ES(Elasticsearch)全文搜索引擎(最全)入门基本语法与在SpringBoot中的实战
注:本文较长,根据个人情况有些内容可以跳过,前面是基本的概述,中间是一些基于es的一个可视化工具进行操作,代码实现在最下边;
一、认识Elasticsearch
1.1、为什么要使用Elasticsearch
虽然在全文搜索领域中,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
实际项目中,我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON/XML通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并在需要扩容时方便地扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。
1.2、ElasticSearch(简称ES)
ES即为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,其第一个版本于2010年2月出现在GitHub上并迅速成为最受欢迎的项目之一。
首先,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,ES的核心不仅仅在于Lucene,其特点更多的体现为:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎 --ES
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
KB-MB-GB-TB-PB
高度集成化的服务,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。
上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它拥有开瓶即饮的效果(安装即可使用),只需很少的学习既可在生产环境中使用。
总结:ElasticSearch简化了全文检索lucene的使用,同时增加了分布式的特性,使得构建大规模分布式全文检索变得非常容易。
二、ES的核心概念
2.1、几个基本概念
Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级;
Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document;
Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type;
Document&field:文档字段
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段;可以拿Mysql去对比方便理解一点;

2.2、集群相关概念
Cluster:集群
包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常;
Node:节点
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为"elasticsearch"的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群;
shard:分片
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index;
replica:复制品
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器;
集群的健康状况
green
所有的 primary shard 和 replica shard 都是 active 活动状态 - 集群健康
yellow
所有的 primary shard 处于 active 活动状态,有部分的 replica shard 不处于 active 状态 - 集群能用
red
至少有一个 primary shard 不处于 active 活动状态就会出现red - 集群不健康
三、ES安装及使用说明
3.1、包含的内容
ES的安装比较简单,只需要官方下载ES的运行包,然后启动ES服务即可。
ES的使用主要是通过能够发起HTTP请求的终端来接入,比如Poster插件、CURL、kibana5等。
3.2、安装ES
① 下载ES安装包
官方下载地址:https://www.elastic.co/downloads/elasticsearch.
本本教程在window环境下,以ES 5.2.2版本为例,下载对应的ZIP文件
② 运行ES
解压
解压完后,建议去config中的jvm.options去修改下内存,默认是4个g

然后就运行
bin/elasticsearch.bat
③ 验证
默认为9200
访问:http://localhost:9200

看到上图信息,恭喜你,你的ES已经启动并且正常运行了。
3.3、辅助管理工具Kibana5
它还有其他的工具,这儿我就使用Kibana5
① Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana.
② 解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
③ 启动Kibana5 : bin\kibana.bat
④ 默认访问地址:http://localhost:5601
下面是它每个目录是干啥用的:
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
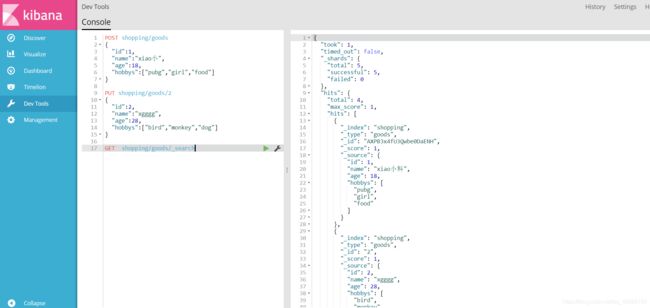
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
⑤正常情况,我们都是在Dev Tools中去操作;
四、ES集成ik分词器
4.1、什么是分词
在全文检索理论中,文档的查询是通过关键字查询文档索引来进行匹配,因此将文本拆分为有意义的单
词,对于搜索结果的准确性至关重要,因此,在建立索引的过程中和分析搜索语句的过程中都需要对文
本串分词。ES的倒排索引是分词的结果。
4.2、ES倒排索引原理
4.3、安装概述
为了后面做类型映射,需要先集成分词器;
lucene由于是jar工具包,如果要在使用lucene的环境下使用ik分词器,只需导入对应jar,做一些配置就OK.但是ES不是工具包了,是服务器.怎么集成呢?
以插件的方式集成ES服务器,客户端只需告诉我们某个字段要用这个分词器就OK了.
步骤:
服务端安装ik插件
客户端端指定字段用ik分词器
4.4、安装
①下载源码
https://github.com/medcl/elasticsearch-analysis-ik
②maven打包
mvn install -Dmaven.test.skip=true
③安装到es服务器
解压到es/plugins
④配置
可选
⑤重启
4.5、测试分词器
随便在网上找段话,看看效果如何
POST _analyze
{
"analyzer":"ik_smart",
"text":"总有一些文章一些句子让我们感同身受,引发读者们的共鸣"
}

当然后面还有很多,截了一部分;
注意:IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
五、操作命令
现在该安装的都安装了,该弄的都弄完了,现在来实际操作一波
5.1、索引库CRUD
都是在Kibana中进行操作的
5.1.1、增加索引库
创建一个名字为 shopping 的索引库,5个 Master Shard 分片,每个Master Shard分片有1个 Replica Shard 从分片
PUT shopping
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}
5.1.2、查询索引库
查询所有索引库
GET _cat/indices?v
查看指定索引库
GET _cat/indices/{index}
5.1.3、删除索引库
DELETE {index}
5.1.4、修改索引库
没有直接修改的方法哦,只能先删除再去增加
5.2、文档CRUD
5.2.1、文档的概念
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document);
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
尽管原始的 Java对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在ES中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。
一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。
三个必须的元数据节点是:
_index:索引库,类似于关系型数据库里的“数据库”——它是我们存储和索引关联数据的地方。
_type:在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。可以是大写或小写,不能包含下划线或逗号。我们将使用 employee 做为类型名。
_id: 与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你 可以自定义 _id ,也可以让Elasticsearch帮你自动生成。另外还包括:uid文档唯一标识(type#id)
_source:文档原始数据
_all:所有字段的连接字符串
5.2.2、添加文档
我们以用户对象为例,我们首先要做的是存储用户数据,每个文档代表一个用户。在ES中存储数据的行为就叫做索引(indexing),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:
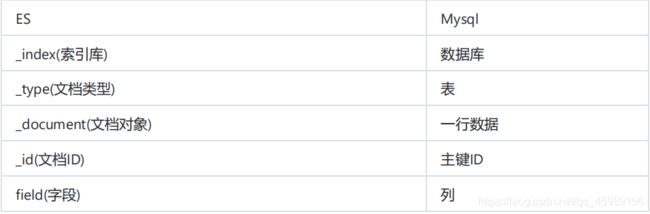
ES集群可以包含多个索引(indices)(数据库),每一个索引库中可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列);
基本语法
指定ID创建索引文档
PUT {index}/{type}/{id}
{
JSON,文档内容
}
-----------------解释----------------------
PUT 索引库/文档类型/文档id
{
JSON格式,文档原始数据
}
如果想使用内置ID创建索引文档就不用跟后面的id就好了
没有指定文档ID,ES会自动生成ID
案例
PUT shopping/goods/1
{
"id":2,
"name":"xgggg",
"age":28,
"hobbys":["bird","monkey","dog"]
}
添加id为1的用户 ,索引库为 shopping,类型为 goods
5.2.3、获取文档
获取指定文档
GET {index}/{type}/{id}
指定返回的列
GET {index}/{type}/{id}?_source=字段1,字段2...
只要内容(只想显示字段)不要元数据
GET {index}/{type}/{id}/_source
5.2.4、修改文档
整体修改
全量修改的语法跟添加文档语法一样,如果文档已经存在就是添加,否则就是修改,
文档修改过程:1.标记删除旧文档,2.添加新文档
PUT {index}/{type}/{id}
{
"id":1,
"name":"zs"
}
注意:上面的修改会把ES中的数据全部覆盖,比如,如果你还有age字段的话,即age字段会消失
局部修改
局部修改过程: 1.检索旧文档 , 2.修改文档 ,3.标记删除旧文档 , 4.添加新文档
POST {index}/{type}/{id}/_update
{
"doc":{
"id":1,
"name":"zs"
}
}
注意:上面修改只会修改id,和name字段,age字段不会作任何改变
5.2.5、删除文档
DELETE {index}/{type}/{id}
六、文档的查询
6.1、常用查询
6.1.1、查询所有
GET _search
6.1.2、查询指定索引库
GET {index}/_search
6.1.3、查询指定类型
GET {index}/{type}/_search
6.1.4、查询指定文档
GET {index}/{type}/{id}
6.2、分页查询
GET _search
{
"from" : 0, "size" : 2
}
size: 每页条数
form:从多少条数据开始查
6.3、字符串查询
GET _search?q=age:17&size=2&from=2&sort=id:desc&_source=id,name
字符串查询(query string)其实就是在url后面以字符串的方式拼接各种查询条件,这种方式不推荐,因为
条件过多,拼接起来比较麻烦
6.4、批量查询
批量查询很重要,对相比单个查询来说,批量查询性能更高
6.4.1、不同索引库查询
GET _mget
{
"docs" : [
{
"_index" : "shopping",
"_type" : "goods",
"_id" : 2
},
{
"_index" : "animal",
"_type" : "dog",
"_id" : 1,
"_source": "name,age"
}
]
}
6.4.2、同索引库同类型 - 推荐
GET {index}/{type}/_mget
{
"ids" : [ "{id}", "{id}" ]
}
七、DSL查询与DSL过滤
7.1、DSL查询
7.1.1、什么是DSL查询
对于简单查询,使用查询字符串比较好,但是对于复杂查询,由于条件多,逻辑嵌套复杂,查询字符串
不易组织与表达,且容易出错,因此推荐复杂查询通过DSL使用JSON内容格式的请求体代替;
DSL查询是由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。DSL有两部分组成:DSL查询和DSL过滤。
7.1.2、DSL查询语法
一个常用的相对完整的DSL查询:
GET shopping/goods/_search
{
"query": {
"match_all": {}
},
"from": 20,
"size": 10,
"_source": ["username", "age", "id"],
"sort": [{"join_date": "desc"},{"age": "asc"}]
}
match_all 表示查询所有数据,分页处理,想要显示的列,排序
DSL查询案例
GET shopping/goods/_search
{
"query" :{
"match" : {
"name" : "李子"
}
}
}
查询username中包含“李子”的内容, match 指的是“标准查询”,该查询方式会对查询的内容进行分词。
DSL查询可以支持的查询方式很多,如 term 词元查询 (不分词,精准查询), range 范围查询等等。
7.2、DSL过滤
7.2.1、什么是DSL过滤
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同:DSL过滤查询文档的方式更像是对于我的条件"有"或者"没有"(等于 ;不等于),而DSL查询语句则像是"有多像"(模糊查询)。
7.2.2、查询与过滤的区别
DSL过滤和DSL查询在性能上的区别:
过滤结果可以缓存并应用到后续请求-> 精确过滤后的结果拿去模糊查询性能高;
查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存;
过滤语句可有效地配合查询语句完成文档过滤;
总结:需要模糊查询的使用DSL查询 ,需要精确查询的使用DSL过滤,在开发中组合使用(组合查询) ,关键字查询使用DSL查询,其他的都是用DSL过滤。
7.2.3、DSL查询+过滤语法
GET animal/dog/_search
{
"query": {
"bool": {
"must": [{ //与(must) 或(should) 非(must not)
"match": {
"name": "zs"
}
}],
"filter": {
"term": {
"name": "zs"
}
}
}
},
"from": 20,
"size": 10,
"_source": ["name", "age", "sex"],
"sort": [{
"join_date": "desc"
}, {
"age": "asc"
}]
}
注:
query : 查询,所有的查询条件在query里面
bool : 组合搜索bool可以组合多个查询条件为一个查询对象,这里包含了 DSL查询和DSL过滤的条件
must : 必须匹配 :与(must) 或(should) 非(must_not)
match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
filter: 过滤条件
term:词元查询,不会对查询条件分词
from,size :分页
_source :查询结果中需要哪些列
sort:排序
7.2.4、综合案例
名称(name)中有 “zs” 的狗 ,性别sex是公(1),年龄(age)在 1- 4之间,按照年龄(age)倒排序,
查询第 1 页,每页10 条 ,查询结果中只需要 :id,name,age
GET animal/dog/_search
{
"query": {
"bool": {
"must": [{
"match": {
"name": "zs"
}
}],
"filter": [
{
"range":{ //范围查询
"age":{
"gte":1, "lte":4
}
}
},
{
"term": { //词元查询
"sex": 1
}
}
]
}
},
"from": 1,
"size": 10,
"_source": ["id", "name", "age"],
"sort": [ {
"age": "desc"
}]
}
7.3、查询方式
在上面的案例中,我们接触了 match , range 等查询方式(查询对象),在ES还有很多其他的查询方式,在不同的场景中我们需要根据情况进行合理的选择。
7.3.1、全匹配(match_all)
(匹配所有文档)
GET _search
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"term": {
"name": "zs1"
}
}
}
}
}
7.3.2、标准查询(match和multi_match)
标准查询,可以理解为分词查询有点像模糊匹配(like),会对查询的内容进行分词后,得到多个单词,分别带着多个单词去检索ES库,只要有一个单词能查出结果,整个查询就有结果。不管你需要全文本查询
还是精确查询基本上都要用到它;
如下面的搜索会对 ‘吃肉’ 分词,并找到包含 ‘吃’ 或 ‘肉’ 的文档,然后给出排序分值
GET _search
{
"query": {
"match": {
"fieldName": "吃肉"
}
}
}
注意:上面效果如同 where fieldName like "%吃%" or fieldName like "%肉%"
提示:match一般只用于全文字段的匹配与查询,一般不用于过滤
而multi_match 查询允许你做 match查询的基础上同时搜索多个字段:
GET _search
{
"query": {
"multi_match": {
"query": "吃肉",
"fields": ["fieldName", "title"]
}
}
}
注意:上面的搜索同时在fieldName和title字段中匹配
7.3.3、单词搜索与过滤(Term和Terms)
单词/词元查询 , 可以理解为等值查询,字符串,数字等都可以使用它,把查询的内容看成一个整体去
检索ES库
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"fieldName": "吃肉"
}
}
}
}
}
上面的 ‘吃肉’ 会被当成一个整体去term中匹配,它跟match不同的地方在于
match会把 ‘吃肉’ 分成 ‘吃’ 和 ‘肉’ 分别取fieldName中查询
Terms支持多个字段查询
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"fieldName": "吃肉"
}
}
}
}
}
上面的 ‘吃肉’ 会被当成一个整体去term中匹配,它跟match不同的地方在于
match会把 ‘吃肉’ 分成 ‘吃’ 和 ‘肉’ 分别取fieldName中查询
7.3.4、组合条件搜索与过滤(Bool)
GET _search
{
"query": {
"bool": {
"must": [
{
"term":
{
"hobby": "睡"
}
}
],
"should": [
{
"term": {
"hobby": "游戏"
}
},
{
"term": {
"hobby": "运动"
}
}
],
"must_not": [
{
"range": {
"birth_date": {
"lt": "1990-06-30"
}
}
}
],
"filter":[
......
]
}
}
}
上面案例如同:hobby=睡 and (hobby=游戏 or hobby=运动) and birth_date >= 1990-06-30
提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有 must子句,那么
没有 should子句也可以进行查询。
7.3.5、范围查询与过滤(range)
range过滤允许我们按照指定范围查找一批数据
GET _search
{
"query": {
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
上例中查询年龄大于等于20并且小于30。
gt:> gte:>= lt:< lte:<=
7.3.6、存在和缺失过滤器(exists和missing)
GET _search
{
"query": {
"bool": {
"must": [
{
"match_all": {
}
}
],
"filter": {
"exists": {
"field": "gps"
}
}
}
}
}
可以通过exist/missing,判断某字段是否存在/缺失
exists和missing只能用于过滤结果
7.3.7、前匹配搜索与过滤(prefix)
和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
GET _search
{
"query": {
"prefix": {
"name": "王"
}
}
}
上例即查询姓王的所有人
7.3.8、通配符搜索(wildcard)
GET _search
{
"query": {
"wildcard": {
"name": "嘟*嘟"
}
}
}
使用*代表0~N个,使用?代表1个
八、文档映射
8.1、基本概念
8.1.1、什么是文档映射
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。就如果Mysql创建表时候指定的每个column列的类型。 为了方便字段的检索,我们会指定存储在ES中的字段是
否进行分词,但是有些字段类型可以分词,有些字段类型不可以分词,所以对于字段的类型需要我们自己去指定。
需要注意的是,我们在Mysql建表过程是:
Mysql创建数据库 -> 创建表(指定字段类型) -> 操作数据
而在ES中也是一样:
ES创建索引库 -> 文档类型映射 -> 操作文档
8.1.2、默认的字段类型
查看索引类型的映射配置:GET {index}/_mapping/{type}
基本字段类型
字符串类型:string,text,keyword
整数类型 :integer,long,short,byte
浮点类型 :double,float,half_float,scaled_float
逻辑类型 :boolean
日期类型 :date
范围类型 :range
复杂字段类型
二进制类型 :binary
数组类型 :array
对象类型 :object
嵌套类型 :nested
地理坐标类型 :geo_point
地理地图 :geo_shape
IP类型 :ip
范围类型 :completion
令牌计数类型 :token_count
附件类型 :attachment
抽取类型 :percolator
默认映射
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映
射关系。

8.1.3、映射规则
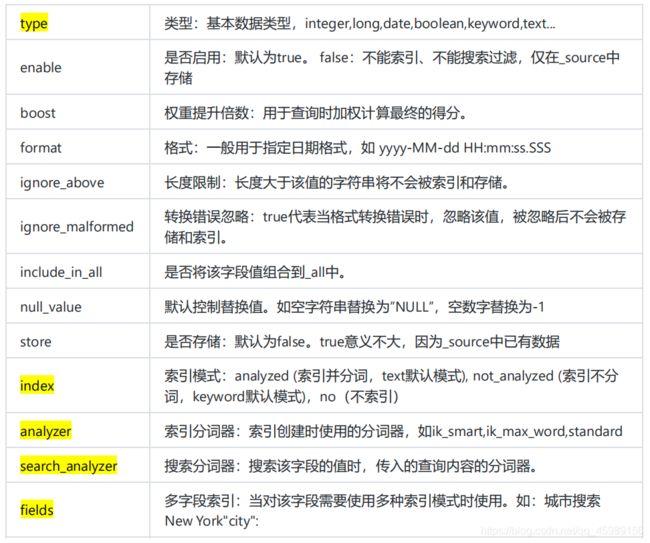
字段映射的常用属性配置列表 - 即给某个字段执行类的时候可以指定以下属性
"city":{
"type": "text",
"analyzer": "ik_smart",
"fields": {
"row": {
"type": "keyword"
}
}
}
相当于给 city取了一个别名 city.row,city的类型为text,city.row的类型为 keyword ,搜索 city分词 ,
搜索city.row 不分词,那么以后搜索过滤和排序就可以使用city.row字段名
8.2、添加映射
注意:如果索引库已经有数据了,就不能再添加映射了
8.2.1、创建新的索引库
put shopping
8.2.2、单类型创建映射
put shopping/goods/_mapping
{
"goods": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
给shopping索引库中的是goods类型创建映射 ,id指定为long类型 , name指定为text类型(要分
词),analyzer分词使用ik,查询分词器也使用ik
8.2.3、多类型创建映射
PUT shopping
{
"mappings": {
"user": {
"properties": {
"id": {
"type": "integer"
},
"info": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
},
"dept": {
"properties": {
"id": {
"type": "integer"
},
....更多字段映射配置
}
}
}
}
同时给user和dept创建文档映射
8.2.4、对象/数组映射
基本类型字段映射非常简单,直接配置对应的类型即可,但是数组和对象如何指定类型呢
①对象映射
{
"id" : 1,
"girl" : {
"name" : "翠花",
"age" : 22
}
}
文档映射
{
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties":{
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
}
}
②数组映射
{
"id" : 1,
"hobby" : ["女","篮球"]
}
文档映射
{
"properties": {
"id": {
"type": "long"
},
"hobby": {
"type": "keyword"
}
}
}
注意啦:数组的映射只需要映射一个元素即可,因为数组中的元素类型是一样的
③对象数组
{
"id" : 1,
"person":[{"name":"小花","age":18},{"name":"大黄","age":22}]
}
文档映射
{
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "text"
}
}
}
}
}
④全局映射
索引库中多个类型(表)的字段是有相同的映射,如所有的ID都可以指定为integer类型,基于这种思想,我们可以做全局映射,让所有的文档都使用全局文档映射。全局映射可以通过动态模板和默认设置两种
方式实现
九、ES集群
十、JavaApi操作ES
10.1、集成ES
10.1.1、导入依赖
org.elasticsearch.client
transport
5.2.2
org.apache.logging.log4j
log4j-api
2.7
10.1.2、连接ES
因为在后面的每一个操作中都会用到,所以就直接弄一个工具类
public class ESClientUtil {
public static TransportClient getClient(){
Settings settings = Settings.builder().put("cluster.name","my-ealsticsearch")
.put("client.transport.sniff", true).build();
TransportClient client = null;
try {
client = new PreBuiltTransportClient(settings)
.addTransportAddress( new InetSocketTransportAddress(InetAddress
.getByName("127.0.0.1"), 9303));
} catch (UnknownHostException e) {
e.printStackTrace();
}
return client;
}
}
10.2、对文档CRUD操作
10.2.1、添加文档
@Test
public void testAdd() {
//使用工具类获取客户端对象
TransportClient client = ESClientUtil.getClient();
//创建索引
IndexRequestBuilder indexRequestBuilder = client.prepareIndex("shopping", "user", "1");
Map data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果
IndexResponse indexResponse = indexRequestBuilder.setSource(data).get();
System.out.println(indexResponse);
client.close(); }
10.2.2、获取文档
GetResponse response = client.prepareGet("crm", "vip", "1").get();
10.2.3、更新文档
@Test
public void testUpdate(){
//使用工具类获取客户端对象
TransportClient client = ESClientUtil.getClient();
//修改索引
UpdateRequestBuilder updateRequestBuilder = client.prepareUpdate("shopping", "user", "1");
Map data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果设置修改内容
UpdateResponse updateResponse = updateRequestBuilder.setDoc(data).get();
System.out.println(updateResponse);
client.close();
}
10.2.4、删除文档
@Test
public void testDelete(){
//使用工具类获取客户端对象
TransportClient client = ESClientUtil.getClient();
DeleteRequestBuilder deleteRequestBuilder = client.prepareDelete("shopping", "user", "1");
DeleteResponse deleteResponse = deleteRequestBuilder.get();
System.out.println(deleteResponse);
client.close();
}
10.2.5、批量操作
@Testpublic void testBuilkAdd(){
//使用工具类获取客户端对象
TransportClient client = ESClientUtil.getClient();
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
Map data1 = new HashMap<>();
data1.put("id",11);
data1.put("username","zs");
data1.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data1));
Map data2 = new HashMap<>();
data2.put("id",22);
data2.put("username","zs");
data2.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data2));
BulkResponse bulkItemResponses = bulkRequestBuilder.get();
Iterator iterator = bulkItemResponses.iterator();
while(iterator.hasNext()){
BulkItemResponse next = iterator.next();
System.out.println(next.getResponse());
}
client.close();
}
10.3、查询
@Test
public void testSearch(){
TransportClient client = ESClientUtil.getClient();
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("shopping");
searchRequestBuilder.setTypes("user");
searchRequestBuilder.setFrom(0);
searchRequestBuilder.setSize(10);
searchRequestBuilder.addSort("age", SortOrder.ASC);
//查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
List must = boolQueryBuilder.must();
must.add(QueryBuilders.matchQuery("username" , "zs"));
List filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").lte(20).gte(10));
filter.add(QueryBuilders.termQuery("id",11));
searchRequestBuilder.setQuery(boolQueryBuilder);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
System.out.println("条数:"+hits.getTotalHits());
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSource());
}
client.close();
}