目标检测知识点
文章目录
- 目标检测知识点
-
- 坐标回归的损失函数
- 计算IOU
- 计算mAP
- NMS
- 为什么二阶段(two-stage)目标检测算法比一阶段(one-stage)目标检测算法精度高
- Focal Loss
- 介绍YOLO,并且解释一下YOLO为什么可以这么快?
- 介绍一下YOLOv3的原理?
- 介绍一下CenterNet的原理,它与传统的目标检测有什么不同点?
- CenterNet中heatmap(热力图)如何生成?
- 你知道哪些边缘端部署的方案?
- 你还了解当下哪些比较流行的目标检测算法?
- 了解哪些开源的移动端轻量型目标检测?
- 对于小目标检测,你有什么好的方案或者技巧?
- RPN
- yolov3为什么这么快?
- 目标检测中如何处理正负样本不平衡的问题?
- Fast RCNN中位置损失为何使用Smooth L1:
- Faster RCNN系列
-
- RCNN
- Fast RCNN
- Faster RCNN
- YOLOv1-v5
参考 https://mp.weixin.qq.com/s/1til8dzApyPnD2Tm9JZm8A
目标检测知识点
坐标回归的损失函数
计算IOU
import numpy as np
def get_IoU(pred_bbox, gt_bbox):
# https://github.com/amusi/Deep-Learning-Interview-Book/blob/master/docs/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89.md
# -----0---- get coordinates of inters
ixmin = max(pred_bbox[0], gt_bbox[0])
iymin = max(pred_bbox[1], gt_bbox[1])
ixmax = min(pred_bbox[2], gt_bbox[2])
iymax = min(pred_bbox[3], gt_bbox[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
# -----1----- intersection
inters = iw * ih
# -----2----- union, uni = S1 + S2 - inters
uni = ((pred_bbox[2] - pred_bbox[0] + 1.) * (pred_bbox[3] - pred_bbox[1] + 1.) +
(gt_bbox[2] - gt_bbox[0] + 1.) * (gt_bbox[3] - gt_bbox[1] + 1.) -
inters)
# -----3----- iou
overlaps = inters / uni
return overlaps
计算mAP
- 以voc数据集为例,我们的模型得到了一组预测结果,我们手头有一组真值。
- 我们去求解每个预测结果和每个真值的IOU,然后我们根据设定的IOU门限(一般是0.5)确定每个预测结果对应的真值标签。但这个时候的对应关系并不表示该预测目标预测正确与否,因为后边还要将每个预测结果的置信度考虑进来。
- 上边我们求出了每个预测结果对应的真值标签,然后我们就可以根据不同的置信度门限计算不同的recall和precision。超过置信度门限的预测结果,我们认为他是positive,然后看它对应的真值标签是0还是1。如果是1,那么这个预测结果就是TruePositive,否则就是FalsePositive。然后我们计算recall=TruePositive/标签为1的真值的个数;precision=TruePositive/所有检测结果为Positive的结果。其中所有检测结果为Positive的结果也就是置信度超过门限的个数。
- 对于每个置信度门限,我们都能计算出一对recall和precision。我们设置好多个门限,就可以得到一组recall和precision,然后就可以绘制PR(纵坐标是precision,横坐标是recall)曲线了。
- 根据PR曲线计算AP值。参考https://www.cnblogs.com/ywheunji/p/13376090.html
- https://blog.csdn.net/qq_43239026/article/details/107554637
- 给所有的类别的AP进行平均,就得到mAP。
计算AP的代码如下:
def voc_ap(rec, prec):
"""Compute VOC AP given precision and recall.
"""
#correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision 曲线值(也用了插值)
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
NMS
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个检测框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score置信度降序排序
order = scores.argsort()[::-1]
keep = [] #保留的结果框集合
while order.size > 0:
i = order[0]
keep.append(i) #保留该类剩余box中得分最高的一个
#得到相交区域,左上及右下
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积,不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算IoU:重叠面积 /(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留IoU小于阈值的box
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位
return keep
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
原文: https://www.cnblogs.com/makefile/p/nms.html © 康行天下
为什么二阶段(two-stage)目标检测算法比一阶段(one-stage)目标检测算法精度高
- 正负样本的不均衡性
这一点想必大家在做目标检测实验的时候深有体会,当某一类别的样本数特别多的时候,训练出来的网络对该类的检测精度往往会比较高。而当某一类的训练样本数较少的时候,模型对该类目标的检测精度就会有所下降,这就是所谓样本的不均衡性导致的检测精度的差异。
对于一阶段的目标检测来说,它既要做定位又要做分类,最后几层中1×1的卷积层的loss都混合在一起,没有明确的分工哪部分专门做分类,哪部分专门做预测框的回归,这样的话对于每个参数来说,学习的难度就增加了。
对于二阶段的目标检测来说(Faster RCNN),在RPN网络结构中进行了前景和背景的分类和检测,这个过程与一阶段的目标检测直接一上来就进行分类和检测要简单的很多,有了前景和背景的区分,就可以选择性的挑选样本,是的正负样本变得更加的均衡,然后重点对一些参数进行分类训练。训练的分类难度会比一阶段目标检测直接做混合分类和预测框回归要来的简单很多。 - 样本的不一致性
怎么理解样本不一致性呢?首先我们都知道在RPN获得多个anchors的时候,会使用一个NMS。在进行回归操作的时候,预测框和gt的IoU同回归后预测框和gt的IOU相比,一般会有较大的变化,但是NMS使用的时候用的是回归前的置信度,这样就会导致一些回归后高IoU的预测框被删除。这就使得回归前的置信度并不能完全表征回归后的IoU大小。这样子也会导致算法精度的下降。在第一次使用NMS时候这种情况会比较明显,第二次使用的时候就会好很多,因此一阶段只使用一次NMS是会对精度有影响的,而二阶段目标检测中会在RPN之后进行一个更为精细的回归,在该处也会用到NMS,此时检测的精度就会好很多。现在的一阶段目标检测的数据不平衡问题已经用focal loss解决了。
————————————————
版权声明:本文为CSDN博主「vodka、」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Vodka_Lou/article/details/115415365
Focal Loss
https://www.cnblogs.com/king-lps/p/9497836.html
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
介绍YOLO,并且解释一下YOLO为什么可以这么快?
yolo是单阶段检测算法的开山之作,最初的yolov1是在图像分类网络的基础上直接进行的改进,摒弃了二阶段检测算法中的RPN操作,直接对输入图像进行分类预测和回归,所以它相对于二阶段的目标检测算法而言,速度非常的快,但是精度会低很多;但是在迭代到目前的V4、V5版本后,yolo的精度已经可以媲美甚至超过二阶段的目标检测算法,同时保持着非常快的速度,是目前工业界内最受欢迎的算法之一。yolo的核心思想是将输入的图像经过backbone特征提取后,将的到的特征图划分为S x S的网格,物体的中心落在哪一个网格内,这个网格就负责预测该物体的置信度、类别以及坐标位置。
介绍一下YOLOv3的原理?
yolov3采用了作者自己设计的darknet53作为主干网络,darknet53借鉴了残差网络的思想,与resnet101、resnet152相比,在精度上差不多的同时,有着更快的速度,网络里使用了大量的残差跳层连接,并且抛弃了pooling池化操作,直接使用步长为2的卷积来实现下采样。在特征融合方面,为了加强小目标的检测,引入了类似与FPN的多尺度特征融合,特征图在经过上采样后与前面层的输出进行concat操作,浅层特征和深层特征的融合,使得yolov3在小目标的精度上有了很大的提升。yolov3的输出分为三个部分,首先是置信度、然后是坐标信息,最后是分类信息。在推理的时候,特征图会等分成S x S的网格,通过设置置信度阈值对格子进行筛选,如果某个格子上存在目标,那么这个格子就负责预测该物体的置信度、坐标和类别信息。
介绍一下CenterNet的原理,它与传统的目标检测有什么不同点?
CenterNet是属于anchor-free系列的目标检测算法的代表作之一,与它之前的目标算法相比,速度和精度都有不小的提高,尤其是和yolov3相比,在速度相同的情况下,CenterNet精度要比yolov3高好几个点。它的结构非常的简单,而且不需要太多了后处理,连NMS都省了,直接检测目标的中心点和大小,实现了真正的anchor-free。CenterNet论文中用到了三个主干网络:ResNet-18、DLA-34和Hourglass-104,实际应用中,也可以使用resnet-50等网络作为backbone;
CenterNet的算法流程是:一张512*512(1x3x512x512)的图片输入到网络中,经过backbone特征提取后得到下采样32倍后的特征图(1x2048x16x16),然后再经过三层反卷积模块上采样到128*128的尺寸,最后分别送入三个head分支进行预测:分别预测物体的类别、长宽尺寸和中心点偏置。其中推理的核心是从headmap中提取需要的bounding box,通过使用3*3的最大池化,检查当前热点的值是否比周围的8个临近点值都大,每个类别取100个这样的点,经过box后处理后再进行阈值筛选,得到最终的预测框。
CenterNet中heatmap(热力图)如何生成?
你知道哪些边缘端部署的方案?
nvidia GPU:pytorch->onnx->TensorRT
intel CPU:pytorch->onnx->openvino
移动端(手机、开发板等):pytorch->onnx->MNN、NCNN、TNN、TF-lite、Paddle-lite、RKNN等
你还了解当下哪些比较流行的目标检测算法?
目前比较流行的目标检测算法有以下几种类型,不局限于这几种:
- anchor-based:yolov3、yolov4、yolov5、pp-yolo、SSD、Faster-R-CNN、Cascade - R-CNN、EfficientDet,RetinaNet、MTCNN;
- anchor-free:CornerNet、CenterNet、CornerNet-lite、FCOS(FCOS: Fully Convolutional One-Stage Object Detection),;
- transform:DETR(DEtection TRansformer);
- mobile-detector:mobileNet-yolo、mobileNet-SSD、tiny-yolo、nanodet、yolo-fastest、YOLObile、mobilenet-retinaNet、MTCNN;
了解哪些开源的移动端轻量型目标检测?
轻量型的目标检测其实有很多,大多数都是基于yolo、SSD的改进,当然也有基于其他算法改的;比较常用的改进方法是使用轻量型的backbone替换原始的主干网络,例如mobilenet-ssd、mobilenet-yolov3、yolo-fastest、yolobile、yolo-nano、nanodet、tiny-yolo等等,在减少了计算量的同时保持着不错的精度,经过移动部署框架推理后,无论是在服务器还是移动端都有着不错的精度和速度。
对于小目标检测,你有什么好的方案或者技巧?
图像金字塔和多尺度滑动窗口检测(MTCNN)
多尺度特征融合检测(FPN、PAN、ASFF等)
增大训练、检测图像分辨率;
超分策略放大后检测;
RPN
https://www.cnblogs.com/Terrypython/p/10584384.html
https://blog.csdn.net/u011436429/article/details/80279536
yolov3为什么这么快?
yolov3和SSD比网络更加深了,虽然anchors比SSD少了许多,但是加深的网络深度明显会增加更多的计算量,那么为什么yolov3会比SSD快3倍?
SSD用的很老的VGG16,V3用的其最新原创的Darknet,darknet-53与resnet的网络结构,darknet-53会先用1x1的卷积核对feature降维,随后再利用3x3的卷积核升维,这个过程中,就会大大降低参数的计算量以及模型的大小,有点类似于低秩分解。究其原因是做了很多优化,比如用卷积替代替代全连接,1X1卷积减小计算量等。
目标检测中如何处理正负样本不平衡的问题?
https://zhuanlan.zhihu.com/p/60698060
Fast RCNN中位置损失为何使用Smooth L1:
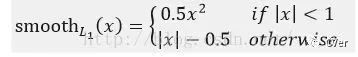
作者这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
Faster RCNN系列
https://blog.csdn.net/lanran2/article/details/54376126
https://mp.weixin.qq.com/s/b40PdGB7o95jmPMEIICBUQ
RCNN
区域卷积网络是卷积神经网络应用于目标检测的第一个里程碑式的飞跃。算法可以分为三步:候选区域选择;CNN特征提取;分类与边界回归。
- 候选区域选择:使用传统的区域提取方法,用的是选择搜索的方法(selective search)。即查看现有的小区域,然后合并两个最有可能的区域,重复此步骤,直到图像合并为一个区域,最后输出候选区域。然后将候选区域对应的目标图像进行归一化,作为CNN的输入。
- CNN特征提取
- 分类与边界回归:分类器有SVM,softmax等;边界回归有bbox损失,多任务损失函数边框回归等。
Fast RCNN
- 候选区域选择:与RCNN类似
- ROIpooling:不同于RCNN使用SVM进行特征提取,fast RCNN使用roipooling+MLP的策略。这使得模型在训练阶段不需要缓存很多的训练样本,提升了训练速度。ROIpooling的思想是,将不同大小的特征图分割为数量相等的子块,然后对这些子块进行最大池化。最后输出的特征图大小就等于子块的个数。这样就解决了输入特征图尺寸不同的问题。
- 分类与边界回归:使用全连接层进行分类和位置回归。这里使用smoothl1损失函数。
Faster RCNN
Faster RCNN相比与前者,使用了RPN结构,并且引入了anchor。
- RPN:对于骨干网得到的特征图,比如维度是256*10*10。256为通道数。首先使用滑动窗口对特征图进行处理,这里相当于对特征图进行卷积,如果使用3*3卷积核,stride=1,pad=1,那么滑动窗口以后得到的结果还是256*10*10,可以看作是100个256维的向量。然后对每个256维的向量做两次全连接操作,这里相当于对特征图再做一次1*1的卷积,得到2*10*10和4*10*10的特征图,分别表示前景和背景的置信度以及目标位置坐标。
- anchor:RPN得到10*10个结果,由于原图像和特征图的大小不一样,所以特征图的一个点可能对应原图像的一个框。我们不妨把框的左上角或者框的中心作为锚点(Anchor),然后想象k个框,k个框的大小比例各不相同。Faster RCNN中k=9。所以最后会得到10*10*k个结果。
- 坐标回归:锚框先验地提供了关于目标的位置信息。所以在回归位置坐标的时候,并是直接回归真实的位置坐标,而是回归到与真值长宽最接近的锚框的偏离值。这里有些绕。比如我们已经先验地给出了9种大小和比例各不相同的锚框,在回归坐标的时候,我们先判断真值和那个锚框最相似,然后去计算真值坐标与最相似的这个锚框的坐标的偏差值。然后网络进行回归的时候,只把这个偏差值作为回归目标。计算偏差值并不是简单做差,而是有一个公式,这里不详细铺开讲述。
- 先训练RPN,然后使用RPN产生推荐区域输入ROIooling,最后经过全连接层分别回归类别信息和位置信息。
YOLOv1-v5
https://blog.csdn.net/qq_38109843/article/details/89315185