Spark RDD深度解析
1 RDD是什么
RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数据的分区。同时, RDD 还提供了一组丰富的操作来操作这些数据。 在这些操作中, 诸如 map,flatMap,filter 等转换操作实现了 Monad 模式, 很好地契合了 Scala 的集合操作. 除此之外, RDD 还提供了诸如 join, groupBy, reduceByKey 等更为方便的操作, 以支持常见的数据运算。
通常来讲, 针对数据处理有几种常见模型, 包括: Iterative Algorithms, Relational Queries, MapReduce, Stream Processing。例如 Hadoop MapReduce 采用了 MapReduce 模型, Storm 则采用了 Stream Processing 模型. RDD 混合了这四种模型, 使得 Spark 可以应用于各种大数据处理场景。
2 RDD为什么会出现
在 RDD 出现之前, 当时 MapReduce 是比较主流的, 而 MapReduce 如何执行迭代计算的任务呢?

多个 MapReduce 任务之间没有基于内存的数据共享方式, 只能通过磁盘来进行共享,这种方式明显比较低效。RDD 如何解决迭代计算非常低效的问题呢?

在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度, RDD 在执行迭代型任务时候的表现可以通过下面代码体现:
// 线性回归
val points = sc.textFile(...)
.map(...)
.persist(...)
val w = randomValue
for (i <- 1 to 10000) {
val gradient = points.map(p => p.x * (1 / (1 + exp(-p.y * (w dot p.x))) - 1) * p.y)
.reduce(_ + _)
w -= gradient
}
在这个例子中, 进行了大致 10000 次迭代, 如果在 MapReduce 中实现, 可能需要运行很多 Job, 每个 Job 之间都要通过 HDFS 共享结果, 熟快熟慢一窥便知
3 RDD特点
3.1 RDD 是一个数据模型
- RDD 允许用户显式的指定数据存放在内存或者磁盘
- RDD 是分布式的, 用户可以控制 RDD 的分区
3.2 RDD 是一个编程模型
- RDD 提供了丰富的操作
- RDD 提供了 map, flatMap, filter 等操作符, 用以实现 Monad 模式
- RDD 提供了 reduceByKey, groupByKey 等操作符, 用以操作 Key-Value 型数据
- RDD 提供了 max, min, mean 等操作符, 用以操作数字型的数据
3.3 RDD 可以分区
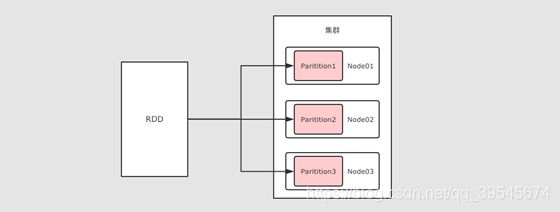
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
3.4 RDD 是只读的
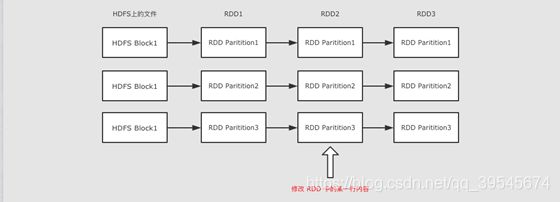
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改。
- RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
- 如果因为支持修改, 而必须保存数据的话, 怎么容错?
- 如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
3.5 RDD 是可以容错的

-
RDD 的容错有两种方式
-
保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
-
直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
-
4 创建RDD
简略的说, RDD 有三种创建方式
-
RDD 可以通过本地集合直接创建
def rddCreationLocal():Unit={ //创建配置信息,设置主机名 local[2]表示本地虚拟两个线程的方式 设置应用名称 // 1. 创建SparkConf val conf = new SparkConf().setMaster("local[2]").setAppName("demo01") // 2. 使用SparkConf创建conf val sc = new SparkContext(conf) // SparkConf作为大入口API,能创建RDD,并且设置参数,设置Jar包等 val list = List(1, 2, 3, 4, 5, 6) //第一种方式 parallelize 可以不指定分区数 // 第一个参数是本地集合 第二个参数是分区数量 val rdd1:RDD[Int] = sc.parallelize(list, 2) //第二种方式 makeRDD val rdd2:RDD[Int] = sc.makeRDD(list, 2) } -
RDD 也可以通过读取外部数据集来创建
def rddCreationFiles():Unit={ val conf = new SparkConf().setMaster("local[2]").setAppName("demo01") val sc = new SparkContext(conf) /** * 1.textFile传入的是什么? * 传入的是一个路径,读取路径 * hdfs:// file:// /.../...(这种方式为在集群中执行还是在本地执行,在集群中,读取的是hdfs,本地是文件) * 2 是否支持分区? * *假如传入的是path是 hdfs:///... 分区由hdfs文件的block决定的 * 3. 支持什么平台 * 支持aws和阿里云 */ val rdd1:RDD[String]= sc.textFile("file:///....") } -
RDD 也可以通过其它的 RDD 衍生而来
def rddCreateFromRDD():Unit={ val conf = new SparkConf().setMaster("local[2]").setAppName("demo01") val sc = new SparkContext(conf) val rdd1 = sc.parallelize(Seq(1,2,3)) /** * 通过在rdd上执行算子操作,会生成新的rdd * 原地计算 * str.substr 返回新的字符串,非原地计算 * 和字符串的方式很像,字符串是不可变的,rdd也是不可变的 **/ val rdd2 = rdd1.map(item=>item) }