注意力机制——CAM、SAM、CBAM、SE
CAM、SAM、CBAM详见:CBAM——即插即用的注意力模块(附代码)
目录
1.什么是注意力机制?
2.通道注意力机制——SE
(1)Squeeze
(2)Excitation
(3)SE Block
3.CAM
4.SAM
5.CBAM
6.代码
参考
1.什么是注意力机制?
从数学角度看,注意力机制即提供一种权重模式进行运算。
神经网络中,注意力机制即利用一些网络层计算得到特征图对应的权重值,对特征图进行”注意力机制“。
2.通道注意力机制——SE
论文地址:论文
该论文于2018年发表于CVPR,是较早的将注意力机制引入卷积神经网络,并且该机制是一种即插即用的模块,可嵌入任意主流的卷积神经网络中,为卷积神经网络模型设计提供新思路——即插即用模块设计。
摘要核心:
- 背景介绍:卷积神经网络的核心是卷积操作,其通过局部感受野的方式融合空间和通道维度的特征;针对空间维度的特征提取方法已被广泛研究。
- 本文内容:本文针对通道维度进行研究,探索通道之间的关系,并提出SE Block,它可自适应的调整通道维度上的特征。
- 研究成果:SE Block可堆叠构成SENet,SENet在多个数据集上表现良好;SENet不仅可以大幅提升精度,同时仅需要增加少量的参数。
- 比赛成绩:ILSVRC 2017分类冠军,top-5 error低至2.251%,相对于2016冠军下降了~25%
- 代码开源
SE Block模型图如下所示:由两部分组成Squeeze和Excitation
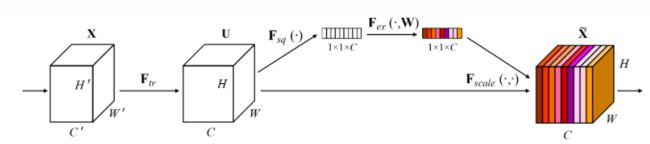
(1)Squeeze
Squeeze(Global Information Embedding):全局信息低维嵌入
Squeeze操作:采用全局池化,即压缩H和W至1*1,利用1个像素来表示一个通道,实现低维嵌入。压缩后的特征本质是一个向量,无空间维度,只有通道维度。
Squeeze计算公式:
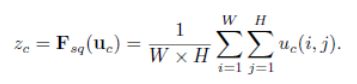
相对应模型的实现位置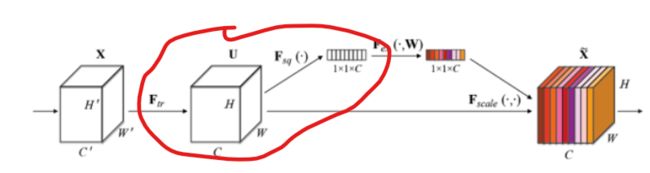
(2)Excitation
Excitation(Adaptative Recalibration):适应变换
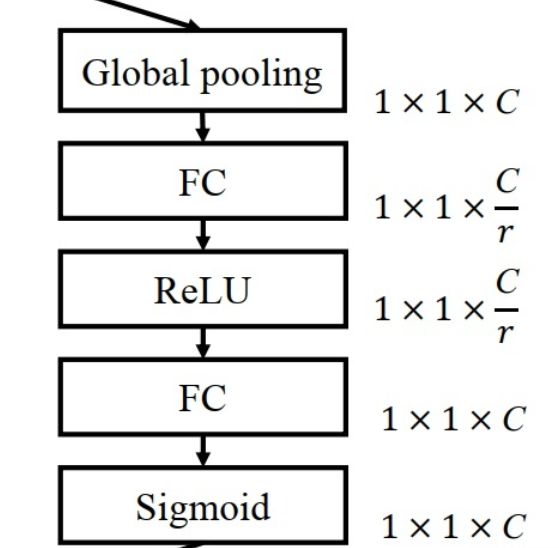
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
Excitation公式: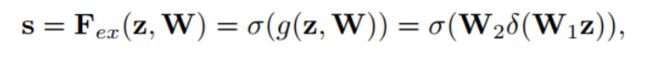
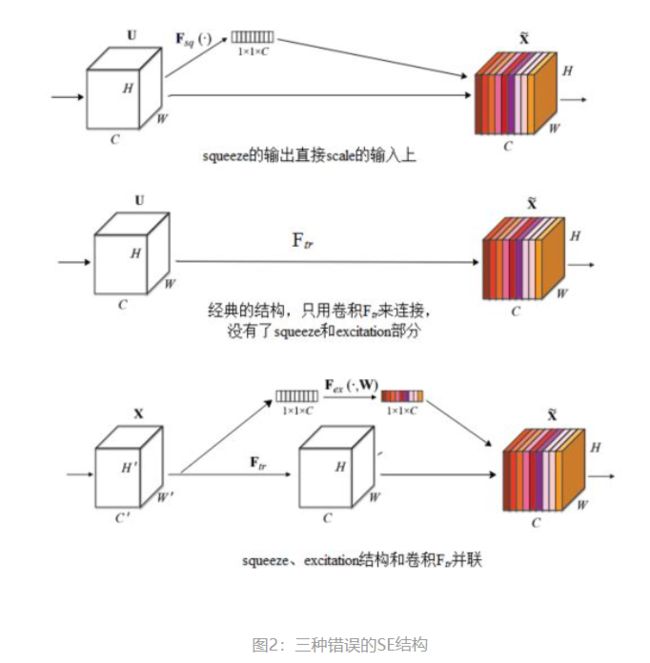
为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。可以拿SE Block和下面3种错误的结构比较来进一步理解:
图2最上方的结构,squeeze的输出直接scale到输入上,没有了全连接层,某个通道的调整值完全基于单个通道GAP的结果,事实上只有GAP的分支是完全没有反向计算、没有训练的过程的,就无法基于全部数据集来训练得出通道增强、减弱的规律。
图2中间是经典的卷积结构,有人会说卷积训练出的权值就含有了scale的成分在里面,也利用了通道间的相关性,为啥还要多个SE Block?那是因为这种卷积有空间的成分在里面,为了排除空间上的干扰就得先用GAP压缩成一个点后再作卷积,压缩后因为没有了Height、Width的成分,这种卷积就是全连接了。
图2最下面的结构,SE模块和传统的卷积间采用并联而不是串联的方式,这时SE利用的是Ftr输入X的相关性来计算scale,X和U的相关性是不同的,把根据X的相关性计算出的scale应用到U上明显不合适。
相对应模型的实现位置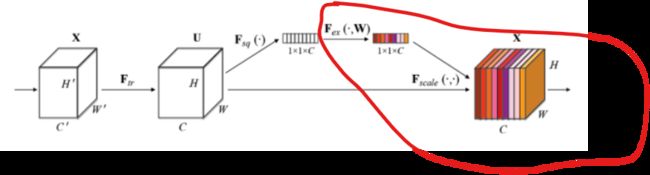
(3)SE Block
分开看完之后,再整合起来看就是如下图这样的操作过程。
- Squeeze:压缩特征图至向量形式
- Excitation:两个全连接对特征向量进行映射变换
- Scale:将得到的权重向量于通道的乘法
SE Block的嵌入方式:只“重构”特征图,不改变原来结构。
3.CAM

4.SAM

5.CBAM

6.代码
空间注意力模块
import torch
from torch import nn
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
if __name__ == '__main__':
SA = SpatialAttention(7)
data_in = torch.randn(8,32,300,300)
data_out = SA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
通道注意力模块
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
if __name__ == '__main__':
CA = ChannelAttention(32)
data_in = torch.randn(8,32,300,300)
data_out = CA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 1, 1])
CBAM注意力机制
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x)
result = out * self.sa(out)
return result
if __name__ == '__main__':
print('testing ChannelAttention'.center(100,'-'))
torch.manual_seed(seed=20200910)
CA = ChannelAttention(32)
data_in = torch.randn(8,32,300,300)
data_out = CA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 1, 1])
if __name__ == '__main__':
print('testing SpatialAttention'.center(100,'-'))
torch.manual_seed(seed=20200910)
SA = SpatialAttention(7)
data_in = torch.randn(8,32,300,300)
data_out = SA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
if __name__ == '__main__':
print('testing CBAM'.center(100,'-'))
torch.manual_seed(seed=20200910)
cbam = CBAM(32, 16, 7)
data_in = torch.randn(8,32,300,300)
data_out = cbam(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
SE注意力机制
from torch import nn
import torch
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
# return x * y
if __name__ == '__main__':
torch.manual_seed(seed=20200910)
data_in = torch.randn(8,32,300,300)
SE = SELayer(32)
data_out = SE(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 300, 300])
参考
注意力机制代码
论文
SENet