密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇(上)
[ TPAMI 2021 ]
Multi-Task Learning for Dense Prediction Tasks:
A Survey
[ The authors ]
• Simon Vandenhende, Wouter Van Gansbeke and Marc Proesmans
Center for Processing Speech and Images, Department Electrical Engineering, KU Leuven.
• Stamatios Georgoulis and Dengxin Dai
Computer Vision Lab, Department Electrical Engineering, ETH Zurich.
• Luc Van Gool
Center for Processing Speech and Images, KU Leuven;
Computer Vision Lab, ETH Zurich.
[ Paper | Code ]
Multi-Task Learning for Dense Prediction Tasks: A Survey
https://arxiv.org/pdf/2004.13379.pdf
GitHub - SimonVandenhende/Multi-Task-Learning-PyTorch: PyTorch implementation of multi-task learning architectures, incl. MTI-Net (ECCV2020).
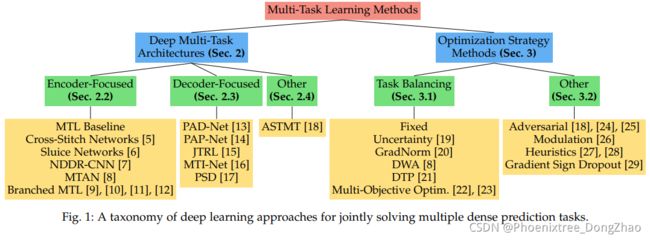
Figure 1 shows a structured overview of the paper. Our code is made publicly available to ease the adoption of the reviewed MTL techniques: https://github.com/ SimonVandenhende/Multi-Task-Learning-PyTorch.
[ CSDN Links ]
该综述全篇过长,故将其分为 4 部分分别讲解,相关博客链接如下:
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 摘要前言篇
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇 (上)
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇 (下)
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 优化方法篇
____________________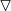 ____________________
____________________
目录
2 Deep Multi-Task Architectures
2.1 Historical Overview and Taxonomy
2.1.1 Non-Deep Learning Methods
2.1.2 Soft and Hard Parameter Sharing in Deep Learning
2.1.3 Distilling Task Predictions in Deep Learning
2.1.4 A New Taxonomy of MTL Approaches
2.2 Encoder-focused Architectures
2.2.1 Cross-Stitch Networks
2.2.2 Neural Discriminative Dimensionality Reduction
2.2.3 Multi-Task Attention Networks
2.2.4 Branched Multi-Task Learning Networks
2 Deep Multi-Task Architectures
In this section, we review deep multi-task architectures used in computer vision. First, we give a brief historical overview of MTL approaches, before introducing a novel taxonomy to categorize different methods. Second, we discuss network designs from different groups of works, and analyze their advantages and disadvantages. An experimental comparison is also provided later in Section 4. Note that, as a detailed presentation of each architecture is beyond the scope of this survey, in each case we refer the reader to the corresponding paper for further details that complement the following descriptions.
本节回顾计算机视觉中使用的深度多任务架构。首先,简要介绍 MTL 方法的历史概况,然后介绍了一种新的分类法来对不同的方法进行分类。其次,从不同的作品群体中讨论网络设计,并分析其优缺点。实验比较也将在后面的第 4 节中提供。注意,由于对每个架构的详细介绍超出了本调查的范围,在每种情况下,请读者参考相应的论文,以获得补充以下描述的进一步细节。
2.1 Historical Overview and Taxonomy
2.1.1 Non-Deep Learning Methods
Before the deep learning era, MTL works tried to model the common information among tasks in the hope that a joint task learning could result in better generalization performance. To achieve this, they placed assumptions on the task parameter space, such as: task parameters should lie close to each other w.r.t. some distance metric [38], [39], [40], [41], share a common probabilistic prior [42], [43], [44], [45], [46], or reside in a low dimensional subspace [47], [48], [49] or manifold [50]. These assumptions work well when all tasks are related [38], [47], [51], [52], but can lead to performance degradation if information sharing happens between unrelated tasks. The latter is a known problem in MTL, referred to as negative transfer. To mitigate this problem, some of these works opted to cluster tasks into groups based on prior beliefs about their similarity or relatedness.
非深度学习方法
在深度学习时代之前,MTL 试图对任务之间的共同信息进行建模,希望联合任务学习能够获得更好的泛化性能。为了实现这一点,他们把假设参数空间的任务,如:任务参数应该接近彼此(关于某种度量距离 [38],[39],[40],[41]),共享一个共同的概率先验 [42],[43],[44],[45],[46],或驻留在一个低维子空间 [47],[48]、[49] 或流形 [50]。当所有任务都是相关的时,这些假设很有效,但如果不相关的任务之间发生信息共享,则可能导致性能下降。后者是 MTL 中的一个已知问题,称为负迁移。为了缓解这一问题,一些研究选择基于对任务相似性或相关性的先验信念将任务分组。
2.1.2 Soft and Hard Parameter Sharing in Deep Learning
In the context of deep learning, MTL is performed by learning shared representations from multi-task supervisory signals. Historically, deep multi-task architectures were classified into hard or soft parameter sharing techniques.
In hard parameter sharing, the parameter set is divided into shared and task-specific parameters (see Figure 2a). MTL models using hard parameter sharing typically consist of a shared encoder that branches out into task-specific heads [19], [20], [22], [53], [54].
In soft parameter sharing, each task is assigned its own set of parameters and a feature sharing mechanism handles the cross-task talk (see Figure 2b).
We summarize representative works for both groups of works below.
在深度学习环境下,MTL 是通过从多任务监控信号中学习共享表示来实现的。在历史上,深度多任务架构分为硬参数共享技术和软参数共享技术。
在硬参数共享中,将参数集分为共享参数和任务特定参数 (如图 2a)。使用硬参数共享的 MTL 模型通常由一个共享编码器组成,该编码器分支到特定于任务的头 [19],[20],[22],[53],[54]。
在软参数共享中,每个任务被分配自己的一组参数,一个特性共享机制处理跨任务对话 (见图 2b)。


Hard Parameter Sharing. UberNet [55] was the first hardparameter sharing model to jointly tackle a large number of low-, mid-, and high-level vision tasks. The model featured a multi-head design across different network layers and scales. Still, the most characteristic hard parameter sharing design consists of a shared encoder that branches out into task-specific decoding heads [19], [20], [22], [53], [54]. Multilinear relationship networks [56] extended this design by placing tensor normal priors on the parameter set of the fully connected layers. In these works the branching points in the network are determined ad hoc, which can lead to suboptimal task groupings. To alleviate this issue, several recent works [9], [10], [11], [12] proposed efficient design procedures that automatically decide where to share or branch within the network. Similarly, stochastic filter groups [57] re-purposed the convolution kernels in each layer to support shared or task-specific behaviour.
硬参数共享
UberNet [55] 是第一个共同解决大量低、中、高层视觉任务的硬参数共享模型。该模型具有跨不同网络层和规模的多头设计。不过,最具特色的硬参数共享设计包括一个共享编码器,该编码器分支为特定任务的解码头。
Multilinear relationship networks [56] 通过在全连通层的参数集上放置张量法线先验来扩展这种设计。在这些工作中,网络中的分支点是自定义的,这可能导致次优任务分组。为了缓解这个问题,最近的几个项目 [9],[10],[11],[12] 提出了自动决定在网络中何处共享或分支的高效设计程序。
类似地,随机滤波器组(stochastic filter groups) [57] 在每一层重新使用卷积核,以支持共享或特定任务的行为。
[55] “Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory,” in CVPR, 2017.
[56] “Learning multiple tasks with multilinear relationship networks,” in NIPS, 2017.
[57] “Stochastic filter groups for multi-task CNNs: Learning specialist and generalist convolution kernels,” in ICCV, 2019.


Soft Parameter Sharing. Cross-stitch networks [5] introduced soft-parameter sharing in deep MTL architectures. The model uses a linear combination of the activations in every layer of the task-specific networks as a means for soft feature fusion. Sluice networks [6] extended this idea by allowing to learn the selective sharing of layers, subspaces and skip connections. NDDR-CNN [7] also incorporated dimensionality reduction techniques into the feature fusion layers. Differently, MTAN [8] used an attention mechanism to share a general feature pool amongst the task-specific networks. A concern with soft parameter sharing approaches is scalability, as the size of the multi-task network tends to grow linearly with the number of tasks.
软参数共享
Cross-stitch networks [5] 在深度 MTL 架构中引入了软参数共享。该模型采用任务特定网络各层激活的线性组合作为软特征融合的手段。
Sluice networks [6] 通过允许学习分层、子空间和跳过连接的选择性共享扩展了这一思想。
NDDR - CNN [7] 还在特征融合层中加入了降维技术。
与此不同的是,MTAN [8] 使用了一种注意机制,在特定任务网络之间共享一个通用的特性池。
软参数共享方法的一个问题是可伸缩性,因为多任务网络的规模往往随任务数量线性增长。
[5] “Cross-stitch networks for multi-task learning,” in CVPR, 2016.
[6] “Latent multi-task architecture learning,” in AAAI, 2019.
[7] “NDDR-CNN: Layer-wise feature fusing in multi-task CNNs by neural discriminative dimensionality reduction,” in CVPR, 2019.
[8] “End-to-end multi-task learning with attention,” in CVPR, 2019.


2.1.3 Distilling Task Predictions in Deep Learning
All works presented in Section 2.1.2 follow a common pattern: they directly predict all task outputs from the same input in one processing cycle. In contrast, a few recent works first employed a multi-task network to make initial task predictions, and then leveraged features from these initial predictions to further improve each task output – in a one-off or recursive manner.
PAD-Net [13] proposed to distill information from the initial task predictions of other tasks, by means of spatial attention, before adding it as a residual to the task of interest. JTRL [15] opted for sequentially predicting each task, with the intention to utilize information from the past predictions of one task to refine the features of another task at each iteration. PAP-Net [14] extended upon this idea, and used a recursive procedure to propagate similar cross-task and task-specific patterns found in the initial task predictions. To do so, they operated on the affinity matrices of the initial predictions, and not on the features themselves, as was the case before [13], [15]. Zhou et al. [17] refined the use of pixel affinities to distill the information by separating inter- and intra-task patterns from each other. MTI-Net [16] adopted a multi-scale multimodal distillation procedure to explicitly model the unique task interactions that happen at each individual scale.
第 2.1.2 节中介绍的所有工作都遵循一个共同的模式:它们直接预测一个处理周期中来自相同输入的所有任务输出。
相反,最近的一些研究首先使用多任务网络来进行初始任务预测,然后利用这些初始预测的特性进一步改进每个任务的输出——以一次性或递归的方式。
PAD-Net [13] 提出通过空间注意从其他任务的初始任务预测中提取信息,然后将其作为兴趣任务的残差添加到兴趣任务中。
JTRL [15] 选择按顺序预测每个任务,目的是在每次迭代时利用来自一个任务的过去预测的信息来改进另一个任务的特性。
PAP-Net [14] 扩展了这一思想,并使用递归过程传播在初始任务预测中发现的类似的跨任务和特定任务模式。为了做到这一点,他们对初始预测的亲和矩阵进行操作,而不是对特征本身进行操作,就像 [13],[15] 之前的情况一样。
Zhou et al. [17] 通过将任务间和任务内模式分离出来,改进了使用像素亲和力来提取信息的方法。
MTI-Net [16] 采用多尺度多峰蒸馏过程,明确地模拟发生在每个个体尺度上的独特任务交互作用。
[13] “Pad-net: Multitasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing,” in CVPR, 2018.
[14] “Pattern affinitive propagation across depth, surface normal and semantic segmentation,” in CVPR, 2019.
[15] “Joint task recursive learning for semantic segmentation and depth estimation,” in ECCV, 2018.
[16] “Mti-net: Multi-scale task interaction networks for multi-task learning,” in ECCV, 2020.
[17] “Pattern-structure diffusion for multi-task learning,” in CVPR, 2020.

2.1.4 A New Taxonomy of MTL Approaches
As explained in Section 2.1.2, multi-task networks have historically been classified into soft or hard parameter sharing techniques. However, several recent works took inspiration from both groups of works to jointly solve multiple pixellevel tasks. As a consequence, it is debatable whether the soft vs hard parameter sharing paradigm should still be used as the main framework for classifying MTL architectures.
In this survey, we propose an alternative taxonomy that discriminates between different architectures on the basis of where the task interactions take place, i.e. locations in the network where information or features are exchanged or shared between tasks. The impetus for this framework was given in Section 2.1.3. Based on the proposed criterion, we distinguish between two types of models: encoder-focused and decoder-focused architectures.
The encoder-focused architectures (see Figure 3a) only share information in the encoder, using either hard- or soft-parameter sharing, before decoding each task with an independent task-specific head.
Differently, the decoder-focused architectures (see Figure 3b) also exchange information during the decoding stage.
如 2.1.2 节所述,多任务网络历来被分为软参数共享技术和硬参数共享技术。然而,最近的一些作品从这两组作品中获得了灵感,共同解决多个像素级的任务。因此,软参数共享范式和硬参数共享范式是否仍应作为对 MTL 体系结构进行分类的主要框架存在争议。
本综述提出了一种可选的分类法,根据任务交互发生的位置来区分不同的体系结构,即任务之间交换或共享信息或特征的网络位置。这个框架的动机在第 2.1.3 节中给出。基于提出的标准,我们区分了两种类型的模型:以 encoder-focused 和 decoder-focused 的体系结构。
encoder-focused 的架构 (参见图3a) 在使用独立的任务专用头解码每个任务之前,只使用硬参数或软参数共享共享编码器中的信息。
decoder-focused 的结构 (见图3b) 也在解码阶段交换信息。


2.2 Encoder-focused Architectures
Encoder-focused architectures (see Figure 3a) share the task features in the encoding stage, before they process them with a set of independent task-specific heads. A number of works [19], [20], [22], [53], [54] followed an ad hoc strategy by sharing an off-the-shelf backbone network in combination with small task-specific heads (see Figure 2a). This model relies on the encoder (i.e. backbone network) to learn a generic representation of the scene. The features from the encoder are then used by the task-specific heads to get the predictions for every task. While this simple model shares the full encoder amongst all tasks, recent works have considered where and how the feature sharing should happen in the encoder. We discuss such sharing strategies in the following sections.
Encoder-focused 的架构 (参见图 3a) 在编码阶段共享任务特性,然后使用一组独立的任务特定头来处理它们。[19],[20],[22],[53],[54] 的许多工作都采用了一种特别的策略,通过与小的特定任务头共享现成的主干网络 (参见图 2a)。这个模型依赖于编码器 (即 backbone 网络) 来学习场景的一般表示。然后,特定于任务的头部使用编码器的特性来获取每个任务的预测。虽然这个简单的模型在所有任务中共享完整的编码器,但最近的工作已经考虑了在编码器中共享特性的位置和方式。本文将在下面的小节中讨论这种共享策略。
2.2.1 Cross-Stitch Networks
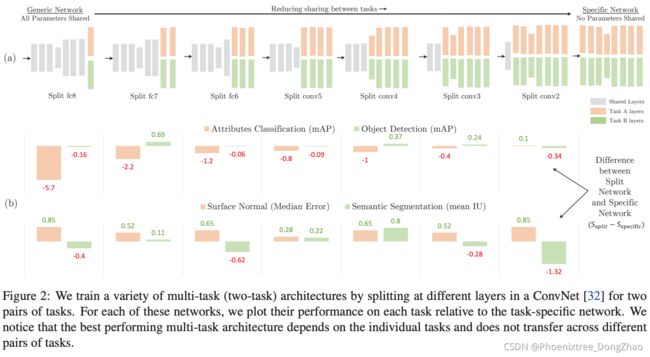
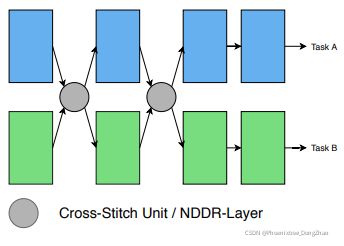
Cross-stitch networks [5] shared the activations amongst all single-task networks in the encoder. Assume we are given two activation maps xA, xB at a particular layer, that belong to tasks A and B respectively. A learnable linear combination of these activation maps is applied, before feeding the transformed result x˜A, x˜B to the next layer in the single-task networks. The transformation is parameterized by learnable weights α, and can be expressed as
As illustrated in Figure 4, this procedure is repeated at multiple locations in the encoder. By learning the weights α, the network can decide the degree to which the features are shared between tasks. In practice, we are required to pre-train the single-task networks, before stitching them together, in order to maximize the performance. A disadvantage of cross-stitch networks is that the size of the network increases linearly with the number of tasks. Furthermore, it is not clear where the cross-stitch units should be inserted in order to maximize their effectiveness. Sluice networks [6] extended this work by also supporting the selective sharing of subspaces and skip connections.

Cross-stitch networks [5] 在编码器中的所有单任务网络中共享激活。假设在一个特定层有两个激活映射 xA, xB,它们分别属于任务 A 和任务 B。将这些激活图进行可学习的线性组合,然后将变换后的结果 x˜A, x˜B 馈给单任务网络中的下一层。该变换由可学习权值 α 参数化,可表示为 (1)。
如图 4 所示,这个过程在编码器的多个位置重复。通过学习权值 α,网络可以确定任务之间特征共享的程度。
在实践中,需要对单任务网络进行预训练,然后将它们拼接在一起,以使性能最大化。
Cross-stitch 网络的一个缺点是网络的大小随任务的数量线性增加。此外,它是不清楚的 Cross-stitch 单位应该在哪里插入,以最大限度地发挥其效力。Sluice networks [6] 通过支持选择性共享子空间和跳过连接扩展了这项工作。
[5] Cross-stitch Networks for Multi-task Learning. CVPR, 2016


[6] Latent Multi-task Architecture Learning. AAAI,2019


arxiv 版本:Sluice networks: Learning what to share between loosely related tasks.
2.2.2 Neural Discriminative Dimensionality Reduction
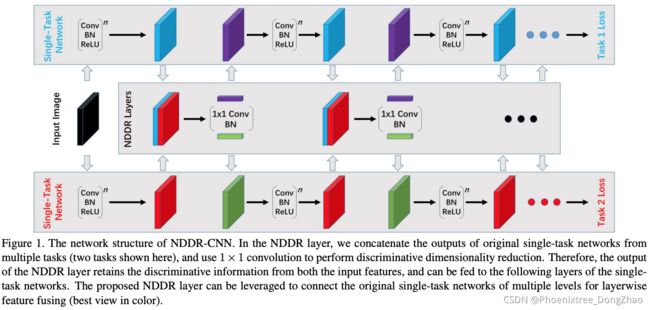
Neural Discriminative Dimensionality Reduction CNNs (NDDR-CNNs) [7] used a similar architecture with crossstitch networks (see Figure 4). However, instead of utilizing a linear combination to fuse the activations from all singletask networks, a dimensionality reduction mechanism is employed. First, features with the same spatial resolution in the single-task networks are concatenated channel-wise. Second, the number of channels is reduced by processing the features with a 1 by 1 convolutional layer, before feeding the result to the next layer. The convolutional layer allows to fuse activations across all channels. Differently, crossstitch networks only allow to fuse activations from channels that share the same index. The NDDR-CNN behaves as a cross-stitch network when the non-diagonal elements in the weight matrix of the convolutional layer are zero.
Due to their similarity with cross-stitch networks, NDDR-CNNs are prone to the same problems. First, there is a scalability concern when dealing with a large number of tasks. Second, NDDR-CNNs involve additional design choices, since we need to decide where to include the NDDR layers. Finally, both cross-stitch networks and NDDR-CNNs only allow to use limited local information (i.e. small receptive field) when fusing the activations from the different single-task networks. We hypothesize that this is suboptimal because the use of sufficient context is very important during encoding – as already shown for the tasks of image classification [58] and semantic segmentation [59], [60], [61]. This is backed up by certain decoder-focused architectures in Section 2.3 that overcome the limited receptive field by predicting the tasks at multiple scales and by sharing the features repeatedly at every scale.
Neural Discriminative dimension Reduction CNNs (NDDR-CNNs) [7] 使用了与 cross-stitch 网络类似的架构 (见图 4)。然而,不是使用线性组合来融合所有单任务网络的激活,而是使用了一种降维机制。首先,将单任务网络中具有相同空间分辨率的特征按通道级联。其次,在将结果提供给下一层之前,通过 1x1 卷积层处理特征来减少通道的数量。卷积层允许融合所有通道的激活。不同的是,cross-stitch 网络只允许融合来自共享相同索引的通道的激活。当卷积层权矩阵中的非对角元素为零时,NDDR-CNNs 表现为 cross-stitch 网络。

由于它们与 cross-stitch 网络的相似性,NDDR-CNNs 容易出现同样的问题。首先,在处理大量任务时,存在可伸缩性问题。第二,NDDR-CNNs 涉及额外的设计选择,因为需要决定在哪里包含NDDR 层。最后,cross-stitch 网络和 NDDR-CNNs 在融合不同单任务网络的激活时,只允许使用有限的局部信息 (即较小的接受域)。假设这是次优的,因为在编码过程中使用足够的上下文非常重要——正如图像分类 [58] 和语义分割 [59],[60],[61] 所显示的那样。2.3 节中某些 decoder-focused 的架构支持了这一点,这些架构通过在多个尺度上预测任务,并在每个尺度上重复共享特征,克服了有限的接受域。
[7] NDDR-CNN: Layerwise Feature Fusing in Multi-Task CNNs by Neural Discriminative Dimensionality Reduction. CVPR, 2019

2.2.3 Multi-Task Attention Networks
Multi-Task Attention Networks (MTAN) [8] used a shared backbone network in conjunction with task-specific attention modules in the encoder (see Figure 5). The shared backbone extracts a general pool of features. Then, each task-specific attention module selects features from the general pool by applying a soft attention mask. The attention mechanism is implemented using regular convolutional layers and a sigmoid non-linearity. Since the attention modules are small compared to the backbone network, the MTAN model does not suffer as severely from the scalability issues that are typically associated with cross-stitch networks and NDDR-CNNs. However, similar to the fusion mechanism in the latter works, the MTAN model can only use limited local information to produce the attention mask.
Multi-Task Attention Networks (MTAN) [8] 使用了一个共享 backbone 网与编码器中的特定任务注意力模块相结合 (见图 5)。共享 backbone 网提取了一个通用的特征库。然后,每个任务特定的注意力模块通过应用一个软注意力 mask 从一般池化中选择特征。注意力机制是使用正则卷积层和 sigmoid 非线性实现的。由于注意力模块与 backbone 网络相比较小,因此 MTAN 模型不会受到 cross-stitch 网络和 NDDR-CNNs 通常存在的可伸缩性问题的严重影响。然而,与后者的融合机制类似,MTAN 模型只能使用有限的局部信息来生成注意力 mask。


[8] End-to-End Multi-Task Learning with Attention. CVPR, 2019

2.2.4 Branched Multi-Task Learning Networks
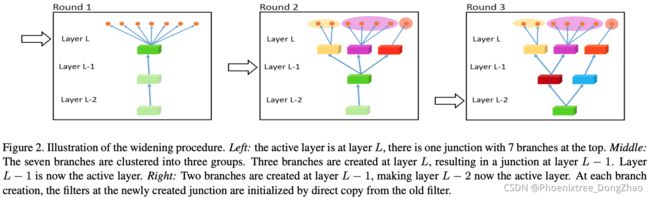
The models presented in Sections 2.2.1-2.2.3 softly shared the features amongst tasks during the encoding stage. Differently, branched multi-task networks followed a hardparameter sharing scheme. Before presenting these methods, consider the following observation: deep neural networks tend to learn hierarchical image representations [62]. The early layers tend to focus on more general low-level image features, such as edges, corners, etc., while the deeper layers tend to extract high-level information that is more task-specific. Motivated by this observation, branched MTL networks opted to learn similar hierarchical encoding structures [9], [10], [11], [12]. These ramified networks typically start with a number of shared layers, after which different (groups of) tasks branch out into their own sequence of layers. In doing so, the different branches gradually become more task-specific as we move to the deeper layers. This behaviour aligns well with the hierarchical representations learned by deep neural nets. However, as the number of possible network configurations is combinatorially large, deciding what layers to share and where to branch out becomes cumbersome. Several works have tried to automate the procedure of hierarchically clustering the tasks to form branched MTL networks given a specific computational budget (e.g. number of parameters, FLOPS). We provide a summary of existing works below.
章节 2.2.1-2.2.3 中介绍的模型在编码阶段柔和地共享了任务之间的特性。不同的是,分支多任务网络遵循硬参数共享方案。在提出这些方法之前,请考虑以下观察:深度神经网络倾向于学习分层图像表示 [62]。早期的层倾向于集中于更一般的低级图像特征,如边缘、角等,而更深的层倾向于提取更特定于任务的高级信息。
基于这种观察,分支 MTL 网络选择学习类似的层次编码结构 [9],[10],[11],[12]。这些分支网络通常以一些共享层开始,然后不同的任务(组)向外分支,形成它们自己的层序列。在这样做的过程中,随着向更深层次移动,不同的分支逐渐变得更加特定于任务。这种行为与深度神经网络学习的层次表示很好地一致。然而,由于可能的网络配置的数量组合起来很大,决定共享哪些层以及在哪里扩展就变得很麻烦。一些工作尝试自动化的过程,层次聚类任务形成分支 MTL 网络给定特定的计算预算 (如参数的数量,FLOPS)。
Fully-Adaptive Feature Sharing (FAFS) [9] starts from a network where tasks initially share all layers, and dynamically grows the model in a greedy layer-by-layer fashion during training. The task groupings are optimized to separate dissimilar tasks from each other, while minimizing network complexity. The task relatedness is based on the probability of concurrently ’simple’ or ’difficult’ examples across tasks. This strategy assumes that it is preferable to solve two tasks in an isolated manner (i.e. different branches) when the majority of examples are ’simple’ for one task, but ’difficult’ for the other.
Fully-Adaptive Feature Sharing (FAFS) [9] 从一个网络开始,其中任务最初共享所有层,并在训练过程中以一种逐层贪婪的方式动态增长模型。优化任务分组,使不同的任务相互分离,同时最小化网络复杂度。任务相关性是基于任务中同时出现 “简单” 或 “困难” 例子的概率。这个策略假设,当大多数例子对一个任务来说是 “简单的”,而对另一个任务来说是 “困难的” 时,以独立的方式解决两个任务( 即不同的分支) 是更好的选择。
[9] Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. CVPR, 2017
Similar to FAFS, Vandenhende et al. [10] rely on precomputed task relatedness scores to decide the grouping of tasks. In contrast to FAFS, they measure the task relatedness based on feature affinity scores, rather than sample difficulty. The main assumption is that two tasks are strongly related, if their single-task models rely on a similar set of features. An efficient method [63] is used to quantify this property. An advantage over FAFS is that the task groupings can be determined offline for the whole network, and not online in a greedy layer-by-layer fashion [10]. This strategy promotes task groupings that are optimal in a global, rather than local, sense. Yet, a disadvantage is that the calculation of the task affinity scores requires a set of single-task networks to be pretrained first.
与 FAFS 类似,Vandenende et al. [10] 依赖于预先计算的任务相关性分数来决定任务分组。与FAFS 不同的是,它们基于特征亲和度评分来衡量任务相关性,而不是样本难度。主要假设是,如果两个任务的单任务模型依赖于一组相似的特性,那么它们是紧密相关的。一种有效的方法 [63] 被用来量化这一性质。与 FAFS 相比,任务分组的一个优点是可以为整个网络脱机确定,而不是以一种逐层贪婪的方式在线确定。这种策略促进任务分组在全局而不是局部的意义上是最优的。但缺点是,计算任务亲和度得分需要先对一组单任务网络进行预训练。
[10] Branched multi-task networks: Deciding what layers to share. BMVC, 2020
Different from the previous works, Branched Multi-Task Architecture Search (BMTAS) [11] and Learning To Branch (LTB) [12] have directly optimized the network topology without relying on pre-computed task relatedness scores. More specifically, they rely on a tree-structured network design space where the branching points are casted as a Gumbel softmax operation. This strategy has the advantage over [9], [10] that the task groupings can be directly optimized end-to-end for the tasks under consideration. Moreover, both methods can easily be applied to any set of tasks, including both image classification and per-pixel prediction tasks. Similar to [9], [10], a compact network topology can be obtained by including a resource-aware loss term. In this case, the computational budget is jointly optimized with the multi-task learning objective in an endto-end fashion.
与以往的工作不同,Branched Multi-Task Architecture Search (BMTAS)ss [11] 和 Learning To Branch (LTB) [12] 直接优化了网络拓扑,而不依赖于预先计算的任务关联评分。更具体地说,它们依赖于树形结构的网络设计空间,其中的分支点被转换为 Gumbel softmax 操作。与 [9]、[10] 相比,该策略的优势在于,任务分组可以直接针对所考虑的任务进行端到端优化。此外,这两种方法可以很容易地应用于任何一组任务,包括图像分类和逐像素预测任务。与 [9]、[10] 类似,可以通过包含一个资源感知损失项来获得紧凑的网络拓扑。在这种情况下,以端到端方式将计算预算与多任务学习目标联合优化。
[11] Automated search for resource-efficient branched multi-task networks. 2020
[12] Learning to branch for multitask learning. ICML, 2020


2.3 Decoder-Focused Architectures
请继续阅读博客:密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇 (下)。
____________________![]() ____________________
____________________
[ Links ]
该综述全篇过长,故将其分为 4 部分分别讲解,相关博客链接如下:
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 摘要前言篇
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇 (上)
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 网络结构篇 (下)
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 优化方法篇
________________________________________
[ Extension ]
Multi-Task Learning with Deep Neural Networks: A Survey (2020)
