Lighttpd1.4.20源码分析之fdevent系统(4) -----连接socket的处理与超时处理
前面讲了lighttpd是怎样使用fdevent系统的,以及监听socket的处理过程。这一篇我们来看一看lighttpd是怎样处理连接socket的。
首先,我们来看看lighttpd是怎样建立和客户端的连接的。前面在讲监听socket的处理过程中其实已经讲解了连接的建立过程。lighttpd监测监听socket的IO事件,如果有可读事件发生,那么表示有新的连接请求,然后调用network.c/network_server_handle_fdevent()来处理连接请求。network_server_handle_fdevent()函数调用connections.c/connection_accept() 接受客户端的请求,建立连接。在建立连接的同时,就得到了连接socket的fd,也就是accept函数的返回值。
建立连接之后,这个连接对应的状态机的状态被设置为CON_STATE_REQUEST_START,就是开始读取客户端发过来的request信息。在从connection_accept函数跳回network_server_handle_fdevent()函数的for循环中后,程序紧接着就调用了一次connection_state_machine()函数,这个函数是根据当前连接的状态机的状态设置状态机的下一个状态,CON_STATE_REQUEST_START的下一个状态是CON_STATE_READ,这个状态表示连接正在读取客户端发送的数据。当连接的状态机被设置成CON_STATE_READ后,在connection_state_machine()函数的最后,有这样一个switch语句:
1 switch (con -> state)
2 {
3 case CON_STATE_READ_POST:
4 case CON_STATE_READ:
5 case CON_STATE_CLOSE:
6 fdevent_event_add(srv -> ev, & (con -> fde_ndx), con -> fd, FDEVENT_IN);
7 break ;
8 case CON_STATE_WRITE:
9 /*
10 * request write-fdevent only if we really need it
11 * - if we have data to write
12 * - if the socket is not writable yet
13 */
14 if ( ! chunkqueue_is_empty(con -> write_queue) && (con -> is_writable == 0 ) && (con -> traffic_limit_reached == 0 ))
15 {
16 fdevent_event_add(srv -> ev, & (con -> fde_ndx), con -> fd, FDEVENT_OUT);
17 }
18 else
19 {
20 fdevent_event_del(srv -> ev, & (con -> fde_ndx), con -> fd);
21 }
22 break ;
23 default :
24 fdevent_event_del(srv -> ev, & (con -> fde_ndx), con -> fd);
25 break ;
26 }
上面这个switch语句将状态处在CON_STATE_READ_POST,CON_STATE_READ和CON_STATE_CLOSE的连接对应的连接socket fd加入到fdevent系统中,并监听可读事件。将处CON_STATE_WRITE状态且有数据要写的连接对应的socket fd加入到fdevent系统中,并监听可写事件。其他状态的连接则把对应的fd从fdevent系统中删除,因为这些连接不会有IO事件发生。
这样,连接socket fd就被加入到了fdevent系统中。下面就是等待IO事件的发生。程序在前面已经提到过,如下:
1 if ((n = fdevent_poll(srv -> ev, 1000 )) > 0 )
2 {
3 int revents;
4 int fd_ndx;
5 fd_ndx = - 1 ;
6 do
7 {
8 fdevent_handler handler;
9 void * context;
10 handler_t r;
11 fd_ndx = fdevent_event_next_fdndx(srv -> ev, fd_ndx);
12 revents = fdevent_event_get_revent(srv -> ev, fd_ndx);
13 fd = fdevent_event_get_fd(srv -> ev, fd_ndx);
14 handler = fdevent_get_handler(srv -> ev, fd);
15 context = fdevent_get_context(srv -> ev, fd);
16 switch (r = ( * handler) (srv, context, revents))
17 {
18 case HANDLER_FINISHED:
19 case HANDLER_GO_ON:
20 case HANDLER_WAIT_FOR_EVENT:
21 case HANDLER_WAIT_FOR_FD:
22 break ;
23 case HANDLER_ERROR:
24 /*
25 * should never happen
26 */
27 SEGFAULT();
28 break ;
29 default :
30 log_error_write(srv, __FILE__, __LINE__, " d " , r);
31 break ;
32 }
33 } while ( -- n > 0 );
34 }
这段程序在前面已经讲解过。对于fdevent系统,它不关心自己处理的fd是连接fd还是监听fd,它所做的就是对于发生了这个fd所希望的IO事件以后,调用这个fd对应的处理函数处理IO事件。连接fd对应的处理函数是connections.c/connection_handle_fdevent()函数。函数的代码如下:
1 handler_t connection_handle_fdevent( void * s, void * context, int revents)
2 {
3 server * srv = (server * ) s;
4 connection * con = context;
5 // 把这个连接加到作业队列中。
6 joblist_append(srv, con);
7 if (revents & FDEVENT_IN)
8 {
9 con -> is_readable = 1 ;
10 }
11 if (revents & FDEVENT_OUT)
12 {
13 con -> is_writable = 1 ;
14 /*
15 * we don't need the event twice
16 */
17 }
18 if (revents & ~ (FDEVENT_IN | FDEVENT_OUT))
19 {
20 /*
21 * looks like an error 即可读又可写,可能是一个错误。
22 */
23 /*
24 * FIXME: revents = 0x19 still means that we should read from the queue
25 */
26 if (revents & FDEVENT_HUP)
27 {
28 if (con -> state == CON_STATE_CLOSE)
29 {
30 con -> close_timeout_ts = 0 ;
31 }
32 else
33 {
34 /*
35 * sigio reports the wrong event here there was no HUP at all
36 */
37 connection_set_state(srv, con, CON_STATE_ERROR);
38 }
39 }
40 else if (revents & FDEVENT_ERR)
41 {
42 connection_set_state(srv, con, CON_STATE_ERROR);
43 }
44 else
45 {
46 log_error_write(srv, __FILE__, __LINE__, " sd " , " connection closed: poll() -> ??? " , revents);
47 }
48 }
49 if (con -> state == CON_STATE_READ || con -> state == CON_STATE_READ_POST)
50 {
51 connection_handle_read_state(srv, con);
52 // 继续读取数据,直到数据读取完毕
53 }
54 // 数据的写回并没有放给状态机去处理。
55 if (con -> state == CON_STATE_WRITE && ! chunkqueue_is_empty(con -> write_queue) && con -> is_writable)
56 {
57 if ( - 1 == connection_handle_write(srv, con))
58 {
59 connection_set_state(srv, con, CON_STATE_ERROR);
60 log_error_write(srv, __FILE__, __LINE__, " ds " , con -> fd, " handle write failed. " );
61 }
62 else if (con -> state == CON_STATE_WRITE)
63 {
64 // 写数据出错,记录当前时间,用来判断连接超时。
65 con -> write_request_ts = srv -> cur_ts;
66 }
67 }
68 if (con -> state == CON_STATE_CLOSE)
69 {
70 /*
71 * flush the read buffers 清空缓冲区中的数据。
72 */
73 int b;
74 // 获取缓冲区中数据的字节数
75 if (ioctl(con -> fd, FIONREAD, & b))
76 {
77 log_error_write(srv, __FILE__, __LINE__, " ss " , " ioctl() failed " , strerror(errno));
78 }
79 if (b > 0 )
80 {
81 char buf[ 1024 ];
82 log_error_write(srv, __FILE__, __LINE__, " sdd " , " CLOSE-read() " , con -> fd, b);
83 // 将缓冲区中的数据读取后并丢弃,此时连接已经关闭,数据是无用数据。
84 read(con -> fd, buf, sizeof (buf));
85 }
86 else
87 {
88 /*
89 * nothing to read 缓冲区中没有数据。复位连接关闭超时计时。
90 */
91 con -> close_timeout_ts = 0 ;
92 }
93 }
94 return HANDLER_FINISHED;
95 }
可以看到,connection_handle_fdevent()函数根据当前连接fd所发生的IO事件,对connection结构体中的标记变量赋值,如is_writable,is_readable等,并做一些时间的记录。这些事件所对应的真正的IO处理则交给状态机处理。状态机根据这些标记变量进行相应的动作处理。
这样,对于fdevent系统对于一次连接fd的IO事件就处理结束了。当然,真正的处理工作是由状态机来完成。下面的图简要的描述了fdevent系统对连接fd和监听fd的处理:
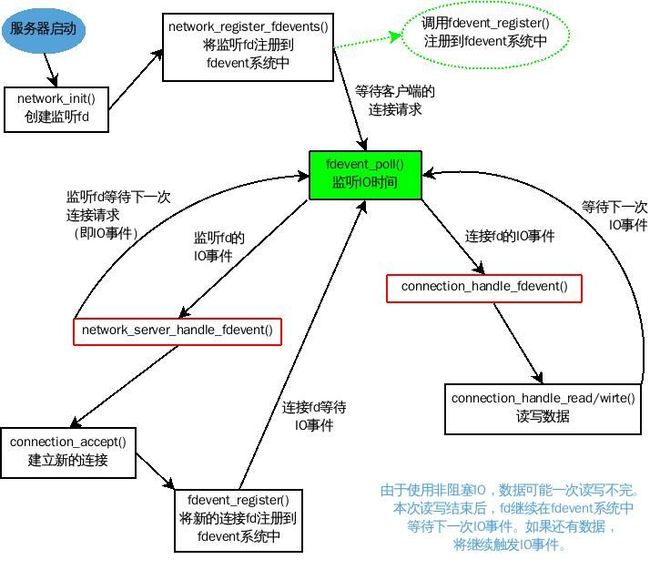
下面我们来看一看连接超时的处理。连接超时有三种:读数据超时,写数据超时和关闭超时。处理超时的代码在server.c中的main函数woker进程开始部分:
1 /* *
2 * alarm函数发出的信号,表示一秒钟已经过去了。
3 */
4 if (handle_sig_alarm)
5 {
6 /*
7 * a new second 新的一秒开始了。。。
8 */
9 #ifdef USE_ALARM
10 /*
11 * reset notification 重置
12 */
13 handle_sig_alarm = 0 ;
14 #endif
15 /*
16 * get current time 当前时间。精确到一秒
17 */
18 min_ts = time(NULL);
19 /* *
20 * 这里判断和服务器记录的当前时间是否相同。
21 * 相同,则表示服务器还在这一秒中,继续处理请求等。
22 * 如果不相同,则进入了一个新的周期(当然周期是一秒)。这就要做一些触发和检查以及清理的动作。
23 * 如插件的触发连接的超时清理状态缓存等。
24 * 其中,最主要的工作是检查连接的超时。
25 */
26 if (min_ts != srv -> cur_ts)
27 {
28 int cs = 0 ;
29 connections * conns = srv -> conns;
30 handler_t r;
31 switch (r = plugins_call_handle_trigger(srv))
32 {
33 case HANDLER_GO_ON:
34 break ;
35 case HANDLER_ERROR:
36 log_error_write(srv, __FILE__, __LINE__, " s " , " one of the triggers failed " );
37 break ;
38 default :
39 log_error_write(srv, __FILE__, __LINE__, " d " , r);
40 break ;
41 }
42 /*
43 * trigger waitpid
44 */
45 srv -> cur_ts = min_ts;
46 /*
47 * cleanup stat-cache 清理状态缓存。每秒钟清理一次。
48 */
49 stat_cache_trigger_cleanup(srv);
50 /* *
51 * check all connections for timeouts
52 */
53 for (ndx = 0 ; ndx < conns -> used; ndx ++ )
54 {
55 int changed = 0 ;
56 connection * con;
57 int t_diff;
58
59
60
61 con = conns -> ptr[ndx];
62
63 // 连接的状态是在读
64 if (con -> state == CON_STATE_READ || con -> state == CON_STATE_READ_POST)
65 {
66 if (con -> request_count == 1 ) // 连接处理一个请求
67 {
68 if (srv -> cur_ts - con -> read_idle_ts > con -> conf.max_read_idle)
69 {
70 /*
71 * time - out
72 */
73 connection_set_state(srv, con, CON_STATE_ERROR);
74 changed = 1 ;
75 }
76 } // 这个连接同时处理多个请求
77 else
78 {
79 if (srv -> cur_ts - con -> read_idle_ts > con -> conf.max_keep_alive_idle)
80 {
81 /*
82 * time - out
83 */
84 connection_set_state(srv, con, CON_STATE_ERROR);
85 changed = 1 ;
86 }
87 }
88 }
89 // 连接的状态是写
90 if ((con -> state == CON_STATE_WRITE) && (con -> write_request_ts != 0 ))
91 {
92 if (srv -> cur_ts - con -> write_request_ts > con -> conf.max_write_idle)
93 {
94 /*
95 * time - out
96 */
97 #if 1
98 log_error_write(srv, __FILE__, __LINE__, " sbsosds " , " NOTE: a request for " ,
99 con -> request.uri, " timed outafter writing " , con -> bytes_written, " bytes. We waited " ,
100 ( int ) con -> conf. max_write_idle,
101 " seconds. If this a problemincrease server.max-write-idle " );
102 #endif
103 connection_set_state(srv, con, CON_STATE_ERROR);
104 changed = 1 ;
105 }
106 }
107
108 /*
109 * we don't like div by zero 防止除0。。。
110 */
111 if ( 0 == (t_diff = srv -> cur_ts - con -> connection_start))
112 t_diff = 1 ;
113
114 /* *
115 * 下面的if语句不是用来判断连接是否超时。
116 * lighttpd对每个连接设置了一个kbytes_per_second,这个变量设定每个连接在一秒钟内多能传输的最大数据量。
117 * 如果传送的数据大于这个值,那么这个连接将停止传输数据,被追加到作业队列中等待下一次处理。
118 * 作者这样做估计是为了平衡各个连接之间的数据传输。
119 */
120 if (con -> traffic_limit_reached && (con -> conf.kbytes_per_second == 0 || ((con -> bytes_written / t_diff) < con -> conf.kbytes_per_second * 1024 )))
121 {
122 /*
123 * enable connection again
124 */
125 con -> traffic_limit_reached = 0 ;
126 changed = 1 ;
127 }
128
129 if (changed)
130 {
131 connection_state_machine(srv, con);
132 }
133 con -> bytes_written_cur_second = 0 ;
134 * (con -> conf.global_bytes_per_second_cnt_ptr) = 0 ;
135 } // end of for( ndx = 0; ...
136 if (cs == 1 )
137 fprintf(stderr, " \n " );
138 } // end of if (min_ts != srv->cur_ts)...
139 } // end of if (handle_sig_alarm)...
在这个If语句中,作者的本意是通过alarm信号来判断时间是否到一秒种。handle_sig_alarm就是标记是否已经过了一秒钟。在server.c的信号处理函数sigaction_handler()中可以看到:
1 case SIGALRM: // 超时信号
2 handle_sig_alarm = 1 ;
3 break ;
当收到SIGALRM信号时,标记handle_sig_alarm为1。
下面的代码是启动计时器。两段代码都被宏包围。说明需要定义宏USE_ALARM才启动计时器。
1 #ifdef USE_ALARM
2 struct itimerval interval;
3 interval.it_interval.tv_sec = 1 ;
4 interval.it_interval.tv_usec = 0 ;
5 interval.it_value.tv_sec = 1 ;
6 interval.it_value.tv_usec = 0 ;
7 #endif
8 #ifdef USE_ALARM
9 signal(SIGALRM, signal_handler);
10 if (setitimer(ITIMER_REAL, & interval, NULL))
11 {
12 log_error_write(srv, __FILE__, __LINE__, " s " , " setting timer failed " );
13 return - 1 ;
14 }
15 getitimer(ITIMER_REAL, & interval);
16 #endif
下面寻找宏USE_ALARM的定义。仍然在server.c文件中:
1 /*
2 * IRIX doesn't like the alarm based time() optimization
3 */
4 /*
5 * #define USE_ALARM
6 */
不过,这个唯一的定义被注释掉了。。。
那么,也就是说,作者并没有使用计时器产生SIGALRM信号来判断时间是否过了一秒。其实,上面处理连接超时的代码中,作者通过判断当前时间和服务器记录的当前时间来判断时间是否过了一秒。如果两个时间不一样,那么时间就过了一秒。不使用SIGALRM信号,可以减少很多信号处理,降低程序的复杂度。没有使用SIGALRM信号,那么handle_sig_alarm就一直是1。子进程每循环一次都要比较服务器记录的时间和当前时间。
下面继续看超时处理。在上面的处理程序中,lighttpd通过比较read_idle_ts,write_request_ts和当前时间的差值来判断连接是否读超时或写超时。如果这两个差值分别大于max_read_idle和max_write_idle则表示超时。如果一个连接正在处理多个请求时,读超时是和max_keep_alive_idle比较。这些上限值在配置中设置。
那么,read_idle_ts和write_request_ts又是记录的什么呢?
对于read_idle_ts,在连接进入CON_STATE_REQUEST_START状态时,记录了当前时间。如果连接长时间没有去读取request请求,则也表示连接超时。当连接开始读数据时,read_idle_ts记录开始读数据的时间。这个不多说了。
对于write_request_ts,在处理CON_STATE_WRITE状态时,有对其赋值的语句。在connection_handle_fdevent函数中也有。其实,都是在调用connection_handle_write函数出错并且连接处在CON_STATE_WRITE状态时,记录当前时间。
通过这两个变量可以看出,lighttpd对读和写的超时处理是不一样的。对于读,设定了最长时间,不管读多少数据,一旦时间超了就算超时。而对于写,只有在写出错的时候才开始计算超时。如果没有出错,那么写数据花再多的时间也不算超时。这就有一个问题了,如果客户端上传的数据很多呢?这样没上传完就有可能被判断为超时。其实,lighttpd做为一个web服务器,其假设上传的数据都是有限的。在绝大多数情况下,上传数据都是很小的,也就是http头等,而下载的数据往往很多。因此,这样处理可以提高效率。如果需要上传大量数据,可以修改配置中的超时限制。(PS:这点不太确定,望高手讲解。)
lighttpd每过一秒钟就要轮询连接,检查是否超时。如果连接很多时,这将浪费大量的时间。虽然这样很低效,但是处理简单,程序复杂度低。在真正的使用中,效率也没有想像中的那么差。
至此,lighttpd的fdevent系统就介绍完毕了。从下一篇开始,我们将走进lighttpd的状态机。