Redis5种数据结构解析
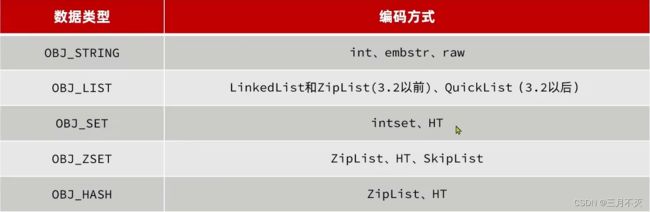
Redis数据结构
Redis 5大数据结构都是基于动态字符串SDS、lntSet、Dict、ZipList、QuickList、SkipList、RedisObject实现的,所以先来介绍这几种数据结构
动态字符串SDS
Redis使用C实验实现的,但是Redis没有使用C语言的字符串
//C语言,声明字符串char* s="hello";
//本质是字符数组:{ 'h', 'e', 'l', 'l', 'o', '/0'}
存在问题:
1、获取字符串长度的需要通过运算;
2、非二进制安全,不能包含/0,否则会提前结束
3、不可修改
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。
在执行 set name sanyue 时,底层创建了两个SDS
SDS是一个结构体,源码如下:

上图中unit8表示无符号整型,8个bit位,最大就是255
第三个属性flags表示不同SDS类型,目的控制SDS头大小节省空间。假如固定都是64位,那么len,alloc就占12字节,能存储2^64-1个字节大小的数据,但大部分时候,字符串数据量都比较小,所以定义了不同的类型使用,有5、8、16、32、64,如下

一个"name"的SDS如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7wGCiohz-1657941415489)(network-img/image-20220716063356037.png)]](http://img.e-com-net.com/image/info8/0549043f29b2454bbb5280b00b75b074.jpg)
读取数据时,他是通过长度控制读数据的,所以是二进制安全 ,不会因为\0提前结束

IntSet
lntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:
typedef struct intset {
uint32_t encoding; /*编码方式,支持存放16位、32位、64位整数*/
uint32_t length; /*元素个数*/
int8_t contents[] /*整数数组,保存集合数据*///(contents前的int8并不表示数组长度,contents相当于指针,指向数组首元素)
}intset;
其中的encoding包含三种模式,表示存储的整数大小不同:
/*Note that these encodings are ordered,so:
*INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64.*/
#define INTSET_ENC_INT16 (sizeof(int16_t)) /*2字节整数,范围类似java的short*/
#define INTSET_ENC_INT32 (sizeof(int32_t)) /*4字节整数,范围类似java的int */
#define INTSET_ENC_INT64 (sizeof(int64_t)) /*8字节整数,范围类似java的long*/
为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:
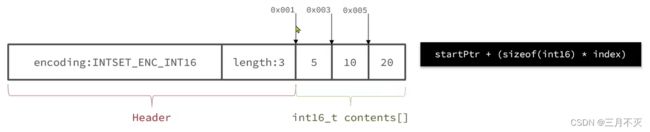
每个字符大小取决于编码方式,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding: 4字节
- length: 4字节
- contents: 2字节* 3 =6字节
为什么要统一编码方式,为了方便基于角标获取元素,C语言操作内存中的数据都是通过指针寻址。
向上述寻址公式=起始位置+元素角标*元素字节数
lntSet升级
现在,假设有一个intset,元素为{5,10,20},采用的编码是INTSET_ENC_INT16,则每个整数占2字节。

)]
我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
1、升级编码为INTSET_ENC_INT32,每个整数占4字节,并按照新的编码方式及元素个数扩容数组
2、倒序依次将数组中的元素拷贝到扩容后的正确位置
3、将待添加的元素放入数组末尾
4、最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sef5C7C8-1657941415491)(network-img/image-20220716063201453.png)]](http://img.e-com-net.com/image/info8/2663ef06ccd649459bce59295db76060.jpg)
IntSet增伤改查源码如下:
/* Insert an integer in the intset */
/**is:要插入的集合
*value:要插入的元素
*success:保存函数执行的结果
*/
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
//获取当前值编码
uint8_t valenc = _intsetValueEncoding(value);
//要插入的位置
uint32_t pos;
if (success) *success = 1;
//判断当前编码是否超过了当前的intset编码
if (valenc > intrev32ifbe(is->encoding)) {
//超出编码,需要升级
return intsetUpgradeAndAdd(is,value);
} else {
//在当前intset中查找值与value一样的元素的角标pos
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;//如果找到了,则无需插入,直接结束并返回失败
return is;
}
//数组扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
//移动数组中pos之后的元素的pos+1,给新元素腾空间
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
//插入新元素
_intsetSet(is,pos,value);
//移动数组中pos之后的元素的pos+1,给新元素腾出空间
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
/* Delete integer from intset */
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
//如果value 大小 <= 当前编码表示范围且集合中存在存在该元素,则可以删除
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) {
uint32_t len = intrev32ifbe(is->length);
/* We know we can delete */
if (success) *success = 1;
/* Overwrite value with tail and update length */
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos);//将pos+1后的元素往前移动
is = intsetResize(is,len-1);
is->length = intrev32ifbe(len-1);//更新集合元素个数
}
return is;
}
/* Upgrades the intset to a larger encoding and inserts the given integer. */
//插入元素可能在所有元素之前或所有元素之后
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
//获取当前intset编码
uint8_t curenc = intrev32ifbe(is->encoding);
//获取新编码
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);//获取元素个数
//判断新元素是大于0还是小于0,小于0插入队首、大于0插入队尾
int prepend = value < 0 ? 1 : 0;
//重置编码为新编码
is->encoding = intrev32ifbe(newenc);
//重置数组大小
is = intsetResize(is,intrev32ifbe(is->length)+1);
//倒叙遍历,逐个搬运元素到新的位置,——intsetGetEncode按照旧编码方式查找旧元素
while(length--)//_intsetSet按照新编码方式插入新元素
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));//把_intsetGetEncoded(is,length,curenc)元素插入到is的length+prehend位置
//插入新元素,prepend决定是队首还是队尾
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);//修改数组长度
return is;
}
/* Search for the position of "value". Return 1 when the value was found and
* sets "pos" to the position of the value within the intset. Return 0 when
* the value is not present in the intset and sets "pos" to the position
* where "value" can be inserted. */
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
//初始二分查找需要的元素min,max,mid
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;//mid对应的值
//如果数组为空则不用找了
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
//数组不为空,判断value是否大于最大值,小于最小值
if (value > _intsetGet(is,max)) {//大于最大值,不用找了,插入队尾
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {//小于最小值,不用找了,插入队首
if (pos) *pos = 0;
return 0;
}
}
//二分查找
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
lntset可以看做是特殊的整数数组,具备一些特点:
1、Redis会确保Intset中的元素唯一、有序
2、具备类型升级机制,可以节省内存空间
3、底层采用二分查找方式来查询
Dict
Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)


当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用h & sizemask(即h%表长)来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3=1,因此k1=v1要存储到数组角标1位置。

redis单线程,头插法不会出现死循环
不同场景使用的hash函数不一样,所以type区分不同类型
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size),满足以下两种情况时会触发哈希表扩容:
- 哈希表的LoadFactor >=1,并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程;
- 哈希表的LoadFactor > 5 ;

/* return DICT_ERR if expand was not performed */
int dictExpand(dict *d, unsigned long size) {
return _dictExpand(d, size, NULL);
}
/* Expand or create the hash table,
* when malloc_failed is non-NULL, it'll avoid panic if malloc fails (in which case it'll be set to 1).
* Returns DICT_OK if expand was performed, and DICT_ERR if skipped. */
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
/*/如果当前entry数量超过了要申请的size大小,或者正在rehash,直接报错*/
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
//声明新的hash Table
dictht n; /* the new hash table */
//实际大小,第一个大于等于size的2^n次方
unsigned long realsize = _dictNextPower(size);
/* Detect overflows 超出LONG_MAX,说明内存溢出,报错*/
if (realsize < size || realsize * sizeof(dictEntry*) < realsize)
return DICT_ERR;
/* Rehashing to the same table size is not useful. 新的size如果与旧的一致,报错*/
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;//重置新的hash table大小和掩码
n.sizemask = realsize-1;
if (malloc_failed) {
n.table = ztrycalloc(realsize*sizeof(dictEntry*));
*malloc_failed = n.table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else//分配内存: size * entrySize
n.table = zcalloc(realsize*sizeof(dictEntry*));
//已使用初始化为0
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys.
如果是第一次,则直接把n赋值给ht[0]即可
*/
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//否则,需要rehash,此处只需要把rehashidx置为0即可。在每次增、删、改、查时都会触发rehash
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;//d->rehashidx=-1,没有在rehash,=0,在rehash
return DICT_OK;
}
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size){
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX +1LU;
while(1) {
if (i >= sie)
return i;
i *= 2;
}
}
Dict的收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor<0.1时,会做哈希表收缩:

Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
1、计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used+ 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n(不得小于4)
2、按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
3、设置dict.rehashidx = 0,标示开始rehash
4、将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
5、将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
如图:
计算扩容后数据大小中
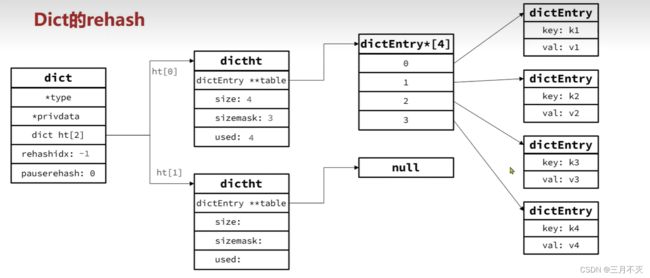
将申请的内存空间赋值给ht[1],rehashidx置为0,表示正在扩容中,接着将ht[0]中的dictEntry都rehash到ht[1]中

最后再将ht[1]给ht[0]
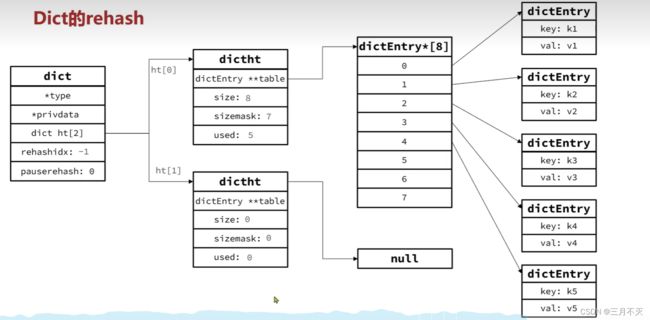

总结:
Dict的结构:
类似java的HashTable,底层是数组加链表来解决哈希冲突
Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
当LoadFactor小于0.1时,Dict收缩
扩容大小为第一个大于等于used + 1的2^n
收缩大小为第一个大于等于used的2^n
Dict采用渐进式rehash,每次访问Dict时执行一次rehash
rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
ZIpList
ZipList是一种特殊的“双端链表”,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1)。

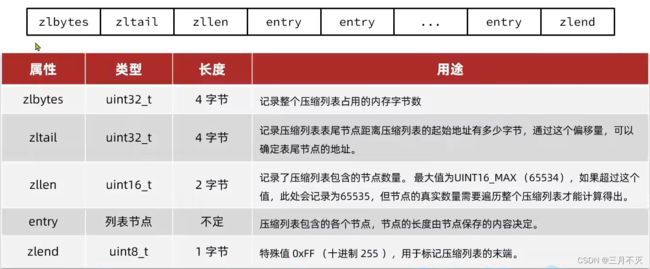
ZipListEntry

Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或“10”开头,则证明content是字符串
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ORSQgcOa-1657941415501)(network-img/image-20220716074411768.png)]](http://img.e-com-net.com/image/info8/1e8bd98d4d2949ec9da3a6cd1d7f3c89.jpg)
上图中00pppppp:00编码(,表示字符串类型,之后位数表示字符串长度,这能表示的字符串长度63
例如,保存字符串:“ab”和“bc”
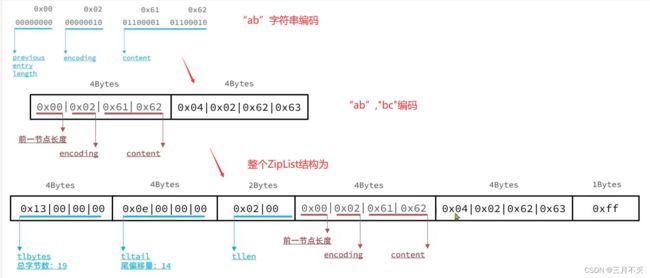
上述中:长度用小端存储,所有前面tlbytes、tllen都是倒着表示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T4IGQ4QJ-1657941415502)(network-img/image-20220716075429010.png)]](http://img.e-com-net.com/image/info8/63cc917f7b6e427ab913c7c80f957c2e.jpg)
ZipListEntry中的encoding编码分为字符串和整数两种:
整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节
(00、01、10开头表示的是字符串,11表示是整数,因为数字范围没字符串那么多。所以用一些特定的来存储长度)
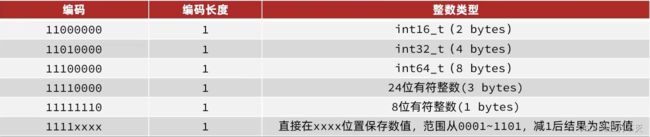
1111xxxx:XXXX可直接保存数字1-12,直接在后四位存
例如,一个ZipList中包含两个整数值:“2”和“5”
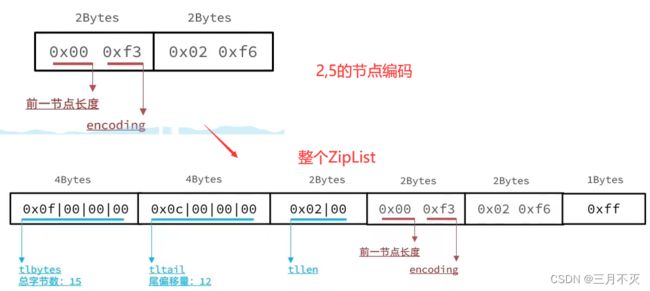
zipList可以尽量节省内存,但由于是数组,查找数据依然要挨个遍历
ZipList的连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为Oxfe,后四个字节才是真实长度数据
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,
此时在链表头部添加了一个长度为254的节点,那么之后所有节点的的上一节previous_entry_length都要换成5字节存储
如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8w69fObv-1657941415503)(network-img/image-20220716081010389.png)]](http://img.e-com-net.com/image/info8/98bd90626d6e44cfa586617336e921be.jpg)
ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
总结:
zipList特性:
压缩列表的可以看做一种连续内存空间的"双向链表"
列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
如果列表数据过多,导致链表过长,可能影响查询性能
增或删较大数据时有可能发生连续更新问题
QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
- 为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
- 我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
- Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
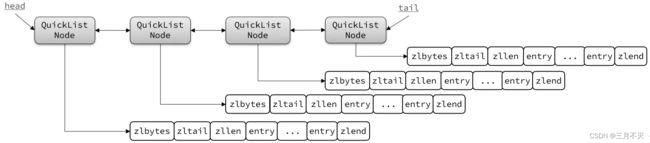
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项: list-max-ziplist-size来限制。
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
- -1:每个zipList的内存占用不能超过4kb
- -2:每个ZipList的内存占用不能超过8kb
- -3:每个zipList的内存占用不能超过16kb
- -4:每个zipList的内存占用不能超过32kb
- -5:每个zipList的内存占用不能超过64kb
- 其默认值为-2

以下是QuickList的和QuickListNode的结构源码:

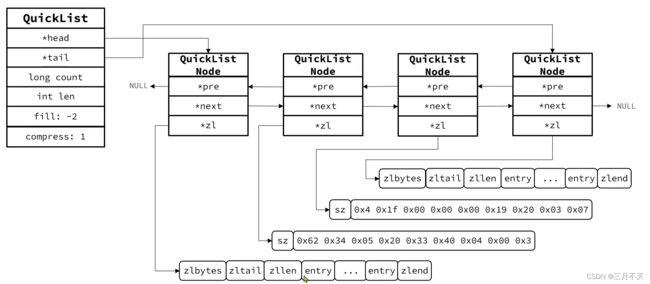
总结
QuickList的特点:
是一个节点为ZipList的双端链表
节点采用zipList,解决了传统链表的内存占用问题
控制了ZipList大小,解决连续内存空间申请效率问题。
中间节点可以压缩,进一步节省了内存
SkipList
QuickList查找节点时只能从头或尾查找,假如查找元素在中间内部,效率低,所以衍生出跳表
skipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
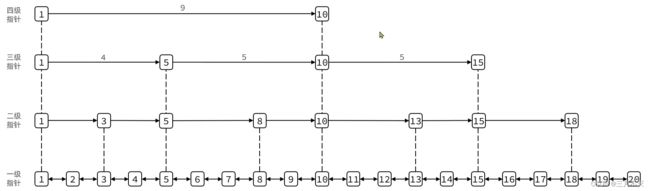


总结:
SkipList的特点:
跳跃表是一个双向链表,每个节点都包含score和ele值
节点按照score值排序,score值一样则按照ele字典排序
每个节点都可以包含多层指针,层数是1到32之间的随机数
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
增删改查效率与红黑树基本一致,实现却更简单
RedisObject
Redis中的任意数据类型的键和值都会被封装为一个Redisobject,也叫做Redis对象,源码如下:
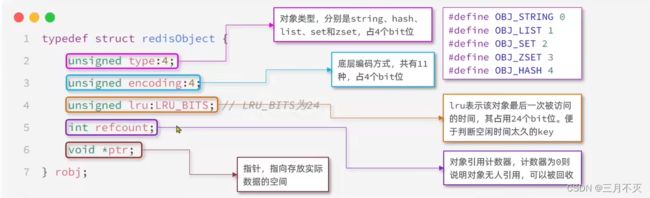
上图中可看出一个对象头就占16个字节(ptr指针一般8字节)
Redis的编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式。
编码方式11种:
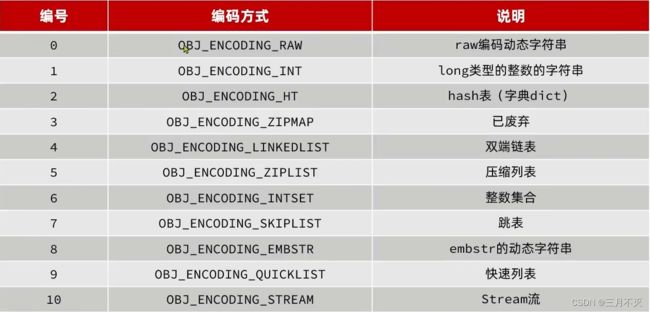
5中数据结构,每种数据类型的编码方式如下:
String
String是Redis中最常见的数据存储类型:
-
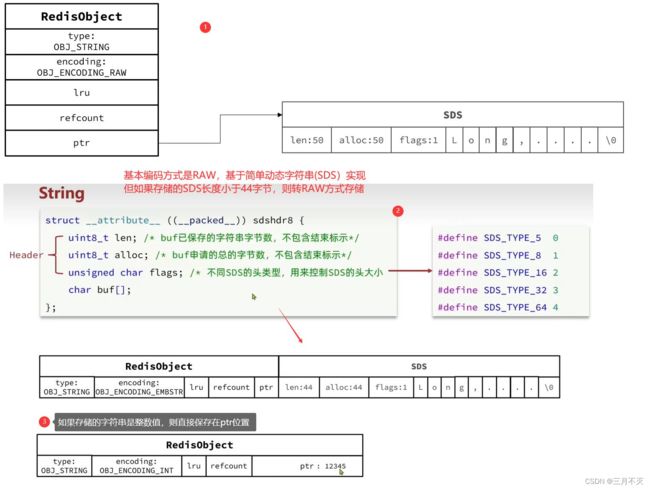
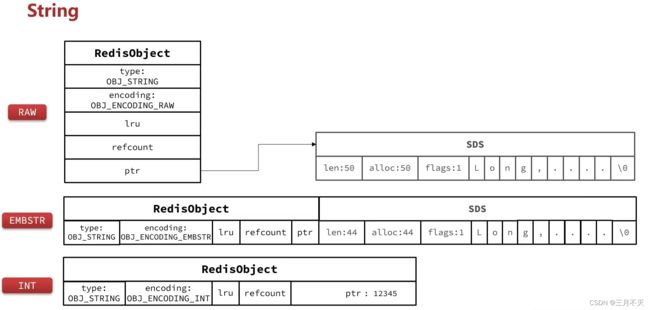
其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
-
如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
-
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
List
Redis的List类型可以从首、尾操作列表中的元素:
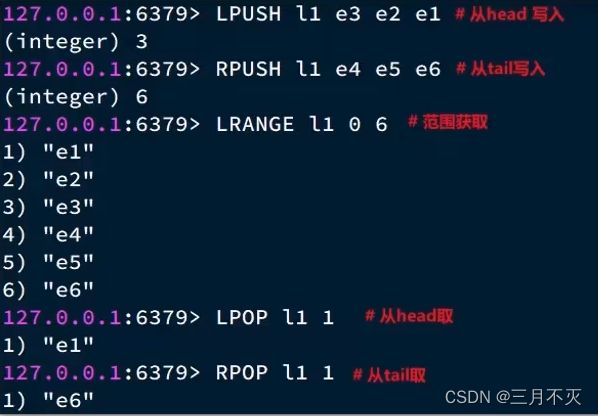
哪一个数据结构能满足上述特征?
- LinkedList:普通链表,可以从双端访问,内存占用较高,内存碎片较多
- zipList:压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList: LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
在3.2版本之前,Redis采用zipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
◆在3.2版本之后,Redis统一采用QuickList来实现List:
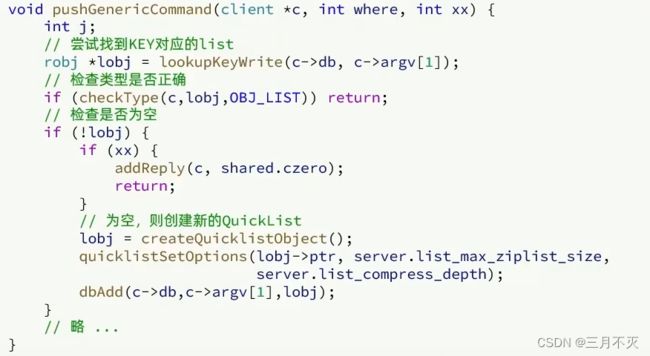
//位于t_list.c
/* Implements LPUSH/RPUSH/LPUSHX/RPUSHX.
* 'xx': push if key exists. */
//如果key存在,就push,不存在直接退出
/**
*参数1:客户端,只要客户端和服务端建立连接,都会被封装成一个client,里面包含客户端的各种信息,包括客户端要执行的命令
*参数2:首或尾(push具备两个功能,左、右插入(通过参数where指定))
*参数3:要添加的元素的值
*/
void pushGenericCommand(client *c, int where, int xx) {
int j;
//遍历每个节点链表元素大小,不能超过LIST_MAX_ITEM_SIZE key v1 v2
for (j = 2; j < c->argc; j++) {
if (sdslen(c->argv[j]->ptr) > LIST_MAX_ITEM_SIZE) {
addReplyError(c, "Element too large");
return;
}
}
//尝试找到KEY对应的list
robj *lobj = lookupKeyWrite(c->db, c->argv[1]);
//检查类型是否正确(检查是否是list类型)
if (checkType(c,lobj,OBJ_LIST)) return;
//检查是否为空
if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
//为空,则创建新的QuickList
lobj = createQuicklistObject();
//限制每个quickList压缩链表大小
/**
server.list_max_ziplist_size:限制每个压缩列表大小,默认-2,不超过8KB
server.list_compress_depth:压缩深度,默认是0.不压缩,是1,则表示quickLiset首位各一个元素不压缩,其余压缩
*/
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
for (j = 2; j < c->argc; j++) {
listTypePush(lobj,c->argv[j],where);
server.dirty++;
}
//添加元素
addReplyLongLong(c, listTypeLength(lobj));
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
//位于object.c
robj *createQuicklistObject(void) {
//申请内存并初始化QuickList
quicklist *l = quicklistCreate();
//创建RdisObject,type为OBJ_LIST,ptr指向 QuickList
robj *o = createObject(OBJ_LIST,l);
//设置编码为QuickList
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用zipList编码。超过则采用LinkedList编码.

Set
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
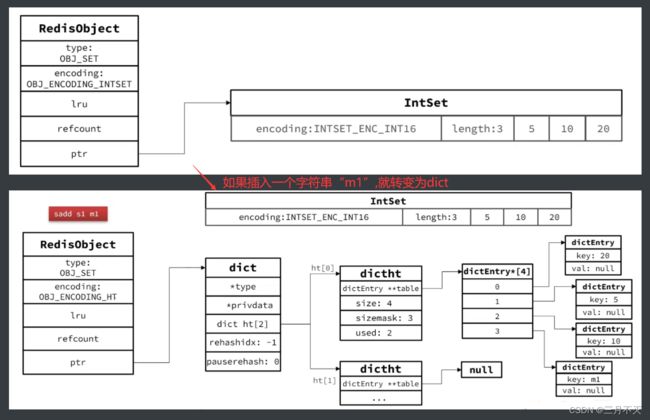
为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存。

在每次插入新元素时。都会检查这两个条件:当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries,如果不满足,则set采用HT编码(Dict),如下源代码:

如下所示:
ZSet
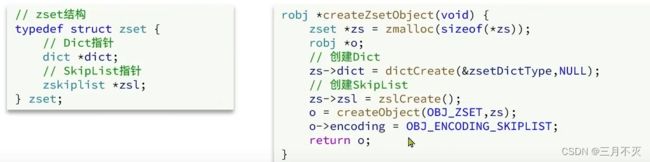
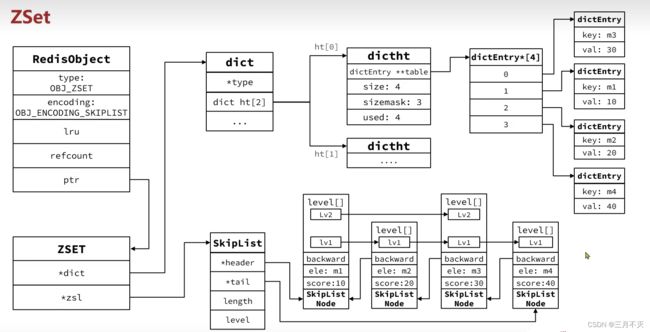
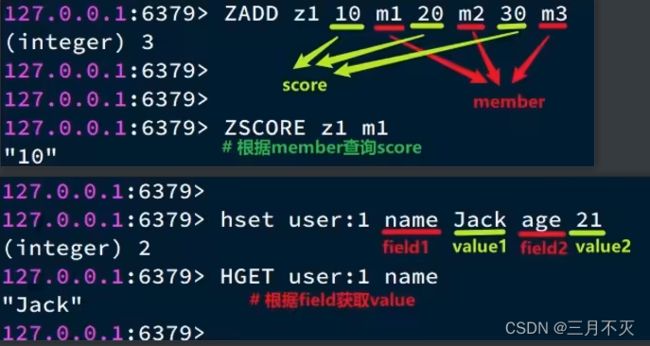
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:

- 可以根据score值排序
- member必须唯一
- 可以根据member查询分数
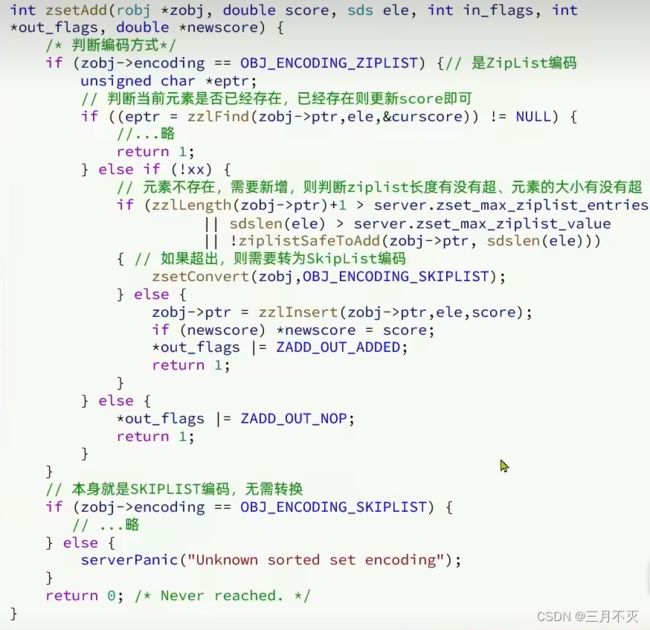
因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList: 可以排序,并且可以同时存储score和ele值( member)
- HT ( Dict) :可以键值存储,并且可以根据key找value
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此ZSet还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
1)元素数量小于zset_max_ziplist_entries,默认值128
2)每个元素都小于zset_max_ziplist_value字节,默认值64
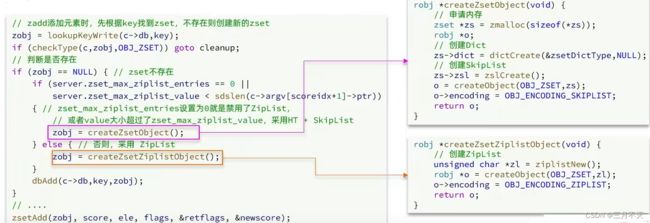
再添加元素过程中会检查是否需要将ZipList转换为Dict
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- zipList是连续内存,因此score和element是紧挨在一起的两个entry,element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7kWpXdAe-1657941415516)(network-img/image-20220716105816686.png)]](http://img.e-com-net.com/image/info8/713217155df54089b9276b5f500c9f73.jpg)
Hash
Hash结构与Redis中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset的键是member,值是score; hash的键和值都是任意值
- zset要根据score排序; hash则无需排序
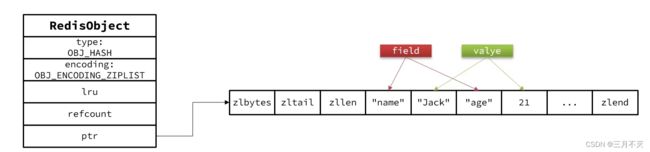
因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可;
Hash结构默认采用ZipList编码,用以节省内存。ZipList中相邻的两个entry分别保存field和value当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries (默认312)
- ZipList中的任意entry大小超过了hash-max-ziplist-value (默认64字节)
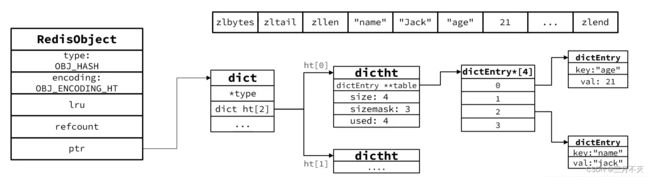
部分源码如下:

参考:https://www.bilibili.com/video/BV1cr4y1671t?p=146&vd_source=4b2762d41a0675aa9823e3c6194fb61d