Pytorch学习笔记7——处理多维特征的输入
Pytorch学习笔记7——处理多维特征的输入
这是一个糖尿病分类的数据集。
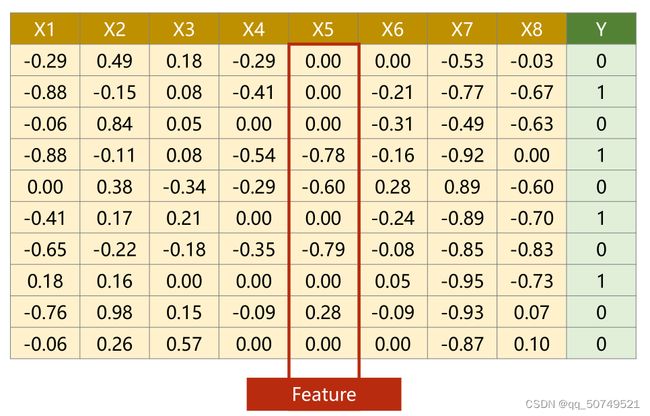
每一行代表一个样本Sample,每一列叫做特征feature。在这里共有10个样本,每个样本有8个特征。Y为对应标签。
数据集准备工作就是:取出前8列得到X矩阵作为input,最后1列得到Y矩阵作为标签。
i表示样本索引,n表示特征索引。每一个特征值都要和权重进行相乘。
得到结果一定是标量。
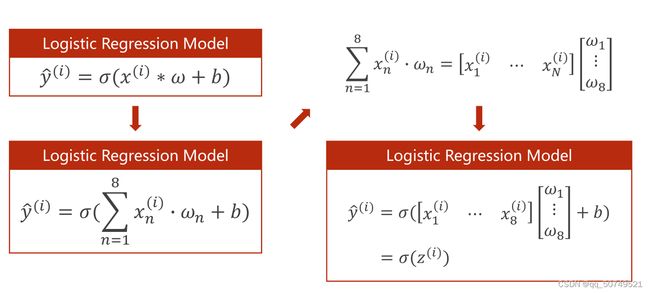
对于N样本处理,在torch里继承的module函数都是向量化函数,比如sigmoid就是按向量计算的,矩阵里每一个元素都是进行相同操作。
这里面的权重和偏置都是一样的。z1 z2 … zn都是标量,组成一个向量。
这样,矩阵运算可以进一步合并。X矩阵变为N * 8的,w矩阵变成8 * 1的,b矩阵变成N * 1的,通过这种向量化计算就可以拥有并行计算的能力,提高了运行速度。

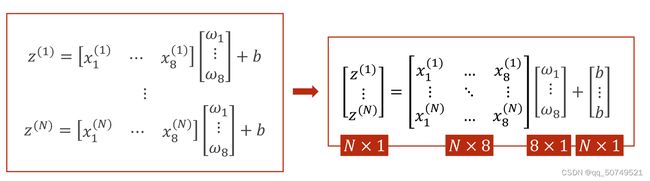
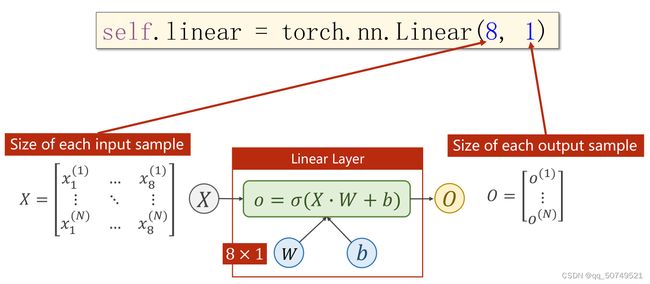
这样,在Linear线性层我们要做的就是把Input(N, 8)转为output(N, 1)。
torch.nn.Linear(input_dim, output_dim), 其中input_dim表示输入数据的特征维度, output_dim表示输出数据的特征维度,这里分别为8,1:
self.linear1 = torch.nn.Linear(8, 1)
损失计算:

四步走:
- Prepare Dataset
- Design model using class
- construct loss and optimizer
- Training cycle(forward, backward, update)
#Preapre Dataset
import numpy as np
xy = np.loadtxt('F:\ASR-source\Dataset\diabetes.csv.gz', delimiter = ',', dtype = np.float32)
x_data = torch.from_numpy(xy[:,:-1])#取出除最后一列y之外的前8列
y_data = torch.from_numpy(xy[:,[-1]])#取出最后一列
print(x_data.shape)
print(y_data.shape)
输出:
torch.Size([759, 8])
torch.Size([759, 1])
#Design model using class
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.relu = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
#construc loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(mymodel.parameters(), lr = 0.01)
#training cycle
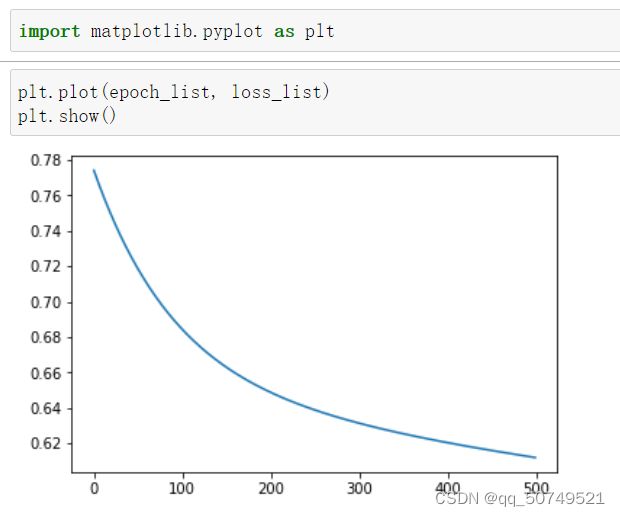
epoch_list = []
loss_list = []
for epoch in range(500):
y_pred = mymodel(x_data) #得到预测值
loss = criterion(y_pred, y_data) #计算损失
optimizer.zero_grad() #梯度归0
loss.backward() #反向传播更新梯度
optimizer.step()#更新权重、偏置
print('='*10, 'Epoch = ', epoch+1, '='*10)
print(loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
实际种的空间变换都是非线性的。我们经常用多个线性变换层,通过找到最优的权重,把他们组合起来,来模拟非线性变换,所以神经网络本质是找到非线性的空间变换。
所以,Linear这里我们可以先8D->6D, 6D->4D, 4D->1D,一步步降低维度。
当然,也可以上升维度, 8D往高维变到24D,再往低变。这决定了网络的复杂程度,至于怎么取,这就是超参数搜索的问题,看谁在数据集上的表现更好。
中间层数越多,神经元越多,模型的学习能力越强。但并不是越多越好,学习能力太强会导致学习到数据的噪声值,出现过拟合现象,这样的模型不具备很好的泛化能力。
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x

我们一般还会使用ReLU激活,但需要注意的是,ReLU在输入值小于0都会输出0,这会导致无法计算梯度,所以在最后一层激活一定不能使用ReLU,可以改成Sigmoid。如下:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.relu = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))#注意最后一步不能使用relu,避免无法计算梯度
return x

End