数据库事务隔离级别
数据库事务,首先提到数据库事务的四大特性:ACID(酸)
与这个acid 相对,还有对于的BASE(碱)来实现最终一致性等实现方法,分布式使用比较多。
Atomic 原子性
Consistency 一致性
Isolation 隔离性
Durability 持久性
Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
事务隔离分为不同级别,包括:
读未提交(Read uncommitted)、
读提交(read committed)、
可重复读(repeatable read)、
串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
AID 是为了实现C
>>> 原子性和持久性是每个事务隔离级别都会完全满足的。其他会进行相应的取舍(trade-off)。
举个例子:
事务例子:
使用Mysql的事务实现一笔交易。
比如:
在事务中执行一个充值100元的交易,
先记录一条交易流水,流水号是1024,
然后,把账户余额从100元更新到200元。
对应的SQL语句如下:
mysql>begin; -- 开始事务
mysql>insert into accunt_log ...; -- 写入交易流程
mysql>update account_balance ...; -- 更新账户余额
mysql>commit; -- 提交事务
事务会做哪些保证呢?
事务可以保证,记录流水和更新账户余额这两个操作,要么都成功,要么都失败。
即使数据库宕机、应用程序退出等异常情况下,也不会出现一个表更新,一个表不更新情况。这个就是事务的原子性(Atomic)。
数据库总是一致性的状态(1024流水不存在,余额是100元)转换到另外一个致性状态(1024流水存在,余额是200元)。也就是对其他事务,不存在任何中间状态(eg,1024流水存在,但是余额100元)。任何时刻,其他事务读取到的流水中的状态如果没有1024这条流水记录,那么他读取的余额一定是100元,这是交易交易前的状态。如果他能读取到1024流水,那么它读取的余额一定是200元,这个是交易后的状态。事务总是能够保证我们读取到的数据(交易和流水)总是一致的,这是事务的一致性(Consistency)。
实时上,事务的执行过程无论有多快,它都需要一定时间,也就是说,数据库在修改流水表和余额表对应的数据是,顺序上必然会有先有后,那么一定存在一个时刻,流水更新了,但是余额没有更新,也就是说,每个事务的中间状态是事实存在的。数据库为了实现一致性,必须保证在每个事务的执行过程中,其中间状态对其他事务是不可见的。比如在事务A中,写入1024这条流水记录,但是还没有提交事务,此时其他任何事务都不应该读取到1024这条流水记录。这是事务的隔离性(Isolation)。
最后,只要事务提交成功,数据就一定会被持久化到磁盘中,后续及时发生数据库宕机的问题,也不会改变事务的结果。这是事务的持久性(Durability)。
事务的ACID四个基本特性,是紧密关联的。
ACID 是一个非常严格的定义,或者说是一种理想情况,如果完全满足ACID,那么数据库中的所有事务和SQL语句都只能串行执行,这样性能可能就不满足客户的需求了。
对账户系统和其他大多数交易系统,事务的原子性和持久性是必须要保证的,否则失去了使用事务的意义;而一致性和隔离性其实可以做出适当的牺牲一换取更高的性能。
为此,Mysql提供了4中事务个了级别,如下。
数据库有几种隔离级别:
1. read uncommitted (读未提交)
2. read commited(读已提交)
3. repeatable read (可重复读)
4. serializable (可串行化)
隔离级别,是针对不同事务并发执行时引入的问题提出的解决方案,防止数据并发读写执行交叉执行而导致的不一致问题的对应处理方式。
oracle 默认隔离级别 read commited(读已提交)
mysql 默认隔离级别 repeatable read (可重复读)
常见的问题
脏写:
一个事务覆盖写入了另一个事务尚未提交的写入。几乎所有的事务隔离等级实现都可以防止脏写。
当一个事务覆盖先前由另一个仍在进行中的事务写入的值时,就会发生脏写(Dirty Write)。
A Dirty Write occurs when one transaction overwrites a value that has previously been written by another still in-flight transaction.
脏写不好的其中一个原因,是它们可能违反数据库一致性。假设在 x 和 y 之间存在一个约束(例如,x = y),并且如果单独运行,T1 和 T2 各自保持约束的一致性。但是,如果两个事务以不同的顺序写入 x 和 y,则很容易违反约束,这只有在有脏写时才会发生。
One reason why Dirty Writes are bad is that they can violate database consistency. Assume there is a constraint between x and y (e.g., x = y), and T1 and T2 each maintain the consistency of the constraint if run alone. However, the constraint can easily be violated if the two transactions write x and y in different orders, which can only happen if there are Dirty writes.
假设 T1 写 x=y=1,T2 写 x=y=2,下列执行顺序会违反完整性约束。
Suppose T1 writes x=y=1 and T2 writes x=y=2, the following history violates the integrity constraint.
防止脏写的另一个必要原因是,如果没有对它们的保护,系统就无法在事务中止时自动回滚到之前的映像。
Another pressing reason to protect against dirty writes is that without protection from them the system can’t automatically rollback to a before image on transaction abort.
即使是最弱的锁定系统也持有长时间的写锁……
Even the weakest locking systems hold long-duration write locks…
假设 T1 写 x=1,T2 写 x=2,T1 回滚,导致T2事务数据丢失,下列执行顺序会违反完整性约束。
(格式良好的写入和长时间写入锁可防止脏写)。
(Well-formed writes and long duration write locks prevent dirty writes).
除了可序列化级别,ANSI SQL 隔离级别不排除脏写。但是,“应修改 ANSI SQL 以要求所有隔离级别的 P0(保护)。”
Other than at the serializable level, ANSI SQL isolation levels do not exclude dirty writes. However, “ANSI SQL should be modified to require P0 (protection) for all isolation levels.”
A Critique of ANSI SQL Isolation Levels | the morning paper
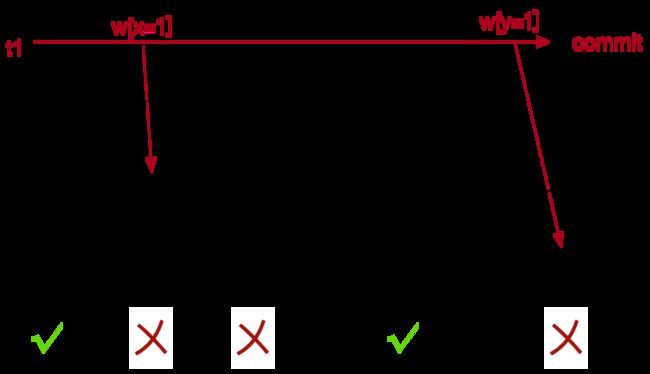
脏读:
一个事务读取到另一个事务尚未提交的写入。读已提交或更强的隔离级别可以防止脏读。
当一个事务读取已由另一个仍在进行中的事务写入的值时,就会发生脏读。仅阻止读取最终回滚的事务写入的值是不够的,您还需要阻止读取最终提交的事务的值。考虑在 x 和 y 之间转移余额,其中余额保持在 100 不变的完整性约束:
A Dirty Read occurs when one transaction reads a value that has been written by another still in-flight transaction. It is not enough to prevent only reads of values written by transactions that eventually rollback, you need to prevent reads of values from transactions that ultimately commit too. Consider a transfer of balance between x and y, with an integrity constraint that the balance remains unchanged at 100:
在基于锁定的实现中,格式良好的读写结合持有短期读锁和长期写锁将防止脏读。
In a locking-based implementation, well-formed reads and writes combined with holding short-duration read-locks and long-duration write-locks will prevent dirty reads.

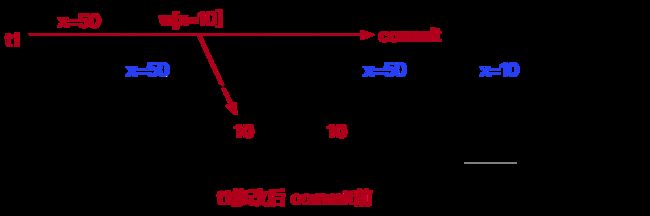
不可重复读:
不可重复读,是指在数据库访问中,一个事务范围内两个相同的查询却返回了不同数据。
一种更易理解的说法是:在一个事务内,多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该同一数据并修改数据。那么,在第一个事务的两次读数据之间。由于另一个事务的修改,那么第一个事务两次读到的数据可能不一样,这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读,即原始读取不可重复。
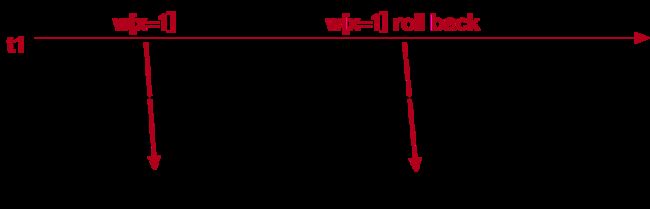
幻读:
事务B前后两次读取同一个范围的数据,在事务B两次读取的过程中事务A新增了数据,导致事务B后一次读取到前一次查询没有看到的行。
幻读和不可重复读有些类似,但是幻读强调的是集合的增减,而不是单条数据的更新。
| 事务隔离级别 | 脏写 | 脏读 | 不可重复读 | 幻读 | ACID特性满足 |
| read uncommitted (读未提交,RU) |
N | Y | Y | Y | AD I未满足 |
| read commited(读已提交,RC) | N | N | Y | Y | AD |
| repeatable read (可重复读,RR) | N | N | N | Y | AD |
| serializable (可串行化,SERIALIZABLE) | N | N | N | N | ACID |
Y 可能会发生问题
N 不会发生
不可重复读重点在于update和delete,而幻读的重点在于insert。
防止常见问题的方法:
防止脏写:
数据库一般用行锁。当事务想要修改特定的行时,必须先获得该行的锁。一次只有一个事务可持有任何给定行的锁。如果另一个事务要写入同一行,就必须等到第一个事务提交或回滚后。
eg:mysql为了防止脏写需要用排他锁(exclusive lock )
防止脏读:
每次写入前,数据库都会记住旧值。 当前事务尚未提交时,其他事务的读取都会拿到旧值。当前事务提交后,其他事务才能读取到新值。】
读已提交这个隔离级别下,事务只能读到已经提交的事务,也就避免了事务回滚带来的脏写、脏读问题。
解决不可重复读:
eg:MVCC
或者:使用锁机制
* 读锁(S锁):共享锁,针对同一份数据,多个读操作可以同时进行而不会互相影响。
* 写锁(X锁):排他锁,当前写操作没有完成前,它会阻断其他写锁和读锁。
我们分几种情况来讨论读写锁:
如果事务一进行读操作,那么给该记录加读锁,事务二进行读操作,可以并行,互补影响;
如果事务一进行读操作,那么给该记录加读锁,事务二进行写操作,如果是对同一条记录进行写操作,比如更新或删除,则无法并行,必须等事务一释放了读锁之后才可,可如果是insert操作,那么事务一的读锁并不会阻碍事务二的新增操作,所以两个事务仍然可以并行。所以在这种情况下可以回答我们上面为什么提及幻读会考虑插入数据而不考虑删除数据?的问题了。
如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。
但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。
不可重复读重点在于update和delete,而幻读的重点在于insert。
在RR的事务隔离级别下(有幻读问题):
快照读:普通的不加锁的select就是快照读。通过readview实现,可重复读级别时,整个事务的普通select都是使用同一个readview。其他事务产生的数据不会影响到这个快照。
简单的select操作(不包括select…lock in share mode,select…for update) 使用的是快照读。
当前读:读取最新版本已提交的数据。就算其他事务版本大于当前事务,但其他事务只要提交了的数据,当前事务使用当前读是可以读取到其他事务提交的数据的。而快照读则无法读取到其他新版事务提交的数据。
select ... lock in share mode
select ... for update
insert
update
delete以上这些操作都使用的是当前读。
现在我们来回答我们上面实验中出现的现象。在MVCC的实现下,是区分当前读和快照读的。
防止幻读:
怎么解决呢?
一、隔离级别设置为Serializable串行执行,但资源消耗最大。
二、间隙锁,(间隙锁和行锁的合集称为 next-key lock)
next-key lock影响并发怎么办?参考(幻读在 InnoDB 中是被如何解决的? - 来份锅包肉 - 博客园)
最主要的是,间隙锁会有增加死锁出现的概率。
所以在业务不需要 RR 支持下,如果想提高并发率,可以将隔离级别设置成 RC ,并将 binlog 格式设置成 row。(为什么要把MySQL的binlog格式修改为row_javaxuexilu的博客-CSDN博客_binlog为row)
在RC的模式下,MVCC解决不了幻读和不可重复读。
其他问题:
问题
我们来看一个问题:为什么提到幻读时,都是说其他事务插入数据引发幻读,而没有提及其他事务删除数据引发幻读?
我们来分析下这个问题,说起幻读,我们一般是在可重复读的隔离级别下谈论,因为其他的隔离级别比如读已提交、读未提交连可重复读都满足不了,更别说幻读了。
在可重复读的隔离级别下,是能够确保两次读都能读取到一样的数据的(在快照读和当前读不混用的前提下),所以其他事务删除数据是不影响的。也就是说并不会引起幻读。
https://blog.csdn.net/yongbutingxide/article/details/122203996
参考:
MVCC能否解决幻读?_程序员资料站的博客-CSDN博客_mvcc幻读
A Critique of ANSI SQL Isolation Levels | the morning paper
事务隔离级别:可重复读 - catmelo - 博客园
细说一下事务隔离机制是怎么解决脏写、脏读、不可重复读和幻读的 - 知乎
mysql中mvcc解决不可重复读_蚂蚁打dota的博客-CSDN博客_解决不可重复读
幻读在 InnoDB 中是被如何解决的? - 来份锅包肉 - 博客园