Pod 排错指南
Pod 在 Waiting 状态或者ContainerCreating 状态
Pod 处于 Crashing 或别的不健康状态
Failed
DNS 无法解析
Pod 一直处于 ImagePullBackOff 状态
Pod 一直处于 ImageInspectError 状态
Pod 处于 CrashLoopBackOff 状态
容器进程主动退出
系统 OOM
cgroup OOM
节点内存碎片化
Pod 一直处于 Unknown 状态
Pod 一直处于 Error 状态
Pod 各种异常现象,可能的原因以及解决方法。
排查过程常用的命名如下 :
查看 Pod 状态: kubectl get pod
查看 Pod 的 yaml 配置: kubectl get pod
查看 Pod 事件: kubectl describe pod
查看容器日志: kubectl logs
Pod 有多种状态,这里罗列一下 :
Error : Pod 启动过程中发生错误
NodeLost : Pod 所在节点失联
Unkown : Pod 所在节点失联或其它未知异常
Waiting : Pod 等待启动
Pending : Pod 等待被调度
ContainerCreating : Pod 容器正在被创建
Terminating : Pod 正在被销毁
CrashLoopBackOff : 容器退出, kubelet 正在将它重启
InvalidImageName : 无法解析镜像名称
ImageInspectError : 无法校验镜像
ErrImageNeverPull : 策略禁止拉取镜像
ImagePullBackOff : 正在重试拉取
RegistryUnavailable : 连接不到镜像中心
ErrImagePull : 通用的拉取镜像出错
CreateContainerConfigError : 不能创建 kubelet 使用的容器配置
CreateContainerError : 创建容器失败
RunContainerError : 启动容器失败
PreStartHookError : 执行 preStart hook 报错
PostStartHookError : 执行 postStart hook 报错
ContainersNotInitialized : 容器没有初始化完毕
ContainersNotReady : 容器没有准备完毕
ContainerCreating :容器创建中
PodInitializing : pod 初始化中
DockerDaemonNotReady : docker 还没有完全启动
NetworkPluginNotReady : 网络插件还没有完全启动
Pods
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod (就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。 Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。 Pod 所建模的是特定于应用的“逻辑主机”,其中包含一个或多个应用容器, 这些容器是相对紧密的耦合在一起的。 在非云环境中,在相同的物理机或虚拟机上运行的应用类似于 在同一逻辑主机上运行的云应用。
除了应用容器,Pod 还可以包含在 Pod 启动期间运行的 Init 容器。 你也可以在集群中支持临时性容器 的情况下,为调试的目的注入临时性容器。
什么是 Pod?
说明: 除了 Docker 之外,Kubernetes 支持 很多其他容器运行时, Docker 是最有名的运行时, 使用 Docker 的术语来描述 Pod 会很有帮助。
Pod 的共享上下文包括一组 Linux 名字空间、控制组(cgroup)和可能一些其他的隔离 方面,即用来隔离 Docker 容器的技术。 在 Pod 的上下文中,每个独立的应用可能会进一步实施隔离。
就 Docker 概念的术语而言,Pod 类似于共享名字空间和文件系统卷的一组 Docker 容器。
使用 Pod
下面是一个 Pod 示例,它由一个运行镜像 nginx:1.14.2 的容器组成。
pods/simple-pod.yaml
![]()
转存失败重新上传取消
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
要创建上面显示的 Pod,请运行以下命令:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Pod 通常不是直接创建的,而是使用工作负载资源创建的。 有关如何将 Pod 用于工作负载资源的更多信息,请参阅 使用 Pod。
用于管理 pod 的工作负载资源
通常你不需要直接创建 Pod,甚至单实例 Pod。 相反,你会使用诸如 Deployment 或 Job 这类工作负载资源 来创建 Pod。如果 Pod 需要跟踪状态, 可以考虑 StatefulSet 资源。
Kubernetes 集群中的 Pod 主要有两种用法:
-
运行单个容器的 Pod。"每个 Pod 一个容器"模型是最常见的 Kubernetes 用例; 在这种情况下,可以将 Pod 看作单个容器的包装器,并且 Kubernetes 直接管理 Pod,而不是容器。
-
运行多个协同工作的容器的 Pod。 Pod 可能封装由多个紧密耦合且需要共享资源的共处容器组成的应用程序。 这些位于同一位置的容器可能形成单个内聚的服务单元 —— 一个容器将文件从共享卷提供给公众, 而另一个单独的“边车”(sidecar)容器则刷新或更新这些文件。 Pod 将这些容器和存储资源打包为一个可管理的实体。
说明: 将多个并置、同管的容器组织到一个 Pod 中是一种相对高级的使用场景。 只有在一些场景中,容器之间紧密关联时你才应该使用这种模式。
每个 Pod 都旨在运行给定应用程序的单个实例。如果希望横向扩展应用程序(例如,运行多个实例 以提供更多的资源),则应该使用多个 Pod,每个实例使用一个 Pod。 在 Kubernetes 中,这通常被称为 副本(Replication)。 通常使用一种工作负载资源及其控制器 来创建和管理一组 Pod 副本。
参见 Pod 和控制器以了解 Kubernetes 如何使用工作负载资源及其控制器以实现应用的扩缩和自动修复。
Pod 怎样管理多个容器
Pod 被设计成支持形成内聚服务单元的多个协作过程(形式为容器)。 Pod 中的容器被自动安排到集群中的同一物理机或虚拟机上,并可以一起进行调度。 容器之间可以共享资源和依赖、彼此通信、协调何时以及何种方式终止自身。
例如,你可能有一个容器,为共享卷中的文件提供 Web 服务器支持,以及一个单独的 "边车 (sidercar)" 容器负责从远端更新这些文件,如下图所示:
有些 Pod 具有 Init 容器 和 应用容器。 Init 容器会在启动应用容器之前运行并完成。
Pod 天生地为其成员容器提供了两种共享资源:网络和 存储。
使用 Pod
你很少在 Kubernetes 中直接创建一个个的 Pod,甚至是单实例(Singleton)的 Pod。 这是因为 Pod 被设计成了相对临时性的、用后即抛的一次性实体。 当 Pod 由你或者间接地由 控制器 创建时,它被调度在集群中的节点上运行。 Pod 会保持在该节点上运行,直到 Pod 结束执行、Pod 对象被删除、Pod 因资源不足而被 驱逐 或者节点失效为止。
说明: 重启 Pod 中的容器不应与重启 Pod 混淆。 Pod 不是进程,而是容器运行的环境。 在被删除之前,Pod 会一直存在。
当你为 Pod 对象创建清单时,要确保所指定的 Pod 名称是合法的 DNS 子域名。
Pod 和控制器
你可以使用工作负载资源来创建和管理多个 Pod。 资源的控制器能够处理副本的管理、上线,并在 Pod 失效时提供自愈能力。 例如,如果一个节点失败,控制器注意到该节点上的 Pod 已经停止工作, 就可以创建替换性的 Pod。调度器会将替身 Pod 调度到一个健康的节点执行。
下面是一些管理一个或者多个 Pod 的工作负载资源的示例:
- Deployment
- StatefulSet
- DaemonSet
Pod 模版
负载资源的控制器通常使用 Pod 模板(Pod Template) 来替你创建 Pod 并管理它们。
Pod 模板是包含在工作负载对象中的规范,用来创建 Pod。这类负载资源包括 Deployment、 Job 和 DaemonSets 等。
工作负载的控制器会使用负载对象中的 PodTemplate 来生成实际的 Pod。 PodTemplate 是你用来运行应用时指定的负载资源的目标状态的一部分。
下面的示例是一个简单的 Job 的清单,其中的 template 指示启动一个容器。 该 Pod 中的容器会打印一条消息之后暂停。
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 这里是 Pod 模版
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# 以上为 Pod 模版
修改 Pod 模版或者切换到新的 Pod 模版都不会对已经存在的 Pod 起作用。 Pod 不会直接收到模版的更新。相反, 新的 Pod 会被创建出来,与更改后的 Pod 模版匹配。
例如,Deployment 控制器针对每个 Deployment 对象确保运行中的 Pod 与当前的 Pod 模版匹配。如果模版被更新,则 Deployment 必须删除现有的 Pod,基于更新后的模版 创建新的 Pod。每个工作负载资源都实现了自己的规则,用来处理对 Pod 模版的更新。
在节点上,kubelet 并不直接监测 或管理与 Pod 模版相关的细节或模版的更新,这些细节都被抽象出来。 这种抽象和关注点分离简化了整个系统的语义,并且使得用户可以在不改变现有代码的 前提下就能扩展集群的行为。
Pod 更新与替换
正如前面章节所述,当某工作负载的 Pod 模板被改变时,控制器会基于更新的模板 创建新的 Pod 对象而不是对现有 Pod 执行更新或者修补操作。
Kubernetes 并不禁止你直接管理 Pod。对运行中的 Pod 的某些字段执行就地更新操作 还是可能的。不过,类似 patch 和 replace 这类更新操作有一些限制:
-
Pod 的绝大多数元数据都是不可变的。例如,你不可以改变其
namespace、name、uid或者creationTimestamp字段;generation字段是比较特别的,如果更新 该字段,只能增加字段取值而不能减少。 -
如果
metadata.deletionTimestamp已经被设置,则不可以向metadata.finalizers列表中添加新的条目。 -
Pod 更新不可以改变除
spec.containers[*].image、spec.initContainers[*].image、spec.activeDeadlineSeconds或spec.tolerations之外的字段。 对于spec.tolerations,你只被允许添加新的条目到其中。 -
在更新
spec.activeDeadlineSeconds字段时,以下两种更新操作是被允许的:- 如果该字段尚未设置,可以将其设置为一个正数;
- 如果该字段已经设置为一个正数,可以将其设置为一个更小的、非负的整数。
资源共享和通信
Pod 使它的成员容器间能够进行数据共享和通信。
Pod 中的存储
一个 Pod 可以设置一组共享的存储卷。 Pod 中的所有容器都可以访问该共享卷,从而允许这些容器共享数据。 卷还允许 Pod 中的持久数据保留下来,即使其中的容器需要重新启动。 有关 Kubernetes 如何在 Pod 中实现共享存储并将其提供给 Pod 的更多信息, 请参考卷。
Pod 联网
每个 Pod 都在每个地址族中获得一个唯一的 IP 地址。 Pod 中的每个容器共享网络名字空间,包括 IP 地址和网络端口。 Pod 内 的容器可以使用 localhost 互相通信。 当 Pod 中的容器与 Pod 之外 的实体通信时,它们必须协调如何使用共享的网络资源 (例如端口)。
在同一个 Pod 内,所有容器共享一个 IP 地址和端口空间,并且可以通过 localhost 发现对方。 他们也能通过如 SystemV 信号量或 POSIX 共享内存这类标准的进程间通信方式互相通信。 不同 Pod 中的容器的 IP 地址互不相同,没有特殊配置,无法通过 OS 级 IPC 进行通信就不能使用 IPC 进行通信。 如果某容器希望与运行于其他 Pod 中的容器通信,可以通过 IP 联网的方式实现。
Pod 中的容器所看到的系统主机名与为 Pod 配置的 name 属性值相同。 网络部分提供了更多有关此内容的信息。
容器的特权模式
在 Linux 中,Pod 中的任何容器都可以使用容器规约中的 安全性上下文中的 privileged(Linux)参数启用特权模式。 这对于想要使用操作系统管理权能(Capabilities,如操纵网络堆栈和访问设备) 的容器很有用。
如果你的集群启用了 WindowsHostProcessContainers 特性,你可以使用 Pod 规约中安全上下文的 windowsOptions.hostProcess 参数来创建 Windows HostProcess Pod。 这些 Pod 中的所有容器都必须以 Windows HostProcess 容器方式运行。 HostProcess Pod 可以直接运行在主机上,它也能像 Linux 特权容器一样,用于执行管理任务。
说明: 你的容器运行时必须支持 特权容器的概念才能使用这一配置。
静态 Pod
静态 Pod(Static Pod) 直接由特定节点上的 kubelet 守护进程管理, 不需要API 服务器看到它们。 尽管大多数 Pod 都是通过控制面(例如,Deployment) 来管理的,对于静态 Pod 而言,kubelet 直接监控每个 Pod,并在其失效时重启之。
静态 Pod 通常绑定到某个节点上的 kubelet。 其主要用途是运行自托管的控制面。 在自托管场景中,使用 kubelet 来管理各个独立的 控制面组件。
kubelet 自动尝试为每个静态 Pod 在 Kubernetes API 服务器上创建一个 镜像 Pod。 这意味着在节点上运行的 Pod 在 API 服务器上是可见的,但不可以通过 API 服务器来控制。
说明:
静态 Pod 的 spec 不能引用其他的 API 对象(例如:ServiceAccount、ConfigMap、Secret等)。
容器探针
Probe 是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 可以执行三种动作:
ExecAction(借助容器运行时执行)TCPSocketAction(由 kubelet 直接检测)HTTPGetAction(由 kubelet 直接检测)
你可以参阅 Pod 的生命周期文档中的探针部分。
接下来
- 了解 Pod 生命周期
- 了解 RuntimeClass,以及如何使用它 来配置不同的 Pod 使用不同的容器运行时配置
- 了解 Pod 拓扑分布约束
- 了解 PodDisruptionBudget,以及你 如何可以利用它在出现干扰因素时管理应用的可用性。
- Pod 在 Kubernetes REST API 中是一个顶层资源。 Pod 对象的定义中包含了更多的细节信息。
- 博客 分布式系统工具箱:复合容器模式 中解释了在同一 Pod 中包含多个容器时的几种常见布局。
要了解为什么 Kubernetes 会在其他资源 (如 StatefulSet 或 Deployment) 封装通用的 Pod API,相关的背景信息可以在前人的研究中找到。具体包括:
- Aurora
- Borg
- Marathon
- Omega
- Tupperware.
通常情况下pod发生问题时首先收集一下错误
kubectl get pod
kubectl describe pod
kubectl logs
Pod Pending 状态
如果一个 Pod 处于 Pending 状态,表示 Pod 没有被调度到节点上。通常这是因为某种类型的资源不足导致无法调度。 查看上面的 kubectl describe … 命令的输出,其中应该显示了为什么没被调度的原因。 常见原因如下:
资源不足: 你可能耗尽了集群上所有的 CPU 或内存。此时,你需要删除 Pod、调整资源请求或者为集群添加节点。
关于pod的资源计算可以参考官方文档:
https://kubernetes.io/zh/docs/concepts/configuration/manage-resources-containers/
使用了 hostPort: 如果绑定 Pod 到 hostPort,那么能够运行该 Pod 的节点就有限了。多数情况下,hostPort 是非必要的,而应该采用 Service 对象来暴露 Pod。 如果确实需要使用hostPort,那么集群中节点的个数就是所能创建的 Pod 的数量上限。通常情况下是HostPort 已被占用
Pod 在 Waiting 状态或者ContainerCreating 状态
如果 Pod 处于 Waiting 状态,则表示 Pod 已经被调度到某工作节点,但是无法在该节点上运行。 同样,kubectl describe … 命令的输出可能很有用。 Waiting 状态的最常见原因是拉取镜像失败。要检查的有以下几个方面:
确保镜像名字拼写正确核实是否是配置了错误的镜像
kubelet无法访问镜像(国内环境访问部分带有gcr.io需要做额外特殊设置)
核实私有镜像的密钥、免密设置等
镜像太大,拉取超时(可以适当调整 kubelet 的 --image-pull-progress-deadline 和 --runtime-request-timeout 选项)
确保镜像已被推送到镜像仓库 用手动命令 docker pull <镜像> 试试看
镜像是否可拉取。
pod 异常日志抛出CNI网络错误以及无法启动
般需要检查 CNI 网络插件的配置。
容器无法启动,则需要检查使用的镜像和容器配置的参数是否无误,通常情况下是由于没有常驻进程和参数设置造成。
Pod 处于 Crashing 或别的不健康状态
一般情况是pod被调度后,容器资源管理约束造成,排查参考官方文档:为 Pod 和容器管理资源 | Kubernetes
Pod 处于 Error 状态
1.通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括:
依赖的 ConfigMap、Secret 或者 PV 等不存在
请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
违反集群的安全策略,比如违反了 PodSecurityPolicy 等
容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
2.通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括
依赖的 ConfigMap、Secret 或者 PV 等不存在
请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
违反集群的安全策略,比如违反了 PodSecurityPolicy 等
容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
Pod 处于 Terminating 或 Unknown 状态
从 v1.5 开始,Kubernetes 不会因为 Node 失联而删除其上正在运行的 Pod,而是将其标记为 Terminating 或 Unknown 状态。想要删除这些状态的 Pod 有三种方法:
1.从集群中删除该 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。而在物理机部署的集群中,需要管理员手动删除 Node(如 kubectl delete node 。
2.Node 恢复正常。Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。 用户强制删除。用户可以执行 kubectl delete pods
–grace-
3.period=0 --force 强制删除 Pod。除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
pod行为异常
行为异常是指 Pod 没有按预期的行为执行,比如没有运行 podSpec 里面设置的命令行参数。这一般是 podSpec yaml 文件内容有误,可以尝试使用 --validate 参数重建容器。
例:
kubectl delete pod mypod
也可以查看创建后的 podSpec 是否是对的
kubectl get pod mypod -o yaml
在修改静态 Pod 的 Manifest 后其未自动重建
Kubelet 使用 inotify 机制检测 /etc/kubernetes/manifests 目录(可通过 Kubelet 的 --pod-manifest-path 选项指定)中静态 Pod 的变化,并在文件发生变化后重新创建相应的 Pod。但有时也会发生修改静态 Pod 的 Manifest 后未自动创建新 Pod 的情景,此时一个简单的修复方法是重启 Kubelet。
对于pod异常官方已给出方案流程可参考:Troubleshoot Applications
思路图解:
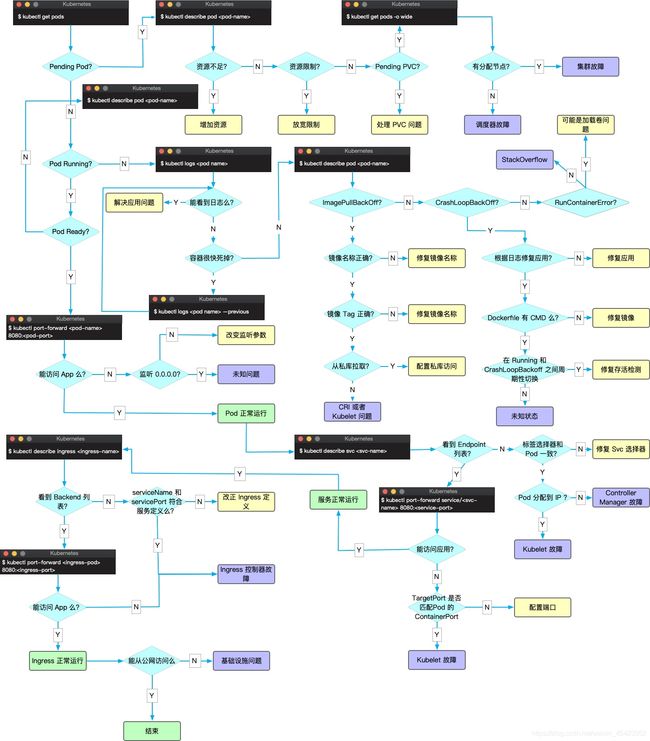
k8s中故障排查可以分为节点的故障排查和kubernetes组件故障排查两大类。例如:基础架构守护进程问题,如NTP服务关闭,硬件问题:cpu、内存或者磁盘损坏,内核问题:内核死锁,文件系统损坏,容器运行时问题,例如运行的守护进程无响应。当kubernetes节点发生这些问题时,k8s服务组件并不能感知以上问题,会导致Pod仍然会调度到问题节点。为了解决该问题,社区引入了守护进程node-problem-detector,守护进程收集节点问题,并上报到api-server。例如可以诊断Runtime无响应,Linux Kernel无响应,网络异常,文件描述符异常,硬件问题如cpu,内存,磁盘等故障。
node-problem-detector通过设置NodeCondition或者创建Event对象来汇报问题,汇报问题有两种方式。
方式一:NodeCondition:针对永久性故障,会通过设置NodeCondition来改变节点状态。
方式二:临时故障通过Event来提醒相关对象,比如通知当前节点运行的所有Pod。
需要注意的是NPD只负责获取异常事件,并修改node condition,不会对节点状态和调度产生影响,所以需要自定义控制器,监听NPD汇报的condition,如果发现上报了节点出错的信息后,那么可以给node打上taint,这样就可以阻止Pod调度到故障节点,当问题修复后,重启NPD Pod来清理错误事件。node-problem-detector详细信息可查看官网信息。
可以通过helm的方式安装node-problem-detector,安装完成后可以通过kubectl get pod方式查看安装后的node-problem-detector,另外,安装node-problem-detector后,除了启动pod后,还会启动对应的daemonset。该集群上加上master节点,总共有3个节点,其中有个节点是NotReady状态,故helm安装后,启动了3个node-problem-detector。
除了通过安装node-problem-detector方式排查节点故障,还可以安装支持ssh的pod,并通过负载均衡的方式转发ssh请求,这样就可以连接到node节点里面,查看node节点情况。
除了通过安装node-problem-detector检查节点健康信息外,还可以journalctl查看k8s核心组件日志信息。例如查看kubelet日志信息。
journalctl -afu kubelet -S “2019-01-01 10:00:00”
-u unit,对应systemd拉起的组件,例如kubelet
-f follow 跟踪最新的日志
-a show all 显示所有的日志列
-S since,查看某一时间开始的日志
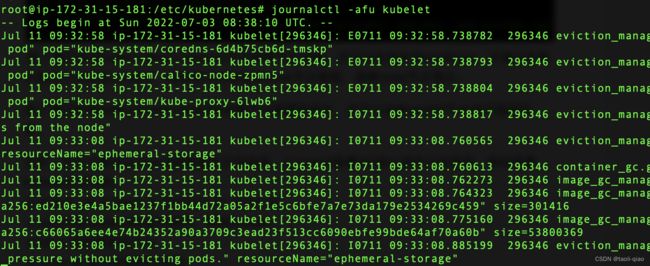
除了journalctl,还可以安装crictl查看pod,容器,image等信息。
例如:如果要查看pod的网络信息,内存等信息,那么可通过如下步骤查看
crictl pods | grep podName,获取到运行的pod的podID
crictl ps | grep podId,获取pod中运行的容器id
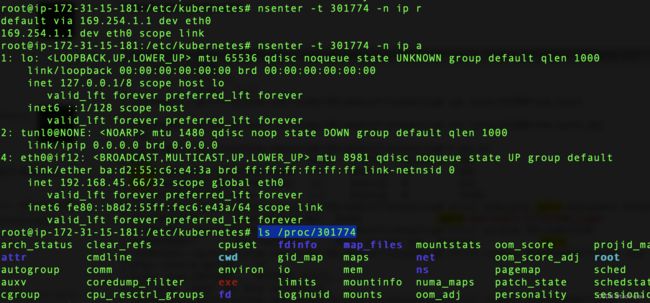
crictl inspect container-id| grep pid:获取容器的进程ID,有了进程Id那么可以查看很多信息,例如查看网络信息和内存信息
nsenter -t 进程id(process id) -n ip a: 查看网络配置信息
nsenter -t 进程id(process id) -n pi r: 查看路由信息
nsenter -t pid -n arping 路由地址: 查看信息转发到了哪里
ls /proc/进程id(process id):查看内存等信息
以下是演示获取pod的process id的过程。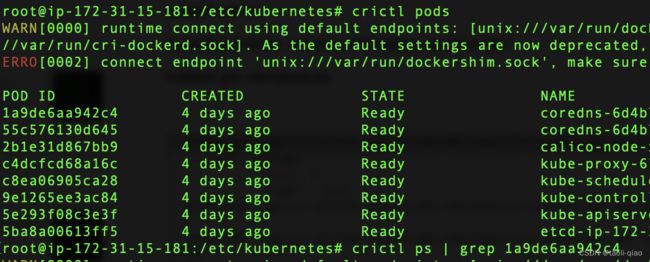
 有了pod的process id后可以看到很多信息,如下所示
有了pod的process id后可以看到很多信息,如下所示
除了上面的命令,crictl其他常用的命令如下所示:
crictl images: 查看下载的image信息
crictl ps:查看所有运行的pod的容器Id信息
crictl logs container-id:查看运行的容器的日志信息
上面介绍了通过crictl查看运行的pod的信息,实际查看pod的日志信息还可以通过kubectl实现。
kubectl logs podName: 查看pod运行的信息
kubectl logs -f -c containername podname: 查看pod中某个容器的运行信息
kubectl logs -f --all-containers podname: 查看pod中所有容器的运行信息
kubectl logs -f -c containername --previous: 如果pod重启过,要查看重启前的日志信息
kubectl exec -it podname --tail -f /path/log: 如果pod运行的日志信息被保存到某个目录下,那么可以通过exec进入pod,--tail命令查看日志信息
kubectl exec -it podname -- ls: exec进入运行的pod,在pod中执行linux命令
kubectl exec -it podname -- bash: exec进入pod,然后可以输入bash的命令,备注:需要启动的容器支持bash命令才行。
上面介绍了部分错误排查的方法,更多错误排查的方法,例如调试service,调试statefulset,调试init容器等,可以查看官网详细信息
Failed
失败(Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。即容器以非0状态退出或者被系统禁止。 (容器进程主动退出)
容器进程如果是自己主动退出 ( 不是被外界中断杀死 ) ,退出状态码一般在 0-128 之间,根据约定,正 常退出时状态码为 0 , 1-127 说明是程序发生异常,主动退出了,比如检测到启动的参数和条件不满足要求,或者运行过程中发生 panic 但没有捕获处理导致程序退出。除了可能是业务程序 BUG ,还有其它许多可能原因,这里我们一一列举下。
DNS 无法解析
可能程序依赖集群 DNS 服务,比如启动时连接数据库,数据库使用 service 名称或外部域名都需
要 DNS 解析,如果解析失败程序将报错并主动退出。解析失败的可能原因 :
集群网络有问题,Pod 连不上集群 DNS 服务
集群 DNS 服务挂了,无法响应解析请求
Service 或域名地址配置有误,本身是无法解析的地址
程序配置有误
配置文件格式错误,程序启动解析配置失败报错退出
配置内容不符合规范,比如配置中某个字段是必选但没有填写,配置校验不通过,程序报错主动退出
Pod 一直处于 ImagePullBackOff 状态
这种情况通常是镜像名称配置错误或者私有镜像的密钥配置错误导致。可以使用docker pull 来验证镜像是否可以正常拉取.
如是私有镜像仓库,需要首先创建一个docker-registry 类型的 Secret (使用的云服务的仓库如阿里镜像仓库如使用免密插件需要去掉这个secret)
kubectl create secret docker-registry my-secret --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
在容器中引用secret
spec:
containers:
- name: private-reg-container
image:
imagePullSecrets:
- name: my-secret
http 类型 registry,地址未加入到 insecure-registry
dockerd 默认从 https 类型的 registry 拉取镜像,如果使用 https 类型的 registry ,则必须将它添加到 insecure-registry 参数中,然后重启或 reload dockerd 生效。
https 自签发类型 resitry,没有给节点添加 ca 证书
如果 registry 是 https 类型,但证书是自签发的,dockerd 会校验 registry 的证书,校验成功才能正常使用镜像仓库,要想校验成功就需要将 registry 的 ca 证书放置到 /etc/docker/certs.d/
私有镜像仓库认证失败
如果 registry 需要认证,但是 Pod 没有配置 imagePullSecret ,配置的 Secret 不存在或者
有误都会认证失败。
镜像文件损坏
如果 push 的镜像文件损坏了,下载下来也用不了,需要重新 push 镜像文件。
镜像拉取超时
如果节点上新起的 Pod 太多就会有许多可能会造成容器镜像下载排队,如果前面有许多大镜像需要下载很长时间,后面排队的 Pod 就会报拉取超时。 kubelet 默认串行下载镜像 :
--serialize-image-pulls Pull images one at a time. We recommend *not* changing the default value on nodes that run docker daemon with version < 1.9 or an Aufs storage backend. Issue #10959 has more details. (default true)
也可以开启并行下载并控制并发:
--registry-qps int32 If > 0, limit registry pull QPS to this value. If 0, unlimited. (default 5) 2. --registry-burst int32 Maximum size of a bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
镜像不不存在:
kubelet 日志 :
PullImage "imroc/test:v0.2" from image service failed: rpc error: code = Unknown desc = Error response from daemon: manifest for imroc/test:v0.2 not found
Pod 一直处于 ImageInspectError 状态
通常是镜像文件损坏了,可以尝试删除损坏的镜像重新拉取
Pod 处于 CrashLoopBackOff 状态
1.Pod 如果处于 CrashLoopBackOff 状态说明之前是启动了,只是又异常退出了,只要 Pod 的
restartPolicy 不是 Never 就可能被重启拉起,此时 Pod 的 RestartCounts 通常是大于0 的,可以先看下容器进程的退出状态码来缩小问题范围。
容器进程主动退出
如果是容器进程主动退出,退出状态码一般在 0-128 之间,除了可能是业务程序 BUG,还有其它许多可能原因。
2.CrashLoopBackOff 状态说明容器曾经启动了,但又异常退出了。可以先查看一下容器的日志
kubectl logs
kubectl logs --previous
一般退出原因有:
容器进程退出(无常驻进程或者服务进程意外退出导致)
健康或存活检查失败退出
也可以登录pod所在节点查看系统日志及kubelet、docker日志进一步排查
系统 OOM
如果发生系统 OOM,可以看到 Pod 中容器退出状态码是 137,表示被 SIGKILL 信号杀死,同时 内核会报错: Out of memory: Kill process ... 。大概率是节点上部署了其它非 K8S 管理的进程消耗了比较多的内存,或者 kubelet 的 --kube-reserved 和 --system-reserved 配的比较小,没有预留足够的空间给其它非容器进程,节点上所有 Pod 的实际内存占用总量不会超过 /sys/fs/cgroup/memory/kubepods 这里 cgroup 的限制,这个限制等于 capacity - "kube-
reserved" - "system-reserved" ,如果预留空间设置合理,节点上其它非容器进程( kubelet,
dockerd, kube-proxy, sshd 等 ) 内存占用没有超过 kubelet 配置的预留空间是不会发生系统
OOM 的,可以根据实际需求做合理的调整。
cgroup OOM
如果是 cgrou OOM 杀掉的进程,从 Pod 事件的下 Reason 可以看到是 OOMKilled ,说明
容器实际占用的内存超过 limit 了,同时内核日志会报 : `` 。 可以根据需求调整下 limit 。
节点内存碎片化
如果节点上内存碎片化严重,缺少大页内存,会导致即使总的剩余内存较多,但还是会申请内存失败, 参考 处理实践: 内存碎片化
健康检查失败
参考 Pod 健康检查失败 进一步定位。
Pod 一直处于 Unknown 状态
通常是节点失联,没有上报状态给 apiserver,到达阀值后 controller-manager 认为节点失联并将其状态置为 Unknown 。
可能原因 :
节点高负载导致无法上报
节点宕机
节点被关机
网络不通