SVM支持向量机-核函数python实现
参考链接:
https://blog.csdn.net/BIT_666/article/details/80012128
导入相关库
导入与我们数据处理有关的库并进行绘图的格式设置
import matplotlib as mpl
import matplotlib.pyplot as plt
from numpy import *
from time import sleep
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
查看数据集格式
filename = 'testSetRBF.txt'
fr = open(filename)
X1 = [];y1 = []
X2 = [];y2 = []
for line in fr.readlines():
lineArr = line.strip().split(',')
if float(lineArr[-1]) == 1:
X1.append(float(lineArr[0]))
y1.append(float(lineArr[1]))
elif float(lineArr[-1]) == -1:
X2.append(float(lineArr[0]))
y2.append(float(lineArr[1]))
# 使用matplotlib来绘制点图
plt.scatter(X1[:],y1[:],c='r',s=50)
plt.scatter(X2[:],y2[:],c='b',s=50)
plt.show()

定义数据读取
def loadDataSet(fileName):
'''
根据一定的格式来读取我们的数据
'''
# 数据
dataMat = []
# 标签
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split(',')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
随机选择J
selectJrand函数根据i,选择与i不同的角标作为另一个alpha的角标.
def selectJrand(i,m):
j=i #希望alpha的标号不同
while (j==i):
j = int(random.uniform(0,m))
return j
调整Alpha
根据不同的yi,调整alphaj的范围,使其在H和L之间.
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
转换核函数
使用五种核函数,在获取数据集的情况下,实现数据转核矩阵.一会针对上述数据集,我们可以看到对于这样线性不可分的数据集,采用lin线性核的效果将大打折扣,而高斯核,拉普拉斯核的效果比较满意.
def kernelTrans(X, A, kTup): #通过数据计算转换后的核函数
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': #线性核函数
K = X * A.T
elif kTup[0]=='rbf': #高斯核
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2))
elif kTup[0] == 'laplace': #拉普拉斯核
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K[j] = sqrt(K[j])
K = exp(-K/kTup[1])
elif kTup[0] == 'poly': #多项式核
K = X * A.T
for j in range(m):
K[j] = K[j]**kTup[1]
elif kTup[0] == 'sigmoid': #Sigmoid核
K = X * A.T
for j in range(m):
K[j] = tanh(kTup[1]*K[j]+kTup[2])
else:
raise NameError('执行过程出现问题 -- 核函数无法识别')
return K
数据结构
为了算法的一致性与简洁性,这里定义了数据结构,之后的函数调用都采用以上的数据结构,从而提高了效率.
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn # 训练数据
self.labelMat = classLabels # 训练类标
self.C = C # 常数
self.tol = toler # 容错率
self.m = shape(dataMatIn)[0] # 数据数目
self.alphas = mat(zeros((self.m,1))) # 初始化alpha为0
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m))) # 初始化核矩阵
# 核矩阵
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
计算误差E
这里根据公式E = f(xi) - yi ,负责计算误差E.
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
根据最大误差选取J
直观来看,KKT条件违背的程度越大,则更新变量更新后可能导致的目标函数增幅越大,所以SMO算法先选取违背KKT条件最大的变量,第二个变量的选择一个使目标函数值增长最快的变量。这里SMO采用了一种启发式,是选取的两个变量所对应的样本的间隔最大,一种直观的解释,这样的两个变量有很大的区别,与对两个相似变量更新相比,对他们更新会使目标函数值发生更大的变化.(参考西瓜书)
def selectJ(i, oS, Ei):
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
# print(validEcacheList)
if (len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i: continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
更新误差E
在alpha更新后,其相对应的误差E也基于更新的alpha重新计算.
def updateEk(oS, k):
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
SMO算法
SMO算法又称序列最小优化,是John Platt发布的的一种训练SVM的强大算法,SMO算法的思想是将大的优化问题转换为多个小优化问题,这些小的优化往往很容易求解,并且对他们进行顺序求解和作为整体求解的结果是完全一致的。SMO算法的目标是求出一些列alpha和b,一旦求出alpha,我们的超平面w的系数便得到,我们就可以利用超平面来进行分类了。SMO算法的思想是将大的优化问题转换为多个小优化问题,这些小的优化往往很容易求解,并且对他们进行顺序求解和作为整体求解的结果是完全一致的。SMO算法的目标是求出一些列alpha和b,一旦求出alpha,我们的超平面w的系数便得到,我们就可以利用超平面来进行分类了。
SMO算法的工作原理是每次循环中选择两个alpha进行优化,先选择一个αi,然后固定αi之外的其他参数,求αi上的极值,由于存在零和约束,所以修改αi时,我们也需要修改一个αj,所以我们选择两个变量αi,αj进行优化,并固定其他参数,在参数初始化后,SMO不断执行下列两个步骤直到收敛:
·选取一对需要更新的αi,αj
·固定αi,αj之外的参数,求解获得新的αi,αj
首先在不满足KKT条件的集合中选取αi,αj,其次SMO采取了一种启发式,使选取的两变量对应的间隔越大越好,直观的解释是,这两个变量有很大的差别,与对两个相似的变量进行更新对比,对他们更新会带给目标函数值更大的变化。
def innerL(i, oS, verbose=True):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H:
if verbose:
print("L==H")
return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j]
if eta >= 0:
if verbose:
print("eta>=0")
return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
if verbose:
print("j not moving enough")
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
updateEk(oS, i)
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2)/2.0
return 1
else:
return 0
核函数选择并计算参数alpha,b
根据输入的数据集,标签,松弛因子C,容忍度toler,最大迭代数与核函数参数,运行完整的SMO算法,直到更新达到一定条件(达到迭代最大次数,更新程度达到一定变化范围),停止迭代,返回参数alpha,b.
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('rbf', 1.3), verbose=True):
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS, verbose)
if verbose:
print ("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS, verbose)
if verbose:
print ("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
if verbose:
print ("iteration number: %d" % iter)
return oS.b,oS.alphas
计算系数W
通过上一个函数返回的alpha,b,通过拉格朗日法推出的w公式,计算w
def calculateW(alphas,dataArr,labelArr):
alphas, dataMat, labelMat = array(alphas), array(dataArr), array(labelArr)
sum = 0
for i in range(shape(dataMat)[0]):
sum += alphas[i]*labelMat[i]*dataMat[i].T
print(sum)
return sum
测试函数
这里选择参数sigma=2,rbf 高斯核函数对之前的线性不可分点进行分类,根据预测标签与真实标签的判别,计算分类的错误率.这里可以修改核函数参数,选择不同的核函数看看支持向量机的性能表现.
def testRbf(trainData, testData, kernel, k1=1.3, verbose=True):
'''
测试支持向量机性能
trainData: 训练数据文件
testData: 测试数据文件
'''
# 加载数据
dataArr, labelArr = loadDataSet(trainData)
# 得到参数alpha和b
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, (kernel, k1), verbose=verbose)
# 生成对应的数据矩阵
datMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd = nonzero(alphas.A>0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
print("there are %d Support Vectors" % shape(sVs)[0])
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],(kernel, k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m))
dataArr,labelArr = loadDataSet(testData)
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],(kernel, k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the test error rate is: %f" % (float(errorCount)/m))
标记支持向量
通过KKT条件,寻找alpha大于0的alpha作为支持向量,然后将对应点标记.
def plot_point(filename,alphas,dataMat):
filename = filename
fr = open(filename)
X1 = [];y1 = []
X2 = [];y2 = []
for line in fr.readlines():
lineArr = line.strip().split(',')
if float(lineArr[-1]) == 1:
X1.append(float(lineArr[0]))
y1.append(float(lineArr[1]))
elif float(lineArr[-1]) == -1:
X2.append(float(lineArr[0]))
y2.append(float(lineArr[1]))
plt.scatter(X1[:],y1[:],c='y',s=50)
plt.scatter(X2[:],y2[:],c='b',s=50)
for i, alpha in enumerate(alphas):
if abs(alpha) > 0:
x, y = dataMat[i]
#plt.scatter(x, y, s=100, c = '', alpha=0.5, linewidth=1.5, edgecolor='red')
plt.scatter(x, y, s=100, alpha=0.5, linewidth=1.5, edgecolor='red')
plt.show()
主函数
第一行读取数据,第二行根据参数计算alpha,b,第三行计算错误率,第四行标记支撑向量,最后一行计算W.
rbf高斯核,k=1.3
import time
if __name__ == "__main__":
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40, verbose=False)
start = time.time()
testRbf(trainData='testSetRBF.txt', testData='testSetRBF2.txt', kernel='rbf', verbose=False)
end = time.time()
print('time cost:',end-start,'s')
plot_point('testSetRBF.txt',alphas,dataArr)
calculateW(alphas,dataArr,labelArr)
there are 20 Support Vectors
the training error rate is: 0.050000
the test error rate is: 0.040000
time cost: 0.3361325263977051 s
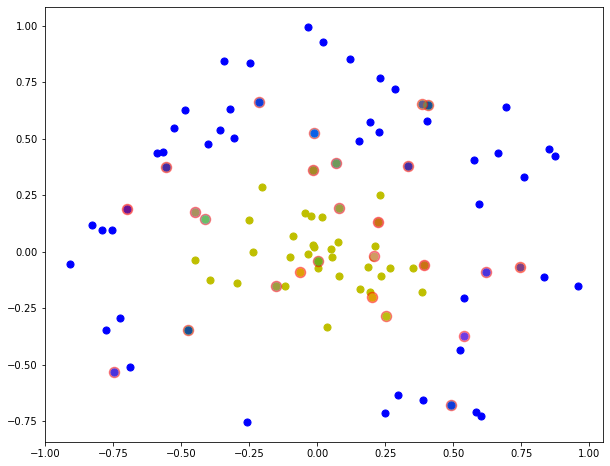
[-0.2837046 -0.4820352]
lapalace拉普拉斯核,k=1.3
if __name__ == "__main__":
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40, kTup=('laplace', 1.3), verbose=False)
start = time.time()
testRbf(trainData='testSetRBF.txt', testData='testSetRBF2.txt', kernel='laplace', verbose=False)
end = time.time()
print('time cost:',end-start,'s')
plot_point('testSetRBF.txt',alphas,dataArr)
calculateW(alphas,dataArr,labelArr)
there are 30 Support Vectors
the training error rate is: 0.000000
the test error rate is: 0.060000
time cost: 0.47074198722839355 s

[-0.436887 -0.9289236]
linear核
if __name__ == "__main__":
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr,labelArr,0.6,0.001,40,kTup=('lin',1.3), verbose=False)
start = time.time()
testRbf(trainData='testSetRBF.txt', testData='testSetRBF2.txt', kernel='lin', verbose=False)
end = time.time()
print('time cost:',end-start,'s')
plot_point('testSetRBF.txt',alphas,dataArr)
calculateW(alphas,dataArr,labelArr)
there are 65 Support Vectors
the training error rate is: 0.380000
the test error rate is: 0.420000
time cost: 1.2347300052642822 s
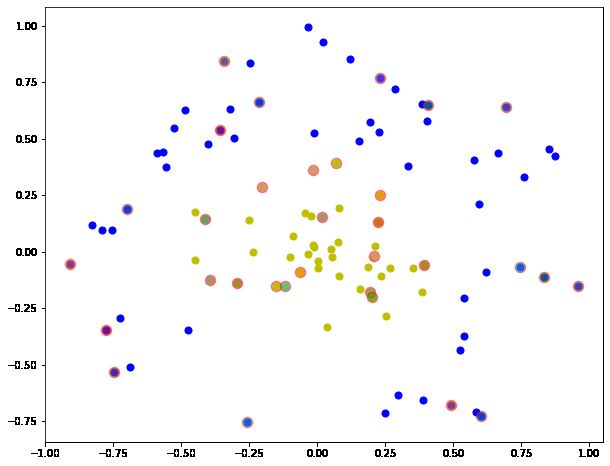
[-0.4637016 -0.160638 ]