【重识云原生】第四章云网络4.4节——Spine-Leaf网络架构
《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第三章云存储第1节——分布式云存储总述
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow

1 CLOS网络模型历史起源
1953年,贝尔实验室有一位名叫Charles Clos的研究员,发表了一篇名为《A Study of Non-blocking Switching Networks》的文章,介绍了一种“用多级设备来实现无阻塞电话交换”的方法。
自从1876年电话被发明之后,电话交换网络历经了人工交换机、步进制交换机、纵横制交换机等多个阶段。20世纪50年代,纵横制交换机处于鼎盛时期。
纵横交换机的核心,是纵横连接器。如下图所示:

纵横制接线器

纵横连接器交叉点示意图
这种交换架构,是一种开关矩阵,每个交点(Crosspoint)都是一个开关。交换机通过控制开关,来完成从输入到输出的转发。

开关矩阵(交点数量=N2)
可以看出,开关矩阵很像一块布的纤维。所以,交换机的内部架构,被称为Switch Fabric。Fabric,就是“纤维、布料”的意思。
Fabric这个词,我相信所有核心网工程师和数通工程师都非常熟悉。“Fabric平面”、“Fabric总线”等概念,经常出现在工作中。
随着电话用户数量急剧增加,网络规模快速扩大,基于crossbar模型的交换机在能力和成本上都无法满足要求。于是,才有了文章开头Charles Clos的那篇研究文章。

Charles Clos(右一)
Charles Clos提出的网络模型,核心思想是:用多个小规模、低成本的单元,构建复杂、大规模的网络。例如下图:

图中的矩形,都是低成本的转发单元。当输入和输出增加时,中间的交叉点并不需要增加很多。
这种模型,就是后来产生深远影响的CLOS网络模型。
到了80年代,随着计算机网络的兴起,开始出现了各种网络拓扑结构,例如星型、链型、环型、树型。
树型网络逐渐成为主流,如下图所示。
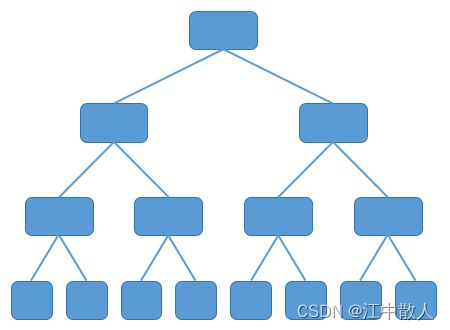
树型网络
传统的树型网络,带宽是逐级收敛的。什么是收敛呢?物理端口带宽一致,二进一出,不就1:2的收敛了嘛。

2 数据中心网络架构演进
2000年之后,互联网从经济危机中复苏,以谷歌和亚马逊为代表的互联网巨头开始崛起。他们开始推行云计算技术,建设大量的数据中心(IDC),甚至超级数据中心。
面对日益庞大的计算规模,传统树型网络肯定是不行的了。于是,一种改进型树型网络开始出现,它就是胖树(Fat-Tree)架构。
胖树(Fat-Tree)就是一种CLOS网络架构。
相比于传统树型,胖树(Fat-Tree)更像是真实的树,越到树根,枝干越粗。从叶子到树根,网络带宽不收敛。

胖树架构的基本理念是:使用大量的低性能交换机,构建出大规模的无阻塞网络。对于任意的通信模式,总有路径让他们的通信带宽达到网卡带宽。
胖树架构被引入到数据中心之后,数据中心变成了传统的三层结构:

这种架构由核心路由器、聚合路由器(有时叫分发路由器,distribution routers )和接入交换机组成。在接入交换机和聚合路由器之间运行生成树协议(Spanning Tree Protocol,STP),以保证网络的二层部分(L2)没有环路。STP 有许多好处:简单, 即插即用(plug-and-play),只需很少配置。每个 pod 内的机器都属于同一个 VLAN, 因此服务器无需修改 IP 地址和网关就可以在 pod 内部任意迁移位置。但是,STP 无法 使用并行转发路径(parallel forwarding path),它永远会禁用 VLAN 内的冗余路径。
- 接入层:接入交换机通常位于机架顶部,用于连接所有的计算节点服务器,所以它们也被称为ToR(Top of Rack)交换机。
- 汇聚层:用于接入层的互联,并作为该汇聚区域二三层的边界。汇聚交换机连接同一个二层网络(VLAN)下的接入交换机,同时提供其他的服务,例如防火墙,SSL offload,入侵检测,网络分析等, 它可以是二层交换机也可以是三层交换机。
- 核心层: 用于汇聚层的的互联,并实现整个数据中心与外部网络的三层通信。此层的核心交换机为进出数据中心的包提供高速的转发,为多个二层局域网(VLAN)提供连接性,核心交换机为通常为整个网络提供一个弹性的三层网络。

在很长的一段时间里,三层网络结构在数据中心十分盛行。在这种架构中,铜缆布线是主要的布线方式,使用率达到了80%。而光缆,只占了20%。
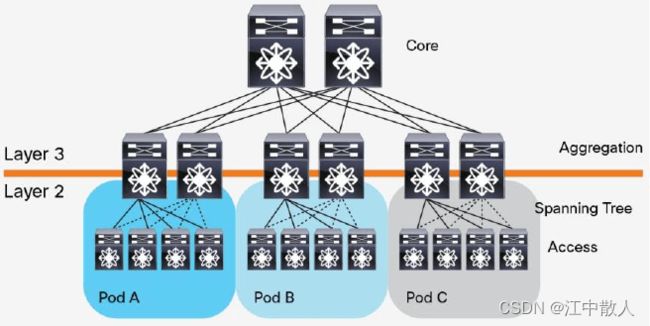
传统三层(Three-Tier)数据中心设计
在这种网络架构下,存在如下的一些弊端:
- 带宽的浪费:为了防止环路,汇聚层和接入层之间通常会运行STP协议,使得接入交换机的上联链路中实际承载流量的只有一条,而其他上行链路将被阻塞(如图中虚线所示),造成了带宽的浪费;
- 故障域较大:STP协议由于其本身的算法,在网络拓扑发生变更时需要重新收敛,容易发生故障,从而影响整个VLAN的网络;
- 难以适应超大规模网络:在云计算领域,网络规模扩大,数据中心也分布在不同的地理位置,虚拟机要求能在任意地点创建,迁移,而保持其网络属性(IP, 网关等)保持不变,需要支持大二层网络,在上图的拓扑中,无法在VLAN10和VLAN20之间作上述迁移;
对于上述带宽浪费的问题,思科提出的解决方案是vPC(virtual Port Channel)协议,可以将接入交换机的两条上行链路做成一个vPC,同时承载流量,从而避免了带宽的浪费,提升了带宽的利用率,然而,一方面,这种方案仍然无法做到水平扩展,因为vPC只支持最多两个上行链路,上行链路增多时,无法线性增加带宽;另一方面,vPC是思科的私有协议,对于厂商的依赖性强,成本上不具有优势,下图为vPC的架构图,使用 vPC 技术时,STP 会作为备用机制( fail-safe mechanism):
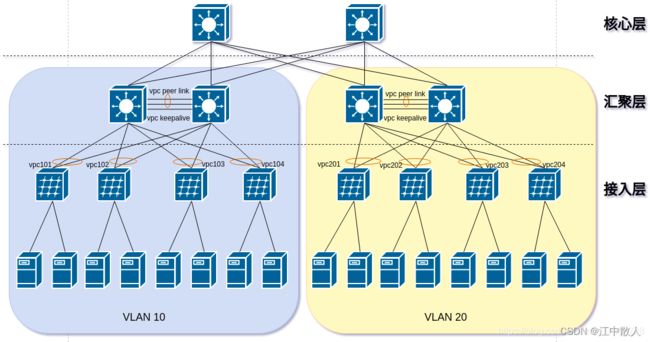
使用 vPC 技术的数据中心设计
上图的方案提高了带宽利用率,但仍没有解决大二层的问题,解决方案是将核心层以下的部分全部放在同一个二层网络中,但是,同一个二层网络中容纳如此多的设备,二层网络中的广播风暴将随着设备的增加而越来越严重,最终给交换机带来沉重的负载,从而影响流量,下图为传统网络大二层的解决方案示意图:

从 2003 年开始,随着虚拟化技术的引入,原来三层(three-tier)数据中心中,在二层(L2)以 pod 形式做了隔离的计算、网络和存储资源,现在都可以被池化(pooled)。这种革命性的技术产生了从接入层到核心层的大二层域(larger L2 domain)的需求,如图 3 所示 。

扩展的 L3 域的数据中心设计
随着 L2 segment(二层网络段,例如 VLAN 划分的二层网络,译者注)被扩展到所有 pod ,数据中心的管理员可以创建一个集中式的、更加灵活的、能够按需分配的资源池。物理服务器被虚拟化为许多虚拟服务器(VM),无需修改运维参数就可以在物理服务器之间自由漂移。
与此同时,微服务架构开始流行,很多软件开始推行功能解耦,单个服务变成了多个服务,部署在不同的虚拟机上。虚拟机之间的流量,大幅增加。
这种平级设备之间的数据流动,我们称之为“东西向流量”。相对应的,那种上上下下的垂直数据流动,称为“南北向流量”,如下图所示:

东西向流量,其实也就是一种“内部流量”。这种数据流量的大幅增加,给传统三层架构带来了很大的麻烦——因为服务器和服务器之间的通信,需要经过接入交换机、汇聚交换机和核心交换机。

数据流向举例
这意味着,核心交换机和汇聚交换机的工作压力不断增加。要支持大规模的网络,就必须有性能最好、端口密度最大的汇聚层核心层设备。这样的设备成本高,价格非常昂贵。
针对以上问题,网络工程师们提出了一种新的数据中心设计,称作基于 Clos 网络的 Spine-and-Leaf 架构(Clos network-based Spine-and-Leaf architecture,中文也翻译成叶脊网络)。事实已经证明,这种架构可以提供高带宽、低延迟、非阻塞的服务器到服务器连接。
3 Spine-Leaf 架构
3.1 Spine-Leaf 架构简介
相比于传统网络的三层架构,叶脊网络进行了扁平化,变成了两层架构。如下图所示:

叶交换机,相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。叶交换机之上是三层网络,之下都是个独立的 L2 广播域。如果说两个叶交换机下的服务器需要通信,需要经由脊交换机进行转发。脊交换机,相当于核心交换机。叶和脊交换机之间通过ECMP(Equal Cost Multi Path)动态选择多条路径。
在以上两级 Clos 架构中,每个低层级的交换机(leaf)都会连接到每个高层级的交换机 (spine),形成一个 full-mesh 拓扑。leaf 层由接入交换机组成,用于连接服务器等设备。spine 层是网络的骨干(backbone),负责将所有的 leaf 连接起来。 fabric 中的每个leaf都会连接到每个spine,如果一个spine挂了,数据中心的吞吐性能只会有轻微的下降(slightly degrade)。
如果某个链路被打满了,扩容过程也很直接:添加一个 spine 交换机就可以扩展每个 leaf 的上行链路,增大了 leaf 和 spine 之间的带宽,缓解了链路被打爆的问题。如果接入层的端口数量成为了瓶颈,那就直接添加一个新的 leaf,然后将其连接到每个 spine 并做相应的配置即可。这种易于扩展(ease of expansion)的特性优化了 IT 部门扩展网络的过程。leaf 层的接入端口和上行链路都没有瓶颈时,这个架构就实现了无阻塞(nonblocking)。
在 Spine-and-Leaf 架构中,任意一个服务器到另一个服务器的连接,都会经过相同数量的设备(除非这两个服务器在同一 leaf 下面),这保证了延迟是可预测的,因为一个包只需要经过一个 spine 和另一个 leaf 就可以到达目的端。
3.2 Spine-Leaf 架构优势
Spine-Leaf 架构的优势非常明显:
1、带宽利用率高
每个叶交换机的上行链路,以负载均衡方式工作,充分的利用了带宽。
2、网络延迟可预测
在以上模型中,叶交换机之间的连通路径的条数可确定,均只需经过一个脊交换机,东西向网络延时可预测。
3、扩展性好
当带宽不足时,增加脊交换机数量,可水平扩展带宽。当服务器数量增加时,增加脊交换机数量,也可以扩大数据中心规模。总之,规划和扩容非常方便。
4、降低对交换机的要求
南北向流量,可以从叶节点出去,也可从脊节点出去。东西向流量,分布在多条路径上。这样一来,不需要昂贵的高性能高带宽交换机。
5、安全性和可用性高
传统网络采用STP协议,当一台设备故障时就会重新收敛,影响网络性能甚至发生故障。叶脊架构中,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。

思科的Nexus 9396PX,适合作为叶交换机
3.3 Spine-Leaf 架构网络规模测算方法
脊交换机下行端口数量,决定了叶交换机的数量。而叶交换机上行端口数量,决定了脊交换机的数量。它们共同决定了叶脊网络的规模。接下来我们可以根据交换机的端口数量和带宽,对Spine-Leaf 架构的网络适用的规模进行简单的估计,如下图所示的拓扑:

估算基于以下假设:
- spine数量:16台
- 每个spine的下联端口:48个 × 100G
- spine上联端口:16个 × 100G
- leaf数量:48台
- 每个leaf的下联端口:64个 × 25G
- leaf的上联端口: 16个 × 25G
spine的下联端口数量和LEAF的上联端口数量相同,以充分利用端口,在考虑链路Spine-Leaf 之间的带宽全部跑满的情况下,每个leaf下联的服务器数量最多为:
![]()
即刚好等于leaf的下联端口数量,总共可支持的服务器数量为:
![]()
也就是说,在上述假设下,一组Spine-Leaf 网络可以支持3072台服务器(注意,叶脊交换机北向总带宽一般不会和南向总带宽一致,通常大于1:3即可。上例为400:640,有点奢侈了。),这是相当于一个中大型规模的数据中心,那么如果仍有扩展的需求该怎么办呢?根据上述的计算,leaf和spine的下联端口都已经耗尽,在这个网络中已无法增加spine,leaf或服务器。
3.4 Facebook的Fabric网络架构
Spine-Leaf 网络从2013年左右开始出现,发展速度惊人,很快就取代了大量的传统三层网络架构,成为现代数据中心的新宠。最具有代表性的,是Facebook在2014年公开的数据中心架构。Facebook使用了一个五级CLOS架构,甚至是一个立体的架构。

在这种架构中,我们的Spine-Leaf 网络是其中的一个POD, 我们的SPINE是图中的Fabric Switches,我们的leaf是图中的Rack Switches,最上面的Spine Switches把各个POD连通起来。当一个POD的容量已满时,可以增加POD,并用spine将这些POD连通起来,实现了网络的继续扩展。除了前面描述的POD和spine,上图中还有黄色的Edge Plane,这是为数据中心提供南北向流量的模块。它们与spine交换机的连接方式,与前文中简单的的Spine-Leaf 架构一样。并且它们也是可以水平扩展的。
Spine-Leaf 网络架构只是一种网络部署的拓扑方式,具体的实现方法与配置多种多样,有的厂商根据这种拓扑结构定义了特定的网络协议,如思科的Fabric Path等。
参考链接
到底什么是叶脊网络(Spine-Leaf)?_交换机
【网络】叶脊(Spine-Leaf)网络拓扑下全三层网络设计与实践(一) - 叶脊网络架构简介_eponia的博客-CSDN博客_spine-leaf
【网络】叶脊(Spine-Leaf)网络拓扑下全三层网络设计与实践(七) - 负载均衡及高可用_eponia的博客-CSDN博客
数据中心网络:Spine-Leaf 架构设计综述(2016) - tycoon3 - 博客园
每日一学|数据中心spine leaf网络架构_weixin_33857679的博客-CSDN博客
为什么选择leaf-spine网络架构?对比传统三层架构具有哪些优势? | 易飞扬社区
网络专题
「网络技术控」数据中心网络走向Spine-Leaf架构