使用 NCS2 异步推理——人脸识别
环境:
- Python:3.7.3
- OpenVINO:2021.4.582
- g++ (Raspbian 8.3.0-6+rpi1) 8.3.0
- raspberrypi:5.10.52-v7l+
- 系统指令集:armv7l
组件:
- Raspberry Pi 4B 8G
- NCS2
人脸检测器基于 MobileNetV2 作为主干,带有多个 SSD 头,用于前置摄像头拍摄的室内和室外场景。在这个模型的训练过程中,训练图像被调整为 384x384。
下载人脸识别模型:
https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.2/models_bin/3/face-detection-0202/FP32/face-detection-0202.xml
https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.2/models_bin/3/face-detection-0202/FP32/face-detection-0202.bin
输入
名称:input,形状:[1 x 3 x 384 x 384] - 格式为 [B x C x H x W] 的输入图像,其中:
- B :批量大小
- C :通道数
- H :图像高度
- W :图像宽度
预期颜色顺序:BGR。
输出
网络输出 blob 的形状为:[1, 1, N, 7],其中 N 是检测到的边界框的数量。每个检测都具有 [ image_id, label, conf, x_min, y_min, x_max, y_max]格式,其中:
- image_id :批次中图像的 ID
- label :预测类 ID(0 :人脸)
- conf :对预测类别的置信度
- (x_min, y_min) : 左上边界框角的坐标
- (x_max, y_max) : 右下边界框角的坐标。
使用Python代码测试
from openvino.inference_engine import IECore
import time
import cv2 as cv
# 配置推断计算设备,IR文件路径
model_xml = "face-detection-0202.xml"
model_bin = "face-detection-0202.bin"
DEVICE = 'MYRIAD'
# DEVICE = 'CPU'
# 异步加载摄像头
def ssd_webcam_demo():
# 初始化插件,输出插件版本号
ie = IECore()
for device in ie.available_devices:
print(device)
# 读取IR模型文件
net = ie.read_network(model=model_xml, weights=model_bin)
# 准备输入输出张量
print("Preparing input blobs")
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))
# 读入图片
n, c, h, w = net.input_info[input_blob].input_data.shape
print(n, c, h, w)
# 打开摄像头
cap = cv.VideoCapture(2)
ret, frame = cap.read()
curr_request_id = 0
next_request_id = 1
# 载入模型到AI推断计算设备
print("Loading IR to the plugin...")
# exec_net = ie.load_network(network=net, device_name=DEVICE) # 同步推理
exec_net = ie.load_network(network=net, device_name=DEVICE, num_requests=2) # 异步推理
while True:
ret, next_frame = cap.read()
if ret is not True:
break
image = cv.resize(frame, (w, h))
image = image.transpose(2, 0, 1)
# 执行推断计算
print("Starting inference in synchronous mode")
inf_start = time.time()
# res = exec_net.infer(inputs={input_blob: [image]}) # 调用同步推理
exec_net.start_async(request_id=next_request_id, inputs={input_blob: [image]}) # 调用异步推理
inf_end = time.time() - inf_start
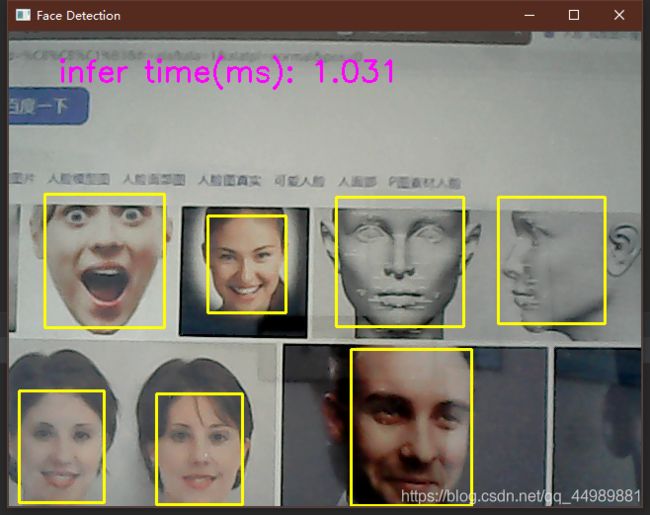
print("infer time(ms):%.3f" % (inf_end * 1000))
# 根据状态检查
if exec_net.requests[curr_request_id].wait(-1) == 0:
res = exec_net.requests[curr_request_id].output_blobs[out_blob].buffer
# 处理输出
ih, iw, ic = frame.shape
for obj in res[0][0]:
if obj[2] > 0.75:
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
cv.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 255), 2, 8)
cv.putText(frame, "infer time(ms): %.3f" % (inf_end * 1000), (50, 50), cv.FONT_HERSHEY_SIMPLEX, 1.0,
(255, 0, 255),
2, 8)
cv.imshow("Face Detection", frame)
c = cv.waitKey(1)
if c == 27:
break
# 交换数据
frame = next_frame
curr_request_id, next_request_id = next_request_id, curr_request_id
cv.waitKey(0)
cv.destroyAllWindows()
if __name__ == "__main__":
ssd_webcam_demo()
face-detection-adas-0001.xml 文件下载网址:https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16
Linux下载 网络和权重文件
wget --no-check-certificate https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.bin
wget --no-check-certificate https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.xml
pi@raspberrypi:~/Desktop/vision_ai $ wget --no-check-certificate https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.xml
–2021-09-27 19:33:49-- https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.xml
已发出 HTTP 请求,正在等待回应… 200 OK
长度:225964 (221K) [text/xml]
正在保存至: “face-detection-adas-0001.xml”
face-detection-adas 100%[===================>] 220.67K 650KB/s 用时 0.3s
2021-09-27 19:33:51 (650 KB/s) - 已保存 “face-detection-adas-0001.xml” [225964/225964])
pi@raspberrypi:~/Desktop/vision_ai $ wget --no-check-certificate https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.bin
–2021-09-27 19:34:06-- https://download.01.org/opencv/2021/openvinotoolkit/2021.2/open_model_zoo/models_bin/3/face-detection-adas-0001/FP16/face-detection-adas-0001.bin
已发出 HTTP 请求,正在等待回应… 200 OK
长度:2106088 (2.0M) [application/octet-stream]
正在保存至: “face-detection-adas-0001.bin”
face-detection-adas 100%[===================>] 2.01M 2.40MB/s 用时 0.8s
2021-09-27 19:34:07 (2.40 MB/s) - 已保存 “face-detection-adas-0001.bin” [2106088/2106088])
#!/usr/bin/env python3
from __future__ import print_function
import sys
import os
from argparse import ArgumentParser, SUPPRESS
import cv2
import time
import logging as log
from openvino.inference_engine import IECore
def build_argparser():
parser = ArgumentParser(add_help=False)
args = parser.add_argument_group('Options')
args.add_argument('-h', '--help', action='help', default=SUPPRESS, help='Show this help message and exit.')
args.add_argument("-m", "--model", help="Required. Path to an .xml file with a trained model.",
default="./model/face-detection-adas-0001.xml", type=str)
args.add_argument("-i", "--input",
help="Required. Path to video file or image. 'cam' for capturing video stream from camera",
required=False, type=str)
args.add_argument("-l", "--cpu_extension",
help="Optional. Required for CPU custom layers. Absolute path to a shared library with the "
"kernels implementations.", type=str, default=None)
args.add_argument("-d", "--device",
help="Optional. Specify the target device to infer on; CPU, GPU, FPGA, HDDL or MYRIAD is "
"acceptable. The demo will look for a suitable plugin for device specified. "
"Default value is CPU", default="MYRIAD", type=str)
args.add_argument("--labels", help="Optional. Path to labels mapping file", default=None ,type=str)
args.add_argument("-pt", "--prob_threshold", help="Optional. Probability threshold for detections filtering",
default=0.5, type=float)
args.add_argument("--no_show", help="Optional. Don't show output", action='store_true')
return parser
def main():
log.basicConfig(format="[ %(levelname)s ] %(message)s", level=log.INFO, stream=sys.stdout)
args = build_argparser().parse_args()
log.info("Creating Inference Engine...")
ie = IECore()
if args.cpu_extension and 'CPU' in args.device:
ie.add_extension(args.cpu_extension, "CPU")
# Read IR
log.info("Loading network")
net = ie.read_network(args.model, os.path.splitext(args.model)[0] + ".bin")
if "CPU" in args.device:
supported_layers = ie.query_network(net, "CPU")
not_supported_layers = [l for l in net.layers.keys() if l not in supported_layers]
if len(not_supported_layers) != 0:
log.error("Following layers are not supported by the plugin for specified device {}:\n {}".
format(args.device, ', '.join(not_supported_layers)))
log.error("Please try to specify cpu extensions library path in sample's command line parameters using -l "
"or --cpu_extension command line argument")
sys.exit(1)
img_info_input_blob = None
feed_dict = {}
for blob_name in net.inputs:
if len(net.inputs[blob_name].shape) == 4:
input_blob = blob_name
elif len(net.inputs[blob_name].shape) == 2:
img_info_input_blob = blob_name
else:
raise RuntimeError("Unsupported {}D input layer '{}'. Only 2D and 4D input layers are supported"
.format(len(net.inputs[blob_name].shape), blob_name))
assert len(net.outputs) == 1, "Demo supports only single output topologies"
out_blob = next(iter(net.outputs))
log.info("Loading IR to the plugin...")
exec_net = ie.load_network(network=net, num_requests=2, device_name=args.device)
# Read and pre-process input image
n, c, h, w = net.inputs[input_blob].shape
if img_info_input_blob:
feed_dict[img_info_input_blob] = [h, w, 1]
if args.input == 'cam':
input_stream = 0
else:
input_stream = args.input
#cap = cv2.VideoCapture(input_stream)
cap = cv2.VideoCapture(0)
assert cap.isOpened(), "Can't open " + input_stream
if args.labels:
with open(args.labels, 'r') as f:
labels_map = [x.strip() for x in f]
else:
labels_map = None
cur_request_id = 0
next_request_id = 1
log.info("Starting inference in async mode...")
is_async_mode = True
render_time = 0
if is_async_mode:
ret, frame = cap.read()
frame_h, frame_w = frame.shape[:2]
print("To close the application, press 'CTRL+C' here or switch to the output window and press ESC key")
print("To switch between sync/async modes, press TAB key in the output window")
while cap.isOpened():
if is_async_mode:
ret, next_frame = cap.read()
else:
ret, frame = cap.read()
if ret:
frame_h, frame_w = frame.shape[:2]
if not ret:
break # abandons the last frame in case of async_mode
# Main sync point:
# in the truly Async mode we start the NEXT infer request, while waiting for the CURRENT to complete
# in the regular mode we start the CURRENT request and immediately wait for it's completion
inf_start = time.time()
if is_async_mode:
in_frame = cv2.resize(next_frame, (w, h))
in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
feed_dict[input_blob] = in_frame
exec_net.start_async(request_id=next_request_id, inputs=feed_dict)
else:
in_frame = cv2.resize(frame, (w, h))
in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
feed_dict[input_blob] = in_frame
exec_net.start_async(request_id=cur_request_id, inputs=feed_dict)
if exec_net.requests[cur_request_id].wait(-1) == 0:
inf_end = time.time()
det_time = inf_end - inf_start
# Parse detection results of the current request
res = exec_net.requests[cur_request_id].outputs[out_blob]
for obj in res[0][0]:
# Draw only objects when probability more than specified threshold
if obj[2] > args.prob_threshold:
xmin = int(obj[3] * frame_w)
ymin = int(obj[4] * frame_h)
xmax = int(obj[5] * frame_w)
ymax = int(obj[6] * frame_h)
class_id = int(obj[1])
# Draw box and label\class_id
#color = (min(class_id * 12.5, 255), min(class_id * 7, 255), min(class_id * 5, 255))
#color = (min(class_id * 60, 255), min(class_id * 60, 255), min(class_id * 60, 255))
color = [(0,0,0),(0,255,0),(255,0,0),(255,255,255),(0,0,0),(203,192,255),(238,130,238),(0,69,255) ]
#print(color[class_id])
#print(obj)
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), color[class_id], 2)
#print(class_id)
det_label = labels_map[class_id] if labels_map else str(class_id)
cv2.putText(frame, 'face' + ' ' + str(round(obj[2] * 100, 1)) + ' %', (xmin, ymin - 7),
cv2.FONT_HERSHEY_COMPLEX, 0.6,(0,255,0), 1)
# Draw performance stats
inf_time_message = "Inference time: N\A for async mode" if is_async_mode else \
"Inference time: {:.3f} ms".format(det_time * 1000)
render_time_message = "OpenCV rendering time: {:.3f} ms".format(render_time * 1000)
async_mode_message = "Async mode is on. Processing request {}".format(cur_request_id) if is_async_mode else \
"Async mode is off. Processing request {}".format(cur_request_id)
cv2.putText(frame, inf_time_message, (15, 15), cv2.FONT_HERSHEY_COMPLEX, 0.5, (200, 10, 10), 1)
cv2.putText(frame, render_time_message, (15, 30), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
cv2.putText(frame, async_mode_message, (10, int(frame_h - 20)), cv2.FONT_HERSHEY_COMPLEX, 0.5,
(10, 10, 200), 1)
#
render_start = time.time()
if not args.no_show:
cv2.imshow("Detection Results", frame)
render_end = time.time()
render_time = render_end - render_start
if is_async_mode:
cur_request_id, next_request_id = next_request_id, cur_request_id
frame = next_frame
frame_h, frame_w = frame.shape[:2]
if not args.no_show:
key = cv2.waitKey(1)
if key == 27:
break
if (9 == key):
is_async_mode = not is_async_mode
log.info("Switched to {} mode".format("async" if is_async_mode else "sync"))
cv2.destroyAllWindows()
if __name__ == '__main__':
sys.exit(main() or 0)
运行结果:

出现问题:
缺少 openvino 模块
Traceback (most recent call last):
File “./demo/OpenVINO/python/openvino_inference.py”, line 15, in
from openvino.inference_engine import IECore
ModuleNotFoundError: No module named ‘openvino’
Raspberry Pi 4B安装 OpenVINO™ 工具包:
https://blog.csdn.net/qq_44989881/article/details/119792769?spm=1001.2014.3001.5501
或者
设置 openvino 的环境变量
source /opt/intel/openvino_2021/bin/setupvars.sh
pi@raspberrypi:~/Desktop $ source /opt/intel/openvino_2021/bin/setupvars.sh
[setupvars.sh] OpenVINO environment initialized