【GNN笔记】GAT(五)
视频链接:【图神经网络】GNN从入门到精通
GNN中三种基础神经网络:GCN, GraphSAGE, GAT
文章目录
-
- 一、GAT
-
- 定义
- 案例
- 二、多头注意力机制
- 三、图网络的应用
- 四、代码目录
- 四、GAT的断点解析
- 五、train()的断点解析
- 附录:train.py的代码
一、GAT
定义

补充:
L e a k y R e L U ( x ) = { x , x ≥ 0 α x , x < 0 w h e r e , α 默 认 很 小 的 值 LeakyReLU(x)=\begin{cases} &x, &x \geq0\\ &\alpha x, & x<0\end{cases}\\ where, \alpha 默认很小的值 LeakyReLU(x)={x,αx,x≥0x<0where,α默认很小的值
参考博文: 《激活函数ReLU、LeakyReLU》 ,重点看为什么需要非线性激活函数。以及博文《ReLU,LeakyReLU的优缺点》
案例

二、多头注意力机制

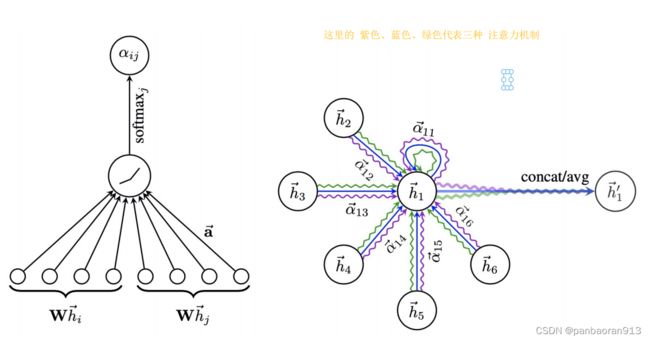
三、图网络的应用

四、代码目录
代码链接,见这里
其函数的大致过程与GCN相同。
四、GAT的断点解析
-
第一层公式
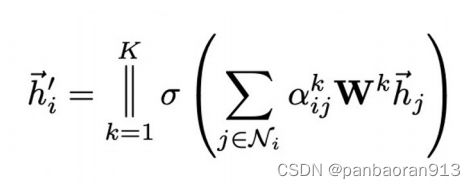
-
打上断点

-
进入GAT: ctrl+点击GAT

-
查看输入的变量

-
查看self.attentions
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
是一个长度为nheads=8的列表,列表中的每个元素都为一个图注意力层。

- 可以进入GraphAttentionLayer查看,(附加)
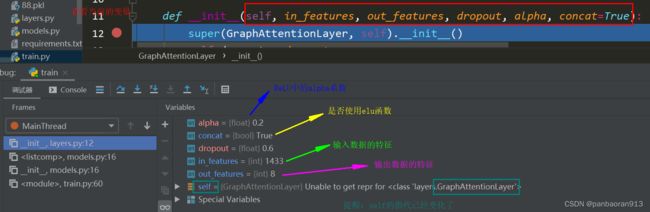
注意到这里的self已经改变了。
self.W 公式含义和形状
self.a 表示两个向量的拼接后的向量,见上图的 e i j e_{ij} eij,因此其形状为(2*out_features,1)=(16,1)

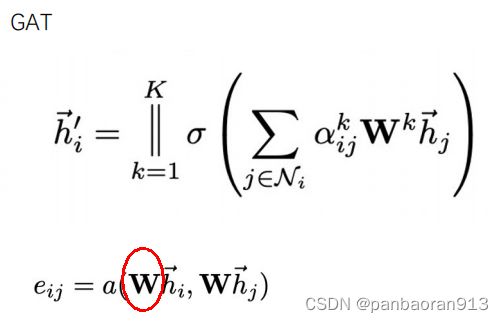
- 将8头注意力机制添加到module中
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
add_module的用法
add_module的用途
add_module(name, module)
举例:self.add_module("time_conv",nn.Conv2d(6,12,3))
等价于:self.time_conv=nn.Conv2d(t,12,3)
添加后的结果为

- 第二层公式
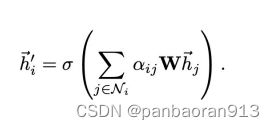
- self.out_att
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)
该层是对接上面8层的的一个图注意力层

五、train()的断点解析
- 1)打上断点,即将进入model

- 2)进入GAT.forward()函数

- 3) 执行第二行
- 进入GraphAttentionLayer.forward()函数
- h–线性变换–>Wh
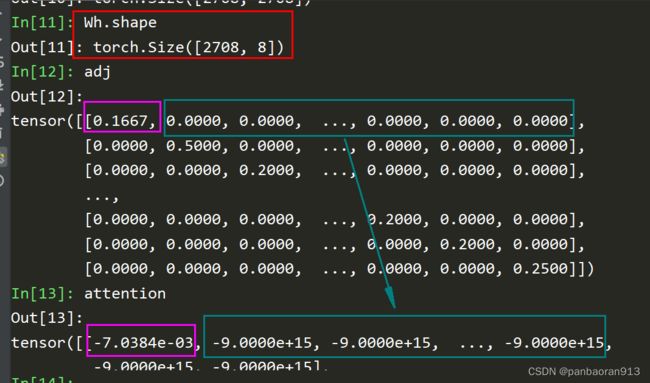
- 调用函数
_prepare_attentional_mechanism_input,如下图返回的是蓝色框的内容
这里应用了Tensor的广播机制,计算了所有的 e i , j e_{i,j} ei,j。如上图中的公式, α i , j \alpha_{i,j} αi,j的分母是相邻的节点之间的关系(或着说需要链接的节点),而不是所有节点的关系。- 设置了一个于e相同形状的负无穷(极大负数即可)矩阵zero_vec
- adj中元素>=0,则选择e,否则选择zero_vec.因为 e − ∞ = 0 e^{- \infty}=0 e−∞=0,所以softmax的分母中的极大负数时趋于0的,从而使分母只限制在相连站点的集合中。
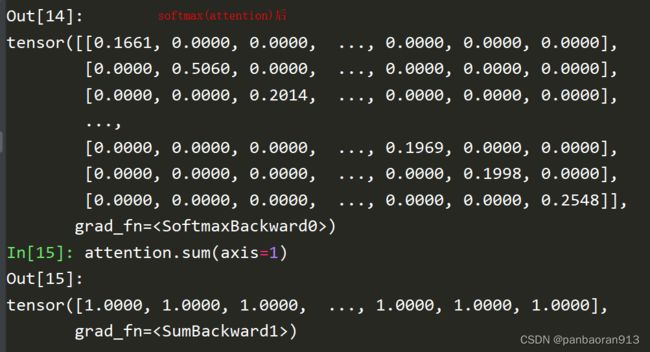
- 根据原理,进行softmax函数
- 节点的聚合表示
7 .self.concat确定是否进行elu函数
在GAT的第一个注意力层有,第二个注意力层没有



-
4) 执行torch.cat,拼接第一层的attetntion后

-
5)执行第二个attetntion层
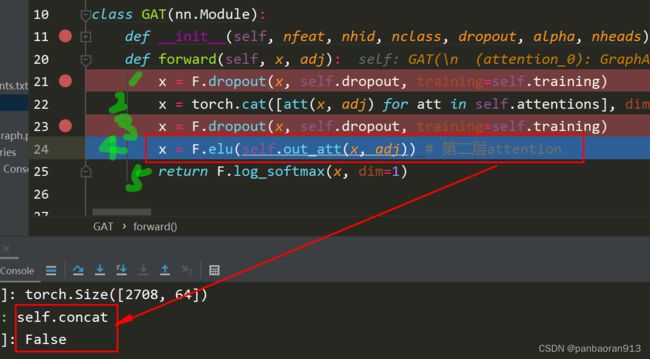

-
6) 返回train函数

附录:train.py的代码
from __future__ import division
from __future__ import print_function
import os
import glob
import time
import random
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from utils import load_data, accuracy
from models import GAT, SpGAT
# Training settings
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False, help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False, help='Validate during training pass.')
parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.005, help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4, help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=8, help='Number of hidden units.')
parser.add_argument('--nb_heads', type=int, default=8, help='Number of head attentions.')
parser.add_argument('--dropout', type=float, default=0.6, help='Dropout rate (1 - keep probability).')
parser.add_argument('--alpha', type=float, default=0.2, help='Alpha for the leaky_relu.')
parser.add_argument('--patience', type=int, default=100, help='Patience')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data()
# Model and optimizer
if args.sparse:
model = SpGAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
else:
model = GAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
optimizer = optim.Adam(model.parameters(),
lr=args.lr,
weight_decay=args.weight_decay)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
features, adj, labels = Variable(features), Variable(adj), Variable(labels)
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features, adj)
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if not args.fastmode:
# Evaluate validation set performance separately,
# deactivates dropout during validation run.
model.eval()
output = model(features, adj)
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.data.item()),
'acc_train: {:.4f}'.format(acc_train.data.item()),
'loss_val: {:.4f}'.format(loss_val.data.item()),
'acc_val: {:.4f}'.format(acc_val.data.item()),
'time: {:.4f}s'.format(time.time() - t))
return loss_val.data.item()
def compute_test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.data.item()),
"accuracy= {:.4f}".format(acc_test.data.item()))
# Train model
t_total = time.time()
loss_values = []
bad_counter = 0
best = args.epochs + 1
best_epoch = 0
for epoch in range(args.epochs):
loss_values.append(train(epoch))
torch.save(model.state_dict(), '{}.pkl'.format(epoch))
if loss_values[-1] < best:
best = loss_values[-1]
best_epoch = epoch
bad_counter = 0
else:
bad_counter += 1
if bad_counter == args.patience:
break
files = glob.glob('*.pkl')
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb < best_epoch:
os.remove(file)
files = glob.glob('*.pkl')
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb > best_epoch:
os.remove(file)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
# Restore best model
print('Loading {}th epoch'.format(best_epoch))
model.load_state_dict(torch.load('{}.pkl'.format(best_epoch)))
# Testing
compute_test()
```