中间件Mycat
Mycat
- mycat基础概念
- Mycat安装部署
- 读写分离
- 垂直拆分——分库
- 水平拆分——分表
- 全局表
- Mycat 安全设置
-
- 权限配置
- SQL拦截
- 高可用方案
-
- 安装配置 HAProxy
- 配置 Keepalived
- 测试高可用
mycat基础概念
1、什么是MyCat
1.一个彻底开源的,面向企业应用开发的大数据库集群
2.支持事务、ACID、可以替代MySQL的加强版数据库
3.一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
4.一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
5.结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
6.一个新颖的数据库中间件产品
2、为什么使用MyCat 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系性数据库。如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储,为应对此问题就出现了——MyCat
综上所述:Mycat作用为:能满足数据库数据大量存储;提高了查询性能
1.读写分离
2.数据分片 垂直拆分(分库) 、 水平拆分(分表) 、 垂直+水平拆分(分库分表)
3.多数据源整合
3、 数据库中间件对比
① Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数
据库的schema, 集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职, Cobar停止维护。
② Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新 的功能在其中。青出于蓝而胜于蓝。
③ OneProxy基于MySQL官方的proxy思想利用c进行开发的, OneProxy是一款商业收费的中间
件。舍 弃了一些功能,专注在性能和稳定性上。
④ kingshard由小团队用go语言开发,还需要发展,需要不断完善。 ⑤ Vitess是Youtube生产在使用, 架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。
⑥Atlas是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定。
⑦ MaxScale是mariadb(MySQL原作者维护的一个版本) 研发的中间件
⑧ MySQLRoute是MySQL官方Oracle公司发布的中间件
4.支持的数据库 支持MySQL ORACLE SQLServer等一些主流的数据库
5.核心技术(分库分表) 数据库分片指:通过某种特定的条件,将我们存放在一个数据库中的数据分散存放在不同的多个数据库(主机)中,这样来达到分散单台设备的负载,根据切片规则,可分为以下两种切片模式
MyCAT通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法
1.Schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
2.Table:逻辑表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
3.DataNode:MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上
4.DataSource:定义某个物理库的访问地址,用于捆绑到Datanode上
5、分片规则:前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难
在部署Mycat之前先部署主从复制
1.master开启二进制
[root@master01 ~]# vim /etc/my.cnf
log-bin=mysql-bin
server-id=1
2.slave开启中继日志
[root@slave01 ~]# vim /etc/my.cnf
relay_log=relay-bin
relay_log_index=slave-relay-bin.index
server_id=2
3.master创建同步账号
mysql> grant replication slave on *.* to rep@'192.168.1.%' identified by '123.com';
mysql> show master status //查看master状态
4.slave执行同步SQL语句
mysql> change master to
-> master_host='192.168.1.10',
-> master_user='rep',
-> master_password='123.com',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=446;
5.启动slave
mysql> start slave;
6.查看是否成功
mysql> show slave status\G
测试
创建库,表,插入数据
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> use test;
Database changed
mysql> create table test1(id int primary key auto_increment,name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into test1(name) values('tangsan'),('xiaowu');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
Mycat安装部署
1.下载及安装
1、jdk:要求jdk必须是1.7及以上版本
2、Mysql:推荐mysql是5.5以上版本
3、Mycat:Mycat的官方网站:http://www.mycat.org.cn/
下载地址: https://github.com/MyCATApache/Mycatdownload Mycat有windows、linux多种版本。
第一步:下载Mycat-server-xxxx-linux.tar.gz
第二步:将压缩包解压缩。建议将mycat放到/usr/local/mycat目录下。
第三步:进入mycat目录,启动mycat./mycat start 停止:./mycat stop mycat支持的命令{ console | start | stop | restart | status |dump }
Mycat的默认端口号为:8066
2. 配置文件的相关配置
schema.xml: 定义逻辑库,表、分片节点等内容
rule.xml: 定义分片规则
server.xml: 定义用户以及系统相关变量,如端口等
下载jdk
[root@mycat ~]# yum -y install java-devel
下载mycat
[root@mycat ~]# wget http://dl.mycat.org.cn/1.6.7.6/20201104174609/Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz
移到/usr/local,方便管理
[root@mycat ~]# mv Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz /usr/local/
解包
[root@mycat local]# tar zxf Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz
做个软链接
[root@mycat local]# ln -s /usr/local/mycat/bin/* /usr/local/bin/
1、 修改配置文件server.xml
修改用户信息,与MySQL区分, 如下:
[root@mycat ~]# vim /usr/local/mycat/conf/server.xml
<user name="mycat" defaultAccount="true"> //修改成mycat
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
修改schema.xml
[root@mycat ~]# vim /usr/local/mycat/conf/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="test" /> //注意:这里写你的数据库名,比如我刚刚主从测试的test
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.1.10:3306" user="root" //这里是master的ip地址
password="123.com">
</writeHost>
在master创建一个用户
mysql> grant all to root@'192.168.1.%' identified by '123.com';
启动mycat
[root@mycat ~]# mycat console //这个是前台运行(一般刚开始调试的时候用到)
或
[root@mycat ~]# mycat start //这个是后台运行
Starting Mycat-server...
[root@mycat-5 ~]#
把mysql传到mycat
[root@slave01 ~]# scp /usr/local/mysql/bin/mysql root@192.168.1.13:/usr/local/bin/
测试连接
[root@mycat ~]# mysql -umycat -p123456 -h 192.168.1.13 -P 8066 //这里是java的端口
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.29-mycat-1.6.7.6-release-20201104174609 MyCat Server (OpenCloudDB)
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
可用另外两个节点登录也是可以的
mysql> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
1 row in set (0.00 sec)
mysql> use TESTDB
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| test1 |
+----------------+
1 row in set (0.01 sec)
mysql> select * from test1;
+------+---------+
| id | name |
+------+---------+
| 1 | tangsan |
| 2 | xiaowu |
+------+---------+
2 rows in set (0.04 sec)
而且在另外两台修改数据也是可以的
mysql> insert into test1(name) values('chenxin');
Query OK, 1 row affected (0.01 sec)
OK!
mysql> select * from test1;
+------+---------+
| id | name |
+------+---------+
| 1 | tangsan |
| 2 | xiaowu |
| 3 | chenxin |
+------+---------+
3 rows in set (0.01 sec)
环境:
192.168.1.10 master01
192.168.1.11 master02
192.168.1.12 slave01
192.168.1.13 mycat
读写分离
Mycat的读写分离是建立在Mysq的主从复制的基础上的 修改配置文件 schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="test" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.10:3306" user="root"
password="123.com">
<readHost host="hostS1" url="192.168.1.12:3306" user="root" password="123.com" />
</writeHost>
(1) 设置balance="1"与writeType="0"
Balance参数设置:
修改的balance属性,通过此属性配置读写分离的类型 负载均衡类型,目前的取值有4 种:
(1) balance="0",不开启读写分离机制, 所有读操作都发送到当前可用的 writeHost 上。
(2) balance="1",全部的 readHost与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从 模式(M1->S1, M2->S2,并且M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。
(3) balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。
(4) balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
WriteType参数设置:
1. writeType=“0”, 所有写操作都发送到可用的writeHost上。
2. writeType=“1”,所有写操作都随机的发送到readHost。
3. writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
“readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。”
(2) 设置switchType=“2” 与slaveThreshold="100"
switchType 目前有三种选择:
-1:表示不自动切换
1 :默认值,自动切换
2 :基于MySQL主从同步的状态决定是否切换
“Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType=“2” 与slaveThreshold=“100”,此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过检测 show slave status 中的 “Seconds_Behind_Master”, “Slave_IO_Running”, “Slave_SQL_Running” 三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。“
4、 启动程序
①控制台启动 : 去mycat/bin 目录下执行 ./mycat console
②后台启动 :去mycat/bin 目录下./mycat start 为了能第一时间看到启动日志,方便定位问题,我们选择。
登录后台管理窗口 此登录方式用于管理维护 Mycat
master01验证读写分离
vim/etc/my.cnf
binlog_format=statement
(1) 在mycat插入数据,主从主机数据不一致了
[root@master01 ~]# mysql -umycat -p123456 -h 192.168.1.13 -P 8066
mysql> insert into test1 values(4,@@hostname);
master01查看
mysql> select * from test1;
+----+----------+
| id | name |
+----+----------+
| 1 | tangsan |
| 2 | xiaowu |
| 3 | chenxin |
| 4 | master01 |
+----+----------+
slave01查看
mysql> select * from test1;
+------+---------+
| id | name |
+------+---------+
| 1 | tangsan |
| 2 | xiaowu |
| 3 | chenxin |
| 4 | slave01 |
+------+---------+
或者在master01插入 在mycat查看
垂直拆分——分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类, 分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面。
如何划分表
分库的原则: 有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
以上四个表如何分库?客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
实现分库
1、 修改 schema 配置文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="costomer" dataNode="dn2" />
</schema>
<dataNode name="dn1" dataHost="host1" database="test" />
<dataNode name="dn2" dataHost="host2" database="test" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.10:3306" user="root"
password="123.com">
<readHost host="hostS1" url="192.168.1.12:3306" user="root" password="123.com" />
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native"
switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.1.11:3306" user="root"
password="123.com">
</writeHost>
</dataHost>
</mycat:schema>
在这里需要开启master02服务器
mysql> create database test;
mysql> grant all on *.* to root@'192.168.1.%' identified by '123.com';
2、 新增两个空白库 分库操作不是在原来的老数据库上进行操作
#在数据节点 master01、slave01 上分别创建数据库 orders(做了主从复制,在一台创建就好)
mysql> create database orders;
访问 Mycat 进行分库
访问 Mycat
mysql -umycat -p123456 -h 192.168.140.128 -P 8066
切换到 TESTDB
mysql> use TESTDB
创建 4 张表
#客户表 rows:20万
create table customer(
id int auto_increment,
name varchar(200),
primary key(id)
);
#订单表 rows:600万
create table orders(
id int primary key auto_increment,
order_type int,
customer_id int,
amount decimal(10,2)
);
#订单详细表 rows:600万
create table orders_detail(
id int primary key auto_increment,
detail varchar(2000),
order_id int
);
#订单状态字典表 rows:20
create table dict_order_type(
id int primary key auto_increment,
order_type varchar(200)
);
master01,slave02查看表信息,可以看到成功分库
mysql> use test;
mysql> show tables;
+-----------------+
| Tables_in_test |
+-----------------+
| customer |
| dict_order_type |
| orders |
| orders_detail |
| test1 |
+-----------------+
5 rows in set (0.01 sec)
水平拆分——分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中, 每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就 是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。
实现分表 选择要拆分的表 MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率, 需要进行水平拆分(分表) 进行优化。 例如:例子中的 orders、 orders_detail 都已经达到600 万行数据,需要进行分表优化。 分表字段 以 orders 表为例,可以根据不同自字段进行分表
| 编号 | 分表字段 | 效果 |
|---|---|---|
| 1 | id(主键、 或创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均 |
| 2 | customer_id(客户 id) | 根据客户 id 去分,两个节点访问平均,一个客户的所有订单都在同一个节点 |
在master02 创建 orders表
create table orders(
id int auto_increment,
order_type int,
customer_id int,
amount decimal(10,2),
primary key(id)
);
修改配置文件 schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="costomer" dataNode="dn2" />
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" />
</schema>
<dataNode name="dn1" dataHost="host1" database="test" />
<dataNode name="dn2" dataHost="host2" database="test" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.10:3306" user="root"
password="123.com">
<readHost host="hostS1" url="192.168.1.12:3306" user="root" password="123.com" />
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native"
switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.1.11:3306" user="root"
password="123.com">
</writeHost>
</dataHost>
</mycat:schema>
为 orders 表设置数据节点为 dn1、 dn2, 并指定分片规则为 mod_rule(自定义的名字)
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table>
修改配置文件 rule.xml
#在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id, #还有选择分片算法 mod-long(对字段求模运算) , customer_id 对两个节点求模,根据结果分片#配置算法 mod-long 参数 count 为 2,两个节点
</tableRule>
<tableRule name="mod-rule">
<rule>
<columns>customer_id</columns> //45行左右
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
…
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property> //114行左右
</function>
5、 在数据节点 dn2 上建 orders 表 6、 重启 Mycat,让配置生效 7、 访问 Mycat 实现分片
#在 mycat 里向 orders 表插入数据, INSERT 字段不能省略
insert into orders(id,order_type,customer_id,amount) values(1,101,100,100100);
insert into orders(id,order_type,customer_id,amount) values(2,101,100,100300);
insert into orders(id,order_type,customer_id,amount) values(3,101,101,120000);
insert into orders(id,order_type,customer_id,amount) values(4,101,101,103000);
insert into orders(id,order_type,customer_id,amount) values(5,102,101,100400);
insert into orders(id,order_type,customer_id,amount) values(6,102,100,100020);
#在mycat、 master01、 master02中查看orders表数据,分表成功
master01
mysql> select * from orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 1 | 101 | 100 | 100100.00 |
| 2 | 101 | 100 | 100300.00 |
| 6 | 102 | 100 | 100020.00 |
+----+------------+-------------+-----------+
master02
mysql> select * from orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 3 | 101 | 101 | 120000.00 |
| 4 | 101 | 101 | 103000.00 |
| 5 | 102 | 101 | 100400.00 |
+----+------------+-------------+-----------+
在master02创建orders_detail表
create table orders_detail(
id int auto_increment,
detail varchar(2000),
order_id int,
primary key(id)
);
修改schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="costomer" dataNode="dn2" />
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
重启 Mycat 访问 Mycat 向 orders_detail 表插入数据
insert into orders_detail(id,detail,order_id) values (1,'detail',1);
insert into orders_detail(id,detail,order_id) values (2,'detail',2);
insert into orders_detail(id,detail,order_id) values (3,'detail',3);
insert into orders_detail(id,detail,order_id) values (4,'detail',4);
insert into orders_detail(id,detail,order_id) values (5,'detail',5);
insert into orders_detail(id,detail,order_id) values (6,'detail',6);
mysql> select orders.*,orders_detail.detail from orders_detail inner join orders on orders_detail.order_id=orders.id;
+----+------------+-------------+-----------+--------+
| id | order_type | customer_id | amount | detail |
+----+------------+-------------+-----------+--------+
| 1 | 101 | 100 | 100100.00 | detail |
| 2 | 101 | 100 | 100300.00 | detail |
| 6 | 102 | 100 | 100020.00 | detail |
| 3 | 101 | 101 | 120000.00 | detail |
| 4 | 101 | 101 | 103000.00 | detail |
| 5 | 102 | 101 | 100400.00 | detail |
+----+------------+-------------+-----------+--------+
master01查看
mysql> select orders.*,orders_detail.detail from orders_detail inner join orders on orders_detail.order_id=orders.id;
+----+------------+-------------+-----------+--------+
| id | order_type | customer_id | amount | detail |
+----+------------+-------------+-----------+--------+
| 1 | 101 | 100 | 100100.00 | detail |
| 2 | 101 | 100 | 100300.00 | detail |
| 6 | 102 | 100 | 100020.00 | detail |
+----+------------+-------------+-----------+--------+
master02查看
mysql> select orders.*,orders_detail.detail from orders_detail inner join orders on orders_detail.order_id=orders.id;
+----+------------+-------------+-----------+--------+
| id | order_type | customer_id | amount | detail |
+----+------------+-------------+-----------+--------+
| 3 | 101 | 101 | 120000.00 | detail |
| 4 | 101 | 101 | 103000.00 | detail |
| 5 | 102 | 101 | 100400.00 | detail |
+----+------------+-------------+-----------+--------+
全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联, 就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
① 变动不频繁
② 数据量总体变化不大
③ 数据规模不大,很少有超过数十万条记录
鉴于此, Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
① 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
② 全局表的查询操作,只从一个节点获取
③ 全局表可以跟任何一个表进行 JOIN 操作 将字典表或者符合字典表特性的一些表定义为全局
表,则从另外一个方面,很好的解决了数据 JOIN 的难题。 通过全局表+基于 E-R 关系的分片策略, Mycat 可以满足 80%以上的企业应用开发
#修改 schema.xml 配置文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="costomer" dataNode="dn2" />
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
<table name="dict_order_type" dataNode="dn1,dn2" type="global" />
#在dn2 创建 dict_order_type 表
create table dict_order_type(
id int auto_increment,
order_type varchar(200),
primary key(id)
);
#重启 Mycat
#访问 Mycat 向 dict_order_type 表插入数据
insert into dict_order_type (id,order_type) values (101,'type1');
insert into dict_order_type (id,order_type) values (102,'type2');
insert into dict_order_type (id,order_type) values (103,'type3');
insert into dict_order_type (id,order_type) values (104,'type4');
insert into dict_order_type (id,order_type) values (105,'type5');
insert into dict_order_type (id,order_type) values (106,'type6');
都查看一下是否有数据
mysql> select * from dict_order_type;
+-----+------------+
| id | order_type |
+-----+------------+
| 101 | type1 |
| 102 | type2 |
| 103 | type3 |
| 104 | type4 |
| 105 | type5 |
| 106 | type6 |
+-----+------------+
常用分片规则
1、 取模 此规则为对分片字段求摸运算。 也是水平分表最常用规则。 5.1 配置分表中, orders 表采用了此规则。
2、 分片枚举 通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务 需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。
在vim rule.xml可查看多种规则
Mycat 安全设置
权限配置
1.user 标签权限控制 目前 Mycat 对于中间件的连接控制并没有做太复杂的控制,目前只做了中间件逻辑库级别的读写权限控制。是通过 server.xml 的 user 标签进行配置。
#server.xml配置文件user部分
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
2.privileges 标签权限控制 在 user 标签下的 privileges 标签可以对逻辑库(schema)、表(table)进行精细化的 DML 权限控制。 privileges 标签下的 check 属性,如为 true 开启权限检查,为 false 不开启,默认为 false。 由于 Mycat 一个用户的 schemas 属性可配置多个逻辑库(schema) ,所以 privileges 的下级节点 schema 节点同样可配置多个,对多库多表进行细粒度的 DML 权限控制
#server.xml配置文件privileges部分
#配置orders表没有增删改查权限
<user name="mycat" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<privileges check="true">
<schema name="TESTDB" dml="0110" >
<table name="orders" dml="0000"></table>
</schema>
</privileges>
</user>
验证
启动mycat
[root@mycat ~]# mycat console
登录mycat验证
[root@mycat ~]# mysql -umycat -p123456 -h 192.168.1.23 -P 8066
mysql> use TESTDB
mysql> select * from orders;
ERROR 3012 (HY000): The statement DML privilege check is not passed, reject for user 'mycat'
验证表示不能够访问,用户’mycat’的DML权限检查不通过,被拒绝
配置说明
| DML权限 | 增加(insert) | 更新(update) | 查询(select) | 删除(delete) |
|---|---|---|---|---|
| 0000 | 禁止 | 禁止 | 禁止 | 禁止 |
| 0010 | 禁止 | 禁止 | 可以 | 禁止 |
| DML权限 | 增加(insert) | 更新(update) | 查询(select) | 删除(delete) |
|---|---|---|---|---|
| 1110 | 可以 | 禁止 | 禁止 | 禁止 |
| 1111 | 可以 | 可以 | 可以 | 可以 |
SQL拦截
firewall 标签用来定义防火墙; firewall 下 whitehost 标签用来定义 IP 白名单 , blacklist 用来定义SQL 黑名单。
1.白名单 可以通过设置白名单, 实现某主机某用户可以访问 Mycat,而其他主机用户禁止访问。
设置白名单
#server.xml配置文件firewall标签
#配置只有192.168.1.10主机可以通过mycat用户访问
<firewall>
<whitehost>
<host host="192.168.1.10" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
意思就是只有192.168.1.10这个主机可以通过mysql -umycat -p123456 -h 192.168.1.13 -P 8066命令登录mycat,别的主机就被禁止了
[root@mycat ~]# mysql -umycat -p123456 -h 192.168.1.13 -P 8066
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 1045 (HY000): Access denied for user 'mycat' with host '192.168.1.13'
2.黑名单 可以通过设置黑名单, 实现 Mycat 对具体 SQL 操作的拦截, 如增删改查等操作的拦截.
设置黑名单
#server.xml配置文件firewall标签
#配置禁止mycat用户进行创建操作
<firewall>
<whitehost>
<host host="192.168.1.10" user="mycat"/>
</whitehost>
<blacklist check="true">
<property name="createTableAllow">false</property>
</blacklist>
</firewall>
验证:
mysql> create database wq;
ERROR 3012 (HY000): The statement is unsafe SQL, reject for user 'mycat'
可以设置的黑名单 SQL 拦截功能列表
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| selelctAllow | true | 是否允许执行 SELECT 语句 |
| deleteAllow | true | 是否允许执行 DELETE 语句 |
| updateAllow | true | 是否允许执行 UPDATE 语句 |
| insertAllow | true | 是否允许执行 INSERT 语句 |
| createTableAllow | true | 是否允许创建表 |
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| setAllow | true | 是否允许使用 SET 语法 |
| alterTableAllow | true | 是否允许执行 Alter Table 语句 |
| dropTableAllow | true | 是否允许修改表 |
| commitAllow | true | 是否允许执行 commit 操作 |
| rollbackAllow | true | 是否允许执行 roll back 操作 |
高可用方案
在实际项目中, Mycat 服务也需要考虑高可用性,如果 Mycat 所在服务器出现宕机,或 Mycat 服务故障,需要有备机提供服务,需要考虑 Mycat 集群。
开启一台mycat02和一台haproxy,mycat02和mycat01环境一样就可以
现在环境
master2台
slave1台
mycat2台
haproxy+keeplived2台
我们可以使用 HAProxy + Keepalived 配合两台 Mycat 搭起 Mycat 集群,实现高可用性。 HAProxy实现了MyCat 多节点的集群高可用和负载均衡, 而 HAProxy 自身的高可用则可以通过 Keepalived 来实现。
安装配置 HAProxy
- 安装 HAProxy 准备好HAProxy安装包,传到/opt目录下 解压到/usr/local/src
[root@haproxy ~]# cd /usr/local/src/
[root@haproxy src]# wget https://www.haproxy.org/download/1.9/src/haproxy-1.9.16.tar.gz
[root@haproxy src]# yum -y install gcc gcc-c++
[root@haproxy src]# tar zxf haproxy-1.9.16.tar.gz
进入解压后的目录,查看内核版本, 进行编译
[root@haproxy src]# cd haproxy-1.9.16/
[root@haproxy haproxy-1.9.16]# uname -r
3.10.0-957.el7.x86_64
[root@haproxy haproxy-1.9.16]# make TARGET=linux310 PREFIX=/usr/local/haproxy ARCH=x86_64
# ARGET=linux310,内核版本,使用uname -r查看内核,如: 3.10.0-957.el7,此时该参数就为
linux310;
#ARCH=x86_64,系统位数;
#PREFIX=/usr/local/haprpxy #/usr/local/haprpxy,为haprpxy安装路径。
编译完成后,进行安装
[root@haproxy haproxy-1.9.16]# make install PREFIX=/usr/local/haproxy
配置文件中插入配置信息
[root@haproxy haproxy-1.9.16]# vim /usr/local/haproxy/haproxy.conf
添加:
global
log 127.0.0.1 local0
#log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn 4096
chroot /usr/local/haproxy
pidfile /usr/local/haproxy/haproxy.pid
uid 99
gid 99
daemon
#debug
#quiet
defaults
log global
mode tcp
option abortonclose
option redispatch
retries 3
maxconn 2000
timeout connect 5000
timeout client 50000
timeout server 50000
listen proxy_status
bind :48066
mode tcp
balance roundrobin
server mycat_1 192.168.1.13:8066 check inter 10s
server mycat_2 192.168.1.14:8066 check inter 10s
frontend admin_stats
bind :7777
mode http
stats enable
option httplog
maxconn 10
stats refresh 30s
stats uri /admin
stats auth admin:123123
stats hide-version
stats admin if TRUE
2.启动验证 启动HAProxy
[root@haproxy haproxy-1.9.16]# /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf
查看HAProxy进程
[root@haproxy haproxy-1.9.16]# ps -ef | grep haproxy
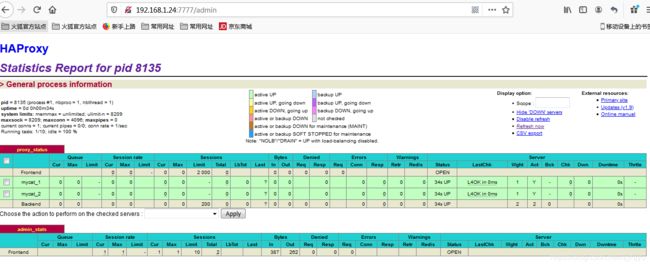
打开浏览器访问 http://192.168.1.25:7777/admin 在弹出框输入用户名: admin密码: 123123

注意:这里mycat要在启动状态,否则上图会显示down机状态
验证负载均衡,通过HAProxy访问Mycat
[root@master01 ~]# mysql -umycat -p123456 -h 192.168.1.25 -P 48066 //注意端口是48066
开启第二台harpoxy(步骤和第一台一样)
配置 Keepalived
1.安装 Keepalived 准备好Keepalived安装包,传到/opt目录下 解压到/usr/local/src
[root@haproxy ~]# cd /usr/local/src/
[root@haproxy src]# wget https://www.keepalived.org/software/keepalived-1.4.4.tar.gz
[root@haproxy src]# yum -y install gcc gcc-c++ popt-devel kernel-devel openssl-devel
[root@haproxy src]# tar zxf keepalived-1.4.4.tar.gz
进入解压后的目录, 进行配置, 进行编译安装
[root@haproxy src]# cd keepalived-1.4.4/
[root@haproxy keepalived-1.4.4]# ./configure --prefix=/ && make && make install
修改配置文件
[root@haproxy keepalived-1.4.4]# vim /etc/keepalived/keepalived.c
! Configuration File for keepalived
global_defs {
router_id LVS_01
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.100
}
}
virtual_server 192.168.1.100 48066 {
delay_loop 6
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 192.168.1.25 48066 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
real_server 192.168.1.24 48066 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
2.启动验证
启动Keepalived
[root@haproxy keepalived-1.4.4]# systemctl start keepalived
keeplived从 也就是在haproxy2的这台修改配置文件
[root@haproxy2 keepalived-1.4.4]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_02
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.100
}
}
virtual_server 192.168.1.100 48066 {
delay_loop 6
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 192.168.1.25 48066 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
real_server 192.168.1.24 48066 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
启动
[root@haproxy2 keepalived-1.4.4]# systemctl start keepalived
登录验证
[root@master01 ~]# mysql -umycat -p123456 -h 192.168.1.100 -P 48066
查看虚拟ip
[root@haproxy keepalived-1.4.4]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c4:da:4c brd ff:ff:ff:ff:ff:ff
inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.1.100/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::73fb:c47c:cd5b:5fce/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@haproxy2 keepalived-1.4.4]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:9e:c5:24 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.24/24 brd 192.168.1.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::73fb:c47c:cd5b:5fce/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::80bb:28f3:88be:5f6d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
测试高可用
- 测试 关闭mycat 通过虚拟ip查询数据
[root@master01 ~]# mysql -umycat -p123456 -h 192.168.1.100 -P 48066