笔记【Two-Stream Convolutional Networks for Action Recognition in Videos】
关于视频中的动作识别,挑战在于从静止帧和帧之间的运动中捕获关于外观的补充信息。
本文研究了经过区别训练的深度卷积网络(ConvNets)的体系结构,用于视频识别中。还旨在在数据驱动的学习框架中概括性能最优手动调节参数。
文章有主要三点贡献:
1.提出结合时间和空间网络的双流ConvNet网络结构。
2.证明在缺少训练集的情况下,ConvNet在多帧密集光流中依然能取得非常好的训练效果。
3.实验表明,应用于两个不同的识别训练集,这种多任务学习方法不仅可以用于增加训练数据,还可以提升两者的性能。
双流网络结构:基于两个单独的识别流(时间和空间)研究不同的架构,然后通过缓慢融合(late fusion)进行组合。空间流从静止视频帧执行动作识别,同时训练时间流以识别来自密集光流形式的运动的动作。
2. Two-stream architecture for video recognition
视频能分成空间部分和时间部分,空间部分以单个帧外观的形式携带有关视频中描绘的场景和对象的信息,时间部分以帧的运动形式传达观察者(相机)和物体的运动。
双流识别结构
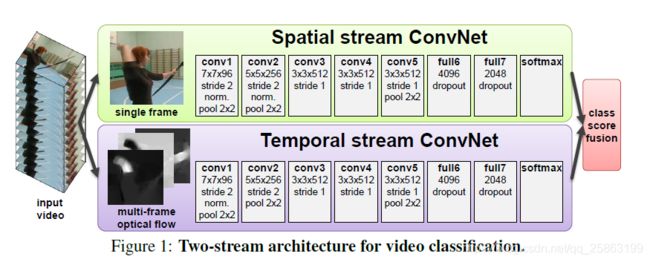
我们将视频识别架构分为两个流,每一个流(时间流,空间流)使用deep ConvNet,softmax函授后紧跟late fusion。虑两种融合方法:对叠加的L2归一化softmax分数进行平均和训练多类线性SVM 作为特征。
Spatial stream ConvNet:空间流ConvNet对各个视频帧进行操作,有效地从静止图像中执行动作识别。 静止帧(空间识别流)的动作分类本身就具有相当的竞争力。由于ConvNet本身就是一个强大的图像识别算法,所以可以基于大规模图片的识别算法构建视频识别网络,还可以在大图片分类数据集上预训练网络。
3.Optical flow ConvNets
Temporal ConvNet的输入是通过在几个连续帧之间堆叠光流位移场而形成的。这种输入带有视频帧之间的动作特征,使得识别过程变得更加容易(不需要网络再隐式估计动作)。
如Figure 2所示:基于光流的输入的几种变化

3.1 ConvNet input configurations
有两种可以表示动作的方法。
(1)Optical flow stacking 和 (2)Trajectory stacking


3.2 Relation of the temporal ConvNet architecture to previous representations
在这一节,我们将时间ConvNet架构放在现有技术中,应用到视频处理上。HOF和MBH局部描述符基于光流方向或其梯度的直方图,(发散,卷曲和剪切)的运动学特征可以通过我们的卷积模型捕获。
在我们的例子中,动作可以用光流位移图表示,并通过基于流的强度和平滑度的恒定性假设计算。将这种假定和ConvNet网络结合能提高端到端的CNN的表现,这是将来的一个研究方向(2014年)。
4.Muti-task learning
由于temporal ConvNet需要在视频数据集上训练,但现有的数据集UCF-101 和 HMDB-51上的视频太少。所以考虑将这两个数据集组合成一个。一种更加可靠的方法是基于多任务学习的方式进行数据集的合并。
文中的ConvNet网络结构是这样的,全连接层前有两个softmax分类层,两个softmax分别计算在UCF-101 和 HMDB-51学习的分数,各自有自己的损失函数,整个网络总的损失函数就是他们的和。网络的权值由反向传播计算得到。
5.Implementation details
- ConvNets configuration,网络结构和CNN-M-2048很像,全部的隐藏层激活函数使用ReLU,时间ConvNet和空间ConvNet不同的点,空间ConvNet去除了第二正则化层。
- Training,网络的权重通过学习率为0.9的mini-batch stochastic gradient descent方法进行学习。在每次迭代中,通过对256个训练视频(均匀地跨越类)进行采样来构建小批量的256个样本,从每个训练视频中随机选择单个帧。
6 Evaluation
(为了比较空间流和时间流识别上的表现差异,训练时都是使用其中一种来训练识别)
spatial stream ConvNet对各个视频帧进行操作,有效地从静止图像中执行动作识别。文中通过三种方法评价空间流CNN的表现。
- 在UCF-101上从头开始训练
- 该空间流CNN在ILSVRC-2012上进行预培训,然后对UCF-101进行微调
- 保留预训练的网络参数,仅仅训练最后一层(分类层)
实验结果如下:

作者发现方法(3)的结果最好,所以接下来的实验都采用该方法。
Temporal ConvNets 在UCF-101上从头开始训练。

根据实验结果发现
- 多层堆叠向量场(stacking multiple displacement fields,L>1)比单帧光流的效果有明显提高(73.9% --> 80.4%)
- mean subtraction对结果提升很大,它能减少两帧之间全局动作的影响
- 光流堆叠(optical flow stacking )和轨迹 (trajectory stacking) 堆叠的效果差不多
对比以上使用spatial ConvNet 和 temporal ConvNet 训练的情况,空间流的识别准确率远远比不上时间流,由此得出多帧信息非常重要的。
Multi-task learning of temporal ConvNets

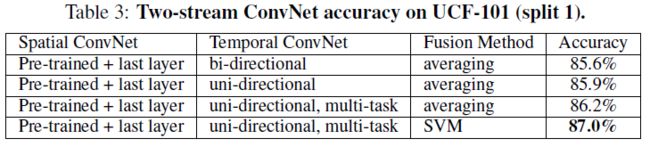
Two-stream ConvNets
双流网络在UCF-101上训练的精度
与当时最先进算法的对比结果

Two-Stream ConvNets的网络训练步骤如下:
- 空间流CNN在ILSVRC上进行预训练,然后在UCF-101和HMDB-51上训练最后一层(分类层)
- 时间流CNN在数据集UCF和HMDB上进行多任务训练,该网络的输入是mean substraction的单向(uni-directional)光流堆叠
- 两个流的网络中softmax的结果使用平均或SVM进行组合
待改进
- 还需要将网络在更大的数据集上进行训练
- 个别先进的好方法没有加入到这个双流网络中,例如 local feature pooling over spatio-temporal tubes
- 另一个潜在的改进领域是对相机运动的明确处理,在我们的例子中,通过平均位移减法来补偿。