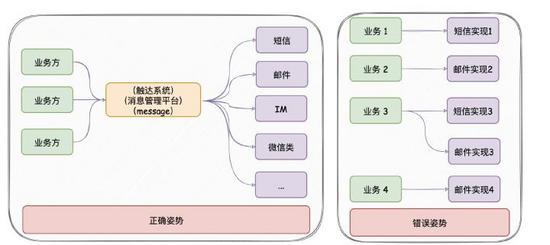
让日志打印更加优雅和数据链路追踪?
今天来聊些大家都用得上的东西: 数据链路追踪 。之前引入了系统的监控来快速定位应用操作系统上的问题,而业务问题呢?在这篇文章中你可以看到用注解的方式打印日志,也能看到 简易版 的全链路追踪是怎么实现的。
不多BB,开始吧
01、注解日志打印
日志的搭建我在austin最开始的前几篇已经有提及了,之前一直在等我的基友 @蛮三刀酱 他的日志组件库上传到Maven库,好让我使用使用下。在最近,他已经更新了两个版本,然后传到了Maven库了,所以我就来接入了
这个组件库做的事情就是使用 注解 的方式来打印日志信息,并支持 SpEL解析 、 自定义上下文 以及 自定义函数 。它支持的东西听起来很牛逼,但说白了就是 让记录日志的方式做得更装逼 。我们写个破代码还能装逼,这谁受得了!这谁顶得住!
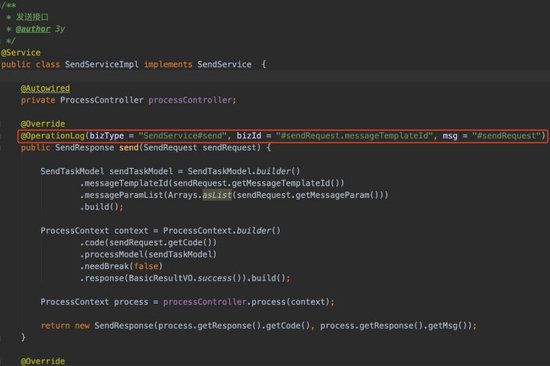
现在我已经把注解在方法上定义了,当该方法被调用时,它打印了以下的日志:

看起来很好用,对不对?通过一个注解,我就能把 方法的入参 信息打印出来,有 bizType 和 bizId 给我们自定义,那就可以很方便地 定位 出打印日志的地方了,并且他还 贴心 把 response 返回值也输出到日志上。
至少在这个接口上,这非常符合我这个场景的需求,我们再通过一张图稍微重温下这个 send 接口到底做了什么事:

在 接口层面 打印入参信息以及返回值就能定位到很多问题( 懂的都懂 ),使用注解还 不用干扰 到我们正常的业务代码就能打印出这么好的日志信息了( 这个逼是装上了 )
它的实现原理并不复杂,感兴趣的小伙伴可以拉代码自己看看,先看 readmd 再看代码!!
GitHub: https:// github.com/qqxx6661/log Record
总的来说,他通过 SpEL表达式 来读取到 #sendRequest 入参对象的信息,而注解解析则用的是 Spring AOP 。至于 自定义上下文 以及 自定义函数 我在这是没用到的,至少在austin项目场景下,我感觉都没什么用。哦,对了,它还能将日志输出到别的管道(MQ)。可惜的是,我这场景也用不到。
在目前的实现下,我 就只有这个接口 能用到该组件,我承认他在某些场景是很好用。
但它是 有局限性 的:打印的日志信息跟 方法参数强相关 :如果要打印 方法参数以外的变量 那需要用到 上下文Context 或者 自定义函数 。自定义函数的使用姿势是有局限性的,我们并不能把日志所涉及的变量都抽取到某函数上。如果用上下文Context的话,还是得 嵌入业务代码 里,那为啥不直接拼装好日志打呢?

我一度怀疑是不是我的使用姿势不对,跟基友探讨了下,我的应用场景下还得自己抽取 LogUtils 进行日志打印。
02、数据链路追踪
从上面的接口打印的日志以及能很快地排查出 接入层 的问题了,其实重头戏其实是在 处理层 上,回顾下处理层目前做的事情:
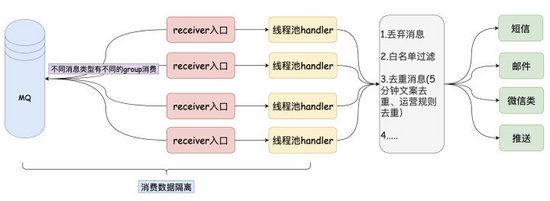
在处理层上会有不少的 平台过滤规则 ,这些过滤规则大多都不是针对于消息模板的,而是针对于userId(接收者)的。在这个处理过程中,记录下 每个消息模板中的每个用户的执行情况 就尤其重要了。
1 、定位和排查问题。如果客户反馈用户收不到短信,一般情况下都在这个处理的过程中导致的(可能是被去重,可能是调用接口出问题)
2 、对模板执行的整体链路数据分析。一个消息模板一天发送的量级,中途被 每个规则 过滤的量级,成功下发的量级以及消息最后被点击的量级。 除了点击数据,其他的数据都来源处理层
基于上面的背景,我设计了一套埋点的规则,在处理 关键链路上 打上对应的点位
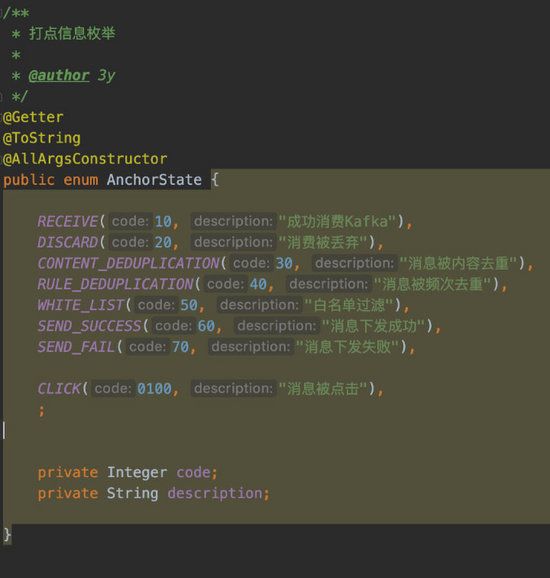
目前点位的信息是不全的,随着系统的完善和接入各个渠道,这里的点位信息还会继续增加,只要我们认为有哪些地方是需要记录下来的,就可以增加。
可能看到这里你会觉得有些抽象,我请求一次接口打印下日志就容易懂啦:
// 1、接入层打印日志(returnStr打印处理结果,而msg打印出入参信息)
2022-01-08 15:44:53.512 [http-nio-8080-exec-7] INFO com.java3y.austin.utils.LogUtils -
{"bizId":"1","bizType":"SendService#send","logId":"34df87fc-0489-46c1-b39f-cafd7652f55b",
"msg":"{\"code\":\"send\",\"messageParam\":{\"extra\":null,\"receiver\":\"13288888888\",\"variables\":{\"title\":\"yyyyyy\",\"contentValue\":\"66661641627893157\"}},\"messageTemplateId\":1}","operateDate":1641627893512,"returnStr":"{\"code\":\"00000\",\"msg\":\"操作成功\"}","success":true,"tag":"operation"}
// 2、处理层打印入口日志(表示成功消费到Kafka的消息 state=10)
2022-01-08 15:44:53.622 [org.springframework.kafka.KafkaListenerEndpointContainer#6-0-C-1] INFO com.java3y.austin.utils.LogUtils -
{"businessId":1000000120220108,"ids":["13288888888"],"state":10,"timestamp":1641627893622}
// 3、处理层打印入口日志(表示成功消费到Kafka的原始日志)
2022-01-08 15:44:53.622 [org.springframework.kafka.KafkaListenerEndpointContainer#6-0-C-1] INFO com.java3y.austin.utils.LogUtils -
{"bizType":"Receiver#consumer","object":{"businessId":1000000120220108,"contentModel":{"content":"66661641627893157"},"deduplicationTime":1,"idType":30,"isNightShield":0,"messageTemplateId":1,"msgType":10,"receiver":["13288888888"],"sendAccount":66,"sendChannel":30,"templateType":10},"timestamp":1641627893622}
// 4、处理层打印逻辑过滤日志(state=20,表示这条消息由于配置了丢弃,已经丢弃掉)
2022-01-08 15:44:53.623 [pool-8-thread-3] INFO com.java3y.austin.utils.LogUtils -
{"businessId":1000000120220108,"ids":["13288888888"],"state":20,"timestamp":1641627893622}
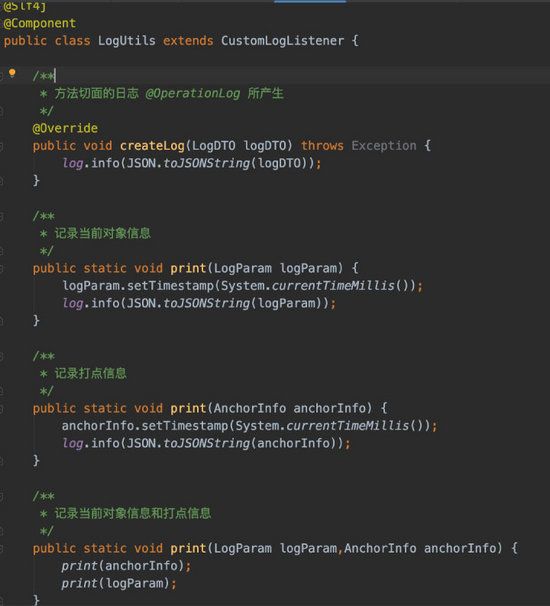
我打印日志的核心逻辑是:
- 在 入口侧 (这里包括接口的入口以及刚消费Kafka的入口)需要打印出原始的信息。原始信息有了,才好对问题进行定位和排查,至少帮助我们复现
- 在处理过程中使用 某个标识 来标明处理的过程(10代表成功消费Kafka,20代表该消息已经被丢弃...),并且 日志的格式是统一 的这样后续我们可以统一清洗该日志信息

至于打日志的过程就很简单了,只要抽取一个 LogUtils 类就好咯:
那对于点击是怎么追踪的呢?其实也好办,在 下发的链接 上拼接 businessId 就好了。只要我们能拿到点击的数据,在链接上就可以判断是否存在 track_code_bid 字符,进而找到是哪个用户点击了哪个模板消息。
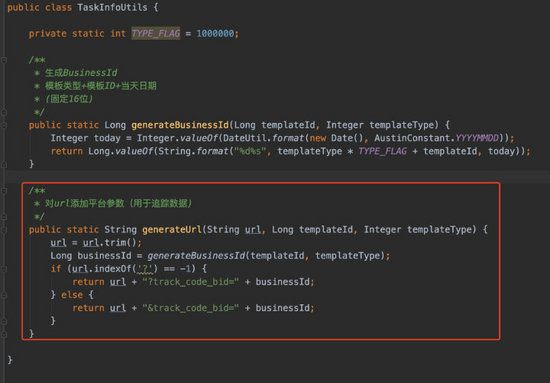
无论是打点日志还是原始日志, businessId 会跟随着消息的生命周期始终。而businessId的构成只是通过 消息模板内容+时间 而成

03、后续
现在已经打印出对应的数据链路信息了,但这是不够的,这只是将数据链路信息写到了服务器的本地上,还需要考虑以下的情况:
1 、运行应用的服务器一般是集群,日志数据会记录到不同的机器上,排查和定位问题只能登录各个服务器查看
2 、链路的数据需要 实时 ,通过提供Web后台的界面功能快速让 业务方自助 查看整个流程
3 、链路的数据需要离线保存用于对数据的分析以及留备份(本地日志往往存放不超过30天)

后面这些功能都会一一实现,优先会接入ELK来有统一查询日志信息的入口以及配置相关的 业务 监控或告警,敬请期待。
点个赞一点都不过分吧?我是3y,下期见。
austin项目
austin项目立志成为每个Java初学者能够写在简历上的项目,它的核心是消息推送平台,核心功能:发送消息
项目出现意义:只要公司内有发送消息的需求,都应该要有类似austin的项目,对各类消息进行统一发送处理。这有利于对功能的收拢,以及提高业务需求开发的效率