])
GPU
Tips
①不管是使用CPU还是GPU,深度学习框架要求计算的所有输入数据和参数都在同一个设备上;
②若将一个变量移动到同一设备上,则系统会直接返回这个设备上的变量而不会进行复制或分配新内存;
③设备之间的数据传输比单个设备上的计算操作要慢得多,因此我们要尽量避免数据拷贝操作以及多个小操作;且额外的设备之间的传输开销受制于全局解释锁,从而使得所有的GPU都会阻塞。