Python面试题整理-牛客网
1、[单选题]关于Python内存管理,下列说法错误的是
A. 变量不必事先声明
B. 变量无须先创建和赋值而直接使用
C. 变量无须指定类型
D. 可以使用del释放资源
解析1:B
Python 是弱类型脚本语言,变量就是变量,没有特定类型,因此不需要声明。
但每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
用 del 语句可以释放已创建的变量(已占用的资源)。
解析2:
1.变量无需事先声明
2.变量无需指定类型
3.程序员不用关心内存管理
4.变量名会被“回收”
5.del语句能够直接释放资源
6.变量只有被创建和赋值后才能被使用
2、[单选题]执行下列选项的程序,会抛出异常的是()
A.
a = 1
b = 2
a,b = b,a
B.
a,*b,c = range(5)
print(a,b,c)
C.
lis = ['1','2']
a,b = list(map(int,lis))
print(a,b)
D.
tup = (1,(2,3))
a,b,c = tup
print(a,b,c)
解析:D
1、*args和**kwargs 这两个是python中方法的可变参数。
2、*args表示任何多个无名参数,它是一个tuple;
3、**kwargs表示关键字参数,它是一个dict。并且同时使用*args和**kwargs时,必须*args参数列要在**kwargs前,像foo(a=1, b='2', c=3, a', 1, None, )
这样调用的话,会提示语法错误“SyntaxError: non-keyword arg after keyword arg”。
4、当方法的参数不确定时,可以使用*args 和**kwargs
5、D的正确写法是a,(b,c)=tup
3、[单选题]以下程序输出为:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'北京'}
age = info.get('age')
print(age)
age=info.get('age',18)
print(age)
A. None 18
B. None None
C. 编译错误
D. 运行错误
解析:A
1、获取字典dict中key的值:dict.get(key,default=None),如果key在dict中则返回对应的值,否则返回default的值,其中default的值可自己指定
https://www.runoob.com/python/att-dictionary-get.html
对比记忆:
dict['key'] 返回指定key在字典中的值,如果key则字典中不存在,则直接报错
dict.setdefault(key,default=None) 如果key在字典中存在,则返回key在字典中指定的值;如果key值不存在,则默认将key添加到字典中去,并将其值设置为default(default默认值为None,也可以自己指定)
4、[单选题]在Python3中,关于字符数组的运行结果为:
names = ["Andrea", "Aaslay", "Steven", "Joa"]
lists = []
for name in names:
if name.count('a') >= 2:
lists.append(name)
print(lists)
A. [‘Andrea’, 'Aaslay', 'Joa']
B. []
C. [‘Andrea’, 'Aaslay']
D. ['Aaslay']
解析:D
需要考虑大小写
5、[单选题]为输出一个字典dic = {‘a’:1,'b':2},下列选项中,做法错误的是()
lis1 = ['a','b']
lis2 = [1,2]
dic = dict(zip(lis1,lis2))
print(dic)
tup = ('a','b')
lis = [1,2]
dic = {tup:lis}
print(dic)
dic = dict(a=1,b=2)
print(dic)
lis = ['a','b']
dic = dict.fromkeys(lis)
dic['a'] = 1
dic['b'] = 2
print(dic)
解析:B
zip函数:
>>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)]
fromkeys() 方法 :
fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值
**方法只用来创建新字典,不负责保存。当通过一个字典来调用 fromkeys 方法时,如果需要后续使用一定记得给他复制给其他的变量
eg:
>>> dict1={}
>>> dict1.fromkeys((1,2,3),'number')
{1: 'number', 2: 'number', 3: 'number'}
>>> print(dict1)
{}
>>> dict2=dict1.fromkeys((1,2,3),'number')
>>> dict2
{1: 'number', 2: 'number', 3: 'number'}
B输出的是 {('a', 'b'): [1, 2]}
6、[单选题]Python3中,下列对程序描述正确的是:
lists = [1, 2, 3, 4, 5, 6]
lists.append([7,8,9])
print(lists)
A. [1,2,3,4,5,6]
B. [1,2,3,4,5,6,[7,8,9]]
C. [1,2,3,4,5,6,7,8,9]
D. [7,8,9]
解析:B
7、[单选题]在Python3中,下列程序运行结果为:
strs = ['a', 'ab', 'abc', 'python']
y = filter(lambda s: len(s) > 2, strs)
tmp = list(map(lambda s: s.upper(), y))
print(tmp)
['ABC', 'PYTHON']
['abc', 'PYTHON']
['abc', 'python']
['a', 'ab']
解析:A
lambda 传参filter函数。
此时lambda函数用于指定过滤列表元素的条件。例如filter(lambda x: x % 3 == 0, [1, 2, 3])指定将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是[3]。
函数式编程filter、map,针对迭代器进行操作。
8、[单选题]Python函数如下,则输出结果为:
def chanageList(nums):
nums.append('c')
print("nums", nums)
str1 = ['a', 'b']
# 调用函数
chanageList(str1)
print("str1", str1)
A. nums ['a', 'b', 'c'],str1 ['a', 'b', 'c']
B. nums ['a', 'b', 'c'],str1 ['a', 'b']
C. nums ['a', 'b'],str1 ['a', 'b']
D. nums ['a', 'b'],str1 ['a', 'b','c']
解析:A
函数传参是赋值操作,赋值的话,列表是引用关系,底层是同一个列表
9、[单选题]下列代码输出为:
str = "Hello,Python";
suffix = "Python";
print (str.endswith(suffix,2));
A. True
B. False
C. 语法错误
D. P
解析:A
str.endswith(suffix[, start[, end]]) 用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。
可选参数"start"与"end"为检索字符串的开始与结束位置。
10、[单选题]在Python3中关于下列字符串程序运行结果为?
str1 = "exam is a example!"
str2 = "exam"
print(str1.find(str2, 7))
A. -1
B. 14
C. 0
D. 10
解析:D
从str1第7个字符开始寻找str2,在str1第10个字符处第一次找到str2字符串
11、[单选题]
执行以下程序,输出结果为()
a = 0 or 1 and True
print(a)
A. 0
B. 1
C. False
D. True
解析:D
优先级从高往低依次为not、and、or。1 and True 结果为True, 0 or True为True
12、[单选题]在Python3中,关于字符串的判断正确的是:
str1 = ''
str2 = ' '
if not str1:
print(1)
elif not str2:
print(2)
else:
print(0)
A. 0
B. 1
C. 2
D. None
解析:B
Python语言中,if后任何非0和非空(null)值为True,0或者null为False。
字符串有值为true 没值为false 进入if判断体 not str1==true 输出
13、[单选题]执行以下程序,结果输出为()
a = [1]
b = 2
c = 1
def fn(lis,obj):
lis.append(b)
obj = obj + 1
return lis,obj
fn(a,c)
print(fn(a,c))
A. ([1, 2, 2], 2)
B. ([1, 2, 2], 3)
C. ([1, 2], 2)
D. ([1, 2], 3)
解析:A
列表可变对象,在第一次函数运行时更改了,但c是数字不可变对象,又是全局变量,第二次调用函数时c仍然为1
14、[单选题]Assuming the filename for the code below is /usr/lib/python/person.py
and the program is run as: python /usr/lib/python/person.py
What gets printed?()
class Person:
def __init__(self):
pass
def getAge(self):
print __name__
p = Person()
p.getAge()
A. Person
B. getAge
C. usr.lib.python.person
D. __main__
解析:D
1、__name__这个系统变量显示了当前模块执行过程中的名称,如果当前程序运行在这个模块中,__name__ 的名称就是__main__如果不是,则为这个模块的名称(当这个模块被引用即被其他模块import时,__name__的值就是模块名,也就是py文件名。)
2、__main__一般作为函数的入口,类似于C语言,尤其在大型工程中,常常有if __name__ == "__main__":来表明整个工程开始运行的入口。
15、[单选题] 一个段代码定义如下,下列调用结果正确的是?
def bar(multiple):
def foo(n):
return multiple ** n
return foo
A. bar(2)(3) == 8
B. bar(2)(3) == 6
C. bar(3)(2) == 8
D. bar(3)(2) == 6
解析:A
bar()()
一般而言,调用一个函数是加一个括号。如果看见括号后还有一个括号,说明第一个bar函数返回了一个函数,如果后面还有括号,说明前面那个也返回了一个函数。以此类推。
1.执行bar函数
bar(2) 返回内层函数foo 传入私有变量 multiple=2
2.执行foo函数
bar(2)(3) -> foo(3) -> 2 * 2 *2 -> 8
16、[单选题]下面哪个是Python中不可变的数据结构?
A. set
B. list
C. tuple
D. dict
解析:C
Python可变数据类型:可改变变量的值,且不会新建对象
List Dictionary Set
Python不可变数据类型:不允许变量的值发生改变,发生改变时会新建对象
Tuple string Number
17、[单选题]
在Python3中,程序运行结果为:
a = 100
b = 14
print(divmod(a, b))
A. (7, 0)
B. (7, 2)
C. [7, 2]
D. None
解析:B
python3里面divmod将除数与余数运算结合,返回的是包含除数与余数的元组。(a//b,a%b)
18、[单选题]在python3中,程序运行结果为:
truple = (1, 2, 3)
print(truple*2)
A. (2,4,6)
B. (1, 2, 3, 1, 2, 3)
C. [1, 2, 3, 1, 2, 3]
D. None
解析:B
print(truple*2)
print(truple)
(1, 2, 3, 1, 2, 3)
(1, 2, 3)
19、[单选题]以下代码运行结果为:
func = lambda x:x%2
result = filter(func, [1, 2, 3, 4, 5])
print(list(result))
A. [1,3,5]
B. [1,2,1,0,1]
C. [1, 2, 3, 4, 5]
D. [1,2,3]
解析:A
filter(function, iterable)
filter函数是python中的高阶函数,
第一个参数是一个筛选函数, 第二个参数是一个可迭代对象,
返回的是一个生成器类型, 可以通过next获取值.
这里大致讲述下原理: filter()把传入的function依次作用于iterable的每个元素, 满足条件的返回true, 不满足条件的返回false, 通过true还是false决定将该元素丢弃还是保留.
所以对2和4取余为0舍弃1,3,5取余为1为真保留
20、[单选题]在Python3中,下列continue的用法:
res = []
for i in 'python':
if i == 'h':
continue
res.append(i)
print(''.join(res))
A. 'p','y','t','h','o','n'
B. 'p','y','t','o','n'
C. 'python'
D. 'pyton'
解析:D
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
str.join(sequence),其中str即为指定字符,sequence要连接的元素序列
21、[单选题]在Python3中,下列说法正确的是:
sets = {1, 2, 3, 4, 5}
print(sets[2])
程序运行结果为:
A. 2
B. 3
C. 报错
D. {3}
解析:C
报错:TypeError: 'set' object is not subscriptable
python中集合set主要利用其唯一性,及并集|、交集&等操作,但不可以直接通过下标进行访问,必须访问时可以将其转换成list再访问
22、[单选题]根据以下代码,下列选项中,说法正确的是()
class Rectangle:
__count = 0
def __init__(self,width,height):
Rectangle.__count += 1
self.__width = width
self.__height = height
@property
def area(self):
return self.__height * self.__width
rectangle = Rectangle(200,100)
A. 创建实例对象rectangle后,可在类外使用rectangle.area()来访问area属性
B. area属性为对象的非私有属性,可以访问和修改
C. 变量__count的作用是为了统计创建对象的个数
D. 因为__width和__height为私有变量,所以在类外不可能访问__width和__height属性
解析:C
@property表示可以使用@property装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改。
A 我们在使用属性的时候 只需要 rectangle.area即可 后面不需要加括号
B 只读不可修改了
C __init__每次实例化对象的时候自动调用,所以C正确
D python里面没有严格的私有属性,还是可以访问的,rectangle_Rectangle__width访问width属性
rectangle_Rectangle__height访问height属性
23、[单选题]如下程序会打印多少个数:()
k = 1000
while k > 1:
print k
k = k/2
A. 1000
B. 10
C. 11
D. 9
解析:D
python2 整数除法/时,会取整的,所以应该是9个。
python3 除法/,结果是浮点的,所以是10个,除非用//取整,是9个
24、[单选题]在Python3中。下列程序运行结果说明正确的是:
strs = 'abcd12efg'
print(strs.upper().title())
A. 'ABCD12EFG'
B. 'Abc12efg'
C. 语法错误
D. 'Abcd12Efg'
解析:D
str.upper() # 把所有字符中的小写字母转换成大写字母
str.lower() # 把所有字符中的大写字母转换成小写字母
str.capitalize() # 把第一个字母转化为大写字母,其余小写
str.title() # 把每个单词的第一个字母转化为大写,其余小写
25、[单选题]下面程序运行结果为:
for i in range(5):
i+=1
print("-------")
if i==3:
continue
print(i)
A. ------- 1 ------- 2 ------- ------- 4 ------- 5
B. ------- 1 ------- 2
C. ------- 1 ------- 2 ------- 3
D. ------- 1 ------- 2 ------- 4 ------- 5
解析:A
1.range(5)返回的是可迭代对象,所以循环次数由可迭代对象决定,语句i+=1并不会影响循环次数
2.但由于i+=1语句,每次循环中print(i)输出的值会比从可迭代对象中取出的值多1
3.continue语句会跳过一次print(i)语句
26、[单选题]下列程序打印结果为( )
nl = [1,2,5,3,5]
nl.append(4)
nl.insert(0,7)
nl.sort()
print nl
A. [1, 2, 3, 4, 5, 5, 7]
B. [0, 1, 2, 3, 4, 5, 5]
C. [1, 2, 3, 4, 5, 7]
D. [7, 5, 4, 3, 2, 1]
解析:A
append()方法是指在列表末尾增加一个数据项。
extend()方法是指在列表末尾增加一个数据集合。
insert()方法是指在某个特定位置前面增加一个数据项,list.insert(index,seq)将指定对象seq插入列表中的指定位置 index为插入位置的索引
sort()是对自己排序,默认为升序,sorted()返回一个排序后的副本
27、[单选题]
列表lis=[1,2,3,4,5,6],其切片lis[-1:1:-1]结果为()
A. [6,5]
B. [1,2]
C. [1,2,3,4]
D. [6,5,4,3]
解析:D
start为-1,stop为1,步进值为-1。
28、[单选题]在Python3中,程序运行返回结果为:
lists = [1, 1, 2, 3, 4, 5, 6]
lists.remove(1)
lists.append(7)
print(lists)
A. [2,3,4,5,6]
B. [1,2,3,4,5,6]
C. [2,3,4,5,6,7]
D. [1,2,3,4,5,6,7]
解析:D
remove()为删除首次出现的指定元素,参数是索引
append()为在列表尾部添加新的元素,加的是元素
29、[单选题]以下程序输出为:
def w1():
print('正在装饰')
def inner():
print('正在验证权限')
return inner()
w1()
A. 正在装饰 正在验证权限
B. 正在装饰
C. 正在验证权限
D. 运行错误
解析:A
如果外层函数返回的是一个函数名的话,运行结果应该是:正在装饰
如果外层函数返回的是函数调用的话,运行结果是:正在装饰 正在验证权限
30、[单选题]What gets printed?()
kvps = { '1' : 1, '2' : 2 }
theCopy = kvps.copy()
kvps['1'] = 5
sum = kvps['1'] + theCopy['1']
print sum
A. 1
B. 2
C. 6
D. 10
E. An exception is thrown
解析1:C
kvps.copy()指的是浅拷贝
在 Python2 和 Python3 中,copy() 方法的意义相同,均为返回一个浅复制的 dict 对象,而浅复制是指只拷贝父对象,不会拷贝对象的内部的子对象,即两个 dict 父对象 kvps 与 theCopy 相互独立,但对它们内部子对象的引用却是共享的,所以 kvps['1'] 的改变不影响 theCopy['1'] 的值(因为改变的是父对象的值)。
顺便一提,深复制是指完全拷贝父对象与子对象,即都相互独立。
注意,这里的子对象不是子类的对象,而是在父对象中的二级对象。
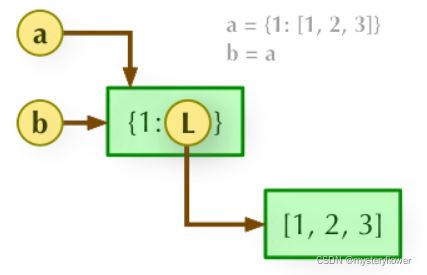
解析2:
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
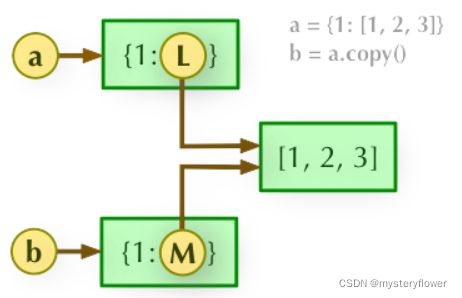
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
3、b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。

解析3:
import copy
d = {'1': [1, 1, 1], '2': 2}
copy1 = d
copy2 = d.copy()
copy3 = copy.copy(d)
copy4 = copy.deepcopy(d)
d['1'][0] = 3
d['2'] = 3
print(copy1, copy2, copy3, copy4)
打印结果分比为
{'1': [3, 1, 1], '2': 3}
{'1': [3, 1, 1], '2': 2}
{'1': [3, 1, 1], '2': 2}
{'1': [1, 1, 1], '2': 2}
方法1:赋值引用,copy1和d指向同一个对象
方法2:浅复制,复制生成新对象copy2,但是只复制一层,[1, 1, 1]为两者共同子对象,
方法3:浅复制,调用copy模块中的方法,同方法2
方法3:深复制,复制生成新对象copy4,并且递归复制所有子对象,所以d中原来指向[1, 1, 1]的改动不会影响深复制生成的子对象[1, 1, 1]
31、[单选题]在Python3中,关于字符串的运算结果为:
strs = 'abcd'
print(strs.center(10, '*'))
A. 'abcd'
B. '*****abcd*****'
C. '***abcd***'
D. ' abcd '
解析:C
center() 方法返回一个指定的宽度10,居中字符串,*为填充的字符,默认是空格。
32、[单选题]已知print_func.py的代码如下:
print('Hello World!')
print('__name__value: ', __name__)
def main():
print('This message is from main function')
if __name__ =='__main__':
main()
print_module.py的代码如下:
import print_func
print("Done!")
运行print_module.py程序,结果是:
A.
Hello World!
__name__ value: print_func
Done!
B.
Hello World!
__name__ value: print_module
Done!
C.
Hello World!
__name__ value: __main__
Done!
D.
Hello World!
__name__ value:
Done!
解析:A
1. 如果模块是被导入,__name__的值为模块名字
2. 如果模块是被直接执行,__name__的值为’__main__’
33、[单选题]当使用import导入模块时,按python查找模块的不同顺序可划分为以下几种:
①环境变量中的PYTHONPATH
②内建模块
③python安装路径
④当前路径,即执行Python脚本文件所在的路径
其中查找顺序正确的一组是()
A. ①④②③
B. ②①④③
C. ②④①③
D. ①②③④
解析:C
34、[不定项选择题]
对于python中__new__和__init__的区别,下列说法正确的是?
A. __new__是一个静态方法,而__init__是一个实例方法
B. __new__方法会返回一个创建的实例,而__init__什么都不返回
C. 只有在__new__返回一个cls的实例时,后面的__init__才能被调用
D. 当创建一个新实例时调用__new__,初始化一个实例时用__init__
解析1:ABCD
__init__ 方法为初始化方法, __new__方法才是真正的构造函数。
__new__方法默认返回实例对象供__init__方法、实例方法使用。
__init__ 方法为初始化方法,为类的实例提供一些属性或完成一些动作。
__new__ 方法创建实例对象供__init__ 方法使用,__init__方法定制实例对象。
__new__是一个静态方法,而__init__是一个实例方法。
实例方法隐含的参数为类实例,而类方法隐含的参数为类本身。
静态方法无隐含参数,主要为了类实例也可以直接调用静态方法。
解析2:
1、静态方法属于类所有,类实例化前即可使用;
2、非静态方法可以访问类中的任何成员,静态方法只能访问类中的静态成员;
3、因为静态方法在类实例化前就可以使用,而类中的非静态变量必须在实例化之后才能分配内存;
4、static内部只能出现static变量和其他static方法!而且static方法中还不能使用this等关键字,因为它是属于整个类;
5、静态方法效率上要比实例化高,静态方法的缺点是不自动进行销毁,而实例化的则可以做销毁;
6、静态方法和静态变量创建后始终使用同一块内存,而使用实例的方式会创建多个内存。
35、[单选题]在Python3中,程序运行结果为:
tmp = dict.fromkeys(['a', 'b'], 4)
print(tmp)
A. {('a', 'b'): 4}
B. {a': 4}
C. {'a': 4, 'b': 4}
D. { 'b': 4}
解析:C
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
36、[单选题]
以下哪个代码是正确的读取一个文件?
A. f = open("test.txt", "read")
B. f = open("r","test.txt")
C. f = open("test.txt", "r")
D. f = open("read","test.txt")
解析:C
Python中,打开文件语法为
text = oepn(filePath, 操作方式,编码方式)
常见操作方式
'r':读
'w':写
'a':追加
常见编码方式
utf-8
gbk
Open是读取,r是文件,rb是二进制文件,read是读取整个文件 readlines是读取整个文件,每一行为一个元素存在列表里,有\n readline 一行一行读取,慢,所需内存大
解析2:
读取文件 :f = open(path,'r','读取方式(r/rb)',encoding='编码格式')
r:表示文本形式读取文件,需要设置编码格式
rb:表示以二进制的方式读取文件,不需要设置编码格式
编码格式:一般为gbk或者utf-8
37、[单选题]执行以下程序,当用户输入0时,输出结果为()
dividend = 1
divide = int(input())
try:
result = dividend / divide
print(1,end=" ")
except ZeroDivisionError:
print(2,end=" ")
except Exception:
print(3,end=" ")
else:
print(4)
A. 1 2
B. 2 4
C. 2 3
D. 2
解析:D
try except else;
except捕获到异常时,else 语句块不会执行
try except finally;
except捕获到异常时,finally语句块会执行
38、[单选题]在Python3中,执行的结果为:
print([2] in [1, 2, 3])
A. True
B. False
C. [2]
D. 报错
解析:B
这个表达式是[1,2,3]这个列表中的元素是否包含列表”[2]” 而不是列表”[2]”中的元素
print(2 in [1, 2, 3]) 执行结果:True
39、[单选题]执行下列选项代码,输出[1, {'age': 10}]的是()
A.
a = [1,{'age':10}]
b = a
a[1]['age'] = 12
print(b)
B.
a = [1,{'age':10}]
b = a[:]
a[1]['age'] = 12
print(b)
C.
a = [1,{'age':10}]
b = a.copy()
a[1]['age'] = 12
print(b)
D.
import copy
a = [1,{'age':10}]
b = copy.deepcopy(a)
a[1]['age'] = 12
print(b)
解析:D
浅拷贝:切片,赋值,调用copy模块的copy方法
深拷贝:用copy模块的deepcopy方法
浅拷贝原数据改变时,拷贝数据也发生改变;深拷贝原数据改变时,拷贝数据不发生改变。
A、B、C均输出:[1, {'age': 12}]
40、[单选题]在python3运行环境下,执行以下选项中的代码,其输出结果不为[2,4,6,8,10]的是()
A.
a = [1,2,3,4,5,6,7,8,9,10]
print(a[1::2])
B.
a = [1,2,3,4,5,6,7,8,9,10]
lis = []
for i in a:
if i % 2 == 0:
lis.append(i)
print(lis)
C.
a = [1,2,3,4,5,6,7,8,9,10]
print(list(filter(lambda x:x % 2 ==0,a)))
D.
a = [1,2,3,4,5,6,7,8,9,10]
def is_odd(n):
return n % 2 == 0
print(list(filter(is_odd(),a)))
解析:D
D错误的原因是因为is_odd加了括号而已,加括号会报错,括号去掉没问题
41、[单选题]
执行下列程序,输出结果为()
def fun(a,*,b):
print(b)
fun(1,2,3,4)
A. [2,3,4]
B. [3,4]
C. 报错
D. 4
解析:C
参数的顺序应该是(位置参数,默认参数,位置不定长参数,关键字不定长参数)
def fun(a,*args,b):
print(b)
def fun1(a,b=1,*args):
print(args)
#fun(1,2,3,4) # TypeError: fun() missing 1 required keyword-only argument: 'b'
#fun(1,2,3,b=4) # TypeError: fun() missing 1 required keyword-only argument: 'b'
fun1(1,2,3,4) # (3, 4)
42、[单选题]
对于以下代码,描述正确的是:
list = ['1', '2', '3', '4', '5']
print list[10:]
A. 导致 IndexError
B. 输出['1', '2', '3', '4', '5']
C. 编译错误
D. 输出[]
解析:D
切片不受内建类型的限制;切片不会导致越界,但通过下标访问会越界。
list 序列和切片
list [a:b:c]:a-开始元素 b-结束元素 c-间隔元素,结果-1
43、[单选题]根据以下程序,下列选项中,说法正确的是()
class Vector:
__slots__='x','y'
def __init__(self):
pass
class Vector3d(Vector):
__slots__='x','z'
def __init__(self):
pass
vector = Vector()
vector3d = Vector3d()
A. 若子类没有定义__slots__属性,则子类可以继承父类的__slots__属性
B. Vector类的实例对象vector会自动获得实例属性x和y
C. Vector3d类的实例对象vector3d最多只能允许属性x和z
D. Vector3d类的实例对象vector3d最多只能允许属性x、y和z
解析:D
44、[不定项选择题]对于下列Python代码,描述正确的有:
foo = [1,2]
foo1 = foo
foo.append(3)
A. foo 值为[1,2]
B. foo 值为[1,2,3]
C. foo1 值为[1,2]
D. foo1 值为[1,2,3]
解析:BD
可变对象为引用传递,不可变对象为值传递。
45、[单选题]执行下面代码,请问输出结果为()
name = "顺顺"
def f1():
print(name)
def f2():
name = "丰丰"
f1()
f1()
f2()
A. 顺顺 顺顺
B. 丰丰 丰丰
C. 顺顺 丰丰
D. 丰丰 顺顺
解析:A
#考的是python代码
name = "顺顺" #定义一个变量name并赋值“顺顺”,python变量具有动态类型
#python是通过制表位的新式分割代码
#定义一个fun1()函数 开始
def fun1():
print(name)
#结束
#定义一个空的方法体fun2()函数 开始
def fun2():
name = "丰丰" #为变量name再次赋值“丰丰”
#结束
fun1() #直接调用函数fun1(), 打印输出 顺顺 ,自动换行
fun1() #直接调用函数fun1() ,打印输出 顺顺,自动换行
fun2() #直接调用函数fun2()
46、[单选题]下列代码输出为:
str1 = "Hello,Python";
str2 = "Python";
print(str1.index(str2));
A. 5
B. 6
C. 7
D. 8
解析:B
index(substr,beg=0,end=len(string)):
在[beg, end]范围内查找substring,找到返回substr的起始下标,否则返回一个异常 ValueError: substring not found
47、[单选题]python3中,执行 not 1 and 1的结果为
A. True
B. False
C. 0
D. 1
解析:B 48、[单选题]Which numbers are printed?() A. 2, 4, 6 解析:C 49、[单选题]在Python3中,程序运行结果为: 解析:C 50、[单选题]Python调用( )函数可实现对文件内容的读取 解析1:A 解析2: 解析3: for line in lines: 解析:B 52、[单选题]在Python3中,关于程序运行结果说法正确的是: 解析:C 53、[单选题]下面有关计算机基本原理的说法中,正确的一项是:() 解析:D 解析:B 解析:B 56、[单选题]What gets printed?() 解析:C A. 求AB最大公约数 解析:A 解析:B A. new line then the string: woow 解析:C 最典型的例子,如要输出字符串 \n,由于反斜杠的转义,因此一般的输出语句为: @outer A. outer 解析:A 61、[单选题]执行以下程序,输出结果为() 解析:D 函数fn的作用是返回传入的字符串的逆序,然后对列表字符串逆序排序,看字符串的最后一个字母e,n,r,h的排序得到结果 fun() 解析:A 63、[不定项选择题]对于Python类中单下划线_foo、双下划线__foo与__foo__的成员,下列说法正确的是? 解析:ABC 64、单选题]在Python3中,下列关于数学运算结果正确的是: A. 3,3,3.3333... 解析:B 65、[单选题]在Python3中,下列程序运行结果为: 解析:C 66、[单选题]在python3中,对程序结果说明正确的是: A. ['one': 1, 'two': 2, 'three': 3],['one': 'abc', 'two': 2, 'three': 3] 解析:B 67、[单选题] A. None 解析:C 68、[单选题] 解析:A 69、[单选题] 解析:C 70、[单选题]在python3中关键字 pass 的使用,则: A. 1,2,3,4,5 解析:B A. Python 解析:B 要匹配的字符串为str1 = "Python's features" re.M:多行匹配,影响 ^ 和 $ .group(0)输出的是匹配正则表达式整体结果 A. 4 解析:A 解析:ABD 元组的运算: 解析:A 75、[单选题]a与b定义如下,下列哪个选项是正确的? 解析:B 76、[单选题]在Python3中,字符串的变换结果为: A. 'Your like python and java','I like python *nd j*v*' 解析:C 77、[单选题]在python3中,关于元组的计算如下: A. None 解析:B 78、[单选题] 解析:B A. 10 解析:B 80、[单选题]在python3.x执行下列选项的程序,不会抛出异常的是() B. C. D. 解析:B 解析:A 解析:D A. gbk utf16 url解码 解析:D 编码过程:line -> 解码 gbk -> 编码 utf-16 -> 编码 url 84、[单选题]在python3中,以下对程序结果描述正确的是: A. {'one': 1, 'two': 2, 'three': 3, 'four': 4} 解析:D 解析:A A. 20 解析:A 87、[单选题]在Python3中。程序语句结果为: A. 'ab' 解析:C 88、[单选题] A. 'abc' 解析:B 89、[单选题]What gets printed?() A. 1 解析:C 90、[单选题]执行下列选项的程序,输出结果为True的是() B. C. D. 解析:B 91、[单选题]假设可以不考虑计算机运行资源(如内存)的限制,以下 python3 代码的预期运行结果是:() A. 455052510 解析:B 92、[单选题]根据以下程序,下列选项中,说法正确的是() foo = Foo() 解析:C 解析:ABCD 94、[单选题] 在Python中没有char字符类型,Python中的数据类型有 A. 1 解析:D B. C. D. 解析:B b1.count = b1.count + 1 A. 1 1 1 解析:B print_module.py的代码如下: 运行 print_module.py程序,结果是: A. Hello World! __name__ value: print_func Done! 解析:A 99、[单选题]有如下函数定义,执行结果正确的是? 解析:A 可以把装饰器想象成洋葱,由近及远对函数进行层层包裹,执行的时候就是拿一把刀从一侧开始切,直到切到另一侧结束。 100、[单选题]执行下列选项的程序,会抛出异常的是() B. C. D. 解析:B A count()返回出现的次数 B index()返回首次出现s2的索引位置,如果没找到则报异常 ValueError: substring not found C find()返回首次出现s2的位置,如果没找到则返回-1 D 返回 s2 in s1 的真假 101、[单选题] A. 1 解析:A A. ['', 'I', 'like', 'python', ''],'I like python ' 解析:C 103、[单选题]有如下类定义,下列描述错误的是? A. isinstance(b, A) == True 解析:D isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。 isinstance()和type()的区别: A. 'abc' 解析:C A. [1, 2, 3] 解析:C 106、[单选题]在Python3中,有关于break的用法: A. 'p','y','t','h','o','n' 解析:B 107、[单选题]在python3中,下列程序运行结果为: A. [0: 'a', 1: 'ab', 2: 'abc', 3: 'abcd'] 解析:C 108、[单选题]如下程序的运行结果为: A. B. C. D. 解析:A A. None 解析:B outer() A. inner outer 解析:C 111、[单选题]在Python3中,下列程序运行结果为: A. 报错 解析:B 112、[单选题]执行以下程序,下列选项中,说法正确的是() A. 执行代码②后,变量tup[2]的id发生改变 解析:C 113、[不定项选择题]下列关于python socket操作叙述正确的是( ) 解析:CD sk.recv(bufsize[,flag]):接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。 上述代码段的运行结果为:() 解析:C 115、[单选题]执行下列选项的程序,输出结果与其他三个选项不同的是() B. C. D. 解析:B 116、[单选题]在python中,使用open方法打开文件,语法如下: 解析:C for f in fn(): A. 4,4, 解析:A 118、[单选题]对列表a = [1,2,3,1,2,4,6]进行去重后,得到列表b,在不考虑列表元素的排列顺序的前提下,下列方法错误的是() B. C. 解析:D 119、[单选题]当一个嵌套函数在其外部区域引用了一个值时,该嵌套函数就是一个闭包,以下代码输出值为: A. 10 解析:D adder(5) #返回了 wrapper ,且x=5 120、[单选题]对于下面的python3函数,如果输入的参数n非常大,函数的返回值会趋近于以下哪一个值(选项中的值用Python表达式来表示)() A. 4 / 3 解析:B 121、[单选题]以下这段代码的输出结果为() A. Hello World! 解析:D A. [('S', 'white'), ('S', 'black'), ('M', 'white'), ('M', 'black')] 解析: @property @① animal = Animal('red') 解析:C A. 解析:A A. 1,[] 解析:C # py3 切片越界(索引为自然数情况): A. 4,4, 解析1:A 解析2: 解析3: A. [1,2,3,7,8,9] 解析:C 128、[单选题]在Python3中,下列程序结果为: A. {'c': 3} 解析:B 解析:B A. a == [1,2, 3, 4, ['a', 'b', 'c'], 5] 解析1:D 解析2: a这个list在电脑里实际的存储情况 b的情况,b实际上和a指向的是同一个值,就好比人的大名和小名,只是叫法不同,但还是同一个人 接下来再看看c的情况,c的情况和a.copy()的情况是一样的,都是我们所谓的浅拷贝(浅复制),浅拷贝只会拷贝父对象,不会拷贝子对象,通俗的说就是只会拷贝到第二层 若父对象发生变化,c不会变化,因为它已经复制的所有父对象,假如子对象发生变化则c会变,比如c[4]和a[4]实际都是一个变量list,他们都指向子对象,若子对象发生变化,他们必然都变化,比如变成["a","d"],那它们指向的值也就变成了a、d。 再看看d的情况,这就是我们所说的深复制,不管a进行什么操作,都不会改变d了,他们已经指向不同的值(这里是指在内存中存储的位置不同了)。 总结: 131、[单选题]在Python3中,下列程序循环的次数为: A. 9 解析:B A. None, 报错 解析:D 解析:ABCD range(100)表示从0到99共一百个数 A. 120 解析:A A. 7,1 解析:C [1, 2, 3, 4, 5] 解析:C A. break 解析:C 解析:D 139、[单选题]运行下列四个选项的程序,不会抛出异常的是() B. C. D. 解析:D A. 9,7,5,3,1 解析:B 141、[单选题]Python3中,已知列表a = [2,3],则下列程序结果是 解析:D 142、下列代码运行结果是? A. [1, 6, 9] 解析:C A. 11 22 (33, 44, 55, 66, 77, 88, 99) 解析:A 144、strs = ' I like python ' A. 'I like python', 'I like python' 解析:C B. C. D. A. {'one': 1, 'two': 2, 'three': 3, 'tmp': 5} 解析:D A. 12,12 x = fn() A. 报错 解析:A 149、下列哪种不是Python元组的定义方式? 解析:A 150、在Python中关于列表的运算结果为: A. 2,3,[1, 2, 2, 3]
优先级关系or
for i in range(2):
print i
for i in range(4,6):
print i
B. 0, 1, 2, 4, 5, 6
C. 0, 1, 4, 5
D. 0, 1, 4, 5, 6, 7, 8, 9
E. 1, 2, 4, 5, 6
range()函数的语法如下:
range(start, end[, step])
参数说明:左闭右开
start: 计数从 start 开始。默认是从 0 开始。例如 range(5) 等价于 range(0, 5);
end: 计数到 end 结束,但不包括 end。例如:range(0, 5) 等于 [0, 1, 2, 3, 4],没有5;
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
lists = [1, 1, 2, 3, 4, 5, 6]
lists.remove(1)
lists.extend([7,8,9])
print(lists)
A. [2,3,4,5,6]
B. [1,2,3,4,5,6,[7,8,9]]
C. [1,2,3,4,5,6,7,8,9]
D. [2,3,4,5,6,7,8,9]
注意 remove()函数用于移除列表中某个值的第一个匹配项。
extend函数是将新列表值依次添加到老列表末尾
A. read()
B. readline()
C. readlines()
D. readclose()
read()读整个文件
readline()读一行
readlines()读所有行到list
1.read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象
2.readline()方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象
3.readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存
python读取文本文件中的信息时,现将信息读取到内存中。
1.读取整个文件
使用read()函数,读取文件的全部内容,返回的内容格式为字符串
使用read()方法读取文件时,在文件的末尾会多一个空行。这是因为read()到文件末尾时返回一个空的字符串。要删除末尾的空行,使用rstrip()方法
2.逐行读取
以每次一行的形式读取文件内容,可对文件对象使用for循环:
如下例:通过for循环来遍历文件对象f中的每一行
with open('123.txt')as f:
for line in f:
print(line)
3.readlines()按行读取,并将结果存储到一个列表中
如下例:readlines读取文件中的所有内容,并按行存储到列表lines中
with open('123.txt')as f:
lines = f.readlines()
print(line)
51、[单选题]执行以下程序,输出结果为()
a = [['1','2'] for i in range(2)]
b = [['1','2']]*2
a[0][1] = '3'
b[0][0] = '4'
print(a,b)
A.[['1', '3'], ['1', '3']] [['4', '2'], ['4', '2']]
B.[['1', '3'], ['1', '2']] [['4', '2'], ['4', '2']]
C.[['1', '3'], ['1', '2']] [['4', '2'], ['1', '2']]
D.[['1', '3'], ['1', '3']] [['4', '2'], ['1', '2']]
嵌套列表乘法得到的每个项都是引用
a和b生成的都是二维列表
b列表的索引指向的是同一片空间,所以,改变了其中一个,都会改变
dicts = {}
dicts[([1, 2])] = 'abc'
print(dicts)
A. {([1,2]): 'abc'}
B. {[1,2]: 'abc'}
C. 报错
D. 其他说法都不正确
字典的键不能是列表
字典的键要求可哈希,而list不可哈希,会报错
可哈希对象:数字类型(int,float,bool)、字符串str、元组tuple、自定义类的对象
不可哈希对象:列表,集合和字典
A. 堆栈(stack)在内存中总是由高地址向低地址方向增长的。
B. 发生函数调用时,函数的参数总是通过压入堆栈(stack)的方式来传递的。
C. 在64位计算机上,Python3代码中的int类型可以表示的最大数值是2^64-1。
D. 在任何计算机上,Python3代码中的float类型都没有办法直接表示[0,1]区间内的所有实数。
A:Intel中规定,栈是从高地址向低地址生长的;堆是由低地址向高地址增长的。ARM就没有规定的很死,可以选择栈是升序还是降序。
B:x64下面在x64下函数调用的前4个参数总是放在寄存器中传递,剩余的参数则压入堆栈中。而x86上则是全部压入堆栈中(除了fastcall方式)。这4个用于存放参数的寄存器分别是:存放整数参数的RCX,RDX,R8,R9;存放浮点数参数的XMM0,XMM1,XMM2,XMM3。
C:在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
D:只要知道,计算机里的浮点类型只是一种用离散方式近似表达实数区间的方法,就可以知道,Python 里的 float 是不可能涵盖 [0,1] 区间内的所有实数的。即,只是---近似---表示,不是真正的能表达实数区间。
54、[单选题]下面哪个不是合法的Python标识符?
A. int32
B. 40XL
C. self
D. name
python中的标识符:
1)第一个字符必须是字母表中字母或下划线 _ 。
2)标识符的其他的部分由字母、数字和下划线组成。
3)标识符对大小写敏感。
4)不可以是python中的关键字,如False、True、None、class等。
5)以下划线_开始的标识符有特殊意义。
以单下划线_开始,代表不能直接访问类的属性;
以双下划线开头代表类的私有成员,如__foo;
以双下划线开始和双下划线结尾,如__foo__(),代表类的构造函数
6)python可以一行显示多条语句,中间用分号;隔开
注意:self不是python中的关键字。类中参数self也可以用其他名称命名,但是为了规范和便于读者理解,推荐使用self。
55、[单选题]在Python3中,对于以下程序正确的是:
lists = [1, 2, 3, 4, 5, 6]
print(lists[6:])
A: 报错
B. []
C. [1,2,3,4,5,6]
D. [6]
对于py3列表切片lists[start:end],当start为自然数且超出索引时,默认返回空列表[ ]
counter = 1
def doLotsOfStuff():
global counter
for i in (1, 2, 3):
counter += 1
doLotsOfStuff()
print counter
A. 1
B. 3
C. 4
D. 7
E. none of the above
当内部作用域想修改外部变量时,需要使用global声明。
局部变量只在函数体内部有效,出了函数体,外面是访问不到的,而全局变量则对下面的代码都有效。
全局变量可以直接在函数体内容部使用的,你可以直接访问,
但是注意的是,如果对于不可变类型的数据,如果在函数里面进行了赋值操作,则对外面的全局变量不产生影响,因为相当于新建了一个局部变量,只是名字和全局一样,
而对于可变类型,如果使用赋值语句,同样对外部不产生影响,但是使用方法的话就会对外部产生影响。
如果使用的是赋值语句,在函数内部相当于新建了一个变量,并且重新给了指向,但是有时候我们想把这个变量就是外部的那个全局变量,在赋值操作的时候,就是对全局变量给了重新的指向,这个时候可以通过global关键字表示我在函数里面的这个变量是使用的全局那个
57、[单选题]下面这段程序的功能是什么?( )
def f(a, b):
if b == 0:
return a
else:
return f(b, a%b)
a, b = input(“Enter two natural numbers: ”)
print f(a, b)
B. 求AB最小公倍数
C. 求A%B
D. 求A/B
最小公倍数=两整数的乘积➗最大公约数
a % b 是求余数,辗转相除法,又称欧几里得算法,以除数和余数反复做除法运算,当余数为 0 时,取当前算式除数为最大公约数。
58、[单选题]以下python代码的输出是什么?
numbers = [1, 2, 3, 4]
numbers.append([5,6,7,8])
print len(numbers)
A. 4
B. 5
C. 8
D. 12
E. An exception is thrown
考察:
list.append()方法,append(self, object, /) Append object to the end of the list.是在原list的末尾增加一个新的元素,a可以是列表、元组、数字、字典等。
list.extend()方法,extend(self, iterable, /) Extend list by appending elements from the iterable.是在原list的末尾,解析a,增加一个或多个元素,a必须是可迭代的对象。
59、[单选题]
What gets printed?()
print r"\nwoow"
B. the text exactly like this: r"\nwoow"
C. the text like exactly like this: \nwoow
D. the letter r and then newline then the text: woow
E. the letter r then the text like this: nwoow
Python 中字符串的前导 r 代表原始字符串标识符,该字符串中的特殊符号不会被转义,适用于正则表达式中繁杂的特殊符号表示。
print "\\n"
这里的 \\ 将被转义为 \ 。而采用原始字符串输出时,则不会对字符串进行转义:
print r"\n"
因此本题答案为 C,输出 \nwoow 。注意前导标识符 r 不会被输出,只起标记作用。
60、[单选题]执行以下程序,输出结果为()
def outer(fn):
print('outer')
def inner():
print('inner')
return fn
return inner
def fun():
print('fun')
B. inner
C. fun
D. 因为没有调用任何函数,所以没有输出结果
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行
lis = ['apple','lemon','pear','peach']
def fn(x):
return x[::-1]
lis.sort(key=fn,reverse=True)
print(lis)
A. ['apple', 'lemon', 'peach','pear']
B. ['pear', 'peach', 'lemon', 'apple']
C. ['apple','pear', 'lemon', 'peach']
D. ['pear', 'lemon', 'peach', 'apple']
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
list.sort( key=None, reverse=False)
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
key=fn 表示对字符串逆序排序
62、[单选题]执行以下程序,输出结果为()
def fun(a=(),b=[]):
a += (1,)
b.append(1)
return a,b
print(fun())
A. ((1,), [1, 1])
B. ((1,1), [1, 1])
C. ((1,), [1])
D. ((1,1), [1])
1. 不可变数据类型,放在函数的形参赋值的时候(设置默认值),每次函数调用都会执行a = '' ,这样相当于每次都清空
不可变数据类型每次在设置默认值时候都会初始化,放在函数的形参里赋值的时候,每次函数调用都会执行a =() a()元组都会变成空值,
2. 可变数据类型,每次只在第一次时候执行赋值。
A. _foo 不能直接用于’from module import *’
B. __foo解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名
C. __foo__代表python里特殊方法专用的标识
D. __foo 可以直接用于’from module import *’
python中主要存在四种命名方式:
1、object #公用方法
2、_object #半保护
#被看作是“protect”,意思是只有类对象和子类对象自己能访问到这些变量,
在模块或类外不可以使用,不能用’from module import *’导入。
#__object 是为了避免与子类的方法名称冲突, 对于该标识符描述的方法,父
类的方法不能轻易地被子类的方法覆盖,他们的名字实际上是
_classname__methodname。
3、_ _ object #全私有,全保护
#私有成员“private”,意思是只有类对象自己能访问,连子类对象也不能访
问到这个数据,不能用’from module import *’导入。
4、_ _ object_ _ #内建方法,用户不要这样定义
a = 10
b = 3
print(a // b)
print(a % b)
print(a / b)
B. 3,1,3.3333...
C. 3.3333...,3.3333...,3
D. 3.3333...,1,3.3333...
// 整除 %取余 / 除
tmp = [1, 2, 3, 4, 5, 6]
print(tmp[5::-2])
A. [5, 3, 1]
B. [6,4,2,0]
C. [6, 4, 2]
D. [2,4,6]
start_index是5,从正向第六个数开始。step是-2,负向每隔两步取一个。end_index省略,取到列表端点。
dicts = {'one': 1, 'two': 2, 'three': 3}
tmp = dicts.copy()
tmp['one'] = 'abc'
print(dicts)
print(tmp)
B. {'one': 1, 'two': 2, 'three': 3},{'one': 'abc', 'two': 2, 'three': 3}
C. {'one': 'abc', 'two': 2, 'three': 3},{'one': 'abc', 'two': 2, 'three': 3}
D. {'one': 1, 'two': 2, 'three': 3},{'one': 1, 'two': 2, 'three': 3}
注意:字典数据类型的copy函数,当简单的值替换的时候,原始字典和复制过来的字典之间互不影响,但是当添加,删除等修改操作的时候,两者之间会相互影响。
所以新字典的值的替换对原字典没有影响
在Python3中,以下程序结果为:
one = (1, 2, 3)
two = ('a', 'b')
print(one+two)
B. 报错
C. (1, 2, 3, 'a', 'b')
D. [1, 2, 3, 'a', 'b']
元组是有内建方法 __add__。 所以可以直接相加
元组不可修改,可以添加
two = one+two
print(two) # 输出 [1, 2, 3, 'a', 'b']
res = 0
for i in range(1, 4):
for j in range(1, 4):
for k in range(1, 4):
if i != j and i != k and j != k:
res += 1
print(res)
在Python3中,三层循环后res的结果为:
A. 6
B. 12
C. 3
D. 5
排列组合
关于Python中的复数,下列说法错误的是()
A. 表是复数的语法是real + image j
B. 实部和虚部都是浮点数
C. 虚部必须后缀j,且必须小写
D. 方法conjugate返回复数的共轭复数
关于python中的复数:
1.复数由实数部分和虚数部分构成
2.虚数不能单独存在,它们总是和一个值为 0.0 的实数部分一起构成一个复数
3.表示复数的语法是real + image j/J
4.实部和虚部都是浮点数
5.虚部的后缀可以是 “j” 或者 “J”
6.复数的 conjugate 方法可以返回该复数的共轭复数。
7.要注意一个细节, 在python3内, 虚数表示是(real) + (image)j, 虚部数字和j或J之间没有空格, 否则j或J将被编译器认为是一个变量名
for i in range(5):
if i == 2:
pass
print(i)
B. 0,1,2,3,4
C. 0,1,3,4
D. 0,1,2,3,4,5
Python中 pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
71、[单选题]下列程序打印结果为()
import re
str1 = "Python's features"
str2 = re.match( r'(.*)on(.*?) .*', str1, re.M|re.I)
print str2.group(1)
B. Pyth
C. thon’s
D. Python‘s features
re模块实现正则的功能:re.match(正则表达式,要匹配的字符串,[匹配模式])
正则表达式r'(.*)on(.*?) .*'
r表示后面的字符串是一个普通字符串(比如\n会译为\和n,而不是换行符)
()符号包住的数据为要提取的数据,通常与.group()函数连用。
.匹配单个任意字符
*匹配前一个字符出现0次或无限次
?匹配前一个字符出现0次或1次
(.*)提取的数据为str1字符串中on左边的所有字符,即Pyth
(.*?)提取的数据为str1中on右边,空格前面,即's
re.I:使匹配对大小写不敏感
|:or
.group(1) 列出第一个括号匹配部分
.group(2) 列出第二个括号匹配部分
72、[单选题]在Python3中,下列程序运行结果为:
tmp = [1, 2, 3, 4, 5, 6]
tmp.insert(-3, 'a')
print(tmp[4])
B. 5
C. 3
D. 'a'
73、[不定项选择题]
若 a = (1, 2, 3),下列哪些操作是合法的?
A. a[1:-1]
B. a*3
C. a[2] = 4
D. list(a)
a[1:-1] ---->(2,)
a*3---->(1,2,3,1,2,3,1,2,3)
a是元组不可改变
list(a)----->[1,2,3]数组和列表可以相互转换
(1)求长度len(T)
(2)拼接T1+T2
(3)元素复制:T*number
(4)求最大值:max(T)
(5)求最小值:min(T)
(6)将列表转成元组:tuple(L)
(7)将元组转成列表:list(T)
74、[单选题]下列程序运行结果为:
a=[2, 4, 6, 8, 20,30,40]
print(a[::2])
print(a[-2:])
A. [2, 6, 20, 40] [30, 40]
B. [4, 8, 30] [30, 40]
C. [2, 6, 20, 40] [40]
D. [4, 8, 30] [30]
对于具有序列结构的数据来说,切片操作的方法是:consequence[start_index: end_index: step]。
请在这里输入引用内容
start_index:
表示是第一个元素对象,正索引位置默认为0;负索引位置默认为 -len(consequence)
end_index:
表示是最后一个元素对象,正索引位置默认为len(consequence)-1;负索引位置默认为 -1。
step:
表示取值的步长,默认为1,步长值不能为0。
a = '123'
b = '123'
A. a != b
B. a is b
C. a == 123
D. a + b = 246
1. python对象的三要素:id用来唯一标识一个对象,type标识对象的类型,value是对象的值
is判断的是a对象是否就是b对象,是通过id来判断的
==判断的是a对象的值是否和b对象的值相等,是通过value来判断的
不可变对象指向同一对象
2. 同一个代码块:数据缓存机制
不同代码块:小数据池驻留机制
提高效率,节约内存
3. 共享字符串字面量是一种优化措施,称为驻留。CPython还会在小的整数上用这个优化措施,防止重复创建“热门”数字。注意,CPython不会驻留所有字符串和整数。
只有数值型和字符串型的情况下,a is b才为True,当a和b是tuple,list,dict或set型时,a is b为False。
strs = 'I like python and java'
print(strs.replace('I', 'Your'))
print(strs.replace('a', '*', 2))
B. 'I like python and java','I like python *nd j*v*'
C. 'Your like python and java','I like python *nd j*va'
D. 'I like python and java','I like python *nd j*va'
Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
str.replace(old, new[, max])
one = (1, 2, 3)
one[2] = 4
print(one[2])
B. 报错:元组中的元素值不支持修改
C. 4
D. (4)
元组是不可变的
下列哪个语句在Python中是非法的?
A. x = y = z = 1
B. x = (y = z + 1)
C. x, y = y, x
D. x += y
y = z + 1 的结果没有返回值,就无法赋值到 x
79、单选题]下列程序运行结果为:
a=[1, 2, 3, 4, 5]
sums = sum(map(lambda x: x + 3, a[1::3]))
print(sums)
B. 13
C. 15
D. 17
a[1::3])其实是列表根据步长的取值,常规所见a[start:end:incr]问题中表示索引范围为1-所有,故得到[ 2, 3, 4, 5]
3为步长,所以最终a[1::3]=[2,5]
lambda函数也叫匿名函数,即,函数没有具体的名称。
map() 会根据提供的函数对指定序列做映射
map(lambda x: x + 3, a[1::3]))--> 进行算数运算后得到新列表,lambda x: x + 3, [2,5]得到[5,8]
sum求和=8+5=13
A.
b = 1
def fn():
nonlocal b
b = b + 1
print(b)
fn()
tup = (('onion','apple'),('tomato','pear'))
for _,fruit in tup:
print(fruit)
a = [b for b in range(10) if b % 2 == 0]
print(b)
lis = [1,2,'a',[1,2]]
set(lis)
A nonlocal关键字是用来在函数或者其他作用域中使用非全局变量。
(简单的来说就是只能用在嵌套函数中,如果在外层函数中定义了相关的局部变量,就会报错)
这里报错b变量找不到
C 打印b变量,未定义,因为循环里面的i是临时变量
D 报错类型错误 不能有list,要是字符的话是可以的
81、[单选题]python变量的查找顺序为()
A. 局部变量>外部嵌套作用域>全局作用域>内置模块作用域
B. 外部嵌套作用域>局部变量>全局作用域>内置模块作用域
C. 内置模块作用域>局部作用域>外部嵌套作用域>全局作用域
D. 内置模块作用域>外部嵌套作用域>局部作用域>全局作用域
82、[单选题]
下面关于return说法正确的是( )
A. python函数中必须有return
B. return可以返回多个值
C. return没有返回值时,函数自动返回Null
D. 执行到return时,程序将停止函数内return后面的语句
return没有返回值时,函数自动返回None,Python没有Null
return返回一个元组,不是返回多个值
83、[单选题]
有一段python的编码程序如下,请问经过该编码的字符串的解码顺序是( )
urllib.quote(line.decode("gbk").encode("utf-16"))
B. gbk url解码 utf16
C. url解码 gbk utf16
D. url解码 utf16 gbk
编码:decode()
解码:encode()
url编码:urllib.quote()
解码过程(与编码过程相反):解码 url -> utf-16 -> gbk
dicts = {'one': 1, 'two': 2, 'three': 3}
dicts['four'] = 4
dicts['one'] = 6
print(dicts)
B. {'one': 6, 'two': 2, 'three': 3}
C. {'one': 1, 'two': 2, 'three': (3, 4)}
D. {'one': 6, 'two': 2, 'three': 3, 'four': 4}
python3中字典是以键:值形式存在,比如{'a':1, 'b':2}
字典添加元素语句:字典名[键] = 值,前提是键不存在;
字典修改元素语句:字典名[键] = 值,前提是键已存在。
85、[单选题]已知a = [1, 2, 3]和b = [1, 2, 4],那么id(a[1])==id(b[1])的执行结果 ()
A. True
B. False
id(object)是python的一个函数用于返回object的内存地址。
但值得注意的是,python 为了提高内存利用效率会对一些简单的对象(如数值较小的int型对象,字符串等)采用重用对象内存的办法。
python中对于小整数对象有一个小整数对象池,范围在[-5,257)之间。对于在这个范围内的征数,不会新建对象,直接从小整数对象池中取就行。
86、[单选题]在Python3中,下列程序运行结果为:
lists = [1, 2, 3, 4]
tmp = 0
for i,j in enumerate(lists):
tmp += i * j
print(tmp)
B. 30
C. 100
D. None
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
enumerate(sequence, [start=0])
strs = 'abbacabb'
print(strs.strip('ab'))
B. 语法错误
C. 'c'
D. ‘ca’
strs.strip('ab')
'ab'表示的是一种集合,这里是指:[ab,ba,aa,bb,aaa,bbb,abb,baa]等;
strs两端,只要是包含了上述集合中的任何一个,都删除。
在Python3中,下列程序运行结果为:
print('\n'.join(['a', 'b', 'c']))
B. 'a'\n'b'\n'c'
C. 报错
D. None
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
nums = set([1,2,2,3,3,3,4])
print len(nums)
B. 2
C. 4
D. 5
E. 7
1、集合是一个无序不重复元素的序列(由于集合是无序的,所以不支持索引) , 集合的元素不能为可变类型(列表、字典、集合)
2、可以使用 { } 或 set( ) 创建集合,但是创建一个空集合时,只能使用set( )
3、集合的特点:
无序性:集合中每个元素的地位是相同的,元素之间是无序的
互异性:一个集合中,每个元素只能出现一次,任何元素之间都是不相同的
确定性:给定一个集合,给定一个元素,该元素或属于该集合,或不属于该集合
4、用集合为列表去重
由于集合中的所有元素都不可重复,因此可以利用集合的这个特点来快速为列表去重
A.
lis = [1,3,2]
a = id(lis)
lis = sorted(lis)
b = id(lis)
print(a==b)
lis = [1,3,2]
a = id(lis)
lis += [4,5]
b = id(lis)
print(a==b)
tup = (1,3,2)
a = id(tup)
tup += (4,5)
b = id(tup)
print(a==b)
tup = (1,3,2)
a = id(tup)
tup = sorted(tup)
b = id(tup)
print(a==b)
使用sorted()进行排序会生成新的序列,生成的新序列和原序列id值必然不同。
对于可变对象,sorted()进行排序时原序列也发生变化
对于+=操作,如果是可变对象,则操作前后序列的id值不变,如果是不可变对象,则操作前后序列的id值改变
import math
def sieve(size):
sieve= [True] * size
sieve[0] = False
sieve[1] = False
for i in range(2, int(math.sqrt(size)) + 1):
k= i * 2
while k < size:
sieve[k] = False
k += i
return sum(1 for x in sieve if x)
print(sieve(10000000000))
B. 455052511
C. 455052512
D. 455052513
通过排除法找素数的个数
算法的思想:
1. 先假设size以内的所有的数都为素数(sieve = [True] * size),
2. 然后在找到size以内的所有的因数(2,math.sqrt(size)+1)p
3. 排除掉所有因数的乘数(sieve[k]=False),
4. 剩下的就是size内所有的素数。
5. math.sqrt(size)+1 为size以内的所有数的最大公因数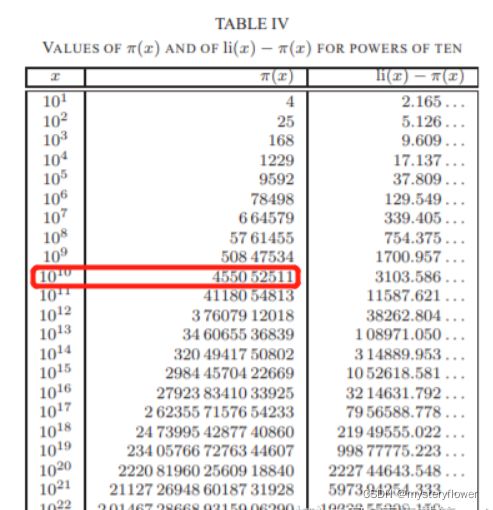
class Foo():
def __init__(self):
pass
def __getitem__(self,pos):
return range(0,30,10)[pos]
A. foo对象表现得像个序列
B. 可以使用len(foo)来查看对象foo的元素个数
C. 可以使用for i in foo:print(i)来遍历foo的元素
D. 不能使用foo[0]来访问对象foo的第一个元素
只要发生了P[key]取值。
当实例对象做P[key]运算时,就会调用类中的__getitem__()方法。
A和B—— foo是一个对象 不可以查看长度
C 因为range(0,30,10)[pos] 所以可以用foo[0] foo[1] foo[2]分别取值 0 10 20
D 我们发生了取下标的操作就会执行 return [0,10,20][pos] pos为你取的下标值 所以当我们foo[1]的时候 返回的是10
93、[不定项选择题]
Python中函数是对象,下列描述正确的有?
A. 函数可以赋值给一个变量
B. 函数可以作为元素添加到集合对象中
C. 函数可以作为参数值传递给其它函数
D. 函数可以当做函数的返回值
Python中一切都是对象,对象的操作用法都可以有
以下哪一个不是Python支持的数据类型
A. char
B. int
C. float
D. list
解析:A
1、数值类型
a、int
b、float
c、long
d、bool(True、False)
e、complex
2、字符串
3、元组
4、列表
5、字典
6、集合
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
95、[单选题]以下代码输出为:
list1 = {'1':1,'2':2}
list2 = list1
list1['1'] = 5
sum = list1['1'] + list2['1']
print(sum)
B. 2
C. 7
D. 10
b = a: 赋值引用,a 和 b 都指向同一个对象。
list1 和 list2 指向的是同一块内存空间
list1['1']=5 ------> 改变了这一块内存空间中'1'的value值
执行这一步后内存空间存储的数据变为:{'1': 5, '2': 2}
因此 sum = list1['1']+list2['1']=5+5=10
96、[单选题]以下判断变量year是否为闰年的方法中,错误的是()
A.
year = int(input("请输入您要判断的年份:"))
result = (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0)
if result:
print(year,"是闰年")
else:
print(year,"不是闰年")
year = int(input("请输入您要判断的年份:"))
if year % 4 ==0:
if year % 100 == 0:
if year % 400 == 0:
print(year , "是闰年")
else:
print(year , "不是闰年")
else:
print(year,"不是闰年")
else:
print(year,"是闰年")
year = int(input("请输入您要判断的年份:"))
if year % 400 == 0:
print(year,"是闰年")
else:
if year % 100 != 0:
if year % 4 == 0:
print(year,"是闰年")
else:
print(year,"不是闰年")
else:
print(year,"不是闰年")
year = int(input("请输入您要判断的年份:"))
if year % 400 == 0:
print(year,"是闰年")
else:
if year % 100 != 0 and year % 4 == 0:
print(year,"是闰年")
else:
print(year,"不是闰年")
97、[单选题]执行以下程序,输出结果为()
class Base(object):
count = 0
def __init__(self):
pass
b1 = Base()
b2 = Base()
print(b1.count,end=" ")
print(Base.count,end=" ")
print(b2.count)
B. 1 0 0
C. 1 0 1
D. 抛出异常
count 类静态变量,类和实例都能访问
98、[单选题]已知print_func.py的代码如下:
print('Hello World!')
print('__name__value: ', __name__)
def main():
print('This message is from main function')
if __name__ =='__main__':
main()
import print_func
print("Done!")
B. Hello World! __name__ value: print_module Done!
C. Hello World! __name__ value: __main__ Done!
D. Hello World! __name__ value: Done!
一个模块中有__name__
1. 直接运行 __name__为 __main__
2. 调用该模块,__name__为被调用模块的 模块名
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
@dec
def foo(n):
return n * 2
A. foo(2) == 12
B. foo(3) == 12
C. foo(2) == 6
D. foo(3) == 6
def test1(func):
def wrapper(*args, **kwargs):
print('before test1 ...')
func(*args, **kwargs)
print('after test1 ...')
return wrapper #返回内层函数的引用
def test2(func):
def wrapper(*args, **kwargs):
print('before test2 ...')
func(*args, **kwargs)
print('after test2 ...')
return wrapper #返回内层函数的引用
@test2
@test1
def add(a, b):
print(a+b)
add(1, 2) #正常调用add
输出:
before test2 ...
before test1 ...
3
after test1 ...
after test2 ...
图片理解(参考知乎姜小白):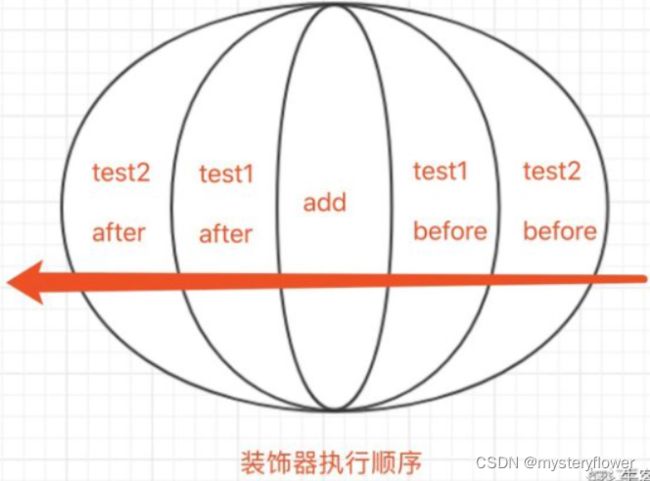
A.
s1 = 'aabbcc'
s2 = 'abc'
count = s1.count(s2)
if count > 0 :
print('s2是s1的子串')
else:
print('s2不是s1的子串')
s1 = 'aabbcc'
s2 = 'abc'
index = s1.index(s2)
if index > -1:
print('s2是s1的子串')
else:
print('s2不是s1的子串')
s1 = 'aabbcc'
s2 = 'abc'
find = s1.find(s2)
if find != -1 :
print('s2是s1的子串')
else:
print('s2不是s1的子串')
s1 = 'aabbcc'
s2 = 'abc'
if s2 in s1:
print('s2是s1的子串')
else:
print('s2不是s1的子串')
index()函数用于找出某个值第一个匹配项的索引位置,如果没有找到对象则抛出异常。
print(s1.count(s2))
运行结果:0
print(s1.index(s2))
运行结果:
ValueError Traceback (most recent call last)
s1 = 'aabbcc'
s2 = 'abc'
----> index = s1.index(s2)
if index > -1:
print('s2是s1的子串')
print(s1.find(s2))
运行结果:-1
print(s2 in s1)
运行结果:False
在Python3中,下列说法正确的是:
lists = [1, 2, 2, 3, 4, 5]
print(lists.index(2))
B. 2
C. 3
D. None
Python index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
index()语法: str.index(str, beg=0, end=len(string))
102、[单选题]在Python3中,下列程序结果为:
strs = ' I like python '
one = strs.split(' ')
two = strs.strip()
print(one)
print(two)
B. ['I', 'like', 'python'],'I like python'
C. ['', 'I', 'like', 'python', ''],'I like python'
D. ['I', 'like', 'python'],'I like python '
三点注意:
split(" "):按一个空格分隔;
strs:首尾空格只有一个;
strip():仅删除首尾空格;
class A(object):
pass
class B(A):
pass
b = B()
B. isinstance(b, object) == True
C. issubclass(B, A) == True
D. issubclass(b, B) == True
abc isinstance(object,classinfo):用于判断object是否是classinfo的一个实例,或者object是否是classinfo类的子类的一个实例,如果是返回True
issubclass(class,classinfo),用于判断class是否是classinfo类的子类,如果是返回True.
issubclass() 函数用于判断参数是否是类型参数的子类。
isinstance()考虑继承关系
type()不考虑继承关系
object -- 实例对象。
classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组
104、[单选题]在Python3中,执行下列程序结果为:
tmp = 'ab' + 'c'*2
print(tmp)
B. 'abcabc'
C. 'abcc'
D. 'abc2'
105、[单选题]在Python3中,下列程序运行结果为:
a = [1, 2, 3]
b = [4, 5, 6]
print(a+b)
B. [4, 5, 6]
C. [1, 2, 3, 4, 5, 6]
D. [5, 7, 9]
for i in 'python':
if i == 'h':
break
print(i)
B. 'p','y','t'
C. 'p','y','t','h'
D. 'pyt'
strs = ['a', 'ab', 'abc', 'abcd']
dicts ={}
for i in range(len(strs)):
dicts[i] = strs[i]
print(dicts)
B. {1: 'a', 2: 'ab', 3: 'abc', 4: 'abcd'}
C. {0: 'a', 1: 'ab', 2: 'abc', 3: 'abcd'}
D. [1: 'a', 2: 'ab', 3: 'abc', 4: 'abcd']
[] 和{}区别
def func(s, i, j):
if i < j:
func(s, i + 1, j - 1)
s[i],s[j] = s[j], s[i]
def main():
a = [10, 6, 23, -90, 0, 3]
func(a, 0, len(a)-1)
for i in range(6):
print a[i]
print "\n"
main()
3
0
‐90
23
6
10
3
0
‐60
23
6
10
6
10
3
0
‐90
23
6
10
3
0
-23
23
109、[单选题]在Python3中,下列程序返回的结果为:
strs = '123456'
print(strs.find('9'))
B. -1
C. 报错
D. 空
find:找到返回第一个位置索引,找不到返回-1
index:找到返回第一个位置索引,找不到报ValueError
110、[单选题]执行以下程序,输出结果为()
def outer():
def inner():
print('inner',end=" ")
print('outer',end = " ")
return inner
B. inner
C. outer
D. outer inner
return inner()才会被调用
dicts = {}
dicts[(1, 2)] = ({3, (4, 5)})
print(dicts)
B. {(1, 2): {(4, 5), 3}}
C. {(1, 2): [(4, 5), 3]}
D. {(1, 2): [3, 4, 5]}
hash(3) = 3
hash((4, 5)) = 3713084879518070856
python中的set是以元素的哈希值确定位置
tup = (1,2,[3,4]) ①
tup[2]+=[5,6] ②
B. 和②均可以执行而不会抛出异常
C. 执行代码②时会抛出异常,最终tup的值为(1,2,[3,4,5,6])
D. 执行代码②时会抛出异常,最终tup的值为(1,2,[3,4])
'tuple'对象不支持项赋值
不能用+=但可以用extend
A. 使用recvfrom()接收TCP数据
B. 使用getsockname()获取连接套接字的远程地址
C. 使用connect()初始化TCP服务器连接
D. 服务端使用listen()开始TCP监听
使用recvfrom()接收TCP数据,udp! socket.recv是tcp协议,recvfrom是udp传输 返回值是(data,address)
其中data是包含接收数据的字符串,address是 发送数据 的套接字地址。
使用getsockname()获取连接套接字的远程地址 自己的! 返回套接字自己的地址,通常是一个元组(ipaddr,port)
使用connect()初始化TCP服务器连接 连接到address处的套接字。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
服务端使用listen()开始TCP监听
sk.recvfrom(bufsize[.flag]):与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.getsockname():返回套接字自己的地址。通常是一个元组(ipaddr,port)
sk.connect(address):连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.listen(backlog):开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
114、[单选题]有如下Python代码段:
b1=[1,2,3]
b2=[2,3,4]
b3 = [val for val in b1 if val in b2]
print (b3)
A. [1,2,3,4]
B. [2]
C. [2,3]
D. 程序有误
要求输出b1和b2的公共部分
A.
a = [['1']*3 for i in range(3)]
print(a)
b = [['1']]*3
print(b)
c=[]
for i in range(3):
lis = ['1']*3
c.append(lis)
print(c)
d = []
lis = ['1']*3
for i in range(3):
d.append(lis)
print(d)
列表乘以数字n,就代表有多少n个列表,然后再把这些列表组成一个列表
open(文件名,访问模式)
如果以二进制格式打开一个文件用于追加,则访问模式为:
A. rb
B. wb
C. ab
D. a
"r","w","a","rb","wb","ab":指定对文件打开方式即文件内容操作方式,即只读,可写,追加,二进制读,二进制写,二进制追加
117、[单选题]执行下列程序,输出结果为()
def fn():
t = []
i = 0
while i < 2:
t.append(lambda x: print(i*x,end=","))
i += 1
return t
f(2)
B. 2,2,
C. 0,1,
D. 0,2,
A.
b = list(set(a))
b = {}
b = list(b.fromkeys(a))
a.sort()
b = []
i = 0
while i < len(a):
if a[i] not in b:
b.append(a[i])
else:
i += 1
D.
a.sort()
for i in range(len(a)-1):
if a[i] == a[i+1]:
a.remove(a[i])
else:
continue
b = a
A项:集合去重
B项:字典去重
b = {} # 字典
# 利用字典去重
dic = b.fromkeys(a) # {1: None, 2: None, 3: None, 4: None, 6: None}
b = list(dic) # <==> list(dic.keys())
C项:列表推导去重
D项索引错误,从后往前实现:
a.sort() # 升序 [1, 1, 2, 2, 3, 4, 6]
length, last = len(a), a[-1]
for i in range(length - 2, -1, -1):
if a[i] == last:
a.remove(a[i])
else:
last = a[i]
b = a
def adder(x):
def wrapper(y):
return x + y
return wrapper
adder5 = adder(5)
print(adder5(adder5(6)))
B. 12
C. 14
D. 16
闭包就是:
1.一个函数(外函数)内部定义了一个函数(内函数):把外部的函数称为外函数,内部的函数称为内函数
2.内函数调用了外函数的变量
3.并且外函数的返回值是内函数的引用,当外函数结束时会将变量绑定给内函数
adder5 = adder(5) # adder5是对wrapper的引用 此时x等于5
adder5(6) # 相当于 wrapper(6) = 5+6=11 所以 adder5(6) =11 ,同理adder5(7)=12
adder5(adder5(6)) # = adder5(11) = wrapper(11) =5+11=16
import random
def foo(n):
random.seed()
c1 = 0
c2 = 0
for i in range(n):
x = random.random()
y = random.random()
r1 = x * x + y * y
r2 = (1 - x) * (1 - x) + (1 - y) * (1 - y)
if r1 <= 1 and r2 <= 1:
c1 += 1
else:
c2 += 1
return c1 / c2
B. (math.pi - 2) / (4 - math.pi)
C. math.e ** (6 / 21)
D. math.tan(53 / 180 * math.pi)
import numpy as np
a = np.repeat(np.arange(5).reshape([1,-1]),10,axis = 0)+10.0
b = np.random.randint(5, size= a.shape)
c = np.argmin(a*b, axis=1)
b = np.zeros(a.shape)
b[np.arange(b.shape[0]), c] = 1
print b
B. 一个 shape = (5,10) 的随机整数矩阵
C. 一个 shape = (5,10) 的 one-hot 矩阵
D. 一个 shape = (10,5) 的 one-hot 矩阵
#生成数组[0,1,2,3,4]:np.arange(5)
#原数组共有x个元素,reshape([n,-1])意思是将原数组重组为n行x/n列的新数组
#所以数组共有5个元素,重组为1行5列的数组:reshape([1,-1])
#因为axis=0,所以是沿着横轴方向重复,增加行数
#所以原数组增加10行:repeat(np.arange(5).reshape([1,-1]), 10, axis = 0)
#数组每个元素都+10:a = repeat(np.arange(5).reshape([1,-1]), 10, axis = 0) + 10
122、[单选题]执行以下程序,输出结果为()
sizes = ['S','M']
colors = ['white','black']
shirts = [(size,color) for color in colors for size in sizes]
print(shirts)
B. [('S', 'white'), ('M', 'white'), ('S', 'black'), ('M', 'black')]
C. [('S', 'white'), ('M', 'black')]
D. [('white', 'S'), ('black', 'M')]
相当于先对sizes循环,再对colors循环
>>> for color in colors:
... for size in sizes:
... res1.append((size, color))
...
>>> res1
[('S', 'white'), ('M', 'white'), ('S', 'black'), ('M', 'black')]
123、[单选题]为了以下程序能够正常运行,①处可以填入的语句是()
class Animal:
def __init__(self,color):
self.__color = color
def color(self):
return self.__color
def color(self,color):
self.__color = color
print(animal.color)
animal.color = 'white'
print(animal.color)
A. property
B. setter
C. color.setter
D. setter.color
property装饰器可以安全的改变函数的属性,利用装饰器的特性,就可以生成装饰器函数下方一样命名的变量,改变该函数就可以采用该函数名.setter
除此之外还有getter,和delter
注意getter的使用一定要在setter和delter之前
124、[单选题]what gets printed? Assuming python version 2.x()
print type(1/2)
B.
C.
D.
E.
python2除法运算为整除运算,
python3除法运算为数学除法运算,整除运算使用符号//
python3中
a/b对应a.__truediv__(b)或者b.__rtruediv__(a);
a//b对应a.__floordiv__(b)或者b.__rfloordiv__(a);
通过重构函数,重写除法运算,例如矩阵的除法。
125、[单选题]在python3中,下列程序结果为:
dicts = {'one': 1, 'two': 2, 'three': 3}
print(dicts['one'])
print(dicts['four'])
B. 1,{}
C. 1,报错
D. 1,None
# py3 访问不存在的索引或key:
# 字典:key访问报KeyError,get访问默认返回None
# 列表、元组、字符串:IndexError
# 列表:
# start越界:返回[] 空列表
# end越界:返回原列表浅拷贝
# start、end均越界:[] 空列表
# 元组:
# start越界:返回() 空元组
# end越界:返回原元组
# start、end均越界:() 空元组
# 字符串:
# start越界:返回'' 空字符
# end越界:返回原字符串
# start、end均越界:'' 空字符
126、[单选题]执行下列程序,输出结果为()
def fn():
t = []
i = 0
while i < 2:
t.append(lambda x: print(i*x,end=","))
i += 1
return t
for f in fn():
f(2)
B. 2,2,
C. 0,1,
D. 0,2,
闭包或工厂函数:
如果在函数中定义的lambda或者def嵌套在一个循环之中,
而这个内嵌函数又引用了一个外层作用域的变量,该变量被循环所改变,
那么所有在这个循环中产生的函数会有相同的值,
也就是在最后一次循环中完成时被引用变量的值。
函数闭包,当调用内层函数时外层函数的i已经变为2了,故i*x = 2*2
def fn():
t = []
i = 0
def inner(x):
print(i * x, end=",")
while i < 2:
t.append(inner)
i += 1
return t # i == 2
for f in fn():
f(2)
在走for f in fn():之前,fn函数已经是确认的值,即已经计算好的两个i*x值
i先通过遍历确定为2,成为一个确定 的数,因为while循环走了两遍,所以整体fn函数包含了两个得到的值
在循环过程中,i只是一个指针,不会计算到i*x里面去,直到退出循环,得到i对应的数为2
后面再进行for时不再重新经历fn函数里的while循环,直接只用i=2这个结果,调用两个值,fn(2)将2复制给x,得到2*2,2*2
127、[单选题]在Python3中,下列正确的是:
lists = [1, 2, 3]
lists.insert(2, [7,8,9])
print(lists)
B. [1,2,3,[7,8,9]]
C. [1,2,[7,8,9],3]
D. [1,2,7,8,9,3]
insert函数用于将指定对象插入列表的指定位置,从另一方面理解,新插入的数据代替了原来该位置的数据,视觉上是在指定位置的‘前面’插入了一个对象。
dicts = {'a': 1, 'b': 2, 'c': 3}
print(dicts.pop())
B. 报错
C. 3
D. ('c': 3)
pop(key[,default]) key值必须写,否则default
pop里面需要传参
129、Python2 中,以下不能在list中添加新元素的方法是()
A. append()
B. add()
C. extend()
D. insert()
1. 列表可包含任何数据类型的元素,单个列表中的元素无须全为同一类型。
2. append() 方法向列表的尾部添加一个新的元素。只接受一个参数。
3. extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
4. insert() 将一个元素插入到列表中,但其参数有两个(如insert(1,”g”)),第一个参数是索引点,即插入的位置,第二个参数是插入的元素。
list中没有add,add()是字典中的操作
130、[单选题]下面代码运行后,a、b、c、d四个变量的值,描述错误的是?
import copy
a = [1, 2, 3, 4, ['a', 'b']]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(5)
a[4].append('c')
B. b == [1,2, 3, 4, ['a', 'b', 'c'], 5]
C. c == [1,2, 3, 4, ['a', 'b', 'c']]
D. d == [1,2, 3, 4, ['a', 'b', ‘c’]]
考察:赋值、深拷贝、浅拷贝
1.对象的赋值
都是进行对象引用(内存地址)传递,即‘’ b is a‘’ ,a 变 b 也变
2.浅拷贝
会创建一个新的对象,即 “c is not a” ,但是,对于对象中的元素,浅拷贝就只会使用原始元素的引用(内存地址),也就是说”c[i] is a[i]”
当我们使用下面的操作的时候,会产生浅拷贝的效果:
使用切片[:]操作
使用工厂函数(如list/dir/set)
使用copy模块中的copy()函数
3.深拷贝
会创建一个新的对象,即”d is not a” ,并且 对于对象中的元素,深拷贝都会重新生成一份(有特殊情况,下面会说明),而不是简单的使用原始元素的引用(内存地址)
拷贝的特殊情况
其实,对于拷贝有一些特殊情况:
对于非容器类型(如数字、字符串、和其他’原子’类型的对象)没有拷贝这一说
如果元祖变量只包含原子类型对象,则不能深拷贝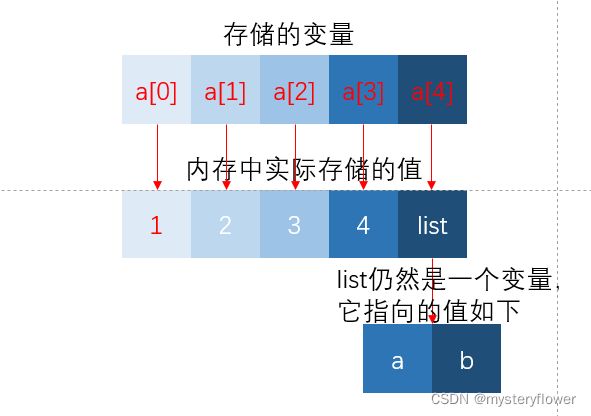
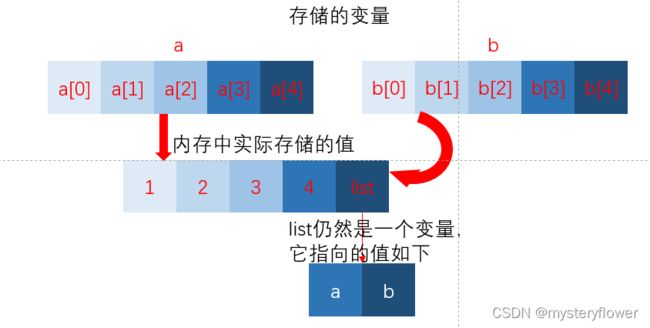
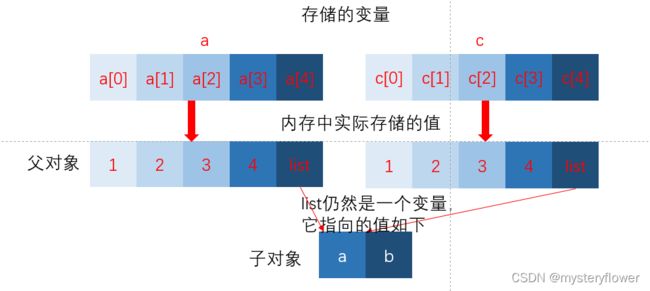

b=a,只是换了一个名字,a怎么变b就怎么变,
c是浅复制,只复制了a的部分值,仍然共用某些值,所以在对a的子对象进行操作时会改变c
d是深复制,完全复制了a的所有值,已经完全与a无关,对a的任何操作都不会影响d
n = 1000
while n > 1:
print(n)
n = n / 2
B. 10
C. 11
D. 无限循环
Python3 循环10次,
Python2.x 循环9次
132、[单选题]在Python3中,以下字符串操作结果为:
strs = 'I like python'
one = strs.find('a')
print(one)
two = strs.index('a')
print(two)
B. 报错,报错
C. -1, None
D. -1, 报错
find:找到返回第一个位置索引,找不到返回-1 index:找到返回第一个位置索引,找不到报ValueError
133、[不定项选择题]若 a = range(100),以下哪些操作是合法的?
A. a[-3]
B. a[2:13]
C. a[::3]
D. a[2-3]
Python 中 切片(Slice)功能的理解:L[start : stop [ : step]]
start 默认值是 0;stop 默认值为 L 的长度;step 默认值是 1。
a[-3]和a[2-3]意味着倒数第三个数和倒数第一个数 分别是97 99
a[::3] start0 end99 step3 依次是0 3 6 9一直到99 步长为3
a[2:13]从a[2]到a[12] 不包括13,前闭后开
134、[单选题]如下代码,执行结果为:
def f(x):
if x == 0:
return 0
elif x == 1:
return 1
else:
return (x*f(x-1))
print(f(5))
B. 720
C. 24
D. 64
递归调用,5的阶乘!
135、[单选题]在Python3中,下列语句正确结果为:
tmp = [2, 1, 5, 4, 7]
print(max(tmp))
print(tmp.index(max(tmp)))
B. 5,2
C. 7,4
D. 7,5
index返回下标
136、[单选题]在Python3环境中,下列程序运行结果为:
trupls = [(1, 2), (2, 3, 4), (4, 5)]
lists = []
for tru in trupls:
for num in tru:
lists.append(num)
print(lists)
(1, 2, 2, 3, 4, 4, 5)
[1, 2, 2, 3, 4, 4, 5]
(1, 2, 3, 4, 5)
list是列表类型
137、[单选题]在Python3的环境中,如下程序是实现找出1-10中奇数,则横线处应填写:
for i in range(1, 11):
if i % 2 == 0:
______
print(i)
B. yield
C. continue
D. flag
break是终止循环的执行 continue 是结束本次循环。
138、[单选题]下列哪种类型是Python的映射类型?
A. str
B. list
C. tuple
D. dict
映射是一种关联式的容器类型,它存储了对象与对象之间的映射关系,字典是python里唯一的映射类型,它存储了键值对的关联,是由键到键值的映射关系。
A.
class Rect:
def __init__(self,width,height):
self.width = width
self.height = height
@property
def area(self):
return self.height* self.width
rect = Rect(10,20)
rect.area()
a = 0
def fun():
a += 1
print(a)
fun()
class Animal:
def __init__(self,color="白色"):
Animal.color = color
def get_color(self):
print("Animal的颜色为",Animal.color)
class Cat(Animal):
def __init__(self):
pass
cat = Cat()
cat.get_color()
class Cat:
def __init__(self,color="白色"):
self.__color = color
cat = Cat("绿色")
print(cat._Cat__color)
A @property将方法变成属性调用,最后一行使用area属性时去掉括号
B 函数中'a += 1'直接修改局部变量不对,可以在使用前用global关键字将其修改成全局变量
C 继承父类的未绑定方法时,要对父类初始化,即在pass前加 'Animal.__init__(self)'
D 也有问题,最后两行代码不需要缩进
140、[单选题]在Python3中,运行结果为:
for i in range(10, 1, -2):
print(i)
B. 10,8,6,4,2
C. 1,3,5,7,9
D. 10,8,6,4,2,1
range(start, stop[,step]) 从start开始(包括start,不写默认为0),到stop结束(不包括stop),step步长(不写默认为1)
print(a*2)
A. [4,6]
B. [4,3]
C. [4,6,4,6]
D.[2,3,2,3]
a = map(lambda x: x**3, [1, 2, 3])
list(a)
B. [1, 12, 27]
C. [1, 8, 27]
D. (1, 6, 9)
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数
1.lambda匿名函数的格式:lambda(x:x**3)冒号前是参数;冒号后是表达式lambda返回的是函数对象
2.map(函数名,可以迭代的对象);可以迭代的对象有列表、元祖、字符串
3.这个函数的意思是:函数名应用于迭代对象(列表)的每一个元素中,结果以列表的形式返回
143、以下程序输出为:
# -*- coding:utf-8 -*-
def test(a, b, *args):
print(a)
print(b)
print(args)
test(11, 22, 33, 44, 55, 66, 77, 88, 99)
B. 编译错误
C. 运行错误
D. 11 22 (11,22,33, 44, 55, 66, 77, 88, 99)
参数优先级:位置参数 > 动态位置参数 > 默认参数 > 动态关键字参数
位置参数:a和b是位置参数
动态参数:
动态位置参数:*args:接收多余的位置参数,以元组形式显示
动态关键字参数:**kwargs:接收多余的关键字参数,以字典形式显示
def test(a,b,*args): # a和b位置参数,级别最高,接收11,22,*args接收多余的参数,不定长,以元组形式显示
print(a)
print(b)
print(args)
test(11,22,33,44,55,66,77,88,99)
#结果:
'''
11
22
(33,44,55,66,77,88,99)
'''
one = strs.strip()
print(one)
two = strs.rstrip()
print(two)
在Python3中,关于 strip() 和 rstrip() 的程序运行结果为:
B. ' I like python', ' I like python'
C. 'I like python', ' I like python'
D. 'I like python', 'I like python '
strip():删除首尾空格;
rstrip():仅删除右空格;
145、执行下列选项中的程序,输出结果为False的是()
A.
t1 = (1,2,3)
t2 = t1[:]
print(t1 is t2)
lis1 = [1,2,3]
lis2 = lis1[:]
print(id(lis1)==id(lis2))
s1 = '123'
s2 = '123'
print(s1 is s2)
a = 123
b = 123
print(id(a) == id(b))
解析:B
146、在Python3中,下列程序结果为:
dict1 = {'one': 1, 'two': 2, 'three': 3}
dict2 = {'one': 4, 'tmp': 5}
dict1.update(dict2)
print(dict1)
B. {'one': 4, 'two': 2, 'three': 3}
C. {'one': 1, 'two': 2, 'three': 3}
D. {'one': 4, 'two': 2, 'three': 3, 'tmp': 5}
dict.update(dict2):把字典dict2的键/值对更新到dict里
147、在Python3中,有关字符串的运算结果为:
strs = 'I like python and java'
one = strs.find('n')
print(one)
two = strs.rfind('n')
print(two)
B. 15,15
C. 12,15
D. None,None
解析:C
rfind函数用于返回字符串最后一次匹配的位置,也就是从右往左第一次匹配的结果,如果没有匹配,返回-1
148、【问题】执行以下代码,结果输出为()
num = 1
def fn():
num += 1
return lambda:print(num)
x()
B. 2
C. None
D.1
函数内部修改同名全局变量需要使用global关键字声明,即global num num+=1,否则报UnboundLocalError
A. (1)
B. (1, )
C. (1, 2)
D. (1, 2, (3, 4))
Python 中的 tuple 结构为 “不可变序列”,用小括号表示。为了区别数学中表示优先级的小括号,当 tuple 中只含一个元素时,需要在元素后加上逗号。
(1)会被python认为是int类型,所以必须是(1,)
元组的本质是逗号
lists = [1, 2, 2, 3, 3, 3]
print(lists.count(3))
print(lists.pop())
lists.pop()
print(lists)
B. 3,3,[1, 2, 2, 3]
C. 3,3,[1, 2, 2, 3, 3]
D. 2,3,[1, 2, 2, 3, 3]
解析:B
count() 方法用于统计某个元素在列表中出现的次数。
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
lists = [1, 2, 2, 3, 3, 3]
3出现了3次
两次的pop() 所以删除 两个三