Task01:异常检测介绍
1、异常检测
异常检测(Outlier Detection)简述:检测出发生不符合预期以及不符合正常逻辑的数据。
1.1 异常检测分类
1.1.1 有监督学习
简介:有明确的特征值和目标结果值
举例:线性回归算法(房价预测,销售额预测,贷款额度预测),K近邻算法,决策树,朴素贝叶斯算法
概念:即通过已知历史学习到的经验与规律,我们只需要给定输入样本集,就可以从中推演出指定目标变量的可能结果
1.1.2 无监督学习
简介:即有特征值,无目标值
举例:常见聚类算法,PCA(主成分分析)
概念:即我们需要直接从样本中总结对应的规律,强调的是自我总觉归纳,目标值并不存在,从样本数据中直接发现有价值的东西
1.1.3 半监督学习
简介:有少部分有特征值与目标值的数据集,以及多数只有目标值和特征值的数据
举例: self-training(自训练算法),SVMs半监督支持向量机等等
概念:主要用于有目标值样本少,难以获取,无目标值数据相对容易获取,例如:在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的无目标值的数据却很容易得到
1.2 生活中的异常检测
下面是异常检测的一些应用场景:
- 工业检测:比如机器设备异常,生产材料用料不规范,网络异常,人为异常
- 欺诈检测:比如信用诈骗,电信诈骗,信用卡盗刷等
- 入侵检测:搞安全的都知道,黑客或者白帽子经常设法攻击一些公司或者个人的服务器或 PC 机(SQL 注入,社会工程学)
- 生态灾难预警:各种自然灾害,极端天气的预警
- 公共健康:禽流感,新冠疫情等传染类疾病的预警
- 制药领域:药物筛选的时候常常要确定试验结果是否正常。
- 反垃圾:但凡现在一个 App 用户有了一定的基数,立马成为各种黑产的目标,各种垃圾广告,垃圾邮件满天飞,让 App 的运营者不胜其扰,用户体验变的很差。
- 数据去噪:一些异常数据可能会导致数据的期望或者方差等严重偏离正常,利用异常检测方法检测出数据中的噪声通常是数据预处理中很重要的一步。
1.3 导致异常的原因
- 来自不同类的数据
一个个体不同于其他个体可能是因为他们的数据源不同,即来自不同的类型或者类别。比如一个盗刷别人的信用卡的用户,跟一个合法的信用卡用户属于两类人。一堆体检男性报告中夹杂着一份女性的体检报告,女性的这份报告的和其他男性报告的本来就是不同的性别。 - 自然变异
很多数据集都满足正态分布,正态分布中,的确会有极其个别样本偏离均值。比如姚明的身高就比一个普通人的身高高几十公分。 - 度量和采集造成的异常
好多数据都是靠仪器和人测量整理的,这难免会有纰漏,比如一个体重秤可能出问题了,那这个秤测量的数据就不靠谱了,或者测量员刚好心情不爽,记录测量数据的时候随便填了一个数。
2 异常检测常用的方法
异常检测的方法有很多,基于统计的方法,基于机器学习的方法,基于时间序列的方法等。所有这些方法都是基于一个异常点的稀有性或者与正常数据点的不一致性。异常点或者目标一般都比较稀有,即出现频率低。比如我们说一件事是“万里挑一”,说的就是稀有性。
2.1 基于统计学方法
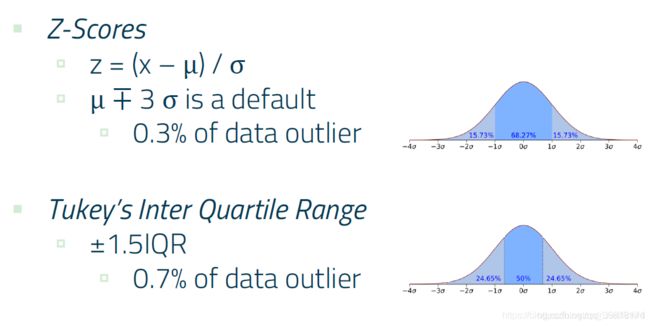
通常可以使用两种指标:Z分数 和 四分位距(IQR)。
Z分数:
计算一个样本的 z 分数,就是减去均值再除以标准差,如果绝对值大于三倍标准差,就认为这个样本异常,属于离群点。
对于正态分布的数据,用 Z 分数为指标,有千分之三的离群点。
四分位距(IQR):
用 IQR 为指标,判定的方式为:在四分位点上加上1.5倍IQR,这个范围之外的都是离群点,正态分布有千分之七的离群点。
两者简单介绍图:
简介图:
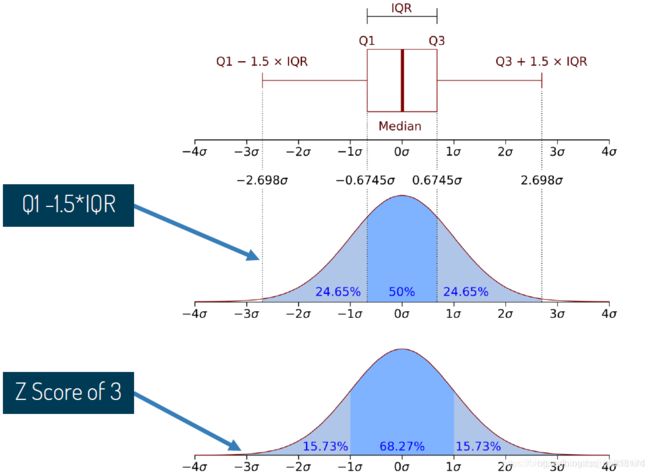
拉伊达(3 σ )准则剔除异常值

2.2 基于机器学习方法
例如:
有一堆训练资料{x1,x2,x3,…xN},要实现,输入一个x_test,此x_test与训练数值是相像的还是相向的

例如:


可使用统计学方法,以及一些常用算法进行异常检测,让机器学习进行有监督以及无监督学习。
2.3 基于时间序列
异常检测(Anomaly detection)是目前时序数据分析最成熟的应用之一,定义是从正常的时间序列中识别不正常的事件或行为的过程。有效的异常检测被广泛用于现实世界的很多领域,例如量化交易,网络安全检测、自动驾驶汽车和大型工业设备的日常维护。以在轨航天器为例,由于航天器昂贵且系统复杂,未能检测到危险可能会导致严重甚至无法弥补的损害。异常随时可能发展为严重故障,因此准确及时的异常检测可以提醒航天工程师今早采取措施。
一般而言很多异常可以通过人工的方式的来判断。然而当业务组合复杂,时序规模变大后,依靠传统的人工和简单的同比环比等绝对值算法来判断就捉襟见肘了。面对各种各样的工业级场景,系统的了解时间序列的异常检测方法显得尤为重要。
简介:给定一组时间序列X = xi ,异常时间序列 xi ∈ X 是在 X 上与大多数时间序列值不一致的部分。
3 异常检测常用开源库
3.1 Scikit-learn
概述:Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库 [1] 。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学图书馆NumPy和SciPy。
优势简介:
自2007年发布以来,scikit-learn已经成为最给力的Python机器学习库(library)了。scikit-learn支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块。作为Scipy库的扩展,scikit-learn也是建立在Python的NumPy和matplotlib库基础之上。NumPy可以让Python支持大量多维矩阵数据的高效操作,matplotlib提供了可视化工具,SciPy带有许多科学计算的模型。
scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。开发者用scikit-learn实验不同的算法,只要几行代码就可以搞定。scikit-learn包括许多知名的机器学习算法的实现,包括LIBSVM和LIBLINEAR。还封装了其他的Python库,如自然语言处理的NLTK库。另外,scikit-learn内置了大量数据集,允许开发者集中于算法设计,节省获取和整理数据集的时间。
3.2 PyOD
概述:PyOD提供了约20种异常检测算法,同时该工具库也包含了一系列辅助功能,包括数据可视化及结果评估等。
优势简介:
包括近20种常见的异常检测算法,比如经典的LOF/LOCI/ABOD以及最新的深度学习如对抗生成模型(GAN)和集成异常检测(outlier ensemble)
支持不同版本的Python:包括2.7和3.5+;支持多种操作系统:windows,macOS和Linux
简单易用且一致的API,只需要几行代码就可以完成异常检测,方便评估大量算法
使用JIT和并行化(parallelization)进行优化,加速算法运行及扩展性(scalability),可以处理大量数据
4 两种异常检测安装与学习
4.1 scikit-learn
安装命令:pip install scikit-learn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
简单例子:
字典特征抽取:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}])
print(dict.get_feature_names())
print(dict.inverse_transform(data))
print(data)
return None
if __name__ == "__main__":
dictvec()
4.2 PyOD
安装命令:pip install pyod -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
注意:目前 PyOD 不支持 Python3.9,目前测试 Python3.8 支持安装。
官方文档实例:
# -*- coding: utf-8 -*-
"""Example of using kNN for outlier detection
"""
# Author: Yue Zhao 5. Ending
Thank for all those who had helped me in the past。I will pray for them and wish their happiness。
Life Motto:Stay hungry, stay foolish。Cheer for freedom。