Spark3.x入门到精通-阶段三(深度剖析spark处理数据全流程)
深度剖析spark原理
简介
深度剖析源码加图解spark处理数据全流程
spark内核
开篇图
下面是Standalone集群模式的情况,yarn集群也是大同小异
- 向集群submit一个应用以后,启动一个Application,里面会启动一个Driver进程
- Driver里面会生成一个sparkContext,每一个action执行都会启动一个job
- 初始化sparkContext以后会生成一个DAGschedule和一个Taskschedule
- 然后Driver向Master申请Executor资源
- Executor申请下来以后会向Driver注册自己的信息
- DAGschedule根据启动的job生成一个个stage,每一个stage里面是一个taskset
- Taskschedule把生成的taskset发送到对应的Executor的线程池里面执行
- 相同stage里面的parition处理是在一个Task里面处理的
- 一个stage处理完以后Taskschedule就会处理另外一个,直到处理完为止
宽依赖窄依赖图解

- 在窄依赖的情况 由于子RDD和父RDD他们是一对一的关系,所以在执行的时候,partition中的数据可以在一个task中执行 。
- Task有两种,一种是shuffleMaptask一种是ResultTask,中间的操作都是shuffleMaptask,在结束的时候才是ResultTask
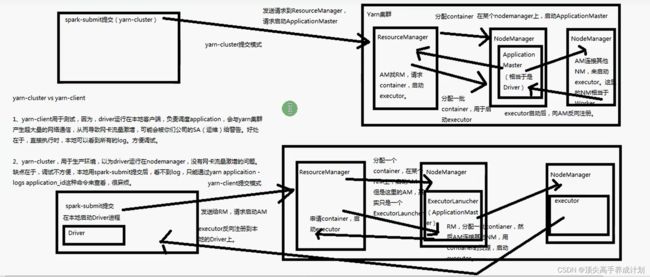
spark三种提交模式图解
- standalone默认(就是spark本身的集群模式,上面已经图解了)
- yarn-cluster (Driver在集群里面分配资源启动)
- yarn-client (Driver在提交的机器启动)
核心类详解
SparkContext
初步认识SparkContext
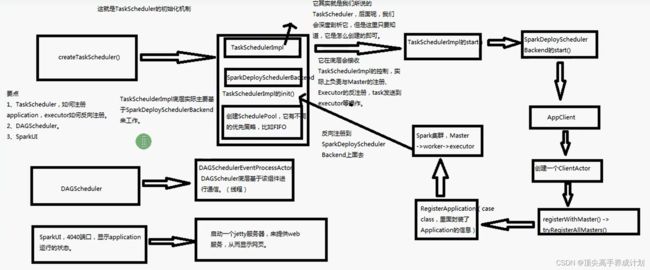
- TaskScheduleImp通过创建的SparkDeployScheduleBackend实现Driver向Master进行注册,还有Executor资源和接收Executor反向注册到Driver的请求
- 生成的DAGschedule负载对于执行action以后生成的job生成stage,并且把每一部分的stage的任务发送到Executor的线程池进行执行
- 生成一个SparkUI,端口是4040,内部使用的jetty
sparkContext启动流程详细图解
链接:https://pan.baidu.com/s/1B6_VrF7y8VvsOX6EZ5Caqg
提取码:yyds
Master深度剖析
Master主备切换图解原理

- 就是在Master的active存活的时候会保存一些信息到hdfs文件系统或者是zookeeper上面,如果Master宕机了,Standby Master就会通知正在处理的Driver和Executor获得他们的存活信息,如果没有存活了重新启动重新分配资源,如果是存活的就给新的Master回复下
在master主从切换完以后处理源码流程图解
master的注册机制图解和源码剖析
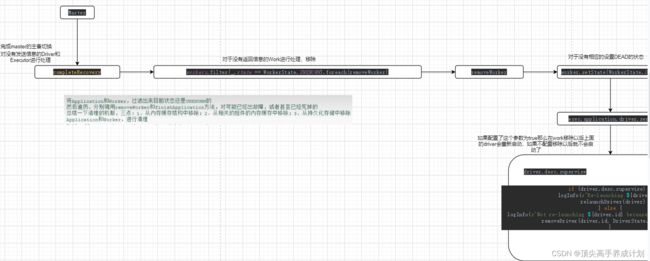
下图是Driver,Worker,Application向Master进行注册

- worker注册到Master的时候,Master先处理掉状态UNKNOWN的Worker,然后保存正在注册的Worker的信息到一个Hashmap中,在用持久化的机制保存到hdfs或者zookeeper,然后执行调度方法
- 其他的图中很详细的介绍了
下图是master注册application源码分析流程图

master的状态改变机制
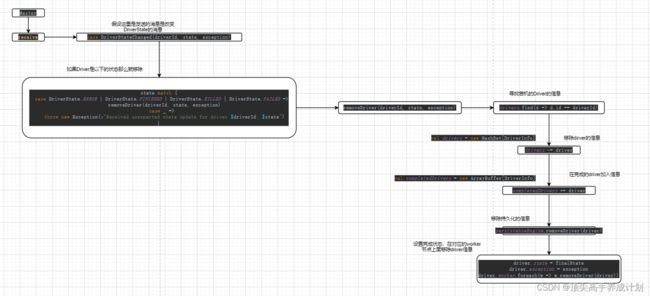
driver状态改变机制源码剖析
exector状态改变机制源码剖析

master资源调度源码分析(schedule)
- 它的主要的作用就是,为driver分配资源,还有对application的exector分配资源
- 为exector分配资源的时候有一个分配算法spreadOutApps,spark.deploy.spreadOut它的默认值为true,也就是默认分配的时候尽量均衡的分配到可用的worker上面,如果为false,那么就是尽量的先把一些worker资源用完在用其他worker的资源
- 然后就是application利用自己对本身driver的引用,为driver发送自己分配的executor的信息,建立driver和executor之间的联系
部分源码流程

详细源码流程
链接:https://pan.baidu.com/s/1qnx6CpLWzTGcHpapO42x0w
提取码:yyds
总结下:
- SparkContext初始化的时候会向Master发送一个registerApplication请求,Master在receive接收到注册Application的请求以后,会在Master缓存中加入ApplicationInfo信息
- 然后就是调度分配资源,如果是yarn模式那么Application中的Driver会在一个调度队列里面等待调度分配资源,如果是其他模式就没有这个等待的操作就会直接启动Driver
- 分配好Driver的资源以后,开始分配Executor的资源,在Worker上面分配Executor的时候有 一个算法可以进行选择spark.deploy.spreadOut,默认是true就是尽量均衡的分配到可用的worker上面,如果为false就是只有worker上面的资源不能分配的时候才分配到其他的worker上面
- 分配好Executor以后,由于Application里面有本身对应Driver的Rpc对象,它就会在Executor资源分配完以后,把自己分配到的Executor发送给Driver,这个请求是ExecutorAdded(exec.id, worker.id, worker.hostPort, exec.cores, exec.memory)
Work深度剖析
work启动Driver和Executor原理剖析大概图
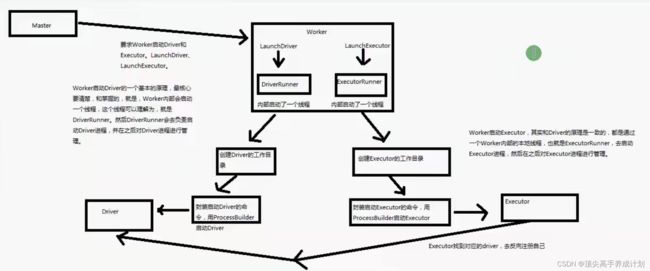
详细源码流程解读
链接:https://pan.baidu.com/s/1KRLnlaeLuC1cMJQHF2VVOw
提取码:yyds
总结启动Driver和Executor的流程:
- 在初始化SparkContext的时候里面会创建一个TaskSchedulede 方法是SparkContext.createTaskScheduler,根据环境的不同创建不同的StandaloneSchedulerBackend,他是CoarseGrainedSchedulerBackend的一个子类,它里面有一个class DriverEndpoint就是Driver的Rpc引用
- 在StandaloneSchedulerBackend的start方法里面会创建一个StandaloneAppClient,它与Application注册有关
- 然后Master接收注册的信息是case RegisterApplication(description, driver),可以看到传入了Application的描述信息还有Driver的信息,说明Driver比Application先创建
- 然后Driver执行driver.send(RegisteredApplication(app.id, self)),在本身绑定application的信息,还有注册到了哪个Master的信息
- 然后就是执行资源调度方法schedule(),Master分别执行launchDriver(worker, driver)(这个Driver在等待队列调度是yarn才有的,如果是其他模式是直接启动的没有等待的过程)和launchExecutor(worker, exec)
- 然后就是到了Worker,receive分别接收case LaunchExecutor,case LaunchDriver,分别为Driver和Executor分配资源
- 然后就是Work更具对于的状态给Master发送状态改变的信息,执行exitCode = process.get.waitFor()然后根据返回的状态码,worker.send(DriverStateChanged(driverId, finalState.get, finalException))
- Master接收到case DriverStateChanged,信息以后释放资源等操作
- 初始化Executor以后,Executor会反向注册到application里面的Driver
- 然后SparkContext初始化完成,资源分配也完成了
Job触发流程和源码分析
从wordcount开始讲解
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaWordCount")
val context = new SparkContext(conf)
val lineTextRDD: RDD[String] = context.textFile("hdfs://hadoop102:8020/data.txt")
lineTextRDD.flatMap(line=>line.split(" "))
.map((_,1))
.reduceByKey(_+_)
.foreach(println)
context.stop()
}
}textFile调用的内容
- 首先调用的是textFile,里面创建了 一个hadoopFile,然后创建了new HadoopRDD,并且把hadoopConfiguration也就是hadoop的配置文件作为广播变量广播到HadoopRDD分区中
- 在hadoopRDD里面分区的方法里面有一个很重要的方法getInputFormat(jobConf).getSplits(jobConf, minPartitions),这也就证明了为什么每一个分块的数据发送到一个分区里面
- 最后得到的数据map(pair => pair._2.toString),因为TextInputFormat读取到的数据是行号,还有对应的行的 信息,我们只要内容就行了。这就是textFile里面包含的内容
reduceByKey的由来
- 在RDD里面我们发现是没有这个方法的,这是由于RDD使用了隐式装换的原因,在伴生对象里面有一个implicit def rddToPairRDDFunctions,只要作用范围内可以装换,那么就会加入装换操作,而rddToPairRDDFunctions就是返回new PairRDDFunctions(rdd)对于key,value类型数据的操作
执行action操作foreach
- 在执行action操作里面会调用sc.runJob,然后会调用dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get),rdd就是要处理的东西,这个dagScheduler就是sparkContext初始化的时候创建的。
DagSchedule原理剖析和源码剖析
DagSchedule划分stage的大概流程图

图解
- 在reduceByKey的时候会分出几个RDD,第一个是mapPartitionRDD会分组后落盘,中间的ShuffleRDD处理聚合操作
- 划分stage的时候,从最后一个RDD开始,一直往前,如果是窄依赖,那么就是划分到一个stage里面,如果是宽依赖那么就划分出一个新的stage,一直循环这样处理,直到处理完最后一个
DAGschedule的stage划分算法详解流程图
链接:https://pan.baidu.com/s/1vyNChLd-VQvN8K8QV5GgLA
提取码:yyds
stage划分算法总结
- 最后一个RDD首先会创建一个finalStage,然后加入到调用栈中,然后开始判断他们的宽依赖还有窄依赖关系,如果是窄依赖就加入栈中,如果是宽依赖那么就创建一个新的stage,新创建的stage叫做ShuffleMapStage
- 更具得到finalStage的父stage,加入到waitingStages(就是等待要执行的stage里面)
- 然后在递归调用,获取到第一个RDD为止,
- 递归到第一个的时候,就开始执行stage0,执行完以后在执行waitingStages里面的stage
stage的task优先位置算法
- 提交stage以后,也就是执行submitMissingTasks,根据stage的不同初始化出不同的task,除了finalstage以外,其他的都是ShuffleMapTask,finalstage创建的task为ResultTask
- 初始化task的时候是每一个分区一个task,在一个stage里面的一个partiton公用一个task,在task优先位置算法的时候,首先寻找这个这个RDD的一个parition是否在缓存中有值,如果有那么task就在cache开始执行,然后就是看checkpoint,如果checkpoint里面有值task就先从checkpoint启动(所以这里得到一个结论,找缓存的时候是根据partition的id去找的)
详细源码跟踪
链接:https://pan.baidu.com/s/1hhJnFeDnxq4QAEjaRoI17Q
提取码:yyds
TaskScheduler原理和源码剖析
原理流程图解
链接:https://pan.baidu.com/s/1bGncyw5g1PDHi0Kb_DRerg
提取码:yyds
- 由于上面的stage已经得到了task,那么就会调用TaskScheduler,进行Task的提交
- 在提交之前,会对Task发送到哪个Executor有一个本地化优先执行算法,然后得到Task和Executor和task的对应关系,然后把Task发送到对应的Executor上面去执行
Executor原理源码剖析
在spark里面创建的Executor实际创建的是CoarseGrainedExecutorBackend
Executor大概图解
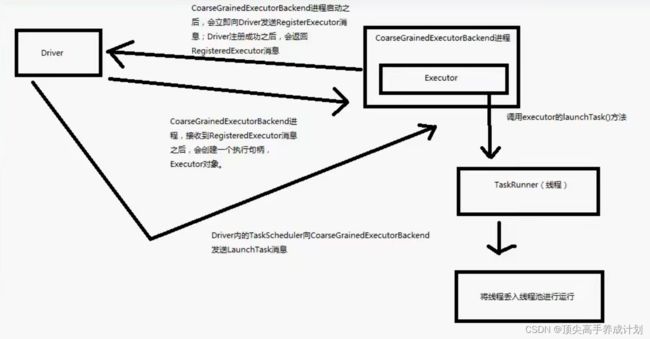
代码逻辑图

总结:
- CoarseGrainedExecutorBackend在启动的时候会执行onStart然后向Driver注册自己
- Driver收到信息以后,回复一条可以注册的信息,然后CoarseGrainedExecutorBackend创建出一个Executor
- 创建出Executor以后,它就会接收由TaskSchedule发送过来的Task信息,进行反序列化以后,放入自己的cache线程池中进行执行
Task原理和源码剖析
Task大致原理如图
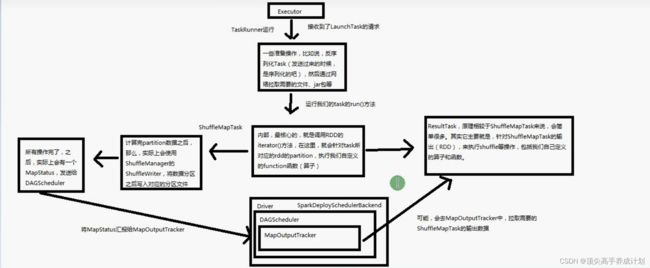
详细执行流程图
链接:https://pan.baidu.com/s/1FYYxCwFmv5PK600-5T5L0Q
提取码:yyds
总结:
- 反序列化Task以后,放入TaskRunable里面执行,读取需要的文件还有Jar包
- 根据runTask不同类,有ShuffleMapTask和ResultTask两种
- ShuffleMapTask执行的时候会根据广播过来的RDD数据,进行区分,也就是说只处理自己的那一部分partition数据
- 处理得到partiton的数据为Mapstatus保存在BlockManage,而且输出的分区格式是Hashpartitioner
- 得到数据以后,就会向Driver汇报执行Task的信息,发送的请求是statusUpdate,Driver通过receive方法接收,通过返回的Task执行的状态判断是在Taskset正在执行的Task里面移除,还有报错以后重新提交Task
Shuffle原理剖析和源码剖析
什么情况下会出现shuffle?
reduceByKey,groupByKey,sortByKey,countByKey,join,cogroup
shuffle的问题及改进
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考Hadoop MapReduce的实现开始引入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到最近的2.0版本,Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。下图是spark shuffle实现的一个版本演进

Hash Shuffle v1

每一个task都对应每一个分区生成一份文件
Hash Shuffle v2

每一个core为单位,产生对应的分区文件
Sort Shuffle v1
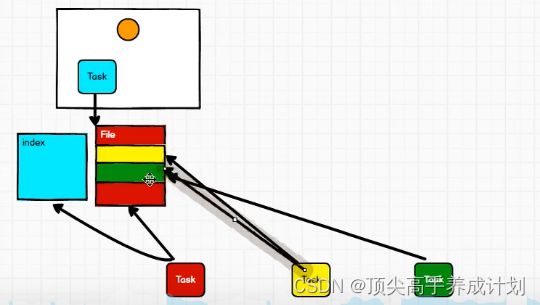
每一个Task产生 一份文件,不过会有一个index文件标识分区段
shuffle源码分析
链接:https://pan.baidu.com/s/10_bK-nefAH8sPHj9QQJDjg
提取码:yyds
总结:
- ShuffleMapTask在执行的时候就会有落盘的操作
- ShuffleMapTask开始的时候会先得到一个shuffleManage,由于在之前的Hash删除了,所以剩下的只有SortShuffleManage
- SortShuffleManage会根据不同的环境得到不同的write对象,如果没有map预聚合的情况,并且下游的partition数量小于默认的200,spark.shuffle.sort.bypassMergeThreshold,可以设置这个值,满足这两个条件就会创建BypassMergeSortShuffleHandle,然后他会得到BypassMergeSortShuffleWriter,它是一种不用排序的shuffleWrite,它的原理和Hash Shuffle v2很像
- 如果不能序列化,也不满足上面的条件,就是SortShuffleWriter,这就是Sort Shuffle v1的情况
- 上面是写的过程,然后读数据的过程是ShuffledRDD,它的compute就是可以找到文件句柄读取文件操作
BlockManage原理
基本架构图解
CacheManager原理
基本架构

CheckPoint原理和源码剖析
基本原理