FLIP-147:支持包含结束任务的 Checkpoint 操作与作业结束流程修正
作者|高赟(云骞)
点击进入 Flink 中文学习网 https://flink-learning.org.cn/
https://flink-learning.org.cn/
第一部分
简介
Flink 可以同时支持有限数据集和无限数据集的分布式处理。在最近几个版本中,Flink 逐步实现了流批一体的 DataStream API 与 Table / SQL API。大部分用户都同时有流处理与批处理的需求,流批一体的开发接口可以帮助这些用户减小开发、运维与保证两类作业处理结果一致性等方面的复杂度, 例如阿里巴巴双十一的场景 [1]。
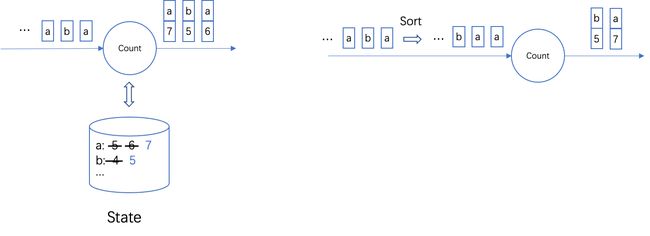
图1. 流执行模式与批执行模式的对比。以Count算子为例,在流模式下,到达的数据是无序的,算子将会读写与该元素对应的状态并进行增量计算。而在批模式下,算子将首先对数据排序,相同Key的数据将被统一处理。
在流批一体的接口之下,Flink 提供了两种不同的执行模式,即流执行模式与批执行模式。流执行模式下 Flink 基于中间状态增量的处理到达的数据,它可以同时支持有限数据与无限数据的处理。批执行模式则是基于按拓扑序依次执行作业中的所有任务,并通过预先对数据进行排序来避免对状态的随机访问,因此它只能用于有限数据的处理,但是一般情况下可以取得更好的性能。虽然许多场景下用户直接采用批处理模式来处理有限数据集,但是也存在许多场景用户仍然依赖流处理模式来处理有限数据集。例如,用户可能想要使用 SQL 的 Retraction 功能或者用户可能依赖于流模式下数据近似按时间有序的性质(例如 Kappa+ 架构 [2])。此外,许多用户需要执行同时包括无限数据流与有限维表的作业,这类作业也必须采用流执行模式。
在流执行模式下,Checkpointing [3] 是保证 Exactly-once 语义的核心机制。通过定期的保存作业的状态,当发生错误时 Flink 可以从最新的保存点恢复并继续执行。但是,在之前的版本中,Flink 不支持当部分任务执行结束之后进行 Checkpoint 操作。对于同时包括无限和有限数据输入的作业,这个问题将导致当有限数据输入处理完成后作业无法继续进行 Checkpoint 操作,从而导致当发生错误时需要从很久之前重新计算。
此外,无法对于部分任务结束后的作业进行 Checkpoint 操作也会影响使用两阶段提交 Sink 来保证端到端一致性 [4] 的作业。为了保证端到端一致性,两阶段提交的 Sink 通常首先将数据写入临时文件或者启用外部系统的事务,然后在 Checkpoint 成功完成后提交 Checkpoint 之前写入的数据,从而避免在发生错误后重放这部分数据导致数据重复。但是,如果作业中包含有限数据源,在这部分源节点任务结束后作业将无法继续提交数据。特别是对于所有数据源均为有限数据源的情况,作业总是无法提交最后一次 Checkpoint 到作业执行结束中间的这部分数据。在之前的实现中,Flink 在作业结束时直接忽略这部分数据,这对于用户带来了极大的困扰,在邮件列表中也有不少用户在询问这个问题。
因此,为了完善流执行模式对有限数据流的支持,Flink 需要:
- 支持任务结束后继续进行 Checkpoint 操作。
- 修正作业结束的流程,保证所有数据都可以被正常提交。
下文我们将首先简要描述针对这两个目标所进行的改动。在第二部分,我们也将分享更详细的实现。
支持包含结束任务的 Checkpoint
总体来说,支持包含结束任务的 Checkpoint 操作的核心思路是给已经执行完成的算子打标,从而在重启后可以跳过这部分算子的执行。如图 2 所示,在 Flink 中,Checkpoint 是由所有算子的状态来组成的。如果一个算子的所有并发都已经执行完成,那们我们就可以将该算子标记为『执行完成』,并在重启后跳过。对于其它算子,算子的状态是由所有当前还在运行的并发的状态组成,当重启后,算子状态将在所有并发中重新划分。
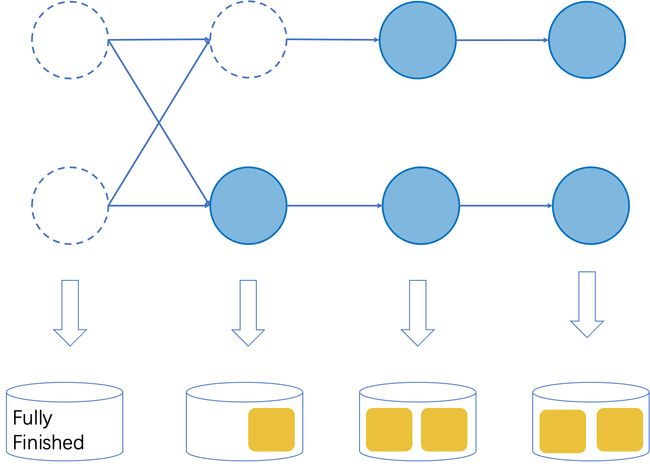
图2. 扩展的Checkpoint格式
为了能够在有任务执行完成的情况下完成上述 Checkpoint 操作,我们修改了 Checkpoint 操作的流程。之前在进行 Checkpoint 时,JobManager 中的 Checkpoint 控制器将首先通知所有的源节点保存当前状态,然后源节点将通过 Barrier 事件通知后续的算子。由于现在源节点可能已经执行完成,Checkpoint 控制器需要改为通知那些本身尚未执行结束、但是所有的前驱任务都已经执行完成的任务。最后,如果一个算子所有任务要么在开始 Checkpoint 的时候已经变为『完成』状态、要么在保存当前状态时已经处理完成所有数据,该算子就会被标记为『执行完成』。
除了在 Checkpoint 时确实有任务执行完成的情况下我们限制作业升级时对作业拓扑结构的修改,上述修改对用户是透明的。具体来说,我们不允许用户在一个被标记为『执行完成』的算子前增加新的算子,因为这将导致一个『执行完成』的算子有一个尚未『执行完成』的前驱,而这违反了 Flink 中算子按拓扑序结束的语义。
修正作业结束的流程
基于上述对包含结束任务的作业进行 Checkpoint 的能力,我们现在可以解决两阶段提交的算子在流模式下无法提交最后一部分数据的问题。总的来说,Flink 作业结束有两种可能的方式:
- 所有数据源都是有限的,这种情况下作业会在处理完所有输入数据并提交所有输出到外部系统后结束。
- 用户显式执行 stop-with-savepoint [--drain] 操作。这种情况下作业会创建一个 Savepoint 后结束。如果指定了 --drain,作业将永久结束,这种情况下需要完成所有外部系统中临时数据的提交。另一方面,如果没有指定该参数,那么作业预期后续会基于该 Savepoint 重启,这种情况下则不需要一定完成所有临时数据的提交,只要保持 Savepoint 中记录的状态与外部系统中临时数据的状态一致即可。
我们首先看一下所有数据源有限的情况。为了能够实现端到端的一致性,使用两阶段提交的算子只在 Checkpoint 完成之后才会提交该 Checkpoint 之前的数据。但是,在之前的实现中,对于最后一个周期性的 Checkpoint 到作业执行结束期间所产生的数据,作业是没有一个合适的机会来进行提交的,从而导致数据丢失。需要注意的是我们在作业结束的时候直接提交这部分数据也是不可取的:如果在某个任务完成提交之后,由于其它任务发生错误导致发生了重启,那么从最后一次 Checkpoint 开始的数据就会被重放,从而导致数据重复。
用户通过 stop-with-savepoint [--drain] 来停止作业的情况同样存在问题。在之前的实现中,Flink 将首先阻塞所有的任务,然后创建一个 Savepoint。在 Savepoint 成功之后,所有的数据源任务将主动停止运行,从而使整个作业执行结束。尽管看起来我们可以通过这次 Savepoint 来提交所有数据,但是在现在的实现中,还有一些逻辑实际上是在作业停止运行的过程中执行的,如果这些逻辑产生了新的数据,这些数据最终会丢失。例如,在之前的实现中 endInput() 方法就是在作业停止过程中执行的,一些算子可能在该方法中发送数据,例如用于异步操作的 AsyncWaitOperator。
最后,尽管不指定 drain 参数时,执行 stop-with-savepoint 不需要提交所有的数据,但是我们还是希望这种情况下作业结束的流程可以与前两种情况统一,从而保证代码的可维护性。
为了解决现有实现中存在的问题,我们需要修改作业结束的流程来保证在需要的时候所有的数据都可以保证提交。如图 3 所示,一个直接的想法是我们可以在任务生命周期增加一步,让任务在结束之前等待下一个 Checkpoint 完成。但是,如下文所述,这种方式仍然不能解决所有问题。

图3. 两种保证任务结束前完成数据提交的方法对比。第一种方法直接在任务的生命周期中插入一步,即等待下一个Checkpoint结束,但这种方式下不同任务无法等待同一个Checkpoint / Savepoint。第二种方式解耦了『完成执行逻辑』与『任务结束』,从而允许所有任务首先完成数据处理,然后它们有机会等待同一个Checkpoint / Savepoint。
对于所有数据源都是有限的情况,这种直接的方式可以解决数据无法提交的问题,但是它可能导致比较严重的性能问题。如图 4 所示,如果有多个级连的任务,每个任务都包含两阶段提交的 Sink,那么每个任务都需要在结束之前等待下一次 Checkpoint 完成,这样整个作业需要等待 3 个 Checkpoint 才能结束,这将对作业的执行时间有较大的影响。
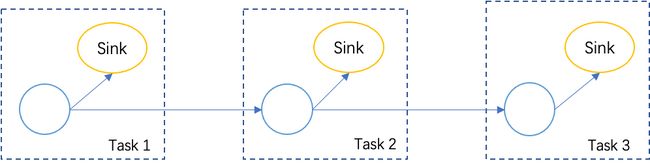
图4. 一个有多级任务并且每个任务都包含两阶段提交算子的例子
对于 stop-with-savepoint [--drain] 的情况,这种直接的想法就不能实施了,因为这种情况下由于不同的任务必须等待不同的 Checkpoint / Savepoint,最终作业无法得到一个完整的 Savepoint。
因此,我们无法采用这种直接的想法。我们采用的方式是将『作业完成所有执行逻辑』与『作业结束』解耦:我们首先让所有任务完成所有的执行逻辑,包括 调用 “endInput()” 这些生命周期方法在内,然后所有的任务就可以并行的等待下一个 Checkpoint / Savepoint 了。此外,对于 stop-with-savepoint [--drain] 的情况,我们也类似的反转当前实现:所有任首先完成所有的执行逻辑,然后它们就可以等待下一个 Savepoint 完成后结束。可以看出,通完这这种方式,我们可以以同样的流程来统一所有作业结束的情况。
基于这一思想,如图 3 的右半部分所示,为了解耦『作业完成所有执行逻辑』与『作业结束』,我们引入了一个新的 EndOfData 事件。对于每一个任务,在完所有的执行逻辑后,它将首先向所有下游发送一个 EndOfData 事件,这样下游也可以明确推断出自己完成了所有的执行逻辑。然后所有的任务就可以并行的等待下一次 Checkpoint 或者指定的 Savepoint 完成后,此时这些任务可以向外部系统提交所有数据后结束。
最后,在修改过程中,我们还重新整理和重命名了『close()』和『dispose()』 两个算子生命周期算法。这两个方法的语义是有所区别的,因为 close() 实际上只在作业正常结束的情况下调用,而 dispose() 在正常结束和异常退出的情况下都会调用。但是,用户很难从这两个名子上看出这个语义。因此,我们将这两上方法重命名为了『finish()』和『close()』:
- finish() 标记着所有的算子已经执行完成,并且不会再产生新的数据。因此,只有当作业正常结束并且已经完全执行完成(即所有数据源执行结束或者用户使用了stop-with-savepoint --drain)的情况下才会调用。
- close() 在所有情况下都会调用,用于释放任务占用的资源。
第二部分
在上述第一部分中,我们已经简要介绍了为支持包含结束任务的 Checkpoint 以及优化作业结束流程所做的工作。在这一部分中我们将更介绍更多实现细节,包括包含结束任务时 Checkpoint 的具体流程与作业结束的具体流程。
包含结束任务的 Checkpoint 实现
如第一部分所述,支持包含结束任务的 Checkpoint 操作的核心思想是对已经完全执行完成的算子打标,并在重启后跳过这些算子的执行。为了实现这一思想,我们需要修改现在 Checkpoint 的流程来创建这些标记并且在恢复时使用这些标记。本节将介绍这一流程的细节实现。
在之前的实现中,只有当所有任务都在运行状态时才可以进行 Checkpoint 操作。如图 5 所示,在这些情况下 Checkpoint 协调器将首先通知所有的数据源任务,数据源任务在完成状态保存后再继续通知后续任务。类似的,在部分任务执行结束的情况下,我们需要首先找到当前仍在运行的部分中的新的『源任务』,也就是那些正在运行但是所有前驱任务都已经执行完成的任务,然后通过通知这些任务来启动 Checkpoint 担任。Checkpoint 协调器在 JobManaer 中任务记录的最新状态原子的计算当前的『源任务』列表。
通知这些源任务的过程可能存在 状态竞争:当 Checkpoint 协调器选中一个任务进行通知的过程中,这个任务可能恰好执行完成并汇报结束状态,从而导致通知失败。在这种情况下,我们选择终止这次 Checkpoint。

图5. 部分任务结束后Checkpoint的Trigger方式
为了在 Checkpoint 中记录算子的结束状态,我们需要扩展 Checkpoint 的格式。一个 Checkpoint 是由所有有状态算子的状态组成的,而每个算子的状态则是由它所有并发实例的状态组成。这里需要指出的是,任务(Task)这一概念并不在 Checkpoint 中反映。任务更多的是一个物理执行的窗口,用于驱动它所包含的所有算子并发实例的执行。 但是在一个作业的多次执行中,由于用户可能修改作业拓扑结构 ,从而使任务的划分发生变化,因此任务在两次执行中可能不是一一对应的。因此,执行结束的标记需要附加在 Checkpoint 中的算子状态上。
如第一部分图 2 所示,在进行 Checkpoint 时根据算子当前的执行状态可以将算子分为三类:
- 完全执行结束:如果一个算子的所有并发实例都执行完成,该算子可以被认为完全执行结束,在重启后可以跳过该算子的执行。我们就需要对这些算子打标。
- 部分执行结束:如果一个算子的部分实例执行完成,那么它在作业重启后需要继续执行剩余的逻辑。整体上我们可以认为这种情况下算子的状态是由所有仍在执行的并发实例的状态组成的,这些状态可以代表尚未执行完成的逻辑。
- 没有完成的实例:这种情况下算子状态与现有实现相同。
后续作业从 Checkpoint 中重启时,我们可以跳过完全执行结束的算子,并且继续执行其它两种类型的算子。
但是,对于部分执行结束的算子,实际情况会更加复杂。在重启时,部分执行结束算子的剩余状态将会被重新分发到所有实例中,这一流程与算子并发修改的情况类似。对于所有类型的状态,Keyed State [5] 与普通的 Oeprator State [6] 的状态可以正常分发,但是 Broacast State [7] 与 Union Operator State [8] 存在问题:
- Broadcast State 在重启后总是将第一个并发实例的状态广播给所有的新的并发实例。但是,如果第一个并发实例已经执行结束,那么它的状态将为空,这将导致所有并发实例的状态变为空,算子将从头执行,这是不符合预期的。
- Union Operator State 在重启后会将所有算子的状态聚合后分发给所有的新的并发实例。基于这一行为,许多算子可能会选择其中一个并发实例来存储所有并发实例共享的状态。类似的,如果所选中的并发实例已经执行结束,那么这部分状态就丢失了。
这实际修改并发的场景中,这两个问题是不会发生的,因为这种情况下并不存在已执行完成的子任务。为了解决上述问题,对于 Broadcast State,我们选择任意一个运行状态的子任务做为广播状态的来源;对于 Union Operator State,我们需要保证能够收集所有子任务的状态,因此目前如果我们观察到一个使用了 Union Operator State 的算子部分执行结束的话,我们取消这次 Checkpoint,后续等到该算子所有子任务执行完成,Checkpoint 将可以继续。
原则上,用户可以在两次执行期间对拓扑进行修改。但是,考虑到任务结束的情况,对拓扑修改有一定的限制:用户不能在一个完全结束的算子之前增加新的算子。Flink 将在作业重启时进行检测并在有此类修改时报错。
修正后的作业结束流程
如第一部分所述,基于在部分任务结束后继续做 Checkpoint 的能力,我们可以对现有作业结束流程进行修正,从而保证两阶段提交的算子总是可以正常提交数据。本节将详细描述修改前后的结束流程。
原作业结束流程
如前文所述,作业结束包括两种情况:所有数据源结束或用户执行 stop-with-savepoint --drain。我们首先来看一下之前的作业结束流程。
所有数据源结束
如果所有的数据源都是有限的,那么作业将在所有数据处理完成后结束,并且所有数据都需要提交。在这种情况下,数据源任务将首先发送一个 MAX_WATERMARK (Long.MAX_VALUE) 然后开始结束任务。在结束过程中,任务将依次对所有算子调用 endOfInput()、close()、和dispose(),然后向下游发送 EndOfPartitionEvent 事件。后续任务在收所有输入边中都读到 EndOfPartitionEvent 事件后,也会开始执行结束流程,这一过程不断重复直到所有任务都结束。
- Source operators emit MAX_WATERMARK
- On received MAX_WATERMARK for non-source operators
a. Trigger all the event-time timers
b. Emit MAX_WATERMARK
- Source tasks finished
a. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
- On received EndOfPartitionEvent for non-source tasks
a. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
用户执行 stop-with-savepoint --drain
用户可以对有限或无限数据流作业执行 stop-with-savepoint [--drain] 操作来结束作业。在这种情况下,作业将首先触发一个同步 Savepoint 操作,并且阻塞所有任务直到该 Savepoint 完成。如果 Savepoint 成功完成,那么所有的数据源任务将主动执行结束流程,后续流程与所有数据源有限的情况类似。
- Trigger a savepoint
- Sources received savepoint trigger RPC
a. If with –-drain
i. source operators emit MAX_WATERMARK
b. Source emits savepoint barrier
- On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
- On received savepoint barrier for non-source operators
a. The task blocks till the savepoint succeed
- Finish the source tasks actively
a. If with –-drain
ii. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
- On received EndOfPartitionEvent for non-source tasks
a. If with –-drain
i. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent e. Task cleanup
该命令有一个可选的 --drain 的参数,如果未指定该参数,后续作业可以从 Savepoint 恢复执行,否则用户预期作业永久结束。因此,只有用户指定该参数的情况下,作业才会发送 MAX_WATERMARK 并且对所有算子调用 endInput()。
修正后作业结束流程
如第一部分所述,在修正后的结束流程中,我们通过增加一个新的 EndOfData 事件解耦了『任务完成执行逻辑』与『任务结束』。每个任务将首先在完成全部执行逻辑后向下游发送一个 EndOfData 事件,这样下游任务也可以先完成所有执行逻辑,然后所有任务就可以并行的等待下一个 Checkpoint 或 指定的 Savepoint 来完成提交所有数据。
本节将详细描述修正后的执行流程。由于我们将 close() / dispose() 方法重命名了 finish() / close(),我们将在后续描述中坚持使用这一术语。
修正后的执行流程如下:
- Source tasks finished due to no more records or stop-with-savepoint.
a. if no more records or stop-with-savepoint –-drain
i. source operators emit MAX_WATERMARK
ii. endInput(inputId) for all the operators
iii. finish() for all the operators
iv. emit EndOfData[isDrain = true] event
b. else if stop-with-savepoint
i. emit EndOfData[isDrain = false] event
c. Wait for the next checkpoint / the savepoint after operator finished complete
d. close() for all the operators
e. Emit EndOfPartitionEvent
f. Task cleanup
- On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
- On received EndOfData for non-source tasks
a. If isDrain
i. endInput(int inputId) for all the operators
ii. finish() for all the operators
b. Emit EndOfData[isDrain = the flag value of the received event]
- On received EndOfPartitionEvent for non-source tasks
a. Wait for the next checkpoint / the savepoint after operator finished complete
b. close() for all the operators
c. Emit EndOfPartitionEvent
d. Task cleanup
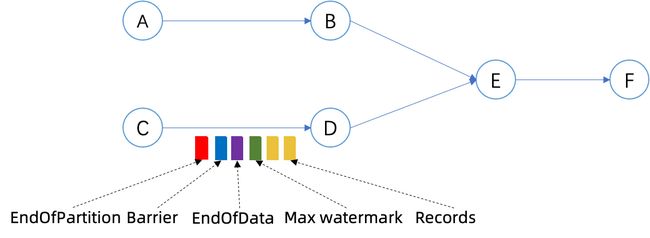
图6. 一个使用修正后的结束流程的作业的例子
一个例子如图 6 所示。我们首先来看一下所有数据源都是有限的情况。
如果任务 C 首先在处理完所有数据后结束,它将首先发送 MAX_WATERMARK,然后对所有算子执行对应结束的生命周期方法并发送 EndOfData 事件。在这之后,它首先等待下一个 Checkpoint 完成,然后发送 EndOfPartitionEvent 事件。
任务 D 在收到 EndOfData 事件后将首先对算子执行结束对应对应结束的生命周期方法。由于任何在算子执行结束后开始的 Checkpoint 都可以提交剩余的数据,而任务 C 提交数据所依赖的 Checkpoint 的 Barrier 事件在 EndOfData 事件后到达,因此任务 D 实际上可以与任务 C 使用同样的 Checkpoint 完成数据提交。
任务 E 略有不同,因为它有两个输入,而任务 A 可能继续运行一段时间。因此,任务 E 必须等到它从两个输入都读取到 EndOfData 事件后才可以开始结束算子执行,并且它需要依赖一个不同的 Checkpoint 来完成数据提交。
另一方面,当使用 stop-with-savepoint [--drain] 来结束作业时,整个流程与数据源有限的情况相同,只是所有任务不是等待任意的下一个 Checkpoint,而是等待一个指定的 Savepoint 来完成数据提交。此外,这种情况下由于任务 C 与任务 A 一定同时结束,因此我们可以保证任务E也可以在结束前等到这个特定的 Savepoint。
结论
通过支持在部分任务结束后的 Checkpoint 作业并且修正作业结束的流程,我们可以支持同时使用有限数据源与无限数据源的作业,并且可以保证所有数据源都是有限的情况下最后一部分数据可以正常提交。这部分修改保证了数据一致性与结束完整性,并且支持了包含有限数据源的作业的错误恢复。这一机制主要在 1.14 实现,并且在 1.15 中默认打开。如果遇到任何问题,欢迎在 dev 或 user / user-zh 邮件列表中发起讨论或提出问题。
[1] Apache Flink's stream-batch unification powers Alibaba's 11.11 in 2020
[2] https://www.youtube.com/watch?t=666&v=4qSlsYogALo&feature=youtu.be
[3] Checkpointing | Apache Flink
[4] Apache Flink: An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
[5] Working with State | Apache Flink
[6] Working with State | Apache Flink
[7] Working with State | Apache Flink
[8] Working with State | Apache Flink
点击进入 Flink 中文学习网https://flink-learning.org.cn/