Yolov5--从模块解析到网络结构修改(添加注意力机制)
文章目录
- 1.模块解析(common.py)
-
-
- 01. Focus模块
- 02. CONV模块
- 03.Bottleneck模块:
- 04.C3模块
- 05.SPP模块
-
- 2.为yolov5添加CBAM注意力机制
-
-
- 01.CBAM机制
- 02.具体步骤
-
-
- ①.以yolov5l结构为例(其实只是深度和宽度因子不同),修改yolov5l.yaml,将C3模块修改为添加注意力机制后的模块CBAMC3,参数不变即可。
- ②.在common.py中添加CBAMC3模块
- ③.修改yolo.py,添加额外的判断语句
-
-
最近在进行yolov5的二次开发,软件开发完毕后才想着对框架进行一些整理和进一步学习,以下将记录一些我的学习记录。
1.模块解析(common.py)
01. Focus模块
作用:下采样
输入:data( 3×640×640 彩色图片)
Focus模块的作用是对图片进行切片,类似于下采样,先将图片变为320×320×12的特征图,再经过3×3的卷积操作,输出通道32,最终变为320×320×32的特征图,是一般卷积计算量的4倍,如此做下采样将无信息丢失。
输出:32×320×320特征图
结构图片描述:

图示切分过程,channels变为4倍

代码实现:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
# c1输入,c2输出,s为步长,k为卷积核大小
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 输入channel数量变为4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
# 进行切分,再进行concat
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
02. CONV模块
- 作者在这个基本卷积模块中封装了三个功能,包括卷积(Conv2d)、BN以及Activate函数(在新版yolov5中,作者采用了SiLU函数作为激活函数),同时autopad(k, p)实现了自动计算padding的效果。
- 总的来说Conv实现了将输入特征经过卷积层,激活函数,归一化层,得到输出层。
输出:输入大小的一半
结构图片描述:


代码实现:
class Conv(nn.Module):
# Standard convolution
# ch_in, ch_out, kernel, stride, padding, groups
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# k为卷积核大小,s为步长
# g即group,当g=1时,相当于普通卷积,当g>1时,进行分组卷积。
# 分组卷积相对与普通卷积减少了参数量,提高训练效率
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
03.Bottleneck模块:
- 先将channel 数减小再扩大(默认减小到一半),具体做法是先进行1×1卷积将channel减小一半,再通过3×3卷积将通道数加倍,并获取特征(共使用两个标准卷积模块),其输入与输出的通道数是不发生改变的。
- shortcut参数控制是否进行残差连接(使用ResNet)。
- 在yolov5的backbone中的Bottleneck都默认使shortcut为True,在head中的Bottleneck都不使用shortcut。
- 与ResNet对应的,使用add而非concat进行特征融合,使得融合后的特征数不变。
结构图片描述:

代码实现:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
# 特别参数
# shortcut:是否给bottleneck结构部添加shortcut连接,添加后即为ResNet模块;
# e,即expansion。bottleneck结构中的瓶颈部分的通道膨胀率,默认使用0.5即变为输入的1/2
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
04.C3模块
- 在新版yolov5中,作者将BottleneckCSP(瓶颈层)模块转变为了C3模块,其结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层以及多个Bottleneck模块(数量由配置文件.yaml的n和depth_multiple参数乘积决定)
- 从下图可以看出,C3相对于BottleneckCSP模块不同的是,经历过残差输出后的Conv模块被去掉了,concat后的标准卷积模块中的激活函数也由LeakyRelu变为了SiLU(同上)。
- 该模块是对残差特征进行学习的主要模块,其结构分为两支,一支使用了上述指定多个Bottleneck堆叠和3个标准卷积层,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。
结构图片描述:
C3模块:

BottleNeckCSP模块:
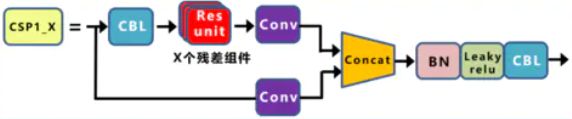
代码实现:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
05.SPP模块
- SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)。
- 对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
结构图片描述:
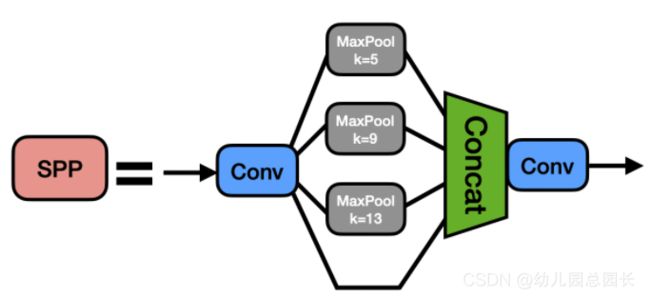
代码实现:
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
2.为yolov5添加CBAM注意力机制
01.CBAM机制

采用CBAM混合域注意力机制,同时对通道注意力和空间注意力进行评价打分。CBAM 包含2个子模块,Channel Attention Module(CAM)和Spartial Attention Module (SAM) 分别实现通道和空间的Attention。
此处参考1. 注意力机制参考链接
2. CBAM参考链接
02.具体步骤
①.以yolov5l结构为例(其实只是深度和宽度因子不同),修改yolov5l.yaml,将C3模块修改为添加注意力机制后的模块CBAMC3,参数不变即可。
②.在common.py中添加CBAMC3模块
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# 将最后的标准卷积模块改为了注意力机制提取特征
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
③.修改yolo.py,添加额外的判断语句
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR, CBAMC3]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, CBAMC3]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
至此,在训练模型时调用我们修改后的yolov5l.yaml,即可在验证注意力机制在yolov5模型上的有效性。