实时数据仓库-从0到1实时数据仓库设计&实现(SparkStreaming3.x)
简介
从数据库的设计,到前端,后端,实时数据仓库一套打通实时数据仓库设计与实现,这个项目的特点就是,麻雀虽小,五脏俱全,一般的实时数据仓库复制粘贴里面的代码就能够实现功能。
数据流程图

需求
利用学生的好强心理,促进学生的好学的习惯,设计这一套全国各地区毕业学生成绩贡献总分数统计,最后按各地区学生所得总分排名(学生提交每一课最优的成绩)
代码
前期web应用开发
springboot,mybatis-plus,mysql,html,js
表设计

资源地址
链接:https://pan.baidu.com/s/1bWf6rEPMBKvY3wZbsNLtUA
提取码:yyds
先启动springboot然后才能得到html里面的数据
效果图
数据流程,点击 提交->springboot->mysql

表
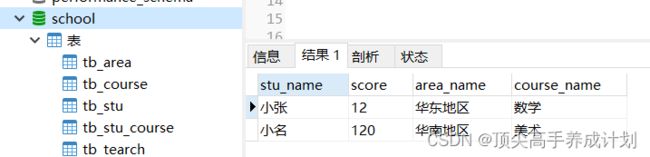
查询保存数据的语句
select stu_name,score,area_name,course_name from tb_stu
LEFT JOIN tb_area
ON tb_stu.area_code=tb_area.area_code
LEFT JOIN tb_stu_course ON
tb_stu.id = tb_stu_course.stu_id
LEFT JOIN tb_course
ON tb_stu_course.course_id=tb_course.id
LEFT JOIN tb_tearch
ON tb_course.teacher_id=tb_tearch.id
数据仓库建设
数据采集
前提安装了kafka
在我kafka的专栏里面有
开启mysql的binlog
vi /etc/my.cnf[mysqld]
server-id = 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=school使用maxwell采集mysql
tar -zxvf maxwell-1.25.0.tar.gz创建位置保存的数据库
mysql -uroot -p123456
CREATE DATABASE schoolmaxwell;
#maxwell是用戶名
GRANT ALL ON schoolmaxwell.* TO 'maxwell'@'%' IDENTIFIED BY '123456';
#maxwell是用戶名
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';修改配置
cp config.properties.exampleproducer=kafka
kafka.bootstrap.servers=master:9092,node1:9092,node2:9092
#需要添加
kafka_topic=school_db
#mysql
#数据库host
host=master
#数据库用户
user=maxwell
#数据库密码
password=123456
#需要添加 后续bootstrap初始化会用
client_id=maxwell_1
#指定消费位置保存的数据库
schema_database=shishimaxwell测试是否可用
初始化表
/home/bigdata/conglingdaoyi/maxwell/maxwell-1.25.0/bin/maxwell --config /home/bigdata/conglingdaoyi/maxwell/maxwell-1.25.0/config.properties
同步数据到kafka(能使用下面命令的前提是先启动了maxwell)
bin/maxwell-bootstrap --user maxwell --password 123456 --host master --database school --table tb_stu --client_id maxwell_1./kafka-topics.sh --bootstrap-server master:9092 --list![]()
消费主题
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic school_db 下面是采集到的数据例子
ODS层
读取kafka里面的数据进行分流处理得到ods
精准一次性 消费
pom.xml
org.apache.spark
spark-core_2.12
3.0.0
org.apache.spark
spark-sql_2.12
3.0.0
org.apache.spark
spark-streaming_2.12
3.0.0
org.apache.spark
spark-streaming-kafka-0-10_2.12
3.0.0
com.fasterxml.jackson.core
jackson-core
2.10.1
redis.clients
jedis
4.2.0
org.apache.logging.log4j
log4j-to-slf4j
2.11.0
com.alibaba
fastjson
1.2.62
org.elasticsearch
elasticsearch
7.12.1
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.12.1
org.projectlombok
lombok
1.18.24
org.apache.phoenix
phoenix-spark
5.0.0-HBase-2.0
org.glassfish
javax.el
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
org.apache.maven.plugins
maven-shade-plugin
2.4.3
shade-my-jar
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.zhang.realtime.app.app.SparkStreamKafkaOfferset
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
配置文件
log4j.properties
log4j.appender.atguigu.MyConsole=org.apache.log4j.ConsoleAppender
log4j.appender.atguigu.MyConsole.target=System.out
log4j.appender.atguigu.MyConsole.layout=org.apache.log4j.PatternLayout
log4j.appender.atguigu.MyConsole.layout.ConversionPattern=%d{yyyy-MM-ddHH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger =errorhbase-site.xml
hbase.regionserver.wal.codec
org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
phoenix.schema.isNamespaceMappingEnabled
true
phoenix.schema.mapSystemTablesToNamespace
true
config.properties
# Kafka
kafka.broker.list=master:9092,node1:9092,node2:9092
# Redis
redis.host=node1
redis.port=6379工具类
PhoenixUtil
object PhoenixUtil {
def queryList(sql: String): List[JSONObject] = {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver")
val resultList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]()
val conn: Connection =
DriverManager.getConnection("jdbc:phoenix:master,node1,node2:2181")
val stat: Statement = conn.createStatement
println(sql)
val rs: ResultSet = stat.executeQuery(sql)
val md: ResultSetMetaData = rs.getMetaData
while (rs.next) {
val rowData = new JSONObject();
for (i <- 1 to md.getColumnCount) {
rowData.put(md.getColumnName(i), rs.getObject(i))
}
resultList += rowData
}
stat.close()
conn.close()
resultList.toList
}
}OffsetManagerUtil
object OffsetManagerUtil {
//得到配置文件类
val properties: Properties = MyPropertiesUtil.load("config.properties")
//获取redis的连接池
val jedisPool = new JedisPool(properties.getProperty("redis.host"), properties.getProperty("redis.port").toInt)
/**
*
* @param topic 要保存的主题
* @param groupName 消费者组
* @param offsetRanges kafkaInputDStream的父类HasOffsetRanges里面有记录每一个分区从哪里消费fromOffset,消费到哪里untilOffset
*/
def saveOffset(topic:String,groupName:String,offsetRanges:Array[OffsetRange]): Unit = {
if(offsetRanges!=null&&offsetRanges.length>0){
//得到连接
val jedisClient: Jedis = jedisPool.getResource
//申明最后得到的hash的key,"offset:"+topic+":"+groupName
val offsetHashKey="offset:"+topic+":"+groupName
val offsetMap = new mutable.HashMap[String, String]()
for (elem <- offsetRanges) {
//消费的分区
val partition: Int = elem.partition
//消费的这个分区的下一次消费开始的偏移量
val untilOffset: Long = elem.untilOffset
//分区为kay,下一次开始的偏移量为value,开始使用latest的时候fromOffset和untilOffset的值是一样的,untilOffset – Exclusive ending offset
println(elem.fromOffset.toString+" "+untilOffset.toString)
offsetMap.put(partition.toString,untilOffset.toString)
}
//java集合装换成scala集合的隐私装换
import scala.collection.JavaConverters._
//redis如果保存的map为空那么会报错
if(!offsetMap.isEmpty){
jedisClient.hmset(offsetHashKey,offsetMap.asJava)
}
jedisPool.returnResource(jedisClient)
}
}
/**
* 得到对应主题的消费起始偏移量
* @param topic 主题
* @param groupName 消费者组名
* @return
*/
def getOfferSet(topic: String, groupName: String): mutable.Map[TopicPartition, Long] = {
val jedisClient: Jedis = jedisPool.getResource
//根据主题名,还有消费者组名得到上一次消费的分区
val offsetHashKey="offset:"+topic+":"+groupName
val result: util.Map[String, String] = jedisClient.hgetAll(offsetHashKey)
//得到偏移量的信息之后把连接返回连接池
jedisPool.returnResource(jedisClient)
val target: mutable.Map[TopicPartition, Long] = collection.mutable.Map[TopicPartition, Long]()
result.entrySet().forEach(
entry=>{
val partition: String = entry.getKey
val partitionOffset: String = entry.getValue
val temp: TopicPartition =new TopicPartition(topic,partition.toInt)
target.put(temp,partitionOffset.toLong)
}
)
target
}
}MyPropertiesUtil
object MyPropertiesUtil {
/**
* 测试加载配置信息
* @param args
*/
def main(args: Array[String]): Unit = {
val properties: Properties = MyPropertiesUtil.load("config.properties")
println(properties.getProperty("kafka.broker.list"))
}
/**
* 加载配置文件
* @param propertieName
* @return
*/
def load(propertieName:String): Properties ={
val prop=new Properties();
prop.load(new
InputStreamReader(Thread.currentThread().getContextClassLoader.
getResourceAsStream(propertieName) , "UTF-8"))
prop
}
}MyKafkaUtil
object MyKafkaUtil {
//读取配置文件
val properties: Properties = MyPropertiesUtil.load("config.properties")
//sparkstreaming消费kafka的kafka参数
private val kafkaParams = collection.immutable.Map[String, Object](
//kafka的服务节点
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> properties.getProperty("kafka.broker.list"),
//kafka的key序列化解码器
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
//kafka的value序列化解码器
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
//消费者组id
ConsumerConfig.GROUP_ID_CONFIG -> "use_a_separate_group_id_for_each_stream",
//起始消费的位置
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest",
//是否自动提交
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> (false: java.lang.Boolean)
)
/**
* 根据提供的主题消费
*
* @param topic 指定消费的主题
* @param streamingContext SparkStreamingContext
* @return
*/
def getInputDStreamByDefault(topic: String, streamingContext: StreamingContext): InputDStream[ConsumerRecord[String, String]] = {
val topics = Array(topic)
KafkaUtils.createDirectStream[String, String](
streamingContext,
//PreferBrokers表示Executor和kafka的Broker在一个节点的时候使用
//PreferConsistent 尽量均衡的把分区放到Executor上面执行 (常用)
//PreferFixed 指定分区由哪个主机去消费
PreferConsistent,
//Subscribe 根据主题进行消费,Assign,指定主题分区进行消费
Subscribe[String, String](topics, kafkaParams)
)
}
/**
*
* @param topic 指定消费的主题
* @param offsetRange Map[TopicPartition, Long] 指定主题对应分区的偏移量进行消费
* @param streamingContext SparkStreamingContext
* @return
*/
def getInputDStreamByMapTopicPartition(topic: String, offsetRange: mutable.Map[TopicPartition, Long], streamingContext: StreamingContext): InputDStream[ConsumerRecord[String, String]] = {
val topics = Array(topic)
KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams, offsetRange)
)
}
}MyKafkaSinkUtil
object MyKafkaSinkUtil {
private val properties: Properties = MyPropertiesUtil.load("config.properties")
val broker_list = properties.getProperty("kafka.broker.list")
var kafkaProducer: KafkaProducer[String, String] = null
def createKafkaProducer: KafkaProducer[String, String] = {
val properties = new Properties
properties.put("bootstrap.servers", broker_list)
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer")
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer")
properties.put("enable.idempotence",(true: java.lang.Boolean))
var producer: KafkaProducer[String, String] = null
try
producer = new KafkaProducer[String, String](properties)
catch {
case e: Exception =>
e.printStackTrace()
}
producer
}
def send(topic: String, msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic, msg))
}
def send(topic: String,key:String, msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic,key, msg))
}
}分流App
SchoolAppStart
object SchoolAppStart {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//这里的partition的数目要和kafka的分区数一致
conf.setAppName(this.getClass.getSimpleName).setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(1))
val topicName = "school_db"
val groupName = "test"
//在程序启动的时候获取偏移量
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topicName, groupName)
var kafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
//是否能够得到偏移量,有就根据得到的偏移量消费消息
if (offset != null && offset.size > 0) {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topicName, offset, ssc)
} else {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByDefault(topicName, ssc)
}
//通过装换成HasOffsetRanges得到Array[OffsetRange],才能拿到下一次消费的开始偏移量untilOffset
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val transformDStream: DStream[ConsumerRecord[String, String]] = kafkaInputDStream.transform(
rdd => {
val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
offsetRanges = ranges.offsetRanges
rdd
}
)
val kafkaValue: DStream[String] = transformDStream.map(_.value())
// 由于得到的数据入下面
// {"database":"school","table":"tb_stu","type":"bootstrap-start","ts":1657768898,"data":{}}
// {"database":"school","table":"tb_stu","type":"bootstrap-insert","ts":1657768898,"data":{"id":"ea26cc","stu_name":"小张","area_code":"0001"}}
// {"database":"school","table":"tb_stu","type":"bootstrap-insert","ts":1657768898,"data":{"id":"e8e4ee","stu_name":"小名","area_code":"0002"}}
// {"database":"school","table":"tb_stu","type":"bootstrap-complete","ts":1657768898,"data":{}}
//先对school_db数据进行分流
val distrubeRes: DStream[JSONObject] = kafkaValue.mapPartitions(iter => {
//保存好的结果
val res: ListBuffer[JSONObject] = ListBuffer[JSONObject]()
for (elem <- iter) {
val kafkaValueJson: JSONObject = JSON.parseObject(elem)
val tableName: String = kafkaValueJson.getString("table")
val dataJson: JSONObject = kafkaValueJson.getJSONObject("data")
val maxwellType: String = kafkaValueJson.getString("type")
if (dataJson != null && !dataJson.isEmpty) {
//分流到kafka
dataJson.put("maxwelltype", maxwellType)
dataJson.put("tableName",tableName)
res.append(dataJson)
}
}
res.iterator
})
distrubeRes.foreachRDD(rdd=>{
rdd.foreach(item=>{
val tableName: String = item.getString("tableName")
item.remove("tableName")
val resTopic="ods_"+tableName
MyKafkaSinkUtil.send(resTopic,item.toString)
})
//如果都操作完了这里就是保存偏移量
OffsetManagerUtil.saveOffset(topicName, groupName, offsetRanges)
// 手动提交kafka的偏移量
kafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}ods结果

里面的数据为例子
{"maxwelltype":"bootstrap-insert","id":"2","tearch_name":"小张老师"}case class TbTearch(
id:String,
tearchName:String
)驼峰命名可以直接装换
JSON.toJavaObject(JSON.parseObject(kafkaValueItem), classOf[TbTearch])工程结构
 DIM层
DIM层
由于我们的功能是,个个地区实时学生共享优异成绩统计,所以我们可以用ods_tb_tearch,ods_tb_course,ods_tb_area 我们选用教师,课程,地区作为维度分析
维度表我们选用hbase作为存储,优点,海量,快速
先创建教师维度表
create table school_dim_tb_tearch (id varchar primary key ,tearch_name varchar) SALT_BUCKETS = 3;
保存到PhoenixApp
DimTbTearch
object DimTbTearch {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("BaseTrademarkApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_tb_tearch";
val groupId = "dim_ods_tb_tearch"
/ 偏移量处理///
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topic,
groupId)
var inputDstream: InputDStream[ConsumerRecord[String, String]] = null
// 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用
if (offset != null && offset.size > 0) {
inputDstream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topic, offset, ssc)
} else {
inputDstream = MyKafkaUtil.getInputDStreamByDefault(topic, ssc)
}
//取得偏移量步长
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
inputDstream.transform {
rdd =>{
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
val objectDstream: DStream[TbTearch] = inputGetOffsetDstream.map {
record =>{
val jsonStr: String = record.value()
val obj: TbTearch = JSON.parseObject(jsonStr, classOf[TbTearch])
obj
}
}
import org.apache.phoenix.spark._
//保存到 Hbase
objectDstream.foreachRDD{rdd=>
rdd.cache()
rdd.saveToPhoenix("SCHOOL_DIM_TB_TEARCH",Seq("ID", "TEARCH_NAME" )
,new Configuration,Some("192.168.66.20,192.168.66.10,192.168.66.21:2181"))
rdd.foreach(println)
OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges)
}
ssc.start()
ssc.awaitTermination()
}
}启动以后执行
bin/maxwell-bootstrap --user maxwell --password 123456 --host master --database school --table tb_tearch --client_id maxwell_1结果

kafka监听
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic ods_tb_tearchDimTbCourse
得到主题结果
bin/maxwell-bootstrap --user maxwell --password 123456 --host master --database school --table tb_course --client_id maxwell_1./kafka-console-consumer.sh --bootstrap-server master:9092 --topic ods_tb_course{"maxwelltype":"bootstrap-insert","course_name":"美术","teacher_id":"1","id":"5"}创建对应的对象
case class TbCourse(
id:String,
course_name:String,
teacher_id:String
)创建Phoneix表
create table school_dim_tb_course (id varchar primary key ,tearch_id varchar,course_name varchar) SALT_BUCKETS = 3;select * from SCHOOL_DIM_TB_COURSE;

app
object DimTbCourse {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("BaseTrademarkApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_tb_course";
val groupId = "dim_ods_tb_stu_course"
/ 偏移量处理///
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topic,
groupId)
var inputDstream: InputDStream[ConsumerRecord[String, String]] = null
// 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用
if (offset != null && offset.size > 0) {
inputDstream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topic, offset, ssc)
} else {
inputDstream = MyKafkaUtil.getInputDStreamByDefault(topic, ssc)
}
//取得偏移量步长
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
inputDstream.transform {
rdd =>{
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
val objectDstream: DStream[TbCourse] = inputGetOffsetDstream.map {
record =>{
val jsonStr: String = record.value()
val obj: TbCourse = JSON.parseObject(jsonStr, classOf[TbCourse])
obj
}
}
import org.apache.phoenix.spark._
//保存到 Hbase
objectDstream.foreachRDD{rdd=>
rdd.cache()
rdd.saveToPhoenix("SCHOOL_DIM_TB_COURSE",Seq("ID", "COURSE_NAME","TEARCH_ID" )
,new Configuration,Some("192.168.66.20,192.168.66.10,192.168.66.21:2181"))
rdd.foreach(println)
OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges)
}
ssc.start()
ssc.awaitTermination()
}
}DimTbArea
bin/maxwell-bootstrap --user maxwell --password 123456 --host master --database school --table tb_area --client_id maxwell_1{"area_name":"华东地区","maxwelltype":"bootstrap-insert","area_code":"0001","id":"1"}
{"area_name":"华南地区","maxwelltype":"bootstrap-insert","area_code":"0002","id":"2"}
{"area_name":"华北地区","maxwelltype":"bootstrap-insert","area_code":"0003","id":"3"}创建对应的Json对应的类
case class TbAear(
id:String,
areaCode:String,
areaName:String
)创建Phoenix表
create table school_dim_tb_area (id varchar primary key ,area_name varchar,area_code varchar) SALT_BUCKETS = 3;select * from SCHOOL_DIM_TB_AREA;
app
object DimTbArea {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("DimTbArea")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_tb_area";
val groupId = "dim_ods_tb_area"
/ 偏移量处理///
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topic,
groupId)
var inputDstream: InputDStream[ConsumerRecord[String, String]] = null
// 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用
if (offset != null && offset.size > 0) {
inputDstream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topic, offset, ssc)
} else {
inputDstream = MyKafkaUtil.getInputDStreamByDefault(topic, ssc)
}
//取得偏移量步长
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
inputDstream.transform {
rdd =>{
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
val objectDstream: DStream[TbAear] = inputGetOffsetDstream.map {
record =>{
val jsonStr: String = record.value()
val obj: TbAear = JSON.parseObject(jsonStr, classOf[TbAear])
obj
}
}
import org.apache.phoenix.spark._
//保存到 Hbase
objectDstream.foreachRDD{rdd=>
rdd.cache()
rdd.saveToPhoenix("SCHOOL_DIM_TB_AREA",Seq("ID", "AREA_CODE","AREA_NAME" )
,new Configuration,Some("192.168.66.20,192.168.66.10,192.168.66.21:2181"))
rdd.foreach(println)
OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges)
}
ssc.start()
ssc.awaitTermination()
}
}dim层结果
select * from SCHOOL_DIM_TB_AREA;
select * from SCHOOL_DIM_TB_COURSE;
select * from SCHOOL_DIM_TB_TEARCH;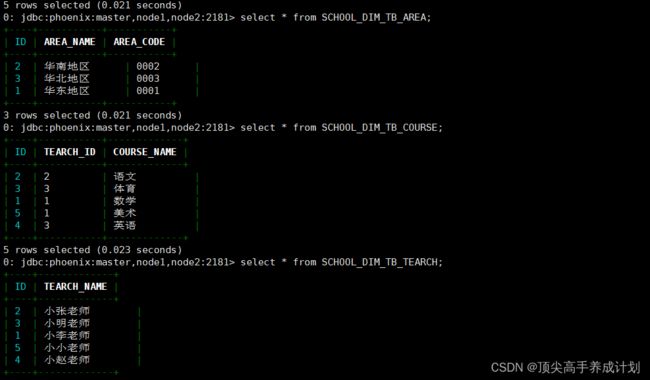
DWD层
DwdTbStu
获取数据
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic ods_tb_stu点击提交
得到的数据
{"maxwelltype":"insert","area_code":"0001","stu_name":"12","id":"fd4fa5"}![]()
开始处理ods_tb_stu里面的数据
- 第一步 先得到所有的地区数据然后变成RDD对象
- 然后和ods_tb_stu里面的数据进行join得到DWD的事实表数据
实现代码
object DwdTbStu {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//这里的partition的数目要和kafka的分区数一致
conf.setAppName(this.getClass.getSimpleName).setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(1))
val topicName = "ods_tb_stu"
val groupName = "test"
//在程序启动的时候获取偏移量
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topicName, groupName)
var kafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
//是否能够得到偏移量,有就根据得到的偏移量消费消息
if (offset != null && offset.size > 0) {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topicName, offset, ssc)
} else {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByDefault(topicName, ssc)
}
//通过装换成HasOffsetRanges得到Array[OffsetRange],才能拿到下一次消费的开始偏移量untilOffset
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val transformDStream: DStream[ConsumerRecord[String, String]] = kafkaInputDStream.transform(
rdd => {
val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
offsetRanges = ranges.offsetRanges
rdd
}
)
val kafkaValue: DStream[String] = transformDStream.map(_.value())
val allAear: List[JSONObject] = PhoenixUtil.queryList("select * from SCHOOL_DIM_TB_AREA")
val resAllAear: List[(String, String)] = allAear.map(allAearItem => {
(allAearItem.getString("AREA_CODE"), allAearItem.getString("AREA_NAME"))
})
//得到地区的RDD
val aearRDD: RDD[(String, String)] = ssc.sparkContext.parallelize(resAllAear)
val aearKeyAndTbstuValue: DStream[(String, TbStu)] = kafkaValue.mapPartitions(iter => {
val res: ListBuffer[(String, TbStu)] = ListBuffer[(String, TbStu)]()
for (elem <- iter) {
val targetTbStu: TbStu = JSON.toJavaObject(JSON.parseObject(elem), classOf[TbStu])
res.append((targetTbStu.areaCode, targetTbStu))
}
res.iterator
})
//对于得到的Stu数据和aearBroadCast进行Join操作
val res: DStream[TbStu] = aearKeyAndTbstuValue.transform(rdd => {
val res: RDD[(String, (TbStu, Option[String]))] = rdd.leftOuterJoin(aearRDD)
res.map(item => {
val tbStu: TbStu = item._2._1
val aearName: Option[String] = item._2._2
tbStu.aearName = aearName.getOrElse("")
tbStu
})
})
//这里是得到的结果
res.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>{
for (tbStuItem <- iter) {
val tbStuItemJSONString: String = JSON.toJSONString(tbStuItem,JSON.DEFAULT_GENERATE_FEATURE)
MyKafkaSinkUtil.send("dwd_tb_stu",tbStuItemJSONString)
}
})
//按分区对于Stu的地区进行赋值
//如果都操作完了这里就是保存偏移量
OffsetManagerUtil.saveOffset(topicName, groupName, offsetRanges)
// 手动提交kafka的偏移量
kafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}查看得到的数据
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic dwd_tb_stu点击提交以后

得到数据
{"aearName":"华北地区","areaCode":"0003","id":"52f31b","stuName":"同学你好"}可以看到ods_tb_stu和维度数据进行了匹配
Scala对象装换成JSON
case class TbStu(
@BeanProperty id: String,
@BeanProperty areaCode: String,
@BeanProperty stuName: String,
@BeanProperty var aearName: String
) val tbStuItemJSONString: String = JSON.toJSONString(tbStuItem,JSON.DEFAULT_GENERATE_FEATURE)DwdTbStuCourse
object DwdTbStuCourse {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//这里的partition的数目要和kafka的分区数一致
conf.setAppName(this.getClass.getSimpleName).setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(1))
val topicName = "ods_tb_stu_course"
val groupName = "test"
//在程序启动的时候获取偏移量
val offset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(topicName, groupName)
var kafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
//是否能够得到偏移量,有就根据得到的偏移量消费消息
if (offset != null && offset.size > 0) {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByMapTopicPartition(topicName, offset, ssc)
} else {
kafkaInputDStream = MyKafkaUtil.getInputDStreamByDefault(topicName, ssc)
}
//通过装换成HasOffsetRanges得到Array[OffsetRange],才能拿到下一次消费的开始偏移量untilOffset
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val transformDStream: DStream[ConsumerRecord[String, String]] = kafkaInputDStream.transform(
rdd => {
val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
offsetRanges = ranges.offsetRanges
rdd
}
)
val kafkaValue: DStream[String] = transformDStream.map(_.value())
val dim_course: List[JSONObject] = PhoenixUtil.queryList("select * from SCHOOL_DIM_TB_COURSE")
val dim_tearch: List[JSONObject] = PhoenixUtil.queryList("select * from SCHOOL_DIM_TB_TEARCH")
val tempDim_course: List[(String, JSONObject)] = dim_course.map(item => {
val tearchId: String = item.getString("TEARCH_ID")
(tearchId, item)
})
val tempDim_tearch: List[(String, String)] = dim_tearch.map(item => {
val tearchId: String = item.getString("ID")
(tearchId, item.getString("TEARCH_NAME"))
})
val tempDim_courseRDD: RDD[(String, JSONObject)] = ssc.sparkContext.parallelize(tempDim_course)
val tempDim_tearchRDD: RDD[(String, String)] = ssc.sparkContext.parallelize(tempDim_tearch)
val courseAndTearchName: RDD[(String, (String, JSONObject))] = tempDim_tearchRDD.join(tempDim_courseRDD)
val dim_res: RDD[(String, (String, String))] = courseAndTearchName.map(item => {
val course: JSONObject = item._2._2
val courseId: String = course.getString("ID")
val courseName: String = course.getString("COURSE_NAME")
val teachName: String = item._2._1
val res: (String, (String, String)) = (courseId, (courseName, teachName))
res
})
dim_res.cache()
// (2,(语文,小张老师))
// (1,(数学,小李老师))
// (5,(美术,小李老师))
// (3,(体育,小明老师))
// (4,(英语,小明老师))
// kafkaValue
// {"stu_id":"0d1269","course_id":"2","score":"120","maxwelltype":"insert","id":"8bc0ed"}
val targetTbStuCourse: DStream[(String, TbStuCourse)] = kafkaValue.map(item => {
val tbStuCourseItem: TbStuCourse = JSON.toJavaObject(JSON.parseObject(item), classOf[TbStuCourse])
(tbStuCourseItem.courseId, tbStuCourseItem)
})
val res: DStream[TbStuCourse] = targetTbStuCourse.transform(rdd => {
val res: RDD[(String, (TbStuCourse, (String, String)))] = rdd.join(dim_res)
res.map(item => {
val tbStuCourse: TbStuCourse = item._2._1
val courseNameAndTearchName: (String, String) = item._2._2
tbStuCourse.courseName = courseNameAndTearchName._1
tbStuCourse.tearchName = courseNameAndTearchName._2
tbStuCourse
})
})
res.foreachRDD(rdd => {
rdd.foreach(item => {
val resjson: String = JSON.toJSONString(item,JSON.DEFAULT_GENERATE_FEATURE)
MyKafkaSinkUtil.send("dwd_tb_stu_course",resjson)
})
//如果都操作完了这里就是保存偏移量
OffsetManagerUtil.saveOffset(topicName, groupName, offsetRanges)
// 手动提交kafka的偏移量
kafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}查看得到的数据为
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic dwd_tb_stu_course{"courseId":"2","courseName":"语文","id":"d2f9f4","score":"120","stuId":"cbb80e","tearchName":"小张老师"}DWS层
双流join
DwsStuScoreJoin
object DwsStuScoreJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//这里的partition的数目要和kafka的分区数一致
conf.setAppName(this.getClass.getSimpleName).setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(1))
// 分别读取两条流
val stuCourseTopicName = "dwd_tb_stu_course"
val stuCourseGroupName = "dwd_tb_stu_course"
val stuTopicName = "dwd_tb_stu"
val stuGroupName = "dwd_tb_stu"
//得到dwd_tb_stu_course的DStream
val stuCourseOffset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(stuCourseTopicName, stuCourseGroupName)
var stuCourseKafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
if (stuCourseOffset != null && stuCourseOffset.size > 0) {
stuCourseKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByMapTopicPartition(stuCourseTopicName, stuCourseOffset, ssc)
} else {
stuCourseKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByDefault(stuCourseTopicName, ssc)
}
var stuCourseOffsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val stuCourseTransformDStream: DStream[ConsumerRecord[String, String]] = stuCourseKafkaInputDStream.transform(
rdd => {
val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
stuCourseOffsetRanges = ranges.offsetRanges
rdd
}
)
val stuCourseKafkaValue: DStream[String] = stuCourseTransformDStream.map(_.value())
//得到dwd_tb_stu的DStream
val stuOffset: mutable.Map[TopicPartition, Long] = OffsetManagerUtil.getOfferSet(stuTopicName, stuGroupName)
var stuKafkaInputDStream: InputDStream[ConsumerRecord[String, String]] = null
if (stuOffset != null && stuOffset.size > 0) {
stuKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByMapTopicPartition(stuTopicName, stuOffset, ssc)
} else {
stuKafkaInputDStream = MyKafkaUtilDwsStuScore.getInputDStreamByDefault(stuTopicName, ssc)
}
var stuOffsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val stuTransformDStream: DStream[ConsumerRecord[String, String]] = stuKafkaInputDStream.transform(
rdd => {
val ranges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
stuOffsetRanges = ranges.offsetRanges
rdd
}
)
val stuKafkaValue: DStream[String] = stuTransformDStream.map(_.value())
// stuCourseKafkaValue.foreachRDD(rdd => {
// rdd.foreach(item => {
// println(item)
{"courseId":"1","courseName":"数学","id":"069428","score":"120","stuId":"6be3f5","tearchName":"小李老师"}
// })
// // 如果都操作完了这里就是保存偏移量
// OffsetManagerUtil.saveOffset(stuCourseTopicName, stuCourseGroupName, stuCourseOffsetRanges)
// // 手动提交kafka的偏移量
// stuCourseKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuCourseOffsetRanges)
//
// })
//
// stuKafkaValue.foreachRDD(rdd => {
// rdd.foreach(item => {
// println(item)
{"aearName":"华东地区","areaCode":"0001","id":"6be3f5","stuName":"小同学"}
// })
//
// // 如果都操作完了这里就是保存偏移量
// OffsetManagerUtil.saveOffset(stuTopicName, stuGroupName, stuOffsetRanges)
// // 手动提交kafka的偏移量
// stuKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuOffsetRanges)
// })
// 上面能够得到两条流的数据
//第一条流是stuCourseKafkaValue:{"courseId":"1","courseName":"数学","id":"069428","score":"120","stuId":"6be3f5","tearchName":"小李老师"}
//第二条是stuKafkaValue{"aearName":"华东地区","areaCode":"0001","id":"6be3f5","stuName":"小同学"}
// 下面是使用双流join的操作
// 这里有三种情况使用redis缓存join,假设学生一次可以输入多条成绩信息的情况
// 1. 如果stu到了,stuCourse也到了
// 2. 如果stu到了,stuCourse没有到
// 3. 如果stu没到 ,stuCourse 到了
// 注意由于用学生关联成绩那么不管stuCourse到了,还是没有到都会在redis缓存防止有晚到的数据
// 如果stuCourse缓存在redis里面,如果stu到了那么就把他删除
// 1.先把数据变成key,value结构才能join
val stuIdAndStu: DStream[(String, TbStu)] = stuKafkaValue.map(item => {
val stu: TbStu = JSON.toJavaObject(JSON.parseObject(item), classOf[TbStu])
(stu.id, stu)
})
val stuIdAndCourse: DStream[(String, TbStuCourse)] = stuCourseKafkaValue.map(item => {
val course: TbStuCourse = JSON.toJavaObject(JSON.parseObject(item), classOf[TbStuCourse])
(course.stuId, course)
})
//这里得到的是fullJoin的结果
val fullJoin: DStream[(String, (Option[TbStu], Option[TbStuCourse]))] = stuIdAndStu.fullOuterJoin(stuIdAndCourse)
val resStuWide: DStream[StuWide] = fullJoin.mapPartitions(iter => {
val jedis: Jedis = OffsetManagerUtil.jedisPool.getResource
val res: ListBuffer[StuWide] = ListBuffer[StuWide]()
for ((stuId, (stu, course)) <- iter) {
if (stu.isDefined) {
//stu来了
if (course.isDefined) {
//如果course来了
val resItem: StuWide = StuAndStuScore.getStuWide(stu.get, course.get)
res.append(resItem)
}
//由于course来还是没有来stu保存在redis里面,目的就是等待晚来的数据
//这里选用存储stu的数据格式为string,keuy=FullJoin:Stu:stuid
val stuKey = s"FullJoin:Stu:${stu.get.id}"
//把json数据传入进去,默认保存一天,根据自己的情况来定
val stuJsonCache: String = JSON.toJSONString(stu.get, JSON.DEFAULT_GENERATE_FEATURE)
jedis.setex(stuKey, 3600 * 24, stuJsonCache)
//stu先到还要看下缓存里面有没有之前到的course
val couKey = s"FullJoin:Course:${stu.get.id}"
val courseCacheDatas: util.Set[String] = jedis.smembers(couKey)
val scala: mutable.Set[String] = courseCacheDatas.asScala
for (elem <- scala) {
val courseItem: TbStuCourse = JSON.toJavaObject(JSON.parseObject(elem), classOf[TbStuCourse])
//这里在把数据加入进去
val stuRes: TbStu = stu.get
val wide: StuWide = StuAndStuScore.getStuWide(stuRes, courseItem)
res.append(wide)
}
//删除掉处理完的course数据
jedis.del(couKey)
} else {
//如果stu没有来,我们选用set存储分数
val courseKey = s"FullJoin:Course:${course.get.stuId}"
val courseJsonCache: String = JSON.toJSONString(course.get, JSON.DEFAULT_GENERATE_FEATURE)
jedis.sadd(courseKey, courseJsonCache)
}
}
//关闭资源
jedis.close()
res.iterator
})
resStuWide.foreachRDD(rdd => {
rdd.foreach(item=>{
println("===========")
println(item)
val stuWide: String = JSON.toJSONString(item, JSON.DEFAULT_GENERATE_FEATURE)
MyKafkaSinkUtil.send("dws_tb_stuwide",stuWide)
})
// 如果都操作完了这里就是保存偏移量
OffsetManagerUtil.saveOffset(stuCourseTopicName, stuCourseGroupName, stuCourseOffsetRanges)
// 手动提交kafka的偏移量
stuCourseKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuCourseOffsetRanges)
// 如果都操作完了这里就是保存偏移量
OffsetManagerUtil.saveOffset(stuTopicName, stuGroupName, stuOffsetRanges)
// 手动提交kafka的偏移量
stuKafkaInputDStream.asInstanceOf[CanCommitOffsets].commitAsync(stuOffsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}分别启动

在双流join的时候,stu的数据保存到redis的形式为

最后效果
点击 
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic dws_tb_stuwide{"aearName":"华北地区","areaCode":"0003","courseId":"5","courseName":"美术","id":"321020","score":"90","scoreid":"8e0276","stuId":"321020","stuName":"双流join缓存实现成功","tearchName":"小李老师"}![]()
做到这里以后kafka里面的主题有

ADS层
动态得到按地区提供的总分数据实时的保存到mysql,用于显示
这里我们使用mysql保存offset
创建表,第二个是统计表
CREATE TABLE `offset` (
`group_id` varchar(200) NOT NULL,
`topic` varchar(200) NOT NULL,
`partition_id` int(11) NOT NULL,
`topic_offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`group_id`,`topic`,`partition_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `aear_sumscore`
(
`aear_name` varchar(20),
`sum_score` decimal(16,2)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;scalikejdbc精准一次性消费
pom.xml
org.scalikejdbc
scalikejdbc_2.12
3.4.0
org.scalikejdbc
scalikejdbc-config_2.12
3.4.0
mysql
mysql-connector-java
5.1.47
配置文件
application.conf
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://master/school?characterEncoding=utf-8&useSSL=false"
db.default.user="root"
db.default.password="root"偏移量保存工具
object OffsetManagerM {
def getOffset(topic: String, consumerGroupId: String): mutable.Map[TopicPartition, Long] = {
val sql=" select group_id,topic,topic_offset,partition_id from offset" +
" where topic='"+topic+"' and group_id='"+consumerGroupId+"'"
val jsonObjList: List[JSONObject] = MySQLUtil.queryList(sql)
val res: mutable.Map[TopicPartition, Long] = mutable.Map()
jsonObjList.map {
jsonObj =>{
val topicPartition: TopicPartition = new TopicPartition(topic,
jsonObj.getIntValue("partition_id"))
val offset: Long = jsonObj.getLongValue("topic_offset")
res.put(topicPartition,offset)
}
}
res
}
}MySQLUtil
object MySQLUtil {
def main(args: Array[String]): Unit = {
val list: List[JSONObject] = queryList("select * from tb_stu")
println(list)
}
def queryList(sql: String): List[JSONObject] = {
Class.forName("com.mysql.jdbc.Driver")
val resultList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]()
val conn: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/school?characterEncoding=utf-8&useSSL=false",
"root",
"root"
)
val stat: Statement = conn.createStatement
println(sql)
val rs: ResultSet = stat.executeQuery(sql)
val md: ResultSetMetaData = rs.getMetaData
while (rs.next) {
val rowData = new JSONObject();
for (i <- 1 to md.getColumnCount) {
rowData.put(md.getColumnName(i), rs.getObject(i))
}
resultList += rowData
}
stat.close()
conn.close()
resultList.toList
}
}最后得到了统计的结果,按地区实时统计优秀学生的贡献成绩
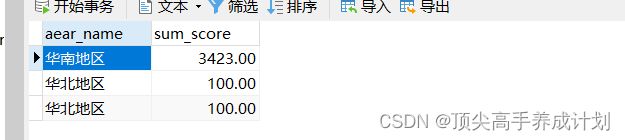
AdsApp
object Ads {
def main(args: Array[String]): Unit = {
// 加载流
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("TrademarkStatApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "ads_tb_stuwide"
val topic = "dws_tb_stuwide";
//从 Mysql 中读取偏移量
val offsetMapForKafka: mutable.Map[TopicPartition, Long] =
OffsetManagerM.getOffset(topic, groupId)
//把偏移量传递给 kafka ,加载数据流
var recordInputDstream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMapForKafka != null && offsetMapForKafka.size > 0) {
recordInputDstream = MyKafkaUtilDwdTbStu.getInputDStreamByMapTopicPartition(topic, offsetMapForKafka, ssc)
} else {
recordInputDstream = MyKafkaUtilDwdTbStu.getInputDStreamByDefault(topic, ssc)
}
//从流中获得本批次的 偏移量结束点
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
recordInputDstream.transform {
rdd =>{
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//提取数据
val stuWideDstream: DStream[StuWide] = inputGetOffsetDstream.map {
record =>{
val jsonString: String = record.value()
//得到最后的数据
val stuWide: StuWide = JSON.parseObject(jsonString,
classOf[StuWide])
stuWide
}
}
// 聚合
val res: DStream[(String, Int)] = stuWideDstream.map(item => {
(item.aearName, item.score.toInt)
}).reduceByKey(_ + _)
//存储数据以及偏移量到 MySQL 中,为了保证精准消费 我们将使用事务对存储数据和修改偏移量
res.foreachRDD {
rdd =>{
val aearSum: Array[(String, Int)] = rdd.collect()
if (aearSum !=null && aearSum.size > 0) {
DBs.setup()
DB.localTx {
implicit session =>{
// 写入计算结果数据
val batchParamsList: ListBuffer[Seq[Any]] = ListBuffer[Seq[Any]]()
for ((aearName, sumScore) <- aearSum) {
//下面是保存数据去哪个地方
batchParamsList.append(Seq(aearName, sumScore))
}
SQL("insert into aear_sumscore(aear_name,sum_score) values(?,?)")
.batch(batchParamsList.toSeq:_*).apply()
//throw new RuntimeException("测试异常")
// 写入偏移量
for (offsetRange <- offsetRanges) {
val partitionId: Int = offsetRange.partition
val untilOffset: Long = offsetRange.untilOffset
SQL("replace into offset values(?,?,?,?)").bind(groupId,
topic, partitionId, untilOffset).update().apply()
}
}
}
}
}
}
ssc.start()
ssc.awaitTermination()
}
}