操作系统--多线程进阶(上)
目录
- 前言
- 一丶常见的锁策略
-
- <1>乐观锁和悲观锁思想
-
- 1>乐观锁
- 2>悲观锁
- <2>重量级锁和轻量级锁
-
- 1>重量级锁
-
- 关于用户态切换到内核态的方式
- 2>轻量级锁
- <3>可重入锁和不可重入锁
- <4>非公平锁和公平锁
- <5>自旋锁
- 二丶CAS
-
- <1>jdk是如何实现CAS的?/CAS的原理是什么?
- <2>CAS存在的问题
-
- ABA问题
- CAS优化
- 三丶synchronized
-
- <1>加锁的工作过程
-
- 无锁
- 偏向锁
- 轻量级锁
- 重量级锁
- <2>加锁的作用原理
- <3>jvm对synchronize的优化方案
-
- 1>锁的消除
- 2>锁的粗化
- 三丶JUC包
-
- <1>Lock系统
- <2>关于Lock和synchronized的区别
- <3>关于Lock锁的种类
前言
这一部分就到了多线程进阶了,还是仔细点整理吧,细节还是挺多的,自己动手编程的地方好像机会就挺少。
一丶常见的锁策略
首先,我们为什么要加锁?
如果说一个数据被多个线程进行引用,并且这些线程并发执行的时候,我们需要保证这些线程之间执行操作互不影响,即一个线程操作不会对另外一个线程造成影响,那么这个时候我们就要对数据加锁,如果说一个线程要对数据进行操作,那么就需要获取锁。如果获取不了锁的话,那么就没有权限对锁进行操作。而锁大致可以分为乐观锁和悲观锁。
但是这里我们需要了解一下,在jdk1.6之前,只有重量级锁,但是我们也都知道,重量级锁依赖于底层操作系统的mutex指令,是特别消耗性能的,所以在jdk1.6之后,出现了偏向锁,轻量级锁。
所以其实锁的状态一共可以分为四种:无锁状态,偏向锁,轻量级锁,重量级锁。他们是一步步升级的。锁只能升级不能降级。
这里我们之后都会讲。所以这里先大致讲一下我们常见锁的类型,然后方便我们引出接下来的内容。
<1>乐观锁和悲观锁思想
1>乐观锁
所谓乐观锁,就是总是假设最好的情况,每次我去操作数据的时候,都认为别人不会修改这个数据,所以在提交数据进行更新的时候,才会正式对数据是否产生冲突进行检测,如果发现并发冲突了,就直接返回修改成功的结果,让用户去决定如何去做。(这里的乐观锁就是每次都不加锁)这里比较典型的就是CAS机制
2>悲观锁
所谓悲观锁,就是总是假设最坏的情况,即每次去拿数据的时候,总会认为别的线程会修改它,所以每次拿数据的时候都会进行上锁,这样别人想拿这个数据的时候就会阻塞,直到它拿到锁。Java中的synchronized和ReentrantLock等独占锁就是典型的独占锁思想。
<2>重量级锁和轻量级锁
锁的核心特性是什么呢?
原子性
这种机制可以一直追溯到CPU
<1>CPU提供了原子操作指令
<2>操作系统根据CPU提供的原子操作指令,实现了mutex互斥锁
<3>JVM根据操作系统提供的mutex互斥锁,实现了synchronized和ReentrantLock等关键字
和类
1>重量级锁
所谓重量级锁的机制依赖了底层操作系统提供的mutex指令
这意味着什么呢?
1.大量的内核态和用户态切换(我这里是不是应该提一下关于用户态切换到核心态的方式????)
2.很容易引发线程的调度
关于用户态切换到内核态的方式
这里既然提到了就说一说,主要的方式有三种
1.系统调用:也就是用户态进程主动要求切换到内核态的一种方式。用户态进程通过系统调用,
申请使用操作系统提供的服务程序来完成工作。
2.异常:如果说CPU在执行运行在用户态下的程序时,发生了某些事先不可预知的异常,会触发
由当前进程切换到处理此异常的内核态的相关程序当中,因此也就转到了内核态。这里如果说要
举一个例子的话:缺页异常
3.外围设备终端:外围设备完成用户请求的操作后,会向CPU发送相应的中断信号。此时,CPU会
暂停执行下一条即将要执行的指令,转而执行与中断信号对应的处理程序。如果当前执行的指令
是用户态的程序,那么转换的过程那是不是就是用户态到内核态的转换呢?
2>轻量级锁
加锁机制尽可能的不是用mutex,而是尽量在用户态代码完成,实在搞不定了,在使用mutex。
这意味着
少量的内核态用户态切换
不太容易引发线程调度
<3>可重入锁和不可重入锁
所谓的可重入锁就是“可以重新进入的锁”,即就是允许同一个线程多次获取同一把锁并且不会造成死锁。在JAVA中,只要是以Reentrant开头命名的锁都是可重入锁,而且JDK提供的所有现成的LOCK实现类,包括synchronized关键字锁都是可重入的。但是linux系统提供的mutex是不可重入锁。
<4>非公平锁和公平锁
非公平锁:不遵循先后顺序,所有的线程都有可能获取到锁,非公平锁效率更高
公平锁:遵循先后顺序,以锁的申请时间先后顺序来获取到锁
<5>自旋锁
这里的自旋锁虽然说是锁,但作为一种典型的轻量级锁的实现方式,实际上它也是JAVA层面的无锁操作。为什么叫做自旋锁呢?按之前的方式,线程在抢锁失败后进入阻塞状态,放弃 CPU,需要过很久才能再次被调度。但实际上, 大部分情况下,虽然当前抢锁失败,但过不了很久,锁就会被释放。没必要就放弃 CPU. 这个时候就可以使用自旋锁来处理这样的问题。如果获取锁失败, 立即再尝试获取锁, 无限循环, 直到获取到锁为止. 第一次获取锁失败, 第二次的尝试会在极短的时间内到来。
优点: 没有放弃 CPU 资源, 一旦锁被释放就能第一时间获取到锁, 更高效. 在锁持有时间比较短的场景下非常有用.
缺点: 如果锁的持有时间较长, 就会浪费 CPU 资源
二丶CAS
前面说了乐观锁和悲观锁,也说了他们对应的思想。这两种使用思想是特别广泛的,不仅仅是某种编程语言或者数据库什么的。
而乐观锁实现方式主要有两种:CAS机制和版本号机制。
那么什么是CAS呢?
CAS是英文单词 compare and swap的缩写,翻译过来的意思就是:比较并且交换。所以CAS需要有三个操作数:
<1>内存地址V
<2>旧的预期值A
<3>即将要更新的目标值B
那么CAS做了什么呢?
CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做。整个比较并替换的操作是一个原子操作。
<1>jdk是如何实现CAS的?/CAS的原理是什么?
首先在讲解之前,为了更好的理解CAS,我想用一个例子来进行说明,看如下代码:
public class 线程不安全 {
public static volatile int count = 0;
private static final int arr_length = 20;
public static void increase(){
count++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[arr_length];
for (int i = 0; i < arr_length; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 10000; j++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1){
Thread.yield();
}
System.out.println(count);
}
}
这里这段代码我们可以很轻易的知道,不论我们怎么运行,最后结果都是一个小于200000的整数

因为我们可以知道,volatile关键字只能保证可见性,但是它的操作不是原子性的,所以无法保证原子性。而自增操作也并不是一个原子性操作,所以就很难得到想要的结果。那么如果是在前面,那么我们怎么做呢?
public static synchronized void increase(){
count++;
}
没错,就是给increase()这个方法加锁,通过加锁操作让自增操作具有原子性。
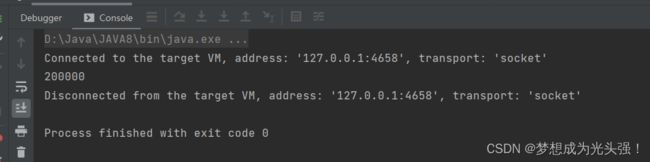
虽然这样是能够得到我们想要的结果,但是有没有想到一个问题?每一次自增操作都是一次加锁的过程,足足加了20万次,是不是很浪费资源呢?那么我们还可以怎么做呢?
这个时候我们就可以使用JAVA并发包原子操作类(Atomic)。
public static AtomicInteger t = new AtomicInteger(0);
public static void increase(){
t.getAndIncrement();
}
那么接下来寻根究底,我们可以看到getAndIncrement()方法其实调用的是AtomicInteger这个类下的getAndAddInt()这个方法

那么继续往下走,这个getAndAddInt()方法怎么实现的呢?

这个代码是什么意思呢?
就是它会拿到内存位置的最新值var5,然后使用CAS操作,尝试将这个内存位置的值修改为目标值var4+var5,如果修改失败就获取该内存位置的新值var5,然后继续尝试修改。
说道这里,没错,这次我们今天的主角就出现了。也就是unsafe这个类下的compareAndSwap()方法。那么接下来我们就探讨我们的CAS。也就是CAS它到底怎么实现的?
我们可以在源码中发现其实它在unsafe中调用的是Atomic::cmpxchg。而这个方法在linux和windows下的实现是不同的,所在这里我们就不深入探究这个命令的具体实现。
所以总结一下:
<1>java 的 CAS 利用的的是 unsafe 这个类提供的 CAS 操作;
<2>unsafe 的 CAS 依赖了的是 jvm 针对不同的操作系统实现的 Atomic::cmpxchg;
<3>Atomic::cmpxchg 的实现使用了汇编的 CAS 操作,并使用 cpu 硬件提供的 lock 机
制保证其原子性。
<2>CAS存在的问题
虽然CAS及其高效的解决了原子性这个问题,但是有几个它自身的问题需要我们去探讨。
1.循环时间长开销大
2.只能解决一个共享变量的原子操作
3.ABA问题
一个一个来
关于时间长这个问题,我们也前面说了,它是怎么实现的。如果这个getAndAddInt()这个方法执行失败的时候,它就会一直进行尝试。如果长时间失败,那么会带来很大的开销
这个从我们刚才的方法讲述也可以看到,如果仅仅是一个共享变量,那么我们的CAS可以很完美的去执行他们的任务,但是多个就不行了。这个时候循环CAS就无法保证原子性,就需要加锁来保证我们的原子性了。
关于这个ABA问题,我们就要单独拉出来说了。
ABA问题
CAS 的使用流程通常如下:1)首先从地址 V 读取值 A;2)根据 A 计算目标值 C;3)通过 CAS 以原子的方式将地址 V 中的值从 A 修改为 C。
但是这个时候是有问题的呀!就是在第一步从地址V中读取值为A并且在第三步成功修改的这中间,我们怎么知道地址V的值有没有被修改过呢?什么意思?
就是在第二步的时候,有其他线程把地址V中的A改成了B,然后又迅速地改回了A,这样我们第三步CAS操作还是正常执行。这就是我们的ABA问题。
那我们要怎么解决这个问题呢?
CAS优化
为了解决这个问题,我们可以引入一个版本号,也就是在比对地址的值的时候,再顺便比对一下版本号可以不可以对的上。也就是让每次修改操作的时候,地址的值的版本号+1。而在JAVA中的具体实现,就要引入一个叫AtomicStampedReference的类,它可以通过控制变量的版本来保证CAS的ABA问题。
三丶synchronized
(关于这一部分我就简略的说一下,因为应该就是这两天,关于这部分,我会单独拉出来写一篇博客好好的深入一下。这玩意太重要了,如果单独放在这里讲有点暴殄天物。而且篇幅确实有点不够。)
<1>加锁的工作过程
上面我们说了JVM将synchronized分为无锁,偏向锁,轻量级锁,重量级锁状态。根据情况会依次升级,而且锁只能升级不可以降级(实际上是可以降级的,这里我针对synchroniced的博客会提到)。
无锁
表示没有任何线程申请到该对象的锁
偏向锁
第一个尝试加锁的线程,优先进入偏向锁状态。
这里的偏向锁不是真的加锁,仅仅就是在对象头做一个标记,记录这个锁属于那个线程,如果后续没有其他线程来竞争该锁, 那么就不用进行其他同步操作了(避免了加锁解锁的开销)。如果后续有其他线程来竞争该锁(刚才已经在锁对象中记录了当前锁属于哪个线程了, 很容易识别当前申请锁的线程是不是之前记录的线程), 那就取消原来的偏向锁状态, 进入一般的轻量级锁状态。
轻量级锁
CAS + 自旋锁,此时出现了线程冲突(竞争),但是冲突概念比较小
随着其他线程进入竞争,偏向锁状态被消除,进入轻量锁状态(自适应的自旋锁),此时的轻量锁就是通过CAS来实现。
1.通过 CAS 检查并更新一块内存 (比如 null => 该线程引用)
2.如果更新成功, 则认为加锁成功
3.如果更新失败, 则认为锁被占用, 继续自旋式的等待(并不放弃 CPU).
注意了,这里的自旋操作不是一直持续进行的,而是达到一定的时间/重试次数之后,就不自旋了,不然就太浪费CPU资源了。
重量级锁
真实进行加锁,使用操作系统的mutex指令,冲突比较严重的时候就会从轻量级锁膨胀为重量
级锁。
具体过程如下:
1.执行加锁操作, 先进入内核态.
2.在内核态判定当前锁是否已经被占用
3.如果该锁没有占用, 则加锁成功, 并切换回用户态.
4.如果该锁被占用, 则加锁失败. 此时线程进入锁的等待队列, 挂起. 等待被操作系统唤醒.
5.经历了一系列的沧海桑田, 这个锁被其他线程释放了, 操作系统也想起了这个挂起的线程, 于是唤醒这个线程, 尝试重新获取锁.
<2>加锁的作用原理
synchronized加锁主要是基于对象头加锁,以此来实现线程之间的同步互斥。

根据上面我画的这个粗糙的图,简略的说一下加锁的原理。
synchronized的底层实现就两个:方法和代码块
什么意思呢?我用一段代码来说明一下
private static final Object lock = new Object();
public static void main(String[] args) {
// 锁作用于代码块
synchronized (lock) {
System.out.println("hello word");
}
}
// 锁作用于方法
public synchronized void test() {
System.out.println("test");
}
然后我们运行这段代码之后去查看对应的字节码文件

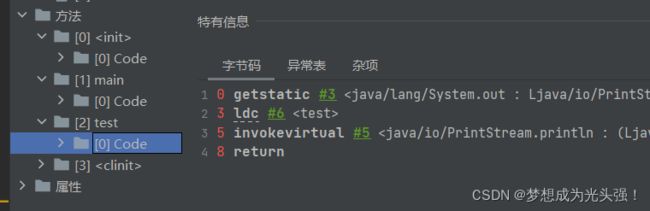
可以发现什么?synchronized修饰代码块的时候,在class编译后会生成monitorenter 和 monitorexit 指令,分别代表进入同步块和退出同步块,可以看到有两个monitorexit,为什么呢?我上面也说啦,一个synchronized底层实现就两个,方法和代码块。所以有两个monitorexit的愿意就是因为这里JVM给synchronized的代码块添加了一个隐形的try-catch,然后在finally中进行了锁释放。这也就是为啥我们的synchronized不需要手动释放锁的原因。
当然我们的monitor中,还保存了加锁的次数,如果说synchronized同一个线程重入申请这个对象锁,那么就次数加一,释放锁就次数减一,如果次数=0,那就真实的释放锁。当然这里知道了就行,不做过多的了解。
<3>jvm对synchronize的优化方案
1>锁的消除
什么意思呢?看如下代码:
StringBuffer sb = new StringBuffer();
sb.append("a");
sb.append("b");
sb.append("c");
sb.append("d");
可以看到,每一次append都是一次加锁的过程,append本身是线程安全的,但是多个append操作就可能不安全(因为可能会有其他线程并发的执行操作),但是当前只有一个线程在操作,其他线程看不到,就没有必要一直加锁解锁。那我们的JVM就可以进行优化:锁消除。
2>锁的粗化
就是说在一段代码中,如果多次出现加锁和解锁的过程,就可以进行锁的粗化。还是这段代码
StringBuffer sb = new StringBuffer();
sb.append("a");
sb.append("b");
sb.append("c");
sb.append("d");
如果说当前有多个线程都可以使用这个对象,但是当前线程连续的调用synchronized这个方法,那么我们就可以进行锁的粗化
加锁
拼接字符串a
拼接字符串b
拼接字符串c
拼接字符串c
释放锁
三丶JUC包
首先,什么是JUC包呢?JUC就是我们对于jdk中java.util .concurrent 工具包的简称,这个包下面的所有类,都是提供多线程并发编程用的,并且满足线程安全,效率也很高。
<1>Lock系统
首先我们需要知道synchronized的缺点。如果说一个代码块被synchronized修饰了,那么当一个线程获取了对应的锁,并且执行该代码块的时候,其他线程只能一直等待,等待获取锁的线程释放锁,如果这个时候出现了意外情况,也就是获取锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,其他线程便只能干巴巴地等待。这是不是很影响效率?这只是其中的一点,还有许多其他问题,比如说当多个线程就算都只是只读操作的时候,线程也会冲突…
那么这个时候我们就需要有一种更灵活的机制,来进行更灵活的操作,比如说我们的Lock。
那么我们都知道synchronized是一个关键字,是JAVA内置的语言实现,那么lock是什么呢?
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
没错,它是一个接口。当然lock系统不仅仅是用来加锁,还有线程通信等等的功能。
<2>关于Lock和synchronized的区别
1)Lock 是一个接口;synchronized 是 Java 中的关键字,synchronized 是内置的语言
实现;
2)Lock 在发生异常时,如果没有主动通过 unLock() 去释放锁,很可能会造成死锁现象,因
此使用 Lock 时需要在 finally 块中释放锁;synchronized 不需要手动获取锁和释放锁,
在发生异常时,会自动释放锁,因此不会导致死锁现象发生;
3)Lock 的使用更加灵活,可以有响应中断、有超时时间等;而 synchronized 却不行,使
用 synchronized 时,等待的线程会一直等待下去,直到获取到锁;
4)在性能上,随着近些年 synchronized 的不断优化,Lock 和 synchronized 在性能上
已经没有很明显的差距了,所以性能不应该成为我们选择两者的主要原因。
<3>关于Lock锁的种类
lock是一个悲观锁也是一个独占锁,其提供了公平锁和非公平锁

如果说没有参数,就是非公平锁,如果有参数,就是公平锁。
它还实现了可重入锁ReentrantLock
Lock() lock = new ReentrantLock();
try{
lock.lock();//锁的对象加锁,只能一个线程获取到锁
//需要保证线程安全的代码
}finally{
lock.unlock();//不论是否出现异常都要手动的去释放锁
}
还有我们的读写锁


对应实现代码如下:

在某些场景下,比如一个web项目,多个客户端对一个服务端文件进行操作,如果全部加一把锁就会导致互斥。所以为了提高效率我们就可以去分开写。毕竟读读是并发,但是读写和写写是互斥操作。