什么是生成对抗网络(GAN)| 小白深度学习入门

小白深度学习入门系列
1. 直观理解深度学习基本概念
2. 白话详解ROC和AUC
3. 什么是交叉熵
4. 神经网络的构成、训练和算法
5. 深度学习的兴起:从NN到DNN
6. 异军突起的激活函数:ReLU
7. CNN,RNN,LSTM都是什么?
8. 什么是Transformer?
生成模型(Generative Model) vs 判别模型(Discriminant Model)
在讨论生成对抗网络之前,我们需要先明确两个概念:生成模型和判别模型。
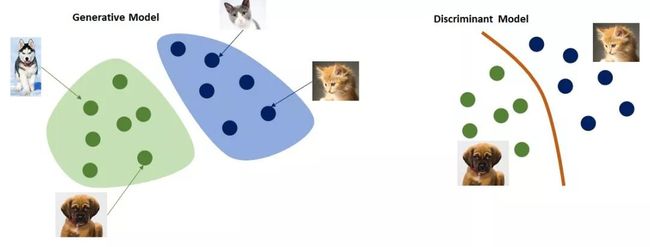
所谓生成网络,指构建生成模型的神经网络;同理判别网络则是构建判别模型的神经网络。
机器学习/深度学习模型所的一个主要任务就是:根据事物的属性(X)预测事物的标记(Y)。生成模型和判别模型,都能完成这个任务,但具体方法不同。
生成式模型会求取X和不同的Y之间的联合概率:P(Y1,X),P(Y2,X),P(Y2,X),..., P(Yn,X),然后选取其中与X联合概率最大的那个Yi,将其作为预测结果。
判别式模型来则会求以X为条件的Y的条件概率:P(Y|X),针对特定X直接得出P(Y|X)的结果,如果这个值大于某个阈值,则可以直接将其作为预测结果。
生成对抗网络(Generative Adversarial Networks,GAN)
那么,什么是生成对抗网络呢?
简单而言,生成对抗网络是一种无监督学习方法,该方法由Goodfellow等人在2014年提出。

这个方法通过两个网络——一个是生成网络,另一个是判别网络——的相互制约来实现训练过程。
生成对抗网络中的生成网络G和判别网络D分别好像是假币团伙和警察——G努力使假币和真币更接近,而D则努力把假币从真币中区分出来。
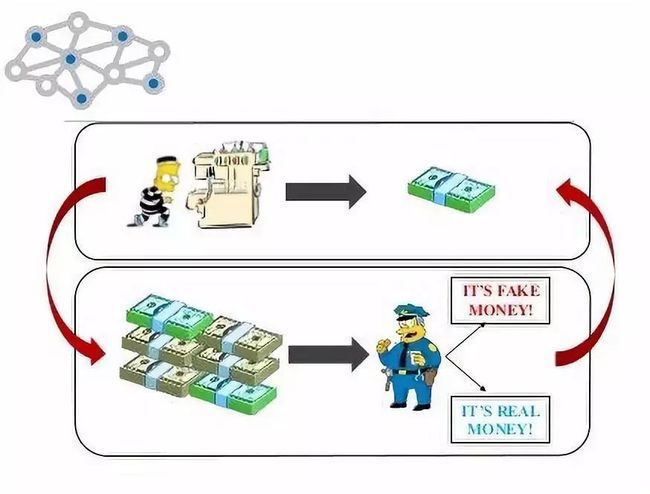
通过G和D的对抗,最终使得两者的模型准确度都得到提升。
生成对抗网络结构
下图是一个以手写数字生成为目标的原始的GAN网络结构,可以它由Generator生成器和Discriminator判别器组成。

生成器用于从噪音中生成一幅手写数字的图片,而判别器则努力将训练集图片和生成器生成的假图片区分开来。
可以证明,当网络的能力足够的时候,生成器最终会生成和训练集特征相同的图像。具体的训练步骤如下(来自原论文中伪代码):
for num_of_training_iterations:
for k_steps: #k在这里是超参数,代表每个迭代对判别器做几次优化
从训练集中随机选取m幅图像
随机选取(生成)m个噪声图片
更新判别器参数(普通神经网络训练过程,例如交叉熵误差函数和随机梯度下降)
随机选取m个噪声图片
更新生成器参数
其实在GAN的论文中主要是提出了利用生成器和判别器相互制约的思路,而非详细的模型结构。上面的训练方法只是一种示例方法,生成器和判别器也不必是神经网络。
生成对抗网络的优势和劣势
GAN的优势和劣势总结如下:
CONs:
1. 网络自由度太高,训练难度大
2. 两个模型是分开更新的,所以带来了两个模型之间的同步问题。如果一个模型训练的过快,会影响另一个模型的训练。
PROs:
1. 只使用反向传播即可完成训练,不使用何马尔可夫链来训练。
2. GAN可以和大部分现有的生成网络算法相结合使用,提高性能。
从实际应用中,模型难以训练是困扰很多研究人员最大的问题。不过在提出GAN的论文发布(2014年)以来,大量GAN改进方法被提出,较好的解决了GAN中存在的问题,使得图像生成任务达到了可以商业应用的成熟度。
生成对抗网络主要应用举例
前面说了生成对抗网络。经过几年的研究已经比较成熟,可以进行商业应用。下面就列举了几个比较有名的开源应用案例:
zi2zi:一个变换中文字体的应用,基于pix2pix

iGAN:我管他叫神笔马良,一个adobe和伯克利联合发布的图像增强网络,能从简笔画生成一个真实度很高的图像。

domain-transfer-network: 感觉和CNN中的风格迁移类似,实现的功能类似脸萌,可以从真实头像生成卡通头像

neural-enhance: 将低分辨率图像处理成高分辨率图像,以后各种游戏炒冷饭,电影重制版的成本可以大大降低了。。。。

deepfake: 前一阵引起轩然大波的现象级应用,可以给视频换脸,应用场景很多

类似的应用还有很多,而且也达到了不错的效果。个人感觉GAN真的是一个很有钱途的领域。
“众智汇”愿景
尽职尽才,允公允能 —— 本社群不定期举行线上分享,组织群友分享知识、经验、资源,以达到让我们每个人的职业生涯得到最大程度的发展的目的。
欢迎扫面下列二维码关注“悦思悦读”公众微信号
