终结篇:MyBatis原理深入解析(二)
8 MyBatis数据源与连接池#
8.1 MyBatis数据源DataSource分类##
MyBatis数据源实现是在以下四个包中:
MyBatis数据源实现包
MyBatis把数据源DataSource分为三种:
UNPOOLED 不使用连接池的数据源
POOLED 使用连接池的数据源
JNDI 使用JNDI实现的数据源
即:

MyBatis三种数据源
相应地,MyBatis内部分别定义了实现了java.sql.DataSource接口的UnpooledDataSource,PooledDataSource类来表示UNPOOLED、POOLED类型的数据源。 如下图所示:
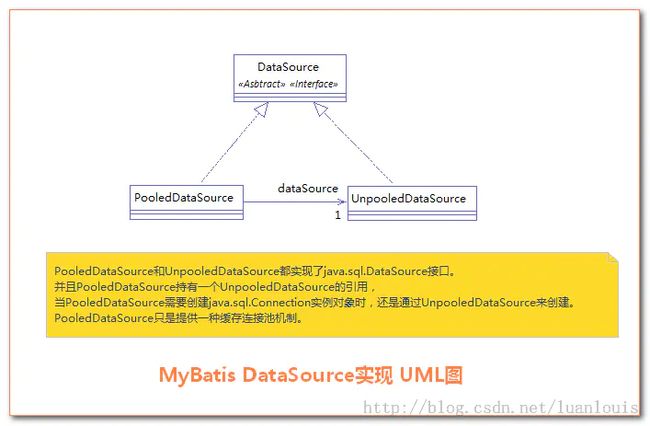
MyBatis DataSource实现UML图
对于JNDI类型的数据源DataSource,则是通过JNDI上下文中取值。
8.2 数据源DataSource的创建过程##
MyBatis数据源DataSource对象的创建发生在MyBatis初始化的过程中。下面让我们一步步地了解MyBatis是如何创建数据源DataSource的。
在mybatis的XML配置文件中,使用
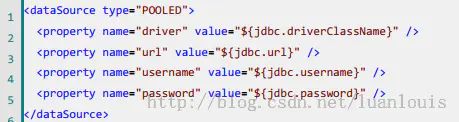
- MyBatis在初始化时,解析此文件,根据
的type属性来创建相应类型的的数据源DataSource,即:
type=”POOLED” :MyBatis会创建PooledDataSource实例
type=”UNPOOLED” :MyBatis会创建UnpooledDataSource实例
type=”JNDI” :MyBatis会从JNDI服务上查找DataSource实例,然后返回使用
- 顺便说一下,MyBatis是通过工厂模式来创建数据源DataSource对象的,MyBatis定义了抽象的工厂接口:org.apache.ibatis.datasource.DataSourceFactory,通过其getDataSource()方法返回数据源DataSource:
public interface DataSourceFactory {
void setProperties(Properties props);
// 生产DataSource
DataSource getDataSource();
}
上述三种不同类型的type,则有对应的以下dataSource工厂:
POOLED PooledDataSourceFactory
UNPOOLED UnpooledDataSourceFactory
JNDI JndiDataSourceFactory
其类图如下所示:
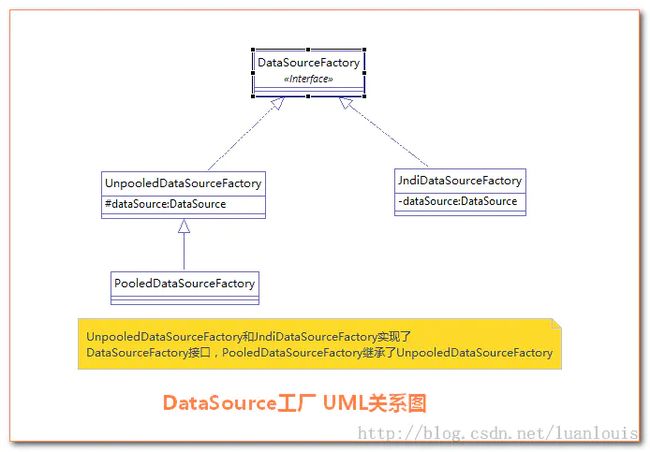
DataSource工厂UML类图
- MyBatis创建了DataSource实例后,会将其放到Configuration对象内的Environment对象中,供以后使用。
8.3 DataSource什么时候创建Connection对象##
当我们需要创建SqlSession对象并需要执行SQL语句时,这时候MyBatis才会去调用dataSource对象来创建java.sql.Connection对象。也就是说,java.sql.Connection对象的创建一直延迟到执行SQL语句的时候。
比如,我们有如下方法执行一个简单的SQL语句:
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
sqlSession.selectList("SELECT * FROM STUDENTS");
前4句都不会导致java.sql.Connection对象的创建,只有当第5句sqlSession.selectList("SELECT * FROM STUDENTS"),才会触发MyBatis在底层执行下面这个方法来创建java.sql.Connection对象:
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
connection = dataSource.getConnection();
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
setDesiredAutoCommit(autoCommmit);
}
8.4 不使用连接池的UnpooledDataSource##
当
使用UnpooledDataSource的getConnection(),每调用一次就会产生一个新的Connection实例对象。
UnPooledDataSource的getConnection()方法实现如下:
/*
* UnpooledDataSource的getConnection()实现
*/
public Connection getConnection() throws SQLException
{
return doGetConnection(username, password);
}
private Connection doGetConnection(String username, String password) throws SQLException
{
//封装username和password成properties
Properties props = new Properties();
if (driverProperties != null)
{
props.putAll(driverProperties);
}
if (username != null)
{
props.setProperty("user", username);
}
if (password != null)
{
props.setProperty("password", password);
}
return doGetConnection(props);
}
/*
* 获取数据连接
*/
private Connection doGetConnection(Properties properties) throws SQLException
{
//1.初始化驱动
initializeDriver();
//2.从DriverManager中获取连接,获取新的Connection对象
Connection connection = DriverManager.getConnection(url, properties);
//3.配置connection属性
configureConnection(connection);
return connection;
}
如上代码所示,UnpooledDataSource会做以下事情:
初始化驱动:判断driver驱动是否已经加载到内存中,如果还没有加载,则会动态地加载driver类,并实例化一个Driver对象,使用DriverManager.registerDriver()方法将其注册到内存中,以供后续使用。
创建Connection对象:使用DriverManager.getConnection()方法创建连接。
配置Connection对象:设置是否自动提交autoCommit和隔离级别isolationLevel。
返回Connection对象。
上述的序列图如下所示:

UnPooledDataSource序列图
总结:从上述的代码中可以看到,我们每调用一次getConnection()方法,都会通过DriverManager.getConnection()返回新的java.sql.Connection实例。
8.5 为什么要使用连接池?##
- 创建一个java.sql.Connection实例对象的代价
首先让我们来看一下创建一个java.sql.Connection对象的资源消耗。我们通过连接Oracle数据库,创建创建Connection对象,来看创建一个Connection对象、执行SQL语句各消耗多长时间。代码如下:
public static void main(String[] args) throws Exception
{
String sql = "select * from hr.employees where employee_id < ? and employee_id >= ?";
PreparedStatement st = null;
ResultSet rs = null;
long beforeTimeOffset = -1L; //创建Connection对象前时间
long afterTimeOffset = -1L; //创建Connection对象后时间
long executeTimeOffset = -1L; //执行Connection对象后时间
Connection con = null;
Class.forName("oracle.jdbc.driver.OracleDriver");
beforeTimeOffset = new Date().getTime();
System.out.println("before:\t" + beforeTimeOffset);
con = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:xe", "louluan", "123456");
afterTimeOffset = new Date().getTime();
System.out.println("after:\t\t" + afterTimeOffset);
System.out.println("Create Costs:\t\t" + (afterTimeOffset - beforeTimeOffset) + " ms");
st = con.prepareStatement(sql);
//设置参数
st.setInt(1, 101);
st.setInt(2, 0);
//查询,得出结果集
rs = st.executeQuery();
executeTimeOffset = new Date().getTime();
System.out.println("Exec Costs:\t\t" + (executeTimeOffset - afterTimeOffset) + " ms");
}

上述程序的执行结果
从此结果可以清楚地看出,创建一个Connection对象,用了250 毫秒;而执行SQL的时间用了170毫秒。
创建一个Connection对象用了250毫秒!这个时间对计算机来说可以说是一个非常奢侈的!
这仅仅是一个Connection对象就有这么大的代价,设想一下另外一种情况:如果我们在Web应用程序中,为用户的每一个请求就操作一次数据库,当有10000个在线用户并发操作的话,对计算机而言,仅仅创建Connection对象不包括做业务的时间就要损耗10000×250ms= 250 0000 ms = 2500 s = 41.6667 min,竟然要41分钟!!!如果对高用户群体使用这样的系统,简直就是开玩笑!
- 问题分析:
创建一个java.sql.Connection对象的代价是如此巨大,是因为创建一个Connection对象的过程,在底层就相当于和数据库建立的通信连接,在建立通信连接的过程,消耗了这么多的时间,而往往我们建立连接后(即创建Connection对象后),就执行一个简单的SQL语句,然后就要抛弃掉,这是一个非常大的资源浪费!
- 解决方案:
对于需要频繁地跟数据库交互的应用程序,可以在创建了Connection对象,并操作完数据库后,可以不释放掉资源,而是将它放到内存中,当下次需要操作数据库时,可以直接从内存中取出Connection对象,不需要再创建了,这样就极大地节省了创建Connection对象的资源消耗。由于内存也是有限和宝贵的,这又对我们对内存中的Connection对象怎么有效地维护提出了很高的要求。我们将在内存中存放Connection对象的容器称之为连接池(Connection Pool)。下面让我们来看一下MyBatis的连接池是怎样实现的。
8.6 使用了连接池的PooledDataSource##
同样地,我们也是使用PooledDataSource的getConnection()方法来返回Connection对象。现在让我们看一下它的基本原理:
PooledDataSource将java.sql.Connection对象包裹成PooledConnection对象放到了PoolState类型的容器中维护。 MyBatis将连接池中的PooledConnection分为两种状态:空闲状态(idle)和活动状态(active),这两种状态的PooledConnection对象分别被存储到PoolState容器内的idleConnections和activeConnections两个List集合中:
idleConnections:空闲(idle)状态PooledConnection对象被放置到此集合中,表示当前闲置的没有被使用的PooledConnection集合,调用PooledDataSource的getConnection()方法时,会优先从此集合中取PooledConnection对象。当用完一个java.sql.Connection对象时,MyBatis会将其包裹成PooledConnection对象放到此集合中。
activeConnections:活动(active)状态的PooledConnection对象被放置到名为activeConnections的ArrayList中,表示当前正在被使用的PooledConnection集合,调用PooledDataSource的getConnection()方法时,会优先从idleConnections集合中取PooledConnection对象,如果没有,则看此集合是否已满,如果未满,PooledDataSource会创建出一个PooledConnection,添加到此集合中,并返回。
PoolState连接池的大致结构如下所示:

PoolState连接池结构图
- 获取java.sql.Connection对象的过程
下面让我们看一下PooledDataSource 的getConnection()方法获取Connection对象的实现:
public Connection getConnection() throws SQLException {
return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
public Connection getConnection(String username, String password) throws SQLException {
return popConnection(username, password).getProxyConnection();
}
上述的popConnection()方法,会从连接池中返回一个可用的PooledConnection对象,然后再调用getProxyConnection()方法最终返回Conection对象。(至于为什么会有getProxyConnection(),请关注下一节)。
现在让我们看一下popConnection()方法到底做了什么:
先看是否有空闲(idle)状态下的PooledConnection对象,如果有,就直接返回一个可用的PooledConnection对象;否则进行第2步。
查看活动状态的PooledConnection池activeConnections是否已满;如果没有满,则创建一个新的PooledConnection对象,然后放到activeConnections池中,然后返回此PooledConnection对象;否则进行第三步;
看最先进入activeConnections池中的PooledConnection对象是否已经过期:如果已经过期,从activeConnections池中移除此对象,然后创建一个新的PooledConnection对象,添加到activeConnections中,然后将此对象返回;否则进行第4步。
线程等待,循环至第1步
/*
* 传递一个用户名和密码,从连接池中返回可用的PooledConnection
*/
private PooledConnection popConnection(String username, String password) throws SQLException
{
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null)
{
synchronized (state)
{
if (state.idleConnections.size() > 0)
{
// 连接池中有空闲连接,取出第一个
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled())
{
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
}
else
{
// 连接池中没有空闲连接,则取当前正在使用的连接数小于最大限定值,
if (state.activeConnections.size() < poolMaximumActiveConnections)
{
// 创建一个新的connection对象
conn = new PooledConnection(dataSource.getConnection(), this);
@SuppressWarnings("unused")
//used in logging, if enabled
Connection realConn = conn.getRealConnection();
if (log.isDebugEnabled())
{
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
}
else
{
// Cannot create new connection 当活动连接池已满,不能创建时,取出活动连接池的第一个,即最先进入连接池的PooledConnection对象
// 计算它的校验时间,如果校验时间大于连接池规定的最大校验时间,则认为它已经过期了,利用这个PoolConnection内部的realConnection重新生成一个PooledConnection
//
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime)
{
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit())
{
oldestActiveConnection.getRealConnection().rollback();
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
oldestActiveConnection.invalidate();
if (log.isDebugEnabled())
{
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
}
else
{
//如果不能释放,则必须等待有
// Must wait
try
{
if (!countedWait)
{
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled())
{
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
}
catch (InterruptedException e)
{
break;
}
}
}
}
//如果获取PooledConnection成功,则更新其信息
if (conn != null)
{
if (conn.isValid())
{
if (!conn.getRealConnection().getAutoCommit())
{
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
}
else
{
if (log.isDebugEnabled())
{
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + 3))
{
if (log.isDebugEnabled())
{
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null)
{
if (log.isDebugEnabled())
{
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
对应的处理流程图如下所示:
PooledDataSource popConnection()流程图
如上所示,对于PooledDataSource的getConnection()方法内,先是调用类PooledDataSource的popConnection()方法返回了一个PooledConnection对象,然后调用了PooledConnection的getProxyConnection()来返回Connection对象。
- java.sql.Connection对象的回收
当我们的程序中使用完Connection对象时,如果不使用数据库连接池,我们一般会调用 connection.close()方法,关闭connection连接,释放资源。如下所示:
private void test() throws ClassNotFoundException, SQLException
{
String sql = "select * from hr.employees where employee_id < ? and employee_id >= ?";
PreparedStatement st = null;
ResultSet rs = null;
Connection con = null;
Class.forName("oracle.jdbc.driver.OracleDriver");
try
{
con = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:xe", "louluan", "123456");
st = con.prepareStatement(sql);
//设置参数
st.setInt(1, 101);
st.setInt(2, 0);
//查询,得出结果集
rs = st.executeQuery();
//取数据,省略
//关闭,释放资源
con.close();
}
catch (SQLException e)
{
con.close();
e.printStackTrace();
}
}
调用过close()方法的Connection对象所持有的资源会被全部释放掉,Connection对象也就不能再使用。
那么,如果我们使用了连接池,我们在用完了Connection对象时,需要将它放在连接池中,该怎样做呢?
为了和一般的使用Conneciton对象的方式保持一致,我们希望当Connection使用完后,调用.close()方法,而实际上Connection资源并没有被释放,而实际上被添加到了连接池中。这样可以做到吗?答案是可以。上述的要求从另外一个角度来描述就是:能否提供一种机制,让我们知道Connection对象调用了什么方法,从而根据不同的方法自定义相应的处理机制。恰好代理机制就可以完成上述要求.
怎样实现Connection对象调用了close()方法,而实际是将其添加到连接池中:
这是要使用代理模式,为真正的Connection对象创建一个代理对象,代理对象所有的方法都是调用相应的真正Connection对象的方法实现。当代理对象执行close()方法时,要特殊处理,不调用真正Connection对象的close()方法,而是将Connection对象添加到连接池中。
MyBatis的PooledDataSource的PoolState内部维护的对象是PooledConnection类型的对象,而PooledConnection则是对真正的数据库连接java.sql.Connection实例对象的包裹器。
PooledConnection对象内持有一个真正的数据库连接java.sql.Connection实例对象和一个java.sql.Connection的代理,其部分定义如下:
class PooledConnection implements InvocationHandler {
//......
//所创建它的datasource引用
private PooledDataSource dataSource;
//真正的Connection对象
private Connection realConnection;
//代理自己的代理Connection
private Connection proxyConnection;
//......
}
PooledConenction实现了InvocationHandler接口,并且,proxyConnection对象也是根据这个它来生成的代理对象:
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
this.realConnection = connection;
this.dataSource = dataSource;
this.createdTimestamp = System.currentTimeMillis();
this.lastUsedTimestamp = System.currentTimeMillis();
this.valid = true;
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
实际上,我们调用PooledDataSource的getConnection()方法返回的就是这个proxyConnection对象。当我们调用此proxyConnection对象上的任何方法时,都会调用PooledConnection对象内invoke()方法。
让我们看一下PooledConnection类中的invoke()方法定义:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
//当调用关闭的时候,回收此Connection到PooledDataSource中
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
dataSource.pushConnection(this);
return null;
} else {
try {
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection();
}
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
从上述代码可以看到,当我们使用了pooledDataSource.getConnection()返回的Connection对象的close()方法时,不会调用真正Connection的close()方法,而是将此Connection对象放到连接池中。
8.7 JNDI类型的数据源DataSource##
对于JNDI类型的数据源DataSource的获取就比较简单,MyBatis定义了一个JndiDataSourceFactory工厂来创建通过JNDI形式生成的DataSource。下面让我们看一下JndiDataSourceFactory的关键代码:
if (properties.containsKey(INITIAL_CONTEXT) && properties.containsKey(DATA_SOURCE))
{
//从JNDI上下文中找到DataSource并返回
Context ctx = (Context) initCtx.lookup(properties.getProperty(INITIAL_CONTEXT));
dataSource = (DataSource) ctx.lookup(properties.getProperty(DATA_SOURCE));
}
else if (properties.containsKey(DATA_SOURCE))
{
//从JNDI上下文中找到DataSource并返回
dataSource = (DataSource) initCtx.lookup(properties.getProperty(DATA_SOURCE));
}
9 MyBatis事务管理机制#
9.1 概述##
对数据库的事务而言,应该具有以下几点:创建(create)、提交(commit)、回滚(rollback)、关闭(close)。对应地,MyBatis将事务抽象成了Transaction接口:
MyBatis将事务抽象成了Transaction接口
MyBatis的事务管理分为两种形式:
- 使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等。
- 使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
这两者的类图如下所示:
MyBatis的事务管理分为两种形式
9.2 事务的配置、创建和使用##
- 事务的配置
我们在使用MyBatis时,一般会在MyBatisXML配置文件中定义类似如下的信息:

MyBatis事务的配置
节点定义了连接某个数据库的信息,其子节点 的type会决定我们用什么类型的事务管理机制 。
- 事务工厂的创建
MyBatis事务的创建是交给TransactionFactory 事务工厂来创建的,如果我们将
/**
* 解析节点,创建对应的TransactionFactory
* @param context
* @return
* @throws Exception
*/
private TransactionFactory transactionManagerElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type");
Properties props = context.getChildrenAsProperties();
/*
* 在Configuration初始化的时候,会通过以下语句,给JDBC和MANAGED对应的工厂类
* typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
* typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
* 下述的resolveClass(type).newInstance()会创建对应的工厂实例
*/
TransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a TransactionFactory.");
}
如上述代码所示,如果type = "JDBC",则MyBatis会创建一个JdbcTransactionFactory.class 实例;如果type="MANAGED",则MyBatis会创建一个MangedTransactionFactory.class实例。
MyBatis对
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
//是和默认的环境相同时,解析之
if (isSpecifiedEnvironment(id)) {
//1.解析节点,决定创建什么类型的TransactionFactory
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//2. 创建dataSource
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
//3. 使用了Environment内置的构造器Builder,传递id 事务工厂TransactionFactory和数据源DataSource
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
Environment表示着一个数据库的连接,生成后的Environment对象会被设置到Configuration实例中,以供后续的使用。

Environment组成结构图
上述一直在讲事务工厂TransactionFactory来创建的Transaction,现在让我们看一下MyBatis中的TransactionFactory的定义吧。
- 事务工厂TransactionFactory
事务工厂Transaction定义了创建Transaction的两个方法:一个是通过指定的Connection对象创建Transaction,另外是通过数据源DataSource来创建Transaction。与JDBC 和MANAGED两种Transaction相对应,TransactionFactory有两个对应的实现的子类:

TransactionFactory两个对应的实现的子类
- 事务Transaction的创建
通过事务工厂TransactionFactory很容易获取到Transaction对象实例。我们以JdbcTransaction为例,看一下JdbcTransactionFactory是怎样生成JdbcTransaction的,代码如下:
public class JdbcTransactionFactory implements TransactionFactory {
public void setProperties(Properties props) {
}
/**
* 根据给定的数据库连接Connection创建Transaction
* @param conn Existing database connection
* @return
*/
public Transaction newTransaction(Connection conn) {
return new JdbcTransaction(conn);
}
/**
* 根据DataSource、隔离级别和是否自动提交创建Transacion
*
* @param ds
* @param level Desired isolation level
* @param autoCommit Desired autocommit
* @return
*/
public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
return new JdbcTransaction(ds, level, autoCommit);
}
}
如上说是,JdbcTransactionFactory会创建JDBC类型的Transaction,即JdbcTransaction。类似地,ManagedTransactionFactory也会创建ManagedTransaction。下面我们会分别深入JdbcTranaction 和ManagedTransaction,看它们到底是怎样实现事务管理的。
- JdbcTransaction
JdbcTransaction直接使用JDBC的提交和回滚事务管理机制。它依赖与从dataSource中取得的连接connection 来管理transaction 的作用域,connection对象的获取被延迟到调用getConnection()方法。如果autocommit设置为on,开启状态的话,它会忽略commit和rollback。
直观地讲,就是JdbcTransaction是使用的java.sql.Connection 上的commit和rollback功能,JdbcTransaction只是相当于对java.sql.Connection事务处理进行了一次包装(wrapper),Transaction的事务管理都是通过java.sql.Connection实现的。JdbcTransaction的代码实现如下:
public class JdbcTransaction implements Transaction {
private static final Log log = LogFactory.getLog(JdbcTransaction.class);
//数据库连接
protected Connection connection;
//数据源
protected DataSource dataSource;
//隔离级别
protected TransactionIsolationLevel level;
//是否为自动提交
protected boolean autoCommmit;
public JdbcTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {
dataSource = ds;
level = desiredLevel;
autoCommmit = desiredAutoCommit;
}
public JdbcTransaction(Connection connection) {
this.connection = connection;
}
public Connection getConnection() throws SQLException {
if (connection == null) {
openConnection();
}
return connection;
}
/**
* commit()功能 使用connection的commit()
* @throws SQLException
*/
public void commit() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + connection + "]");
}
connection.commit();
}
}
/**
* rollback()功能 使用connection的rollback()
* @throws SQLException
*/
public void rollback() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Rolling back JDBC Connection [" + connection + "]");
}
connection.rollback();
}
}
/**
* close()功能 使用connection的close()
* @throws SQLException
*/
public void close() throws SQLException {
if (connection != null) {
resetAutoCommit();
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + connection + "]");
}
connection.close();
}
}
protected void setDesiredAutoCommit(boolean desiredAutoCommit) {
try {
if (connection.getAutoCommit() != desiredAutoCommit) {
if (log.isDebugEnabled()) {
log.debug("Setting autocommit to " + desiredAutoCommit + " on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(desiredAutoCommit);
}
} catch (SQLException e) {
// Only a very poorly implemented driver would fail here,
// and there's not much we can do about that.
throw new TransactionException("Error configuring AutoCommit. "
+ "Your driver may not support getAutoCommit() or setAutoCommit(). "
+ "Requested setting: " + desiredAutoCommit + ". Cause: " + e, e);
}
}
protected void resetAutoCommit() {
try {
if (!connection.getAutoCommit()) {
// MyBatis does not call commit/rollback on a connection if just selects were performed.
// Some databases start transactions with select statements
// and they mandate a commit/rollback before closing the connection.
// A workaround is setting the autocommit to true before closing the connection.
// Sybase throws an exception here.
if (log.isDebugEnabled()) {
log.debug("Resetting autocommit to true on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(true);
}
} catch (SQLException e) {
log.debug("Error resetting autocommit to true "
+ "before closing the connection. Cause: " + e);
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
connection = dataSource.getConnection();
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
setDesiredAutoCommit(autoCommmit);
}
}
- ManagedTransaction
ManagedTransaction让容器来管理事务Transaction的整个生命周期,意思就是说,使用ManagedTransaction的commit和rollback功能不会对事务有任何的影响,它什么都不会做,它将事务管理的权利移交给了容器来实现。看如下Managed的实现代码大家就会一目了然:
/**
*
* 让容器管理事务transaction的整个生命周期
* connection的获取延迟到getConnection()方法的调用
* 忽略所有的commit和rollback操作
* 默认情况下,可以关闭一个连接connection,也可以配置它不可以关闭一个连接
* 让容器来管理transaction的整个生命周期
* @see ManagedTransactionFactory
*/
public class ManagedTransaction implements Transaction {
private static final Log log = LogFactory.getLog(ManagedTransaction.class);
private DataSource dataSource;
private TransactionIsolationLevel level;
private Connection connection;
private boolean closeConnection;
public ManagedTransaction(Connection connection, boolean closeConnection) {
this.connection = connection;
this.closeConnection = closeConnection;
}
public ManagedTransaction(DataSource ds, TransactionIsolationLevel level, boolean closeConnection) {
this.dataSource = ds;
this.level = level;
this.closeConnection = closeConnection;
}
public Connection getConnection() throws SQLException {
if (this.connection == null) {
openConnection();
}
return this.connection;
}
public void commit() throws SQLException {
// Does nothing
}
public void rollback() throws SQLException {
// Does nothing
}
public void close() throws SQLException {
if (this.closeConnection && this.connection != null) {
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + this.connection + "]");
}
this.connection.close();
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
this.connection = this.dataSource.getConnection();
if (this.level != null) {
this.connection.setTransactionIsolation(this.level.getLevel());
}
}
}
注意:如果我们使用MyBatis构建本地程序,即不是WEB程序,若将type设置成"MANAGED",那么,我们执行的任何update操作,即使我们最后执行了commit操作,数据也不会保留,不会对数据库造成任何影响。因为我们将MyBatis配置成了“MANAGED”,即MyBatis自己不管理事务,而我们又是运行的本地程序,没有事务管理功能,所以对数据库的update操作都是无效的。
10 MyBatis关联查询#
MyBatis 提供了高级的关联查询功能,可以很方便地将数据库获取的结果集映射到定义的Java Bean中。下面通过一个实例,来展示一下Mybatis对于常见的一对多和多对一关系复杂映射是怎样处理的。
设计一个简单的博客系统,一个用户可以开多个博客,在博客中可以发表文章,允许发表评论,可以为文章加标签。博客系统主要有以下几张表构成:
Author表:作者信息表,记录作者的信息,用户名和密码,邮箱等。
Blog表:博客表,一个作者可以开多个博客,即Author和Blog的关系是一对多。
Post表:文章记录表,记录文章发表时间,标题,正文等信息;一个博客下可以有很多篇文章,Blog 和Post的关系是一对多。
Comments表:文章评论表,记录文章的评论,一篇文章可以有很多个评论:Post和Comments的对应关系是一对多。
Tag表:标签表,表示文章的标签分类,一篇文章可以有多个标签,而一个标签可以应用到不同的文章上,所以Tag和Post的关系是多对多的关系;(Tag和Post的多对多关系通过Post_Tag表体现)
Post_Tag表:记录 文章和标签的对应关系。
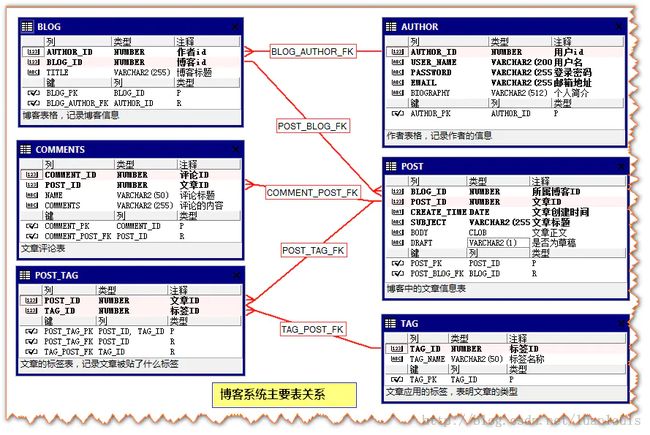
博客系统主要表关系
一般情况下,我们会根据每一张表的结构创建与此相对应的JavaBean(或者Pojo),来完成对表的基本CRUD操作。

表结构和Java Bean对应关系
上述对单个表的JavaBean定义有时候不能满足业务上的需求。在业务上,一个Blog对象应该有其作者的信息和一个文章列表,如下图所示:
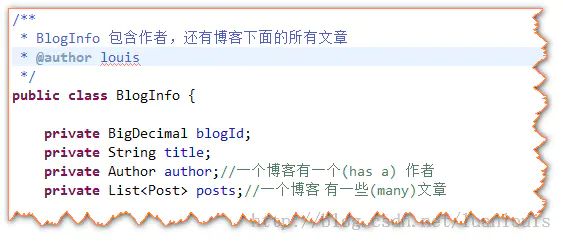
一个Blog对象应该有其作者的信息和一个文章列表
如果想得到这样的类的实例,则最起码要有一下几步:
通过Blog 的id 到Blog表里查询Blog信息,将查询到的blogId 和title 赋到Blog对象内;
根据查询到到blog信息中的authorId 去 Author表获取对应的author信息,获取Author对象,然后赋到Blog对象内;
根据 blogId 去 Post表里查询 对应的 Post文章列表,将List
对象赋到Blog对象中;
这样的话,在底层最起码调用三次查询语句,请看下列的代码:
/*
* 通过blogId获取BlogInfo对象
*/
public static BlogInfo ordinaryQueryOnTest(String blogId)
{
BigDecimal id = new BigDecimal(blogId);
SqlSession session = sqlSessionFactory.openSession();
BlogInfo blogInfo = new BlogInfo();
//1.根据blogid 查询Blog对象,将值设置到blogInfo中
Blog blog = (Blog)session.selectOne("com.foo.bean.BlogMapper.selectByPrimaryKey",id);
blogInfo.setBlogId(blog.getBlogId());
blogInfo.setTitle(blog.getTitle());
//2.根据Blog中的authorId,进入数据库查询Author信息,将结果设置到blogInfo对象中
Author author = (Author)session.selectOne("com.foo.bean.AuthorMapper.selectByPrimaryKey",blog.getAuthorId());
blogInfo.setAuthor(author);
//3.查询posts对象,设置进blogInfo中
List posts = session.selectList("com.foo.bean.PostMapper.selectByBlogId",blog.getBlogId());
blogInfo.setPosts(posts);
//以JSON字符串的形式将对象打印出来
JSONObject object = new JSONObject(blogInfo);
System.out.println(object.toString());
return blogInfo;
}
从上面的代码可以看出,想获取一个BlogInfo对象比较麻烦,总共要调用三次数据库查询,得到需要的信息,然后再组装BlogInfo对象。
10.1 嵌套语句查询##
mybatis提供了一种机制,叫做嵌套语句查询,可以大大简化上述的操作,加入配置及代码如下:
/*
* 通过blogId获取BlogInfo对象
*/
public static BlogInfo nestedQueryOnTest(String blogId)
{
BigDecimal id = new BigDecimal(blogId);
SqlSession session = sqlSessionFactory.openSession();
BlogInfo blogInfo = new BlogInfo();
blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryBlogInfoById",id);
JSONObject object = new JSONObject(blogInfo);
System.out.println(object.toString());
return blogInfo;
}
通过上述的代码完全可以实现前面的那个查询。这里我们在代码里只需要 blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryBlogInfoById",id);一句即可获取到复杂的blogInfo对象。
嵌套语句查询的原理:
在上面的代码中,Mybatis会执行以下流程:
先执行 queryBlogInfoById 对应的语句从Blog表里获取到ResultSet结果集;
取出ResultSet下一条有效记录,然后根据resultMap定义的映射规格,通过这条记录的数据来构建对应的一个BlogInfo 对象。
当要对BlogInfo中的author属性进行赋值的时候,发现有一个关联的查询,此时Mybatis会先执行这个select查询语句,得到返回的结果,将结果设置到BlogInfo的author属性上;
对BlogInfo的posts进行赋值时,也有上述类似的过程。
重复2步骤,直至ResultSet. next () == false;
以下是blogInfo对象构造赋值过程示意图:

blogInfo对象构造赋值过程示意图
这种关联的嵌套查询,有一个非常好的作用就是:可以重用select语句,通过简单的select语句之间的组合来构造复杂的对象。上面嵌套的两个select语句com.foo.bean.AuthorMapper.selectByPrimaryKey和com.foo.bean.PostMapper.selectByBlogId完全可以独立使用。
N+1问题:
它的弊端也比较明显:即所谓的N+1问题。关联的嵌套查询显示得到一个结果集,然后根据这个结果集的每一条记录进行关联查询。
现在假设嵌套查询就一个(即resultMap 内部就一个association标签),现查询的结果集返回条数为N,那么关联查询语句将会被执行N次,加上自身返回结果集查询1次,共需要访问数据库N+1次。如果N比较大的话,这样的数据库访问消耗是非常大的!所以使用这种嵌套语句查询的使用者一定要考虑慎重考虑,确保N值不会很大。
以上面的例子为例,select 语句本身会返回com.foo.bean.BlogMapper.queryBlogInfoById 条数为1 的结果集,由于它有两条关联的语句查询,它需要共访问数据库 1*(1+1)=3次数据库。
10.2 嵌套结果查询##
嵌套语句的查询会导致数据库访问次数不定,进而有可能影响到性能。Mybatis还支持一种嵌套结果的查询:即对于一对多,多对多,多对一的情况的查询,Mybatis通过联合查询,将结果从数据库内一次性查出来,然后根据其一对多,多对一,多对多的关系和ResultMap中的配置,进行结果的转换,构建需要的对象。
重新定义BlogInfo的结果映射 resultMap:
对应的sql语句如下:
/*
* 获取所有Blog的所有信息
*/
public static BlogInfo nestedResultOnTest()
{
SqlSession session = sqlSessionFactory.openSession();
BlogInfo blogInfo = new BlogInfo();
blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryAllBlogInfo");
JSONObject object = new JSONObject(blogInfo);
System.out.println(object.toString());
return blogInfo;
}
嵌套结果查询的执行步骤:
根据表的对应关系,进行join操作,获取到结果集;
根据结果集的信息和BlogInfo 的resultMap定义信息,对返回的结果集在内存中进行组装、赋值,构造BlogInfo;
返回构造出来的结果List
结果。
对于关联的结果查询,如果是多对一的关系,则通过形如
如果是一对多的关系,就如Blog和Post之间的关系,通过形如
对于关联结果的查询,只需要查询数据库一次,然后对结果的整合和组装全部放在了内存中。