LSTM神经网络算法
RNN
RNN 是包含循环的网络,允许信息的持久化。
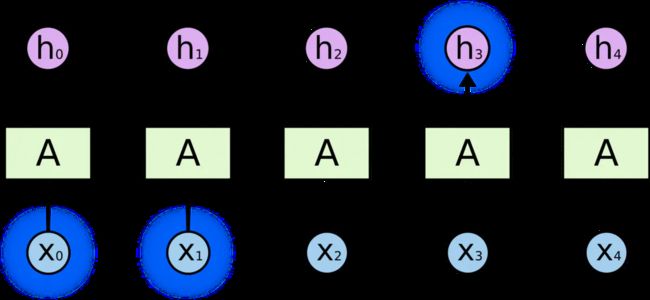
在下面的示例图中,神经网络的模块,A,正在读取某个输入 x_i,并输出一个值 h_i。循环可以使得信息可以从当前步传递到下一步。

RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开:

链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
而这些成功应用的关键之处就是 LSTM 的使用,这是一种特别的 RNN,比标准的 RNN 在很多的任务上都表现得更好。几乎所有的令人振奋的关于 RNN 的结果都是通过 LSTM 达到的。这篇博文也会就 LSTM 进行展开。
传统RNN的弊端
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。
如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。
例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
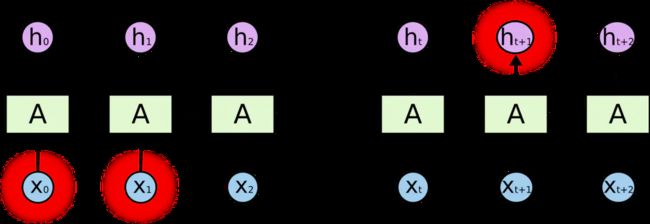
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
然而,幸运的是,LSTM 并没有这个问题!
LSTM
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
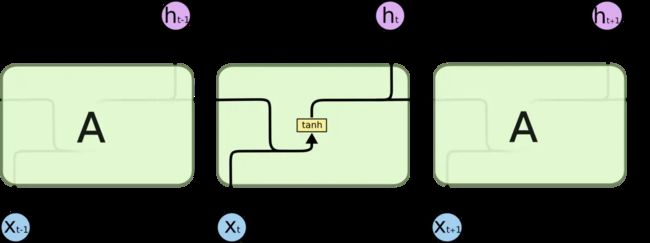
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
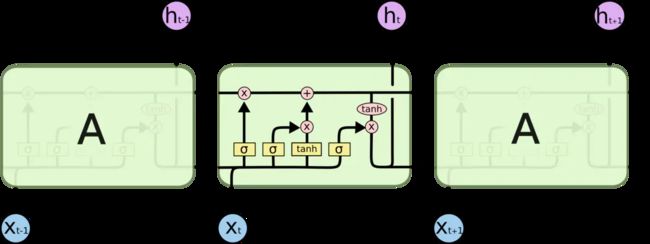
现在,我们先来熟悉一下图中使用的各种元素的图标。

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表按位 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
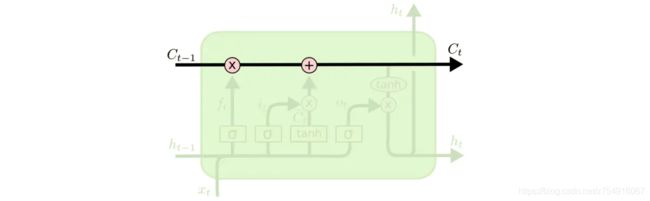
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个按位的乘法操作。
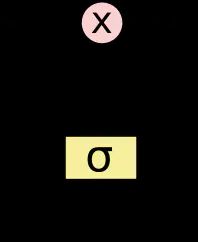
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解LSTM
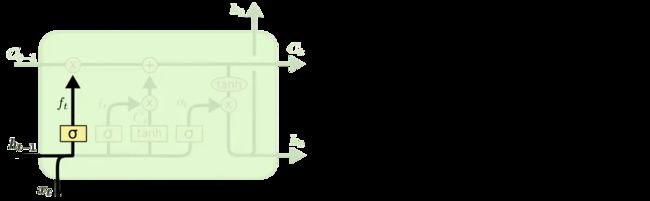
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取h(t-1)和 xt,输出一个在0到1之间的数值给每个在细胞状态c(t-1)中的数字。1表示“完全保留”,0表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
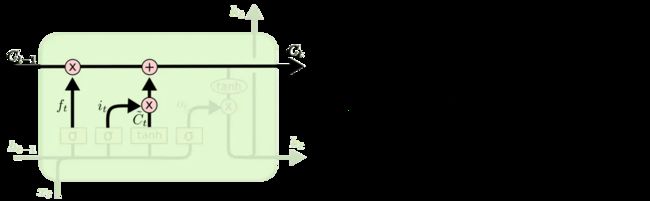
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,Ct,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

现在是更新旧细胞状态的时间了,C(t-1)更新为Ct。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与Ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*ct。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
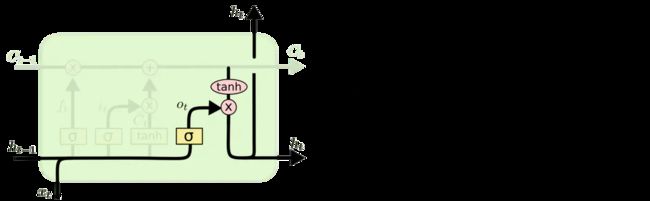
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在-1到1之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
讲得比较好的别网链接
https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/82922386
https://www.jianshu.com/p/9dc9f41f0b29