美团在Redis上踩过的一些坑-1.客户端周期性出现connect timeout
1. 背景:
大部分互联网公司都会有Mysql或者Oracle的DBA,但是在Nosql方面一般不会设置专门的DBA。不过对于一些知名的互联网公司来说,Nosql的使用量是巨大的,所以通常让Mysql的DBA或者单独聘请工程师来维护一些Nosql数据库,比如:
Redis, Hbase, Memcache(其实严格讲不是nosql), Mongodb, Cassandra。从讲座看美团网应该是有专职的Redis DBA。所以作为业务开发人员不需要自己安装、配置、运维Redis,只需要找Redis DBA来申请就可以了。
这里为了简化说明:Redis DBA提供的服务叫做Redis云,业务开发人员叫做业务端(redis的使用者)
2. 现象:
业务端在使用redis云提供的redis服务后,经常出现connect timeout:
Java代码
![]()
- redis.clients.jedis.exceptions.JedisConnectionException
- java.net.SocketException
- java.net.SocketTimeoutException:connect time out
3. 分析和怀疑:
业务端一般认为redis出现问题,就是redis云有问题,人的“正常”思维:看别人错误容易,发现自己难,扯多了, 出现这个有很多原因:
(1). 网络原因:比如是否存在跨机房、网络割接等等。
(2). 慢查询,因为redis是单线程,如果有慢查询的话,会阻塞住之后的操作。
(3). value值过大?比如value几十兆,当然这种情况比较少,其实也可以看做是慢查询的一种
(4). aof重写/rdb fork发生?瞬间会堵一下Redis服务器。
(5). 其他..................
4. 查询原因
演讲者一开始怀疑是网络问题,但是并未发现问题,观察各种对比图表,tcp listenOverFlow和timeout经常周期出现。(赞一下这个监控,我们监控现在还没有这个层面的)
有关listenOverFlow:
查看现有的连接数是否大于设置的backlog,如果大于就丢弃,并相应的参数值加1。其中backlog是由程序和系统参数net.core.somaxconn共同设置,当backlog的值大于系统设置的net.core.somaxconn时则取net.core.somaxconn的值,否则取程序设置的backlog值。这种出错的方式也被记录在TcpListenOverflows中(其只记录了连接个数不足而产生溢出错误的次数!)。
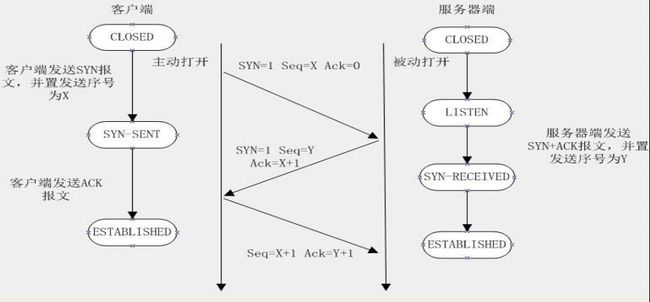
觉得可能和TCP相关,于是分析了Tcp三次握手:最后一次握手客户端的请求会进入服务器端的一个队列(可以认为是下三图)中,如果这个队列满了,就会发生上面的异常。(accept)
(1) TCP三次握手:
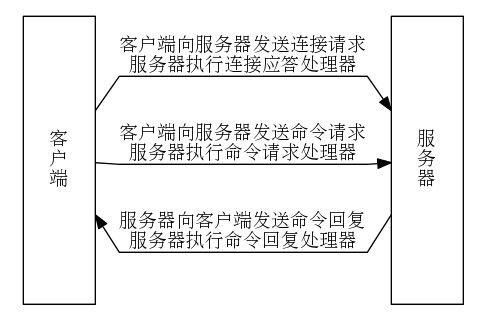
(2) redis客户端与redis服务器交互的过程(本质就是TCP请求)
(3) I/O 多路复用程序通过队列向文件事件分派器传送套接字的过程

(4) 和redis有什么关系呢?
由于Redis的单线程模型(对命令的处理和连接的处理都是在一个线程中),如果存在慢查询的话,会出现上面的这种情况,造成新的accept的连接进不了队列。
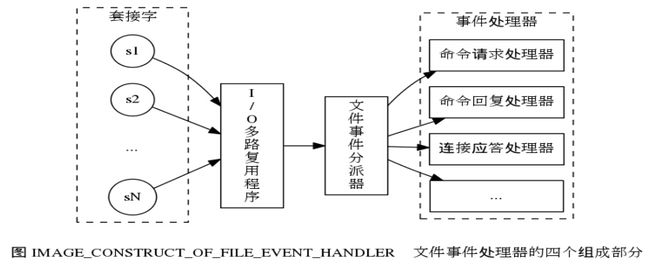
如果上面的图没法理解的话,看看这张图:

5. 解决方法:
(1) 对慢查询进行持久化,比如定时存放到mysql之类。(redis的慢查询只是一个list,超过list设置的最大值,会清除掉之前的数据,也就是看不到历史)
(2) 对慢查询进行报警(频率、数量、时间)等等因素
(3) 打屁股,哈哈:
(4) 其实应该做的是:对业务端进行培训,告诉他们一下redis开发的坑,redis不是万金油,这个和Mysql DBA要培训Mysql使用者一样,否则防不胜防。
比如他执行了 monitor, keys *, flushall, drop table, update table set a=1; 这种也是防不胜防的( 当然也可以做限制,利用rename-command一个随机数),但是提高工程师的水平才是关键。