Linux内核 ftrace 介绍与初使用
1、ftrace含义
ftrace 可以跟踪内核函数调用,查看内核正在做什么。
ftrace 具体含义有两层:
- 提供函数钩子的基础设施
- 基于tracefs文件系统的 trace 框架
1) 需要打开内核配置选项:CONFIG_FUNCTION_TRACER
2) 挂载 tracefs
# mount -t debugfs none /sys/kernel/debug
or
# cat /etc/fstab
tracefs on /sys/kernel/debug/tracing type tracefs
2、全局概要图
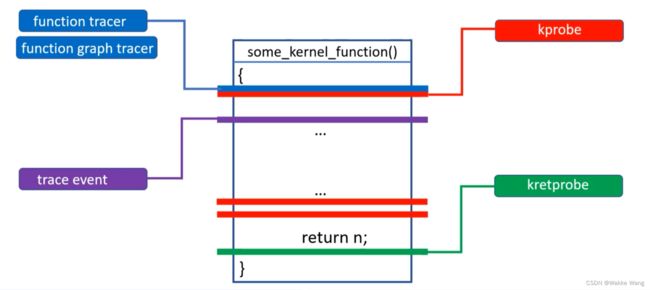

function tracer : 确定函数是否执行了,函数的call trace, 执行到函数的时间。
钩子在函数开始,返回处都有。
function graph tracer:打印该函数向下的所有执行流,以及执行时间。确认执行流是否调用了某个函数,钩子在函数开始,返回处都有。
trace event 内核某个子系统的维护者在函数的实现过程中,就把钩子写进去了,当函数执行的时候,就会执行这个钩子函数,钩子函数会输出一些特定的信息,便于调试
kprobe 可以把钩子挂到函数的任一个地方,最常见的一种用法,就是把钩子挂到函数头上,可以获取函数的参数,也可以挂载其它地方,检查或者修改一下变量的值,
kretprobe 特殊的kprobe,把钩子函数挂到了函数的返回处,获取函数的返回值。
3、ftrace 使用方法
以 blk_update_request 为例
使用perf 工具 进行 function tracer:
perf frace --tracer=function -T blk_update_request -a
perf probe -a 'blk_update_request diskname=req->rq_disk->disk_name:string'
perf record -e probe:blk_update_request -aR sleep 1
perf record -e block:block_rq_complete -a以echo cat 为例
1)function tracer
cd /sys/kernel/debug/tracing/
echo vfs_open > set_ftrace_filter
echo function > current_tracer
# 打开堆栈信息
echo 1 > ./options/func_stack_trace 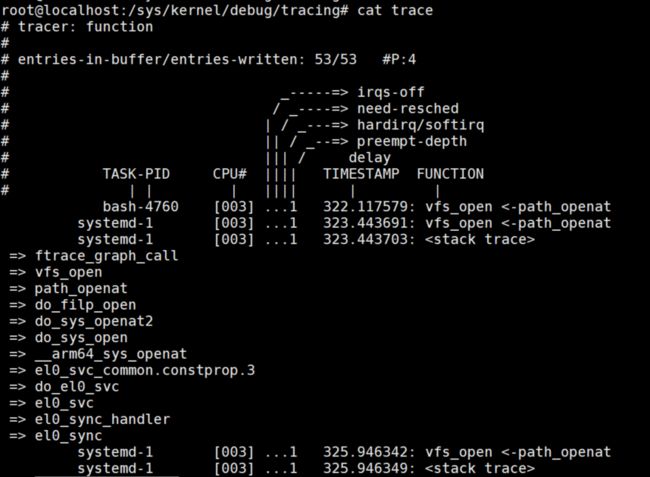
2)function graph tracer
cd /sys/kernel/debug/tracing/
echo vfs_open > set_graph_function
echo function_graph > current_tracer
echo 1 > options/funcgraph-proc
echo 1 > options/funcgraph-tail
cat /root/.profile
cat trace
3) kprobe event
获取函数的参数
这里需要gdb 获取变量的偏移量:
打开内核的调试选项:linux-5.10-35
Kernel hacking —>
Compile-time checks and compiler options —>
[ ] Compile the kernel with debug info
General architecture-dependent options --->
[*] Kprobes
获取 文件的name 有两种方法
path->dentry->d_iname (char []) 名字长度小于32字节

name: +0x38(+0x8($arg1)):string
path->dentry.d_name->name (char *) 名字长度小于32字节,指向上面的数组,否自己开辟内存
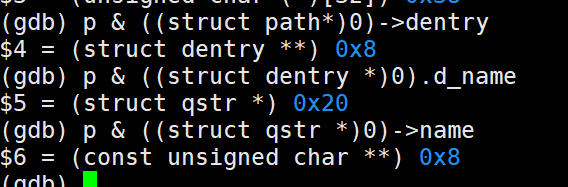
name: +0(+0x28(+0x8($arg1))):string
这里 +0的意思,类似于取*,取里面的内容。数组不用+0,char *指针需要。
cd /sys/kernel/debug/tracing/
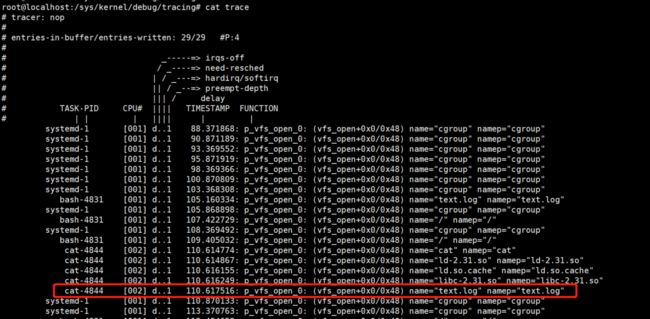
echo 'p vfs_open name=+0x38(+0x8($arg1)):string namep=+0(+0x28(+0x8($arg1))):string' > kprobe_events
echo 1 > events/kprobes/p_vfs_open_0/enable
echo 1 > /text.log
cat /text.log
实测,这两种方式都是可以成功获取的
![]()
enable: 使能kprobe
filter: 过滤指定文件的信息,要注意看 format格式
trigger: kprobe event执行的时候 ,可以触发什么事件,比如触发一下打印堆栈,触发function trace功能,或者 function graph trace功能,
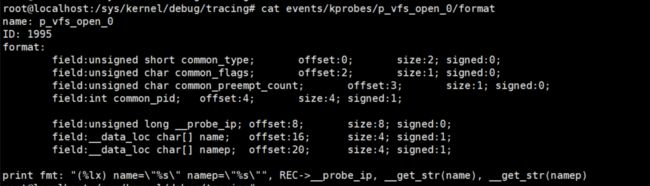
上面的变量都是在环形队列缓冲区中,offset=0 是偏移为0,大小为2的第一个成员。
前4个是 kprobe event 的通用字段,
common_type : kprobe event ID:1995 , 这个perf 会用到
common_flags: 比如可以通过kprobe 是在软中断,硬中断,是否可以被调度,都可以用这个flags表示,也可以用了过滤。在什么上下文执行的时候过滤。
common_preempt_count 被抢占计数,内核支持抢占嵌套的,如果是0的话,就是下图中的点。如果是非0的话,就是数字。
__probe_ip: 函数的地址
name namep 是咱们自己添加的变量
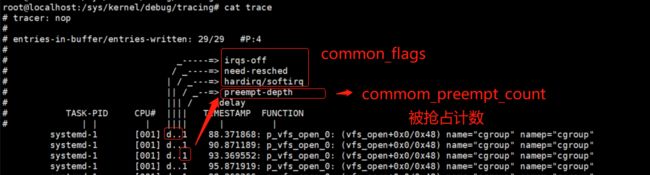
支持的 tragger 方式如下:
![]()
如果我想知道某一个文件是否被打开了,如果被打开了,就打印一下堆栈信息,可以这么做:
cd /sys/kernel/debug/tracing/
echo 'p vfs_open name=+0x38(+0x8($arg1)):string namep=+0(+0x28(+0x8($arg1))):string' > kprobe_events
echo 1 > events/kprobes/p_vfs_open_0/enable
# 支持通配符来过滤,名字包含text的文件
echo 'name ~"*text*"' > events/kprobes/p_vfs_open_0/filter
echo 'stacktrace if name ~"*text*"' > events/kprobes/p_vfs_open_0/trigger
cat /text.log
cat trace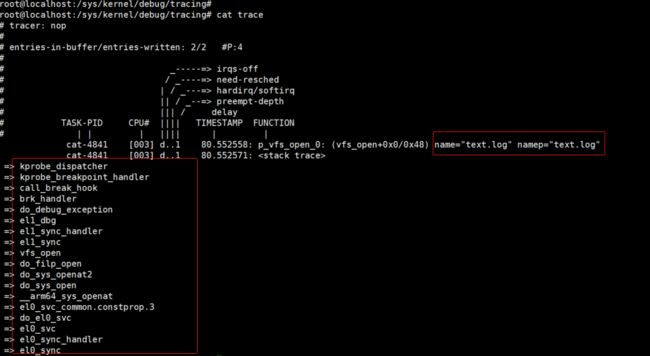
4) trace event (tracepoints, 或者 static event)
一般都是代码的维护者加进去的,block_rq_complete 这个在打开文件,返回的时候会调用。

使用方法类似于kprobe event

如果要定义自己的trace event ,可以参考

下面是自己定义的参数格式
echo 1 > events/block/block_rq_complete/enable
cat /text.log
4、perf工具 && ftrace && ebpf的关系
ftrace是一个框架,这个框架下包括以下几种tracer

使用这几种tracer的话,可以
- 使用perf 工具,集成ftrace等工具。
- 使用 echo & cat , 或者是封装好的命令行工具 trace-cmd / kernelshark
ebpf 本身是一个字节码程序,字节码程序被load之后 ,会返回一个fd, 根据这个fd 就可以找到字节码程序了。
perf 是可以使用 ftrace的,是一个万能工具,ftrace给 perf 提供了接口,可以让perf 使用 kprobe event的功能,
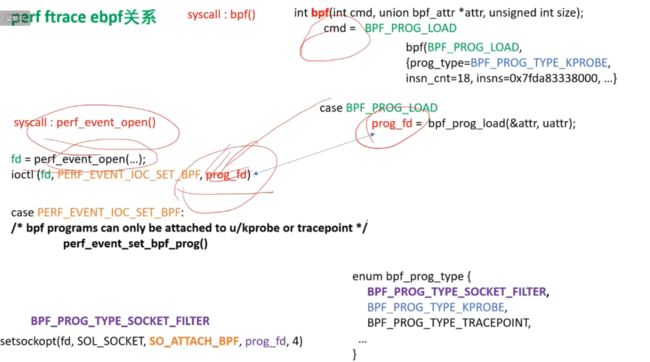
这里是说,perf 是使用了 ebpf的,最后都会调用 ebpf 的系统调用 bpf()。

ebpf 本质上还是使用的ftrace
