需要掌握的机器学习算法

目录
-
- 1. 机器学习算法简介
- 2. 通过学习风格分组的机器学习算法
- 3. 由功能的相似性分组的算法
- 4. 常用机器学习算法列表

- 5. 结论
1. 机器学习算法简介
有两种方法可以对你现在遇到的所有机器学习算法进行分类。
- 第一种算法分组是学习风格的。
- 第二种算法分组是通过形式或功能相似。
通常,这两种方法都能概括全部的算法。但是,我们将重点关注通过相似性对算法进行分组。
2. 通过学习风格分组的机器学习算法

算法可以通过不同的方式对问题进行建模,但是,无论我们想要什么结果都需要数据。此外,算法在机器学习和人工智能中很流行。让我们来看看机器学习算法中的三种不同学习方式:
监督学习
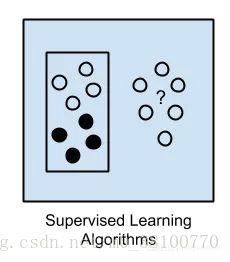
基本上,在监督机器学习中,输入数据被称为训练数据,并且具有已知的标签或结果,例如垃圾邮件/非垃圾邮件或股票价格。在此,通过训练过程中准备模型。此外,还需要做出预测。并且在这些预测错误时予以纠正。训练过程一直持续到模型达到所需水平。
示例问题:分类和回归。
示例算法:逻辑回归和反向传播神经网络。
无监督学习
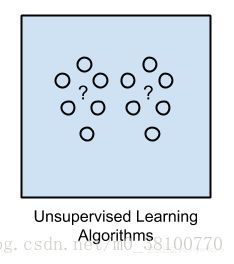
在无监督机器学习中,输入数据未标记且没有已知结果。我们必须通过推导输入数据中存在的结构来准备模型。这可能是提取一般规则,但是我们可以通过数学过程来减少冗余。
示例问题:聚类,降维和关联规则学习。
示例算法:Apriori算法和k-Means。
半监督学习

输入数据是标记和未标记示例的混合。存在期望的预测问题,但该模型必须学习组织数据以及进行预测的结构。
示例问题:分类和回归。
示例算法:其他灵活方法的扩展。
3. 由功能的相似性分组的算法
ML算法通常根据其功能的相似性进行分组。例如,基于树的方法以及神经网络的方法。但是,仍有算法可以轻松适应多个类别。如学习矢量量化,这是一个神经网络方法和基于实例的方法。
回归算法

回归算法涉及对变量之间的关系进行建模,我们在使用模型进行的预测中产生的错误度量来改进。
这些方法是数据统计的主力,此外,它们也已被选入统计机器学习。最流行的回归算法是:
普通最小二乘回归(OLSR);
线性回归;
Logistic回归;
逐步回归;
多元自适应回归样条(MARS);
局部估计的散点图平滑(LOESS);
基于实例的算法

该类算法是解决实例训练数据的决策问题。这些方法构建了示例数据的数据库,它需要将新数据与数据库进行比较。为了比较,我们使用相似性度量来找到最佳匹配并进行预测。出于这个原因,基于实例的方法也称为赢者通吃方法和基于记忆的学习,重点放在存储实例的表示上。因此,在实例之间使用相似性度量。最流行的基于实例的算法是:
k-最近邻(kNN);
学习矢量量化(LVQ);
自组织特征映射(SOM);
本地加权学习(LWL);
正则化算法
我在这里列出了正则化算法,因为它们很流行,功能强大。并且通常对其他方法进行简单的修改,最流行的正则化算法是:
岭回归;
最小绝对收缩和选择算子(LASSO);
弹性网回归;
最小角回归(LARS);
决策树算法

决策树方法用于构建决策模型,这是基于数据属性的实际值。决策在树结构中进行分叉,直到对给定记录做出预测决定。决策树通常快速准确,这也是机器学习从业者的最爱的算法。最流行的决策树算法是:
分类和回归树(CART);
迭代Dichotomiser 3(ID3);
C4.5和C5.0(强大方法的不同版本);
卡方自动交互检测(CHAID);
决策树桩;
M5;
条件决策树;
贝叶斯算法

这些方法适用于贝叶斯定理的问题,如分类和回归。最流行的贝叶斯算法是:
朴素贝叶斯;
高斯朴素贝叶斯;
多项朴素贝叶斯;
平均一依赖估计量(AODE);
贝叶斯信念网络(BBN);
贝叶斯网络(BN);
聚类算法

几乎所有的聚类算法都涉及使用数据中的固有结构,这需要将数据最佳地组织成最大共性的组。最流行的聚类算法是:
K-均值;
K-平均;
期望最大化(EM);
分层聚类;
关联规则学习算法

关联规则学习方法提取规则,它可以完美的解释数据中变量之间的关系。这些规则可以在大型多维数据集中被发现是非常重要的。最流行的关联规则学习算法是:
Apriori算法;
Eclat算法;
人工神经网络算法

这些算法模型大多受到生物神经网络结构的启发。它们可以是一类模式匹配,可以被用于回归和分类问题。它拥有一个巨大的子领域,因为它拥有数百种算法和变体。最流行的人工神经网络算法是:
感知机;
反向传播;
Hopfield神经网络;
径向基函数神经网络(RBFN)
深度学习算法

深度学习算法是人工神经网络的更新。他们更关心构建更大更复杂的神经网络。最流行的深度学习算法是:
深玻尔兹曼机(DBM);
深信仰网络(DBN);
卷积神经网络(CNN);
堆叠式自动编码器;
降维算法

与聚类方法一样,维数减少也是为了寻求数据的固有结构。通常,可视化维度数据是非常有用的。此外,我们可以在监督学习方法中使用它。
主成分分析(PCA);
主成分回归(PCR);
偏最小二乘回归(PLSR);
Sammon Mapping;
多维缩放(MDS);
投影追踪;
线性判别分析(LDA);
高斯混合判别分析(MDA);
二次判别分析(QDA);
费舍尔判别分析(FDA);
4. 常用机器学习算法列表

朴素贝叶斯分类器机器学习算法
通常,网页、文档和电子邮件进行分类将是困难且不可能的。这就是朴素贝叶斯分类器机器学习算法的用武之地。分类器其实是一个分配总体元素值的函数。例如,垃圾邮件过滤是朴素贝叶斯算法的一种流行应用。因此,垃圾邮件过滤器是一种分类器,可为所有电子邮件分配标签“垃圾邮件”或“非垃圾邮件”。基本上,它是按照相似性分组的最流行的学习方法之一。这适用于流行的贝叶斯概率定理。
K-means:聚类机器学习算法
通常,K-means是用于聚类分析的无监督机器学习算法。此外,K-Means是一种非确定性和迭代方法,该算法通过预定数量的簇k对给定数据集进行操作。因此,K-Means算法的输出是具有在簇之间分离的输入数据的k个簇。
支持向量机学习算法
基本上,它是用于分类或回归问题的监督机器学习算法。SVM从数据集学习,这样SVM就可以对任何新数据进行分类。此外,它的工作原理是通过查找将数据分类到不同的类中。我们用它来将训练数据集分成几类。而且,有许多这样的线性超平面,SVM试图最大化各种类之间的距离,这被称为边际最大化。
SVM分为两类:
- 线性SVM:在线性SVM中,训练数据必须通过超平面分离分类器。
- 非线性SVM:在非线性SVM中,不可能使用超平面分离训练数据。
Apriori机器学习算法
这是一种无监督的机器学习算法。我们用来从给定的数据集生成关联规则。关联规则意味着如果发生项目A,则项目B也以一定概率发生,生成的大多数关联规则都是IF_THEN格式。例如,如果人们购买iPad,那么他们也会购买iPad保护套来保护它。Apriori机器学习算法工作的基本原理:如果项目集频繁出现,则项目集的所有子集也经常出现。
线性回归机器学习算法
它显示了2个变量之间的关系,它显示了一个变量的变化如何影响另一个变量。
决策树机器学习算法
决策树是图形表示,它利用分支方法来举例说明决策的所有可能结果。在决策树中,内部节点表示对属性的测试。因为树的每个分支代表测试的结果,并且叶节点表示特定的类标签,即在计算所有属性后做出的决定。此外,我们必须通过从根节点到叶节点的路径来表示分类。
随机森林机器学习算法
它是首选的机器学习算法。我们使用套袋方法创建一堆具有随机数据子集的决策树。我们必须在数据集的随机样本上多次训练模型,因为我们需要从随机森林算法中获得良好的预测性能。此外,在这种集成学习方法中,我们必须组合所有决策树的输出,做出最后的预测。此外,我们通过轮询每个决策树的结果来推导出最终预测。
Logistic回归机器学习算法
这个算法的名称可能有点令人困惑,Logistic回归算法用于分类任务而不是回归问题。此外,这里的名称“回归”意味着线性模型适合于特征空间。该算法将逻辑函数应用于特征的线性组合,这需要预测分类因变量的结果。
5. 结论
我们研究了机器学习算法,并了解了机器学习算法的分类:回归算法、基于实例的算法、正则化算法、决策树算法、贝叶斯算法、聚类算法、关联规则学习算法、人工神经网络算法、深度学习算法、降维算法、集成算法、监督学习、无监督学习、半监督学习、朴素贝叶斯分类器算法、K-means聚类算法、支持向量机算法、Apriori算法、线性回归和Logistic回归。熟悉这类算法有助你成为机器学习领域的专家!
转自:云栖社区