HDC2021技术分论坛:HarmonyOS内核技术大公开
作者:jikecheng,miaoxie,HarmonyOS内核技术专家
HarmonyOS整体框架分为四个层级,如图1所示。从上到下,依次为:第一层是应用层,主要涵盖系统应用、Launcher、设置,以及三方应用。第二层是框架层,提供基础UI框架、用户程序框架以及能力模块框架。第三层是系统服务层,让HarmonyOS具有分布式流转负载的能力。大家看到的高速多设备协同能力就是由该层级提供。
而承载整个操作系统,同时发挥芯片算力的基石就沉淀在第四层——内核层。宏观来说,内核的主要工作包含芯片资源管理、软件任务调度,以及衔接用户空间与系统调用能力。
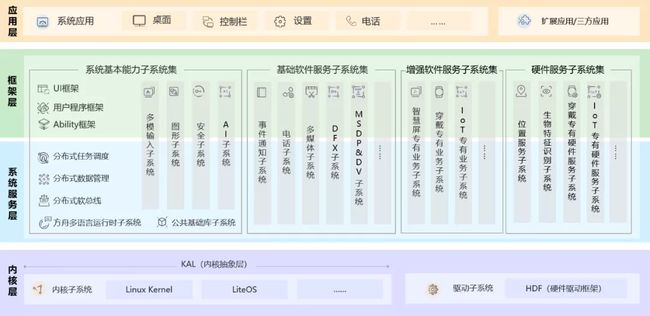
图1 HarmonyOS整体框架
本期,我们要重点给大家讲一讲HarmonyOS的内核层。
目录
一、HarmonyOS内核构成
二、高能效CPU资源调度
三、Hyperhold内存管理引擎
四、高效的文件系统
五、未来演进方向
一、HarmonyOS内核构成
为了支撑HarmonyOS在多设备、多场景下的性能表现,内核主要由三部分组成,如下图所示:
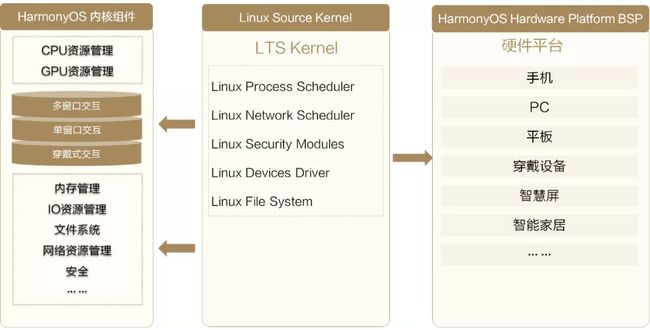
图2 内核的组成
- HarmonyOS内核组件:具有智慧化资源管理能力的内核组件,包括CPU/GPU资源管理,内存管理,IO调度管理以及高效的文件系统等。
- 标准的Linux内核:兼容了LTS Linux主线版本,做好外围生态的对接。
- 硬件平台BSP:面向各种不同芯片与硬件平台(包含1+8+N的多种设备)的BSP(board support package,板级支撑包)基础能力。
本期要为大家介绍的就是HarmonyOS内核组件的三项核心技术:高能效CPU资源调度、Hyperhold内存管理引擎和高效的文件系统。下面为大家一一揭晓~
二、高能效CPU资源调度
业界多数的操作系统都是基于标准的Linux内核开发的。传统的Linux内核,早期用于服务器和PC设备,与我们现在用于手机、平板等的交互式内核相比,它们的设计理念和资源管理方式有所不同。以CPU资源为例,传统的Linux内核存在以下典型问题:
1. 同优先级的业务过多,每次调度都不一定选择到关键进程。
传统的Linux内核偏向于在多用户的场景下公平地分配资源。比较明显的特征是,多个用户并发访问,并发使用公共资源。由于同优先级的业务比较多,每次任务调度不一定能够选择到关键进程。举个例子,当设备后台存在多个应用或者服务任务时,系统中和用户交互最敏感的渲染任务没法即时得到调度资源,导致设备会高概率出现使用不流畅或者点击无响应的现象,也就是咱们平时常说的随机卡顿。
2. 选择最优能效的CPU资源时间过长,CPU资源选择过度。
传统的Linux内核选择算力的流程,是一个慢速爬坡的过程。任务调度必须经过选择CPU核簇、负载均衡、选择频点等一系列流程。其漫长的过程,极易导致任务调度错过调度窗口,出现算力供给不足的现象。
为了解决以上问题,HarmonyOS内核提供了全栈式的调度框架,如下图所示:
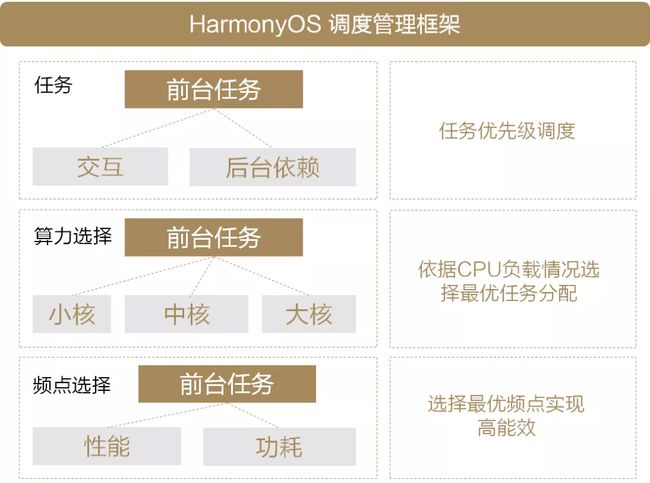
图3 HarmonyOS调度管理框架
HarmonyOS调度管理框架有以下特点:
● 任务按优先级调度
对现有系统任务进行严格级别划分,在线标记与用户的操作体验直接相关的关键进程和关联任务,优先调度关键任务。
● 依据CPU负载情况选择最优任务分配
我们会动态检测不同CPU的负载,保证当前CPU有足够的算力提供。
● 选择最优频点实现高能效
我们提供了频点与性能、功耗之间的帕累托最优模型。每次任务,我们都能够快速选择系统最优的频点组合方式,实现最优能效。
经过试验,HarmonyOS的全栈式调度框架可以帮助用户获得在多场景(尤其是游戏场景)下持续且稳定的高帧率体验。
三、Hyperhold内存管理引擎
对于内存管理,由于开源生态的不限制,导致应用开发的内存使用野蛮生长。设备长时间使用后,可回收内存越来越低。产生这个问题的原因有两个:
1. 传统内存数据冷热管理,无法感知业务特性
尽管Linux内核提供了很多的内存回收机制,然而每种内存回收都会有相应的系统代价。比如,回收文件页面后,如果系统需要二次加载这部分数据,需要从底层器件Flash里面把数据读回来,这会引起Flash随机IO读的现象。对IO操作来说,Flash器件速度和当前读取任务是随机读还是顺序读有着很强的相关性,随机读容易导致系统随机卡顿。再比如,回收匿名页面后,如果系统需要二次加载这部分数据,会触发ZRAM解压,消耗CPU。
另外,由于应用的内存负载越来越重,当系统冷热数据识别不恰当,会导致系统的CPU负载长期处于高负载状态,最终影响前台应用的基础性能。
2. 传统共享式内存分配,无法感知数据重要性
从内存分配角度看,现在的操作系统基本采用统一接口的分配方式,使得手机里面多个进程或多个业务会共用一块内存区域。数据回收时,会频繁出现数据搬移,以及内存震荡的现象。这个现象会加重内核管理内存的开销。
为了解决传统Linux内核的内存问题,HarmonyOS提供了Hyperhold内存管理引擎。Hyperhold内存管理引擎打通了上层系统到内核的调用栈,让内核完整感知到应用的整个生命周期,并结合应用生命周期以及周期内的数据访问特征,对每一块内存数据做合理的内存管理。同时,为了降低内核管理内存的开销,我们提出了自研的压缩体系,包括多线程压缩、自研的压缩算法。为了进一步扩大可用空间,我们在Flash器件上开出了一块可交换区,结合自研的聚合换出和内存标记技术,充分利用Flash器件的性能。

图4 Hyperhold内存管理引擎
经过试验, Hyperhold内存管理引擎可以让应用在后台的驻留能力提升50%以上,用户可以明显感知到后台应用的保活率有大幅提升。
四、高效的文件系统
存储处于整个缓存体系下的最慢路径,容易成为系统性能瓶颈。不仅如此,由于存储器件碎片化的问题,存储还容易出现越用越慢的难题。其次,随着系统的发展,系统占用存储越来越多。而在多设备流转的场景下,分布式文件系统的高效转存能力显得尤为重要。
为应对上述问题,HarmonyOS提供了高效的自研文件系统体系。从第一代的eF2FS到最新的HMDFS,文件系统逐步解决了碎片化问题、容量问题与多设备流转问题。

图5 HarmonyOS文件系统
下面我们从第一代的eF2FS到最新的HMDFS,依次介绍HarmonyOS文件系统的技术特点。
1. 第1代数据盘eF2FS:智能感知空间管理,改善越用越慢
面对存储越用越慢的业界难题,我们通过数据类型感知的多流算法和空间感知的分配算法,减少碎片产生。同时,通过高效、业务感知的两层智能垃圾空间回收,实现智能感知空间管理。
下面我们通过一个动图,更好地了解HarmonyOS的空间管理机制。
2. 系统盘EROFS:变长压缩,支持压缩与性能双赢
针对系统占用存储越来越多的问题,业界其他操作系统也采取过改进措施,比如squashfs采用“定长输入,变长输出”的压缩策略,但会存在读放大的问题。而我们的EROFS(Extendable Read-Only File System,超级文件系统)采用“变长输入,定长输出”的压缩策略,尽可能地将不等长的文件块压缩成一个等长的存储块进行存储。这样,我们访问任何文件块,只需读取一个存储块,减少了无效读取。除此之外,我们在解压性能和IO流程上也做了优化。
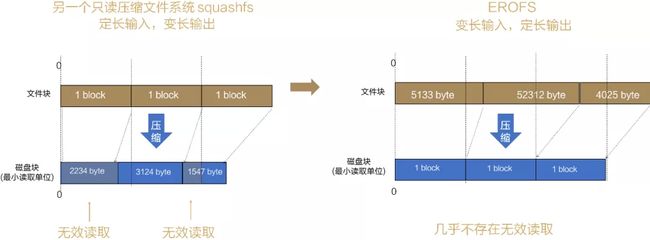
图6 系统盘EROFS的变长压缩
通过以上关键技术,系统盘EROFS的性能得到大幅提升:
- 随机读性能平均提升20%。
- 系统初始空间相比Ext4节省2GB,相当于用户可以多存1000张照片或500首歌曲。
- 升级包大小下降约5%-10%,升级时间缩短约20%。
3. 跨设备HMDFS:“批流”结合的分布式文件系统
HarmonyOS同一套系统能力、适配多种终端形态的分布式理念,就要求我们有一套数据流转的底座——分布式文件系统HMDFS。
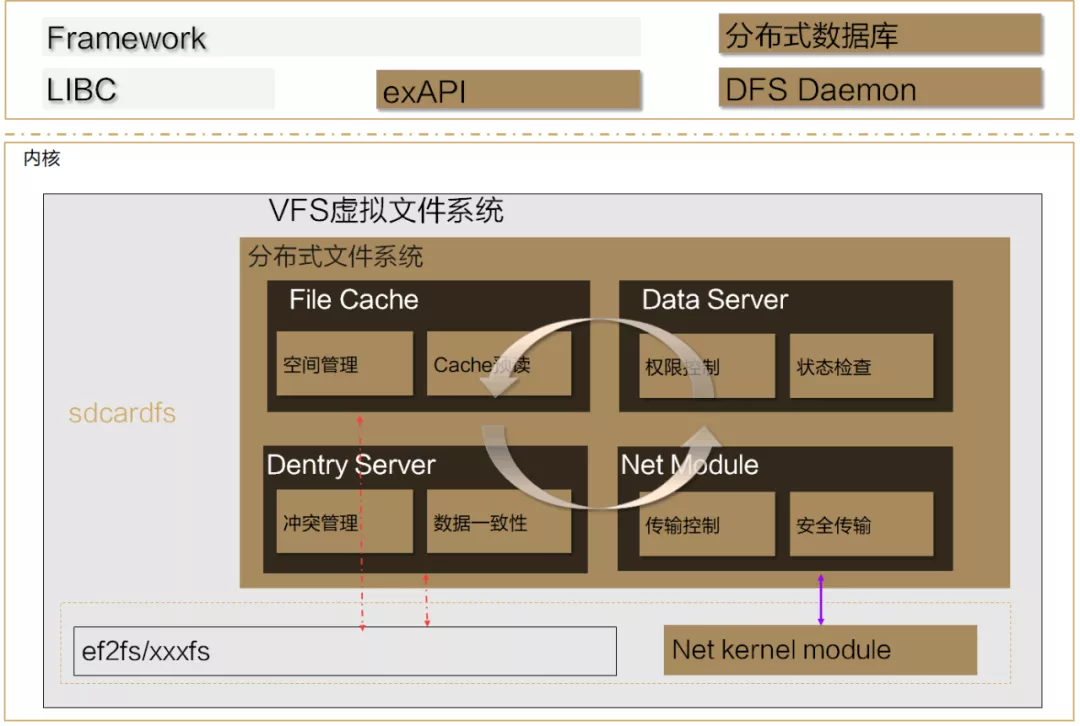
图7 HMDFS
应对多设备流转,HMDFS提供了多种文件系统能力,包括:
- 文件类型聚合
- 高效的缓存管理
- 批处理接口
- 分布式的权限管控
- 高效传输
- 数据一致性管理
通过上述一系列技术的研发与集成,最终实现了现有的跨设备高效文件系统,为用户提供流畅的分布式体验。
五、未来演进方向
上面就是我们本期要介绍的HarmonyOS内核核心技术内容了。未来还有很多方向值得我们继续探索,下图列出了HarmonyOS内核的未来演进方向。

图8 未来演进方向
相信经过我们不断的探索,我们能打造出更好的内核,为大家提供更流畅、体验更好的HarmonyOS!

扫码添加开发者小助手微信
获取更多HarmonyOS开发资源和开发者活动资讯