C语言-哈夫曼编码解码程序
(老代码修复)
C语言-哈夫曼编码解码程序
功能:
- 输入一串大写英文字符,统计字母频率并输出哈夫曼编码
- 输入一串哈夫曼编码,解码成大写英文字母输出并统计字母频率
- 先续遍历创建的哈夫编码
#includeTEST
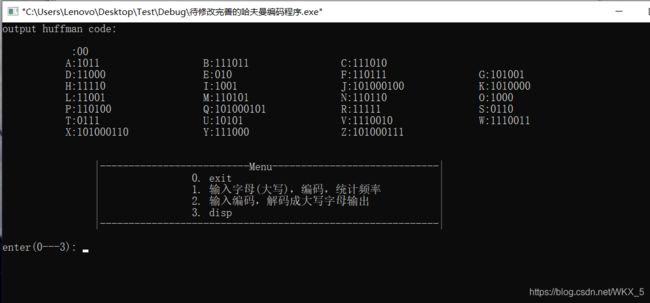
主界面

解码
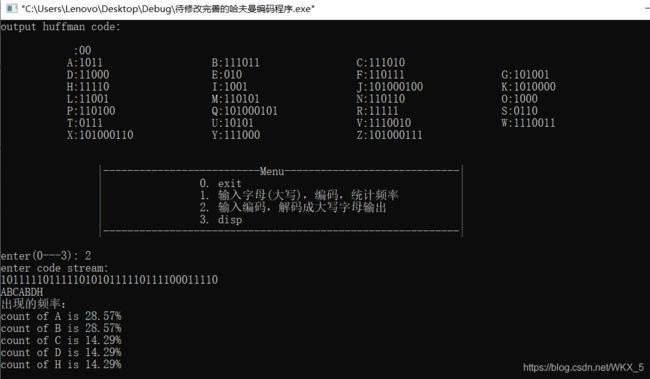
编码