目标检测学习笔记——yolov1-yolov4
一、 yolov1
1.损失函数


1 i j o b j 1_{ij}^{obj} 1ijobj和 1 i o b j 1_{i}^{obj} 1iobj是由gt确认的mask, 当gt中心落在这个grid cell时值为1
x,y:预测出的bbox的中心点坐标。
w,h:预测出的bbox的长与宽。
x ^ , y ^ \hat{x}, \hat{y} x^,y^:已标注bbox的中心点坐标。
w ^ , h ^ \hat{w}, \hat{h} w^,h^:已标注的bbox的长与宽。
根号w,根号h:减少大物体边框的影响。不然的话损失函数会被大物体所左右,这样只会学到大物体的信息。
s的平方:grid cell数
B每个grid cell负责预测的bbox数目
λ c o o r d λ_{coord} λcoord:可以取5,为了平衡“非物体”bbox过多的影响。比如一个77的特征图,每个cell预测两个bbox,那么会有98个小格(yolov1的每个cell预测两个bbox),可是真实物体只有三个。
λ n o b j λ_{nobj} λnobj:可以取0.5,为了平衡“非物体”bbox过多的影响。比如一个77的特征图,每个cell预测两个bbox,那么会有98个小格(yolov1的每个cell预测两个bbox),可是真实物体只有三个。
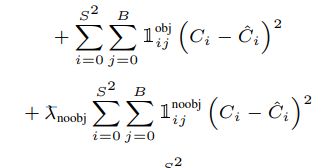
下面的式子是学习背景的,是必须要存在的,比如分类问题中,假如有n类物体,实际要分类的是n+1类物体,还有一类就是无处不在极其复杂的背景,所有学习的是n+1类物体的特征。如果只学习狗的特征,那么在实际预测中就会把那些很像狗但不是狗的物体识别成狗,所以除了学习真实物体,还要加入学习背景的信息。
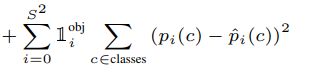
softmax的求导,softmax与CE结合,结合后的求导
2.优缺点
优点:one stage 确实快。
缺点:对拥挤物体检测不太好,因为每个cell只检测一个物体(物体中心落在这个cell的物体)。那么如果两个物体中心都落在这个cell的话就没法检测出两个物体。
对小物体检测不好。
对new width-height ratio物体不好
没有Batch Normalize
二、yolov3
改进之处: 相较于yolov2,改进了多尺度预测,损失函数,多标签分类
1.论文解读
1.1 损失函数:位置损失+置信度损失+类别损失
位置预测: 不像faster rcnn那样而是使用了相对于grid cell的相对位置,损失函数采用的还是误差平方和(回归)。

置信度预测: 使用逻辑回归进行置信度预测,如果一个anchor与某个gt的iou比其他anchor的大,那么这个值应该为1;如果一个anchor与某个anchor的iou比iou阈值大,但是它不是最大的,我们将它作为忽略样本,(代码中设值为-1,iou阈值通常为0.5);其他的anchor认为是负样本,值为0;与faster rcnn不同,yolov3只为每个gt分配一个anchor,如果一个anchor没有分配给一个gt,那么它不参与位置和类别的损失,仅作用于置信度损失。


类别预测: 因为softmax分类器默认目标只属于一类,yolov3没有使用softmax而是使用损失函数为二元交叉熵的逻辑分类,实现多标签分类。

2.2 多尺度预测
yolov3使用特征图为1313,2626,52*52的多尺度预测
3.训练过程
(1)网络head输出: 利用2层卷积操作输出我们想要尺寸的tensor,也是网络原始输出;
(2) anchor生成:利用设置的anchor(利用聚类算法,每个分支有3个共9组尺寸的anchor)生成整个特征图上所有的anchor,方便后续计算。
(3) gt box网格的分配: gt box按照中心落入那个网格,那个网格负责的原则提前分配好,方便后续计算。
(4) 正负样本分配: 将全部anchor根据和gt box的iou以及分配的网络,划分为正、负、忽略样本;
(5) 样本采样: 为了平衡正负样本,按照一定规则(例如随机采样)选择部分anchor进行后续loss计算,yolov3全部采样;
(6) gt box编码: 将gt box编码为网络输出的相同形式,方便直接计算loss;
(7) loss 计算:计算分类、confidence、矩形框位置和宽高的loss,并加权求和最终输出,供计算梯度和反向传播;
3.1 网络head输出
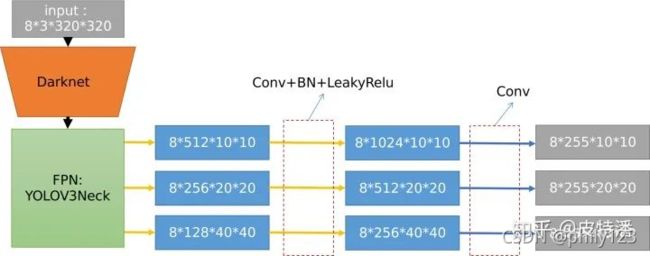
FPN输出的3个分支,通过两层卷积输出预测head。这里最终输出的形式为:batchSize X (5+类别总数) X 特征图宽X特征图宽。其中的5为预测的xywh和confidence。如下图,因为采用的是coco数据集,所以有80个类别,所以输出的tensor的channel输为255,这里假定batchSize为8,网络的输入为尺寸[8,3,320,320] 的tensor。
3.2 anchor生成
根据预先设定的anchor生成对应特征图的anchor
这里anchor的表达形式为左上点和右下点,既[x_0,y_0,x_1,y_1],核心代码如下:
base_anchor = torch.Tensor([
x_center - 0.5 * w, y_center - 0.5 * h, x_center + 0.5 * w, y_center + 0.5 * h]
这里的x_center和y_center为base(作为基)的grid cell的中心点坐标,即原图尺度的左上角第一个格子的中心坐标。例如在尺度为2020的特征图上,其x和y方向的stride均为320/20=16,因此x_center和y_center为[stride_x/2,stride_y/2]=[8,8](2020的特征图每一个grid cell对应原图的16)。最终获取的一层输出的base_anchors 尺度为34,其中3为anchor个数,4为中心坐标和宽高。然后再通过grid_anchors()方法将base_anchors扩充到整个特征图上,为了后续计算方便,对特征图的宽高w h拉成一个维度。最终得到的anchor_list是长度为8(batch size)的list,list中每一个元素是长度为3(输出层的个数)的list,内包含3个tensor,尺度分别为3004(3个anchor X 特征图宽10 X 特征图高10,下同),12004,48004。
3.3 gt box网格的分配
初步通过gt box生成对应特征图的mask,值为1或者0
正如前文所说,Yolo系列按照grid cell来分配样本。gt box的中心点落入哪一个grid cell,哪一个grid cell负责预测该gt box。通过对gt box的分配,最终获取和anchor_list外两层同样尺度的数据,内部tensor长度为特征图宽X特征图高X anchor数目,值为1代表该物体属于该anchor预测(不是真的需要它来负责,下面还会根据iou再次筛选,可以理解为候选anchor)。代码如下:
feat_h, feat_w = featmap_size
# 获取gt的中心位置
gt_bboxes_cx = ((gt_bboxes[:, 0] + gt_bboxes[:, 2]) * 0.5).to(device)
gt_bboxes_cy = ((gt_bboxes[:, 1] + gt_bboxes[:, 3]) * 0.5).to(device)
# 将gt的中心位置映射到特征图尺寸
gt_bboxes_grid_x = torch.floor(gt_bboxes_cx / stride[0]).long()
gt_bboxes_grid_y = torch.floor(gt_bboxes_cy / stride[1]).long()
# 将w和h方向拉成一个维度
gt_bboxes_grid_idx = gt_bboxes_grid_y * feat_w + gt_bboxes_grid_x
# 记录gt所在的grid的mask,存在gt的位置设置为1
responsible_grid = torch.zeros(
feat_h * feat_w, dtype=torch.uint8, device=device)
responsible_grid[gt_bboxes_grid_idx] = 1
# 将该mask推广到所有的anchor位置
responsible_grid = responsible_grid[:, None].expand(
responsible_grid.size(0), num_base_anchors).contiguous().view(-1)
return responsible_grid
3.4 正负样本分配
这里使用iou来确定正负样本和忽略样本
该部分做的是确定正负样本,是在anchor维度上的。也确定所有的anchor哪些是正样本,哪些是负样本。划分为正样本的anchor意味着负责gt box的预测,训练的时候就会计算gt box的loss。而负样本表明该anchor没有负责任何物体,当然也需要计算loss,但是只计算confidence loss,因为没有目标,所以无法计算box loss 和类别loss。
正样本: 负责预测gt box的anchor。loss计算box loss(包括中心点+宽高)+confidence loss + 类别loss。
负样本:不负责预测gt box的anchor。loss只计算confidence loss。
忽略样本:和gt box的iou大于一定阈值,但又不负责该gt box的anchor,一般指中心点grid cell附近的其他grid cell 里的anchor。不计算任何loss。
具体步骤:
第一步,将所有的assigned_gt_inds设置为-1,默认为忽略样本。
第二步,将所有iou小于一定值例如0.5(或者在一定区间的),设置为0,置为负样本。所有gt box和所有anchor计算iou,这里的boxes为anchor,是带有位置信息的。获取的overlaps 尺度为gt box个数*全部anchor个数(这里为300+1200+4800=6300)。
overlaps = self.iou_calculator(gt_bboxes, bboxes) # 获取全部iou,size为gt个数X6300
max_overlaps, argmax_overlaps = overlaps.max(dim=0) # 找和所有gtbox最大的iou,size为6300,也就是看看每一个anchor,和所有gt box最大的iou有无大过阈值
assigned_gt_inds[(max_overlaps >= 0) & (max_overlaps <= self.neg_iou_thr)] = 0 #如果小于阈值,例如0.5,设置为负样本,不负责任何gt的预测。
第三步,将全部iou中,非负责gt的(记录在box_responsible_flags,非中心点grid cell的anchor)置为-1,该步骤首先排除掉非中心点grid cell的anchor。因为排除掉的部分肯定不是正样本。
第四步,将gt box对应的grid cell 里面大于一定阈值的anchor设置为正样本,可能是多个anchor。遍历gt box,找到其最大的anchor,且在负责的grid cell中,设置为正样本。
#获取和哪一个gt最大的iou,size为6300,和上一步类似,不过获取的都是负责gt box的grid cell里的anchor
max_overlaps, argmax_overlaps = overlaps.max(dim=0)
# 获取的iou和一定阈值对比,例如0.5,大于该值,设置为正样本。
## 可见这一步是将gt box对应的grid cell 里面大于一定阈值的anchor设置为正样本,可能是多个anchor。
pos_inds = (max_overlaps > self.pos_iou_thr) & box_responsible_flags.type(torch.bool)
assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
#------------------------------------------------------------------------------------#
#------------------------------------------------------------------------------------#
#获取全部gt和哪一个anchor最大的iou,尺度为gt的数目,例如有2个gt,那么size就是2
gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
# 遍历gt box,找到其最大的anchor,且在负责的grid cell中,设置为正样本。
# 因为上一步,有些gt box并找不到iou大于阈值的anchor,这部分也是要预测的,所以退而求其次,找最大iou的anchor负责它,当然也是在gt box自己的grid cell里的anchor中寻找。
for i in range(num_gts):
if gt_max_overlaps[i] > self.min_pos_iou:
if self.gt_max_assign_all:
max_iou_inds = (overlaps[i, :] == gt_max_overlaps[i]) & \
box_responsible_flags.type(torch.bool)
assigned_gt_inds[max_iou_inds] = i + 1
总结:
(1)每个gt对应最大iou的bbox设为正样本呢,其他默认为负样本objectness=0;
(2)将负样本中iou大于阈值的(但不是最大的)设置为忽略样本objectness=0;
(3)负样本只参与置信度损失函数,忽略样本三种损失函数都不参与;
也就是每个gt最大iou的为正样本,objectness设置为1;与gt的iou大于iou阈值的但不是最大的设置为忽略样本呢,objectness设置为-1,不参与损失函数的计算;其余的小于iou阈值的设置为负样本,objectness设置为0,不参与位置和类别的计算。
参考链接
3.5 样本采样
在目标检测中,为了保证正负样本平衡,一般采用了采样设置。但通常情况下, Yolov3 所有的样本都有用到,所以采用默认的采样器PseudoSampler,不做任何的采样操作。只是把anchor和gt box 选出来(按照GridAssigner中的信息),这里不再叙述。
3.6 gt box编码
3.7 loss计算
所有的anchor全部计算出来并完成了分配,可以直接进行loss的计算了。经过前面的转化,这里遍历所有输出分支(3个)进行loss计算,如下:
# 在样本上计算分类
loss_cls = self.loss_cls(pred_label, target_label, weight=pos_mask)
# 在正+负样本上计算confidence
loss_conf = self.loss_conf(pred_conf, target_conf, weight=pos_and_neg_mask)
# 在正样本上计算中心点损失和宽高损失
loss_xy = self.loss_xy(pred_xy, target_xy, weight=pos_mask)
loss_wh = self.loss_wh(pred_wh, target_wh, weight=pos_mask)
2.预测过程
1.遍历全部batch中的输出tensor;
利用sigmoid操作将位置x,y预测拉到0到1之间,并利用decode操作获取预测的box;
2.利用sigmoid操作获取预测的confidence;
3.利用sigmoid操作获取预测的类别得分;
4.保留confidence大于一定阈值的部分,对剩下的box进行nms操作,删除重叠框,获取最终的box。
[mmdetection学习]结构最清晰的Yolov3 head和loss实现完全解析