Kubernetes进阶部分学习笔记
K8S 进阶部分
-
- 1. Deployment 部署
-
- 1.1 自愈能力
- 1.2 多副本
- 1.3 扩容、缩容
- 1.4 滚动更新
- 1.5 版本回退
- 1.6 工作负载
- 2. Service 网络
-
- 2.1 ClusterIP 模式
- 2.2 NodePort 模式
- 3. Ingress 网关
-
- 3.1 安装
- 3.2 实战
-
- 3.2.1 apply一个yaml文件
- 3.2.2 解析yaml为架构图
- 3.2.3 域名访问
- 3.3 Ingress的高级功能
-
- 3.3.1 路径重写
- 3.3.2 流量限制
- 4. 存储抽象
-
- 4.1 环境准备
- 4.2 PV 和 PVC
-
- 4.2.1 创建 PV 池
- 4.2.2 PVC 创建与绑定
- 4.3 配置 ConfigMap(推荐)
-
- 4.3.1 配置文件准备
- 4.3.2 yaml文件创建Pod
- 4.3.3 进入容器查看效果
- 4.3.4 图解
- 4.4 Secret
- 5. 总结
-
- 5.1 工作负载
- 5.2 服务
- 5.3 配置和存储
1. Deployment 部署
1.1 自愈能力
强大的自愈能力
# 1、先删除之前的pod
[root@cluster-master /]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp 2/2 Running 3 3d9h
[root@cluster-master /]# kubectl delete pod myapp
pod "myapp" deleted
# 2、创建一个Pod
kubectl create deployment mytomcat --image=tomcat:9.0
[root@cluster-master /]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytomcat-77bcdc77bf-kd6qm 1/1 Running 0 2m38s
测试delete掉这个pod:
左边的是使用watch -n 1 kubectl get pod 一秒自动执行一次这个命令,我们发现,我们欲删除的这个这个后缀为kd6qm的mytomcat,确实是被删掉了,但Deployment又帮我们重新启动了一个,后缀不同的pod。强大的自愈能力。

如果我们真想删除这个Pod,其实是要把这个Deployment删除
[root@cluster-master /]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
mytomcat 1/1 1 1 11m
[root@cluster-master /]# kubectl delete deploy mytomcat
deployment.apps "mytomcat" deleted
[root@cluster-master /]# kubectl get pod
No resources found in default namespace.
1.2 多副本
通过Deployment创建五个tdengine副本(因为我在学TDengine)
1、键入kubectl create deployment my-deptd01 --image=tdengine/tdengine --replicas=5
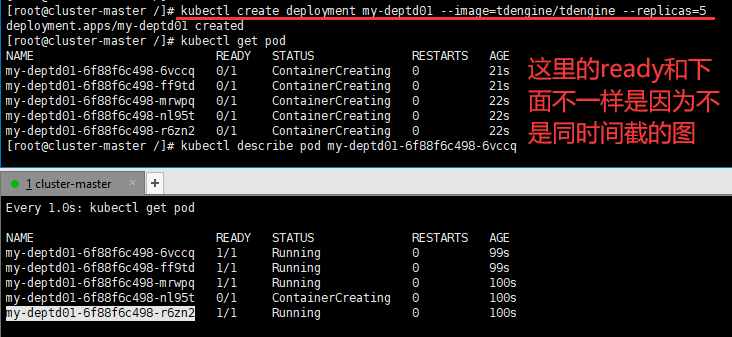
2、键入kubectl get pod -owide可以查看各个节点上assigned的任务

3、当node2节点宕机,deployemnt会自动的在其它节点再启动对应的个数服务,又是极好的自愈能力。故障转移。
当一个节点宕机,K8S不会立即重新在新的节点部署,会有一个阈值,监测五分钟或者多久没有脸上,就认定为下线。
4、reboot和shutdown都测试了,只展示shutdown的,reboot的很容易理解
- 看到node2在集群里已经不是ready了
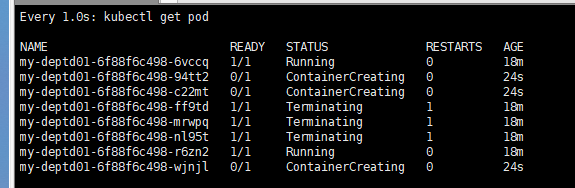
- 同时,deployemnt在其他节点创建新的pod

- 查看到已经都OK了,宕机的三个几点都在node1上重新创建了。

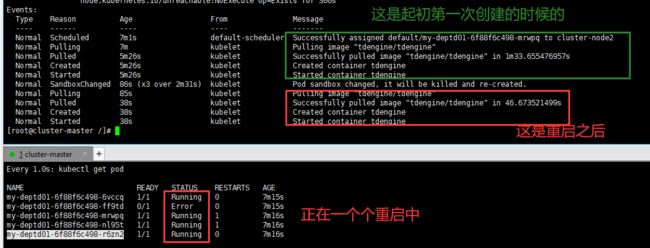
下面这个展示的是reboot的效果图
1.3 扩容、缩容
# 扩缩容
kubectl scale deploy/my-deptd01 --replicas=6
kubectl scale deploy/my-deptd01 --replicas=2
# yaml方式实现
kubectl edit deploy my-deptd01 # 会给我们展示yaml文件,找replicas进行修改来实现
# 可视化的也比较简单
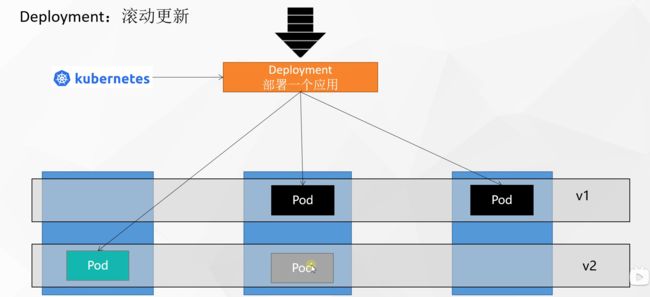
1.4 滚动更新
图解:
需要更新为V2版本,但是不可以停机,会一直有流量进来,先启动一个V2的Pod,把流量接到V2上,这个Pod接受之后,再把V1的对应的Pod下掉(具体是删除还是隐藏?因为后面还要回滚)
“启动一个杀一个”

命令实现:
# 版本更新
kubectl set image deploy/my-dep01 nginx=nginx:1.16.1 --record
# 我们可以通过两种方式来查看这个滚动更新的状态
kubectl get pod -w
watch -n 1 kubectl get pod
1.5 版本回退
# 查看过去的版本
kubectl rollout history deploy/my-dep01
#查看某个历史详情
kubectl rollout history deploy/my-dep01 --revision=2
#回滚(回到上次)
kubectl rollout undo deploy/my-dep01
#回滚(回到指定版本)
kubectl rollout undo deploy/my-dep01 --to-revision=2
1.6 工作负载
官网介绍工作负载资源
Deployment:无状态应用部署,比如微服务、提供多副本。
StateFulSet:有状态应用部署,比如数据库之类的,redis、mysql。可以固定IP,可以保证一个Pod宕掉,重启之后还是之前的IP地址,提供稳定的存储、网络等功能。
DaemonSet:守护型应用部署,比如日志收集组件,每一个机器都只能运行一份。
Job/CronJob:定时任务部署,比如垃圾清理组件,可以在指定的时间运行,比如每晚两点清理垃圾。
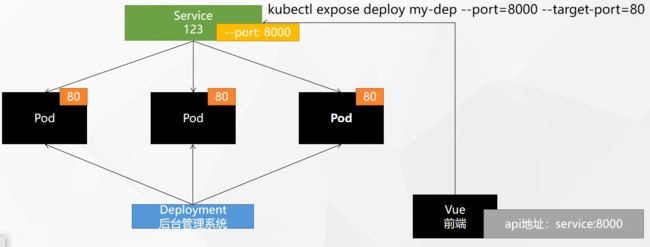
2. Service 网络
问题和需求:
我们创建启动了三个nginx副本,三个Pod,有各自的IP,当我们前端部署的时候,需要配置一个API的地址,只能配置一个IP地址,但是,如果我们配置的这个IP地址所在的Pod宕机了,我们是不是还要去修改这个API地址,很麻烦。
为此我们使用Serivce,它可以配置某次Deployment部署的一个总IP,对外暴露一个IP,将一组Pod公开。
图解:

2.1 ClusterIP 模式
命令:
# 针对我们这个deploy,我们对外暴露8000端口,对应源Pod的80端口
[root@cluster-master ~]# kubectl expose deploy my-dep01 --port=8000 --target-port=80
service/my-dep01 exposed
[root@cluster-master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d14h
my-dep01 ClusterIP 10.96.32.173 <none> 8000/TCP 8s # 暴露的8000端口
[root@cluster-master ~]# curl 10.96.32.173:8000
# 这样子,访问到这个IP,Service会自动分配到这三个Pod,自动实现负载均衡。
# 这个IP集群内部可以任意使用
yaml方式:
# 我们查看一下创建这个service的yaml文件
[root@cluster-master ~]# kubectl edit service my-dep01
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service # 类型是service
metadata:
creationTimestamp: "2022-07-23T09:23:55Z"
labels:
app: my-dep01
name: my-dep01 # 这个service的名字
namespace: default
resourceVersion: "77046"
uid: 0dc7adf5-ebd2-4355-8fb1-cb04f5e00605
spec:
clusterIP: 10.96.32.173 # 这个service暴露的统一Pod的IP
clusterIPs:
- 10.96.32.173
ports:
- port: 8000 # 对外暴露的端口
protocol: TCP
targetPort: 80 # 源Pod的端口
selector:
app: my-dep01 # 对应的是我们选择的哪一个deploy ,这很重要,我们每次通过deployment创建一个Pod都会有个标签,记录是哪一个deployment创建的Pod
sessionAffinity: None
type: ClusterIP # 集群内部可访问
status:
loadBalancer: {}
# 针对上面的selector里的app是哪里来的,下面做了解释
[root@cluster-master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-dep01-75c8465dbd-4h75m 1/1 Running 0 25m app=my-dep01,pod-template-hash=75c8465dbd
my-dep01-75c8465dbd-b58zm 1/1 Running 0 24m app=my-dep01,pod-template-hash=75c8465dbd
my-dep01-75c8465dbd-jpksr 1/1 Running 0 25m app=my-dep01,pod-template-hash=75c8465dbd
my-dep01-75c8465dbd-rnk2k 1/1 Running 0 24m app=my-dep01,pod-template-hash=75c8465dbd
# 除了IP访问的方式,我们还可以通过域名来访问(服务名.命名空间.svc)
root@my-tomcat-5987455b6b-8q4kx:/usr/local/tomcat# curl my-dep01.default.svc:8000
<head>
<title>Welcome to nginx!</title>
</head>
<h1>Welcome to nginx!</h1>
-------- 略 -----------
# 注意:这个方式只能在其他的Pod里面进行访问,而不能在宿主机节点访问。(--type=CLusterIp)
# 回顾:我们之前在基础部分创建dashboard的时候,就是把type: ClusterIP 改为 type: NodePort,之后就可以在公网下访问了
2.2 NodePort 模式
默认的暴露service方式是ClusterIP,只有集群内部可以访问。
我们使用NodePort方式,可以让集群外部也可以访问。
# 在暴露的时候使用这种方式
kubectl expose deploy my-dep01 --port=8000 --target-port=80 --type=NodePort
# 或者把之前的ClusterIP换成NodePort
[root@cluster-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d14h
my-dep01 ClusterIP 10.96.32.173 <none> 8000/TCP 35m
[root@cluster-master ~]# kubectl edit svc my-dep01
service/my-dep01 edited
[root@cluster-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d14h
my-dep01 NodePort 10.96.32.173 <none> 8000:32135/TCP 36m
# 可以看到,不仅有一个8000端口,是我们自己写的,还有一个32135端口,这个是K8S给我们配置的,每一个Pod都一样,随机生成的这个范围是 30000-32767
测试访问:
# 测试ClusterIP(集群内部访问)
[root@cluster-master ~]# curl 10.96.32.173:8000
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
# 测试公网IP访问(集群外部访问)
C:\Users\whirl\Desktop>curl 192.76.116.202:32135
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
PS:
我们注意到这些用于集群内部访问的IP都是10.96.0.0/16的,这是我们之前在初始化主节点的时候配置的**–service-cidr**=10.96.0.0/16 \
同时,这些Pod的网络都是192.168.0.0/16 这也是初始化主节点的时候配置的**–pod-network-cidr**=192.168.0.0/16
3. Ingress 网关
Ingress是Service的统一网关入口,Service是Pod的统一入口。
通常,会有很多个服务,service A、 service B、service C,他们都在同一层,用的IP就是10.96.0.0/16下面的子网,K8S统一管理,由ingress来决定不同的访问路径调用不同的服务,底层是一个nginx。
3.1 安装
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
# 修改镜像
vi deploy.yaml
# 将image的值改为如下值:(这是尚硅谷雷丰阳老师阿里云仓库里的ingress地址)
registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0
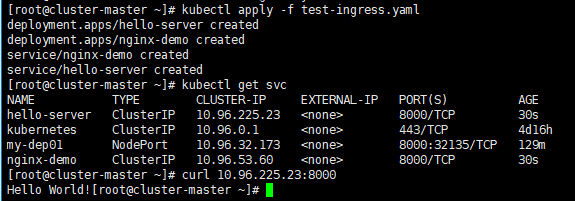
[root@cluster-master ~]# kubectl apply -f deploy.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
configmap/ingress-nginx-controller created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
service/ingress-nginx-controller-admission created
service/ingress-nginx-controller created
deployment.apps/ingress-nginx-controller created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
serviceaccount/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
# 检查安装的结果
[root@cluster-master ~]# kubectl get pod,svc -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-b96tw 0/1 ContainerCreating 0 15s
pod/ingress-nginx-admission-patch-9725j 0/1 CrashLoopBackOff 1 15s
pod/ingress-nginx-controller-65bf56f7fc-ggndz 0/1 ContainerCreating 0 15s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller NodePort 10.96.39.227 <none> 80:30278/TCP,443:32006/TCP 15s
service/ingress-nginx-controller-admission ClusterIP 10.96.62.203 <none> 443/TCP 15s
# 最后别忘记把svc暴露的端口要放行
测试集群外部访问 Success:
问题:yaml文件下不下来?
解决:
# 排查一下创建过程发生了什么
[root@cluster-master ~]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-b96tw 0/1 Completed 0 8m50s
ingress-nginx-admission-patch-9725j 0/1 Completed 2 8m50s
ingress-nginx-controller-65bf56f7fc-ggndz 1/1 Running 0 8m50s
# 查看Event事件
kubectl describe pod ingress-nginx-controller-65bf56f7fc-ggndz -n ingress-nginx
# 如果那个镜像说pull 失败了,就自己去docker pull
自己也可以去更改镜像源,因为官方没有上传到Docker-hub,注意版本的对应关系
解决国内k8s的ingress-nginx镜像无法正常pull拉取问题_文杰@的博客-CSDN博客

3.2 实战
3.2.1 apply一个yaml文件
(学习一下Deployment配置的格式)
apiVersion: apps/v1
kind: Deployment # 来一个deployment
metadata:
name: hello-server
spec:
replicas: 2 # 两个副本
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server
ports:
- containerPort: 9000
---
apiVersion: apps/v1
kind: Deployment # 来一个deployment
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
replicas: 2 # 两个副本
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: v1
kind: Service # 来一个service服务
metadata:
labels:
app: nginx-demo
name: nginx-demo # 服务的名字
spec:
selector:
app: nginx-demo
ports:
- port: 8000
protocol: TCP
targetPort: 80
---
apiVersion: v1
kind: Service # 配置服务
metadata:
labels:
app: hello-server
name: hello-server # 服务的名字
spec:
selector:
app: hello-server
ports:
- port: 8000
protocol: TCP
targetPort: 9000
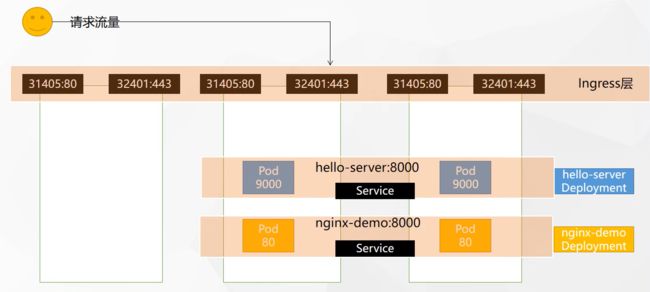
3.2.2 解析yaml为架构图
展示刚才的部署效果:
3.2.3 域名访问
apiVersion: networking.k8s.io/v1
kind: Ingress # 配置了一个转发的类型
metadata:
name: ingress-host-bar # 不重名即可
spec:
ingressClassName: nginx
rules:
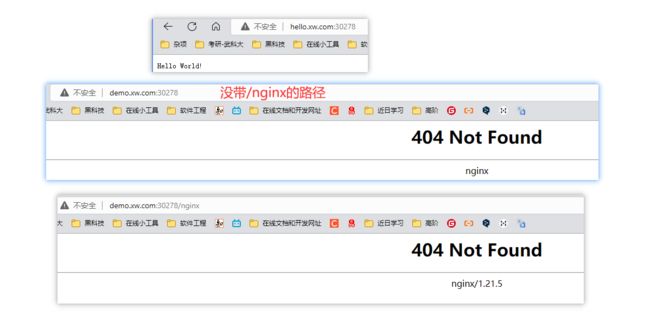
- host: "hello.xw.com" # 多个rule多个这样的 - host
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server # 指定给哪个service来完成
port:
number: 8000
- host: "demo.xw.com"
http:
paths:
- pathType: Prefix
path: "/nginx" # 把请求会转给下面的服务,下面的服务一定要能够处理这个路径,不然就是404
backend:
service:
name: nginx-demo # 指定给哪个service来完成
port:
number: 8000
需要进入任意一个nginx的Pod里面,然后写入文件,命名就是nginx(上面path里面的目录名称),不然就是404
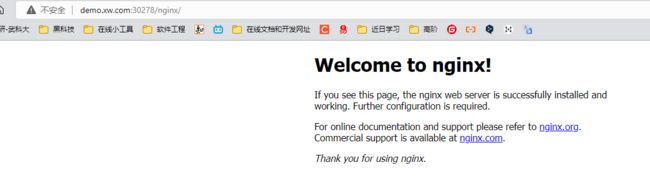
测试访问:
# 查看端口
[root@cluster-master ~]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.39.227 <none> 80:30278/TCP,443:32006/TCP 42m
ingress-nginx-controller-admission ClusterIP 10.96.62.203 <none> 443/TCP 42m
# 配置的是30278端口
# 接着我们在我们的Windows配置hosts映射
192.76.116.201 hello.xw.com demo.xw.com
以下两个是ingress官网给的高级功能,加注解Annotations。
3.3 Ingress的高级功能
3.3.1 路径重写
刚才的配置demo.xw.com修改一下
主要是在metadata里面加了一个annotations,然后在path进行了修改
apiVersion: networking.k8s.io/v1
kind: Ingress # 配置了一个转发的类型
metadata:
name: ingress-host-bar # 不重名即可
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations: # 高级部分,加注解
nginx.ingress.kubernetes.io/rewrite-target: /$2 # 你要重写的部分
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.xw.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "demo.xw.com"
http:
paths:
- pathType: Prefix
path: "/nginx(/|$)(.*)" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo # java,比如使用路径重写,去掉前缀nginx
port:
number: 8000
进入任意一个nginx容器,输入nginx文件echo xiaowei > nginx
虽然输入的是/nginx,但是ingress自动给我们截掉了,就是相当于/了,这样转发到其他的Pod的时候,就是直接访问它们的根路径了。就会显示这个起始欢迎页面。

3.3.2 流量限制
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-limit-rate # 这个ingress的名称
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1" # 限制访问频率
spec:
ingressClassName: nginx
rules:
- host: "hh.xw.com" # 这里新的host,记得需要在Windows的hosts里面加一个哈
http:
paths:
- pathType: Exact #精确匹配,只有haha.xw.com的才会被限制,haha.xw.com:30278/sad都不会被限制
path: "/"
backend:
service:
name: nginx-demo
port:
number: 8000
如果浏览器访问频率过快:
4. 存储抽象
之前,我们在Docker里面,文件挂载到宿主机上,但在K8S里面的话,挂载是挂载到当前的node里面,然后如果这个node节点宕机,那么由于K8S的故障转移能力,会自动的在其他node节点创建一个Pod,这个时候,会新起一个挂载的目录,这个目录是不包含之前宕掉的节点的目录里面的数据的。
所以有了新的方法,存储系统,可以选择很多种方式来存储,K8S是开放的,我们这里使用**NFS(网络文件系统)**来完成这个存储的任务,也可以选择其他的方式。
4.1 环境准备
大致步骤:安装工具,配置目录,主节点是服务节点,其他节点去同步这个主节点的数据
# 在所有节点安装
yum install -y nfs-utils
# 在主节点暴露一个nfs的目录
mkdir -p /nfs/data
# *表示目录下的所有文件,然后括号里的是可以让同步的目录也可以执行rw的操作
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
systemctl enable rpcbind --now
systemctl enable nfs-server --now
# 使配置生效
exportfs -r
# 在从节点展示目标IP下可供同步的目录
[root@cluster-node1 ~]# showmount -e 192.76.116.201
Export list for 192.76.116.201:
/nfs/data *
# 同样的,创建目录,然后将服务器上的目录共享到本机
mkdir -p /nfs/data
mount -t nfs 192.76.116.201:/nfs/data /nfs/data
测试环境 Success:
# 在主节点
echo "hello nfs server" > /nfs/data/test.txt
# 在从节点查看
[root@cluster-node1 ~]# cd /nfs/data/
[root@cluster-node1 data]# ls
test.txt
[root@cluster-node1 data]# cat test.txt
hello nfs server
原生方式挂载:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 192.76.116.201
path: /nfs/data/nginx-pv
测试访问 Success:

PS:存在一个问题:
如果我们把这次部署deploy删掉了,但是数据挂载的目录并不会被删除,时间长了之后,会有很多的垃圾文件。怎么办呢?为此我们引入PV和PVC
4.2 PV 和 PVC
PV:Persistent Vloume 持久卷,将应用需要持久化的数据保存到指定位置
PVC:Persistent Volume Claim 持久卷声明,声明需要使用的持久卷规格
4.2.1 创建 PV 池
我们这里使用的是静态供应,后面还要学习动态供应。
# 先在主节点的/nfs/data下创建三个目录备用
mkdir 01 02 03
创建我们需要的 PV:
apiVersion: v1
kind: PersistentVolume # 创建持久卷
metadata:
name: pv01-10m
spec:
capacity:
storage: 10m # 静态创建10M的空间
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/01 # 挂载的目录
server: 192.76.116.201
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1g # g要小写
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 192.76.116.201
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3g
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03
server: 192.76.116.201
创建成功:
[root@cluster-master ~]# kubectl apply -f deploy-pv.yaml
persistentvolume/pv01-10m unchanged
persistentvolume/pv02-1gi created
persistentvolume/pv03-3gi created
[root@cluster-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10m RWX Retain Available nfs 5m10s
pv02-1gi 8M RWX Retain Available nfs 54s
pv03-3gi 5M RWX Retain Available nfs 54s
# 可以看到目前都是“可用”的状态
# 注意在你申请的时候,首先要确保你当前的节点的空间足够,我虚拟机报错空间不足了,
创建好PV池了,我们怎么使用呢?
4.2.2 PVC 创建与绑定
我们尝试创建一个Pod并配置它的文件挂载点
先创建PVC,写一个声明,然后创建Pod的时候用这个声明就可以了
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-pvc # 注意这里的名字,以后需要使用这个PVC的时候,就写这个名字
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5M
storageClassName: nfs
应用结果:
[root@cluster-master ~]# vim dep-pvc.yaml
[root@cluster-master ~]# kubectl apply -f dep-pvc.yaml
persistentvolumeclaim/nginx-pvc created
[root@cluster-master ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-pvc Bound pv03-3gi 5M RWX nfs 5s
[root@cluster-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10m RWX Retain Available nfs 25m
pv02-1gi 8M RWX Retain Available nfs 21m
pv03-3gi 5M RWX Retain Bound default/nginx-pvc nfs 21m
# 已经是Bound的状态了
创建Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc
name: nginx-deploy-pvc
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim: # 这里是持久卷声明
claimName: nginx-pvc # 这里是创建PVC的时候定义的名字
测试访问 Success:
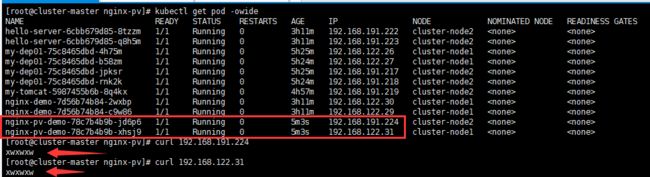
这是挂载的数据文件夹目录,那我们的配置文件呢?
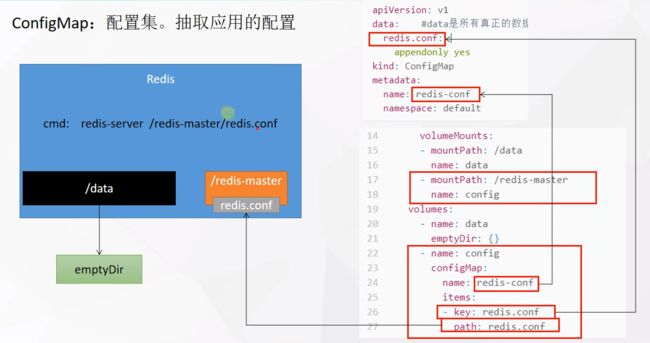
4.3 配置 ConfigMap(推荐)
优点:可以统一配置,还可以支持热更新
大致步骤:先准备一个配置文件,使用create cm变成configmap
4.3.1 配置文件准备
[root@cluster-master 03]# cd ~
[root@cluster-master ~]# vim redis.conf
# configmap简写为cm 后面的redis-conf是文件的名字 fromfile是依据哪个文件创建cm
[root@cluster-master ~]# kubectl create cm redis-conf --from-file=redis.conf
configmap/redis-conf created
[root@cluster-master ~]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 4d21h
redis-conf 1 5s
[root@cluster-master ~]# kubectl edit cm redis-conf
Edit cancelled, no changes made.
[root@cluster-master ~]# kubectl get cm redis-conf -oyaml
# 精简了一下文件内容
apiVersion: v1
data: # data是真正的数据,是key-value的形式
redis.conf: |
appendonly yes
kind: ConfigMap
metadata:
name: redis-conf # 这个名字是其他Pod绑定cm的时候用的
namespace: default
4.3.2 yaml文件创建Pod
创建Deployment(第一次是Pod的,为了实验,换了Deployment之后又试了一次)
Pod的:(可以和Deployemnt的对比一下)
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
command:
- redis-server
- "/redis-master/redis.conf" #指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data
name: data
- mountPath: /redis-master
name: config
volumes:
- name: data
emptyDir: {}
- name: config
configMap:
name: redis-conf
items:
- key: redis.conf
path: redis.conf
Deployment的:(yaml解析图在后面)
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
replicas: 1
selector: # 这里的selector和紧跟其后的template长的差不多
matchLabels:
app: redis-server
template:
metadata:
labels:
app: redis-server
spec:
containers:
- name: redis
image: redis
command: # 这个容器启动运行的命令
- redis-server
- "/redis-master/redis.conf" # 指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data # 这个是redis容器内部的目录
name: data # 挂载目录到data指定的地方,这个data在下面有
- mountPath: /redis-master
name: config
volumes:
- name: data
emptyDir: {} # 对应上面的data,这里是空的,是让K8S给我们生成一个文件夹
- name: config
configMap:
name: redis-conf # 前面创建cm的时候里面的名字
items: # 配置文件里面有很多数据,我们按照Key的形式来取
- key: redis.conf # 对应的configmap里面的key
path: redis.conf # 这个是把上面那个key对应的value取出来放到外面的路径,会在redis-master下面创建一个redis.conf
apply文件
4.3.3 进入容器查看效果
# 先查看配置文件的数据是否同步成功
root@redis:/# cd redis-master/
root@redis:/redis-master# ls
redis.conf
root@redis:/redis-master# cat redis.conf
appendonly yes
# 在外面修改ConfigMap配置集的时候,redis里面也会同步
[root@cluster-master ~]# kubectl edit cm redis-conf
configmap/redis-conf edited
# 我们加了一条配置requirepass 123456
# 经过等待,redis容器内部的文件也改变了
root@redis:/redis-master# cat redis.conf
appendonly yes
requirepass 123456
# redis登陆
root@redis:/redis-master# redis-cli
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "yes"
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "" # 没有值是因为redis没有热更新,因为我第一次不是deployemnt方式创建的redis,所以删除之后也不会重新创建一个新的,所以,后面我换成deployemnt又试了一次
# 这个我用deployment部署的一个Pod
# 需要密码才可以登上了
root@redis-84dc8cb45b-xgf76:/redis-master# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "yes
# 我在此时修改了cm文件,改了密码
# 测试删除Pod,deployment会自动再创建一个Pod
root@redis-84dc8cb45b-rwqxp:/redis-master# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
AUTH failed: WRONGPASS invalid username-password pair or user is disabled. # 就登不上去了
root@redis-84dc8cb45b-rwqxp:/redis-master# redis-cli -a xw123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "xw123456
4.3.4 图解

configMap用来保存明文信息,那令牌和密钥那些敏感信息呢?
4.4 Secret
小菜鸡的我暂时用不上这个功能,但还是记录一下
这个的用处就是:
针对有些Docker-hub的镜像是私有的,需要使用那个用户的身份才可以pull,一般的,我们每次需要在命令行窗口登陆我们的dockerhub,但很麻烦,所以,我们使用这个Secret来保存我们的密钥。
需要的时候直接在后面加上这个imagePullSecrets即可
kubectl create secret docker-registry xw-docker \
--docker-username=xwxwxwxwx \
--docker-password=xw12312321 \
--docker-email=321321321@qq.com
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: private-nginx
spec:
containers:
- name: private-nginx
image: xw/test-secret:v1.0
imagePullSecrets: # 加这个,然后name是我们创建的secret
- name: xw-docker
5. 总结
5.1 工作负载
Deployemet部署的应用具有强大的自愈和故障处理能力,可以平滑的升级,很多优秀的特性。底层运行的是一个个的Pod,Pod里面是一个个的容器。
Jobs/CronJobs是用来做定时任务的部署。
DaemonSets是用来做守护进程的部署。
StatefulSets是用来做有状态的进程的部署。
ReplicaSets:Deployments是一个更高层次的概念,它管理ReplicaSets。
无论是什么部署的,都是Pod,这些Pod间是可以互相访问的,但我们不这么做,因为如果Pod“死掉了”,重启之后,它的IP会变,我们得重新改IP,这很麻烦,所以我们用Service来访问。
5.2 服务

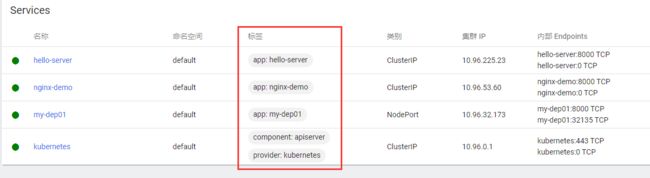
每一个服务都会有一个标签,一组Pod,我们给他设定一个标签。
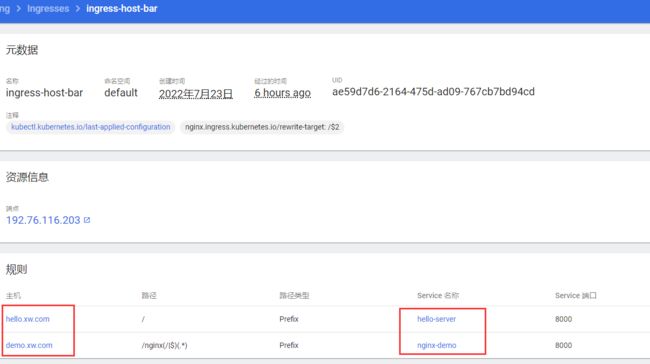
这还不够,在Service之上,我们还有Ingress,可以针对不同的流量访问,我们可以让它转到不一样的Service。
5.3 配置和存储
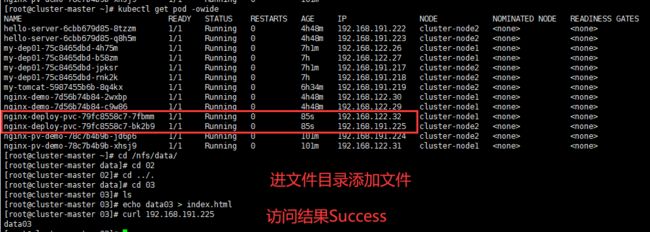
挂载目录我们推荐用PV和PVC,挂载配置文件我们推荐用ConfigMap。挂载密钥我们就用Secret。
这个是PV和PVC
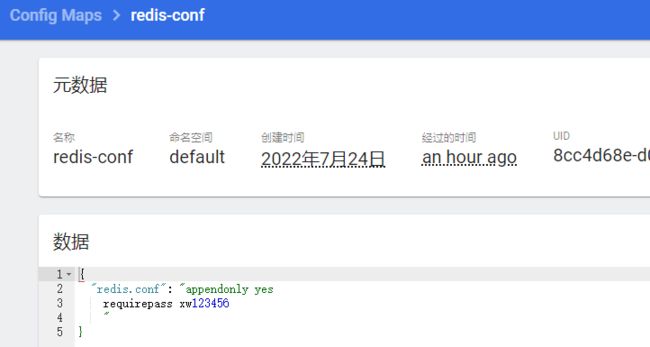
这个是Configmap
这个是Secret
结语:
测试学习Kubernetes基础和进阶部分完毕,但是关于K8S和容器的基础知识还是有点匮乏,之后可以看学长发的那些个文件补充基础知识。
另外对于yaml文件的写法,格式语法,都需要再了解一下,具体可以看尚硅谷的那个讲解K8S的。