【目标检测实战学习】从零开始制作并训练自己的VOC数据集,并使用Retinanet进行目标检测
目录
基础软件安装
项目来源
环境配置
使用LabelImg给图片打标签
数据增强
划分训练集,测试集
模型训练
将验证集结果可视化
首先写一下我们这个项目的思路
1.下载图片,网上随便找
2.使用LabelImg对这些图片打标签,生成对应的XML文件
3.使用数据增强方法(我这里主要使用mixup和mosaic的方法),生成更多图片
4.使用代码脚本划分训练集,测试集,生成csv文件
5.对训练集数据进行训练,得到一个权重文件.pt
6.使用这个文件对测试集进行可视化结果测试
基础软件安装
关于Anaconda,PyTorch的安装已经有很多大佬发过贴了,我也是按照教程来的,这里就不惜将了,贴个链接,不会的可以自己去看
Anaconda安装:(18条消息) 史上最全最详细的Anaconda安装教程_OSurer的博客-CSDN博客_anaconda 安装
Pytorch安装:
PyTorch 最新安装教程(2021-07-27)_ZSYL的博客-CSDN博客_pytorch安装教程
这里需要提醒一下:看了很多帖子说用清华源下载会下成CPU版本的,所以网速还ok的话建议还是不要换源,还有就是本人推荐使用pip安装(我conda安装经常会出一些莫名其妙的问题)
cuDNN和cuda toolkit安装:
CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客_cuda安装
LabelImg的安装:
图像标注工具labelImg安装教程及使用方法_望天边星宿的博客-CSDN博客_labelimg安装教程
项目来源
我参考的是GIthub上面大神的项目,星星非常多,要把他下载下来
链接:GitHub - yhenon/pytorch-retinanet: Pytorch implementation of RetinaNet object detection.
下载后解压,在pycharm中打开,结构如下:

环境配置
打开文件--设置--项目--python解释器,点击右上角的小齿轮:
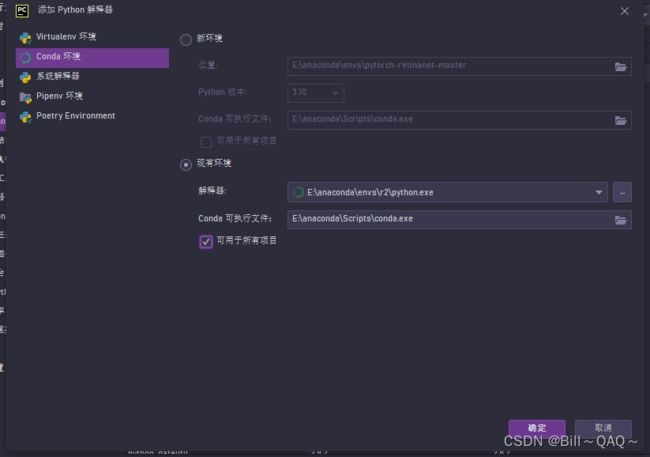
选择Conda 环境--现有环境,然后在解释器那里按照路径选择我们安装好的conda pytorch环境,一般是:anaconda\eves\创建的虚拟环境名字(conda create -n 的名字)\phthon.exe,选择这个exe文件
这样解释器就配置好了
还需要设置终端的python解释器的环境,这一步很重要。因为后面我们需要使用指令在终端运行程序,如果不设置的话很容易出错,我一开始就是没有管这个,后来发现我的pytorch虚拟环境是python 3.9的,终端的python是3.10,完全不一样。而且在虚拟环境中已经调试好的torch.cuda.is_available=True,但是在终端中运行的时候却显示False,这些都是终端的解释器环境没有设置好导致的
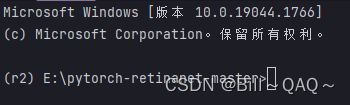
直接按照下图来

在python解释器那里选择刚刚那个anaconda\eves\创建的虚拟环境名字(conda create -n 的名字)\phthon.exe,点击确定保存。然后打开终端,如果出现(环境名称)+项目路径就代表设置好了,如下图,我这里虚拟环境的名字是r2
这样有关环境的设置就调好了
使用LabelImg给图片打标签
在项目的文件夹下创建两个新的文件:
JPEGImages_original:用于存储我们下载好的原始图片
Annotations_original:用于存放我们对原始图片打好的标签
同时原来那个images文件夹可以删掉,本次用不上

然后就可以去网上下载图片了,一定一定要下载一样格式的!格式不统一的话后面代码会报错!! 建议统一jpeg,保存路径就是那个JPEGImages
我这里下载的都是一些猫猫狗狗的,拿这个做检测比较直观,数量不一定要特别多,20来张左右差不多了,我们后面可以通过数据增强来增加样本的数量,后面会讲到

然后我们打开LabelImg,具体步骤是:在Anaconda prompt中cd 到labelimg所在的文件夹,然后输入
python labelImg.py这样就打labelImg的界面了
其中
打开目录就选择我们存储原始图片的JPEGImages_original文件夹
改变存放目录选择Annotations_original文件夹
输出格式选择Pascal VOC格式,生成的就是xml文件
然后就可以点击“创建区块”对图像进行标注了,并写明该目标的类型
 每标注完一张图像都要点击保存,然后用快捷键d跳到下一张
每标注完一张图像都要点击保存,然后用快捷键d跳到下一张
全部标注完成,就可以关闭labelImg,然后打开Annotations_original文件夹

已经生成好了对应的xml文件,里面存储的是我们刚刚打好的标签的信息
数据增强
数据增强简单来说就是对图像进行旋转,对称,融合,拼接,改变HSV通道参数等一系列操作,可以在已有数据集基础上生成更多的数据集
其原理也很好理解,对于我们人来说,你的面前有一只猫,我把它的上半身遮住,你依旧能根据一些特征判断出它是猫,我把它染个颜色,你依旧能认出它是猫,我让它倒立,你依旧能认出它是猫,我把它和一群狗放在一起,还是能认出它是猫
那么对于计算机来说,这些变换都是可以作为样本输入进行学习的
我这里采用的是Github上面一个项目,把他下载下来后解压到我们这个项目的文件夹下
GitHub - bubbliiiing/object-detection-augmentation: 这里面存放了一些目标检测算法的数据增强方法。如mosaic、mixup。
本次实验主要使用的是mixup方法和mosaic方法,其他的方法大家可以去自己找代码套用
mixup:就是图像融合,把很多张图融合到一起

mosaic:就是拼图,把几张图拼到一起,并改变其原有的HSV数值(亮度,色相,饱和度)

cutout:用一个任意大小的黑色的方块,把图像的某一部分遮住(图源自网友)

我们首先在项目下创建两个文件夹
JPEGImages_final:用于存储数据增强后的图片
Annotations_final:对图像进行数据增强需要连带把原有标签处理并标记到新的图像上,会生成新图像的标签信息
然后,重点来了
将这两个_final文件夹,替换掉VOCdevkit/VOC2007文件夹下的Annotations和JPEGImages文件夹
用之前两个_original文件夹,替换掉VOCdevkit_Origin/VOC2007文件夹下的Annotations和JPEGImages文件夹

接下来打开generate_mosaic.py,有一些参数需要修改,generate_mixup.py和generate_get_random_data.py都是同理,就不一一演示了
将代码中15,16行注释掉

在代码的68,69,71,72行,将输入,输出的路径改成_original文件夹和_final文件夹的绝对路径

为什么要修改的原因,是本人在实验中发现,如果使用源代码的相对路径,会出现输出空文件夹的情况,就是程序运行不会报错,但是结果不能存储到文件夹中,因此采用了绝对路径这种笨方法
接下来回到代码的21行,有一个

Out_Num是输出图像的数目,这个可以调大些,1000,2000都可以
input_shape是生成图像的大小,不建议修改
再去到代码的102,111,112行,这里有三个数据需要进行修改
![]()
![]() 如果你之前JPEGImages_original中的图像是jpg形式,就不需要修改,如果是jpeg的话,需要将图像修改成jpeg形式
如果你之前JPEGImages_original中的图像是jpg形式,就不需要修改,如果是jpeg的话,需要将图像修改成jpeg形式
然后就可以运行了,下面是结果

可以随便打开一个结果看一下

划分训练集,测试集
这里我使用的是站里一位大佬的代码,但是原帖子链接找不到了QAQ
import os
import xml.etree.ElementTree as ET
import random
import math
import argparse
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--indir', type=str)
parser.add_argument('-p', '--percent', type=float, default=0.3)
parser.add_argument('-t', '--train', type=str, default='train.csv')
parser.add_argument('-v', '--val', type=str, default='val.csv')
parser.add_argument('-c', '--classes', type=str, default='class.csv')
args = parser.parse_args()
return args
#获取特定后缀名的文件列表
def get_file_index(indir, postfix):
file_list = []
for root, dirs, files in os.walk(indir):
for name in files:
if postfix in name:
file_list.append(os.path.join(root, name))
return file_list
#写入标注信息
def convert_annotation(csv, address_list):
cls_list = []
with open(csv, 'w') as f:
for i, address in enumerate(address_list):
in_file = open(address, encoding='utf8')
strXml =in_file.read()
in_file.close()
root=ET.XML(strXml)
for obj in root.iter('object'):
cls = obj.find('name').text
cls_list.append(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text),
int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
f.write(file_dict[address_list[i]])
f.write( "," + ",".join([str(a) for a in b]) + ',' + cls)
f.write('\n')
return cls_list
if __name__ == "__main__":
args = parse_args()
file_address = args.indir
test_percent = args.percent
train_csv = args.train
test_csv = args.val
class_csv = args.classes
Annotations = get_file_index('E:\pytorch-retinanet-master\object-detection-augmentation-main\VOCdevkit\VOC2007\Annotations_final', '.xml')
Annotations.sort()
JPEGfiles = get_file_index('E:\pytorch-retinanet-master\object-detection-augmentation-main\VOCdevkit\VOC2007\JPEGImages_final', '.jpg') #可根据自己数据集图片后缀名修改 这是你VOC数据集的JPEGImage的路径 每一人路径不一样 我一般用的就是绝对路径
JPEGfiles.sort()
assert len(Annotations) == len(JPEGfiles) #若XML文件和图片文件名不能一一对应即报错
file_dict = dict(zip(Annotations, JPEGfiles))
num = len(Annotations)
test = random.sample(k=math.ceil(num*test_percent), population=Annotations)
train = list(set(Annotations) - set(test))
cls_list1 = convert_annotation(train_csv, train)
cls_list2 = convert_annotation(test_csv, test)
cls_unique = list(set(cls_list1+cls_list2))
with open(class_csv, 'w') as f:
for i, cls in enumerate(cls_unique):
f.write(cls + ',' + str(i) + '\n')
还是一样的,使用绝对路径,改成你自己的,其他不用修改,这里的jpg不用改成jpeg
运行之后,会发现生成了三个.csv文件
class.csv存储了类的信息,也就是标签的目录
train,val分别存储了训练集和测试集的图像信息

模型训练
打开train.py文件,大致看看几个参数
![]()
最后一个default代表epoch的次数
先简单解释四个概念
Batch:就是我们中文里面所说的批,把样本数据分成很多批放入模型中进行训练
Batch_size:批大小,也就是一批数据中有多少张图片
Iteration:迭代,训练一批数据(一个batch)就是一次迭代
epoch:所有的样本都进行了一次卷积网络前向传播和一次反向传播
因为retinanet是一种基于Resnet卷积网络的目标检测算法,因此可以将epoch的次数调大些,并且不用担心由于训练次数过多而导致的拟合效果下降问题(这涉及到resnet的原理,这里不展开了)
为了演示成果,我这里暂且调为3

batch_size:也就是批大小,这个具体要根据你电脑的GPU性能来调整,我这台电脑是Nvidia-1050的显卡,经过测试证明最大的batchsize只能调到3,4开始就会报错提示显存不足。这里强烈建议大家使用GPU跑数据,不要用CPU,笔记本也是,我用这台电脑cpu跑的话,batchsize只能调为1,速度特别慢(关于怎么使用GPU,可以去看PyTorch的安装教程,还有在前面调试终端的环境有讲到解决cuda.is_available=false,也就是gpu用不了怎么解决的问题)
调完就可以开始在终端下开始训练了,在终端输入如下指令:
python train.py --dataset csv --csv_train --csv_classes --csv_val 把< >中的路径,换成刚刚生成的三个csv文件的绝对路径,下面这个是我的路径:
python train.py --dataset csv --csv_train E:\pytorch-retinanet-master\train.csv --csv_classes E:\pytorch-retinanet-master\class.csv --csv_val E:\pytorch-retinanet-master\val.csv这里它会提醒下载一个关于resnet的pth文件,等待下载完成即可,速度可能会比较慢,也可以去网上提前下载好,然后直接放到项目的文件夹下面
![]()
然后就等待训练进行就行,一般来说前几个iteration不报错的话,后面都不会有问题,可以摸会儿鱼

在每完成一次训练集完成训练后,会对测试集进行测试,输出损失函数的数值

在训练完成后,会看到多出了几个文件

![]()
每完成一次epoch,就会生成一个权重文件,在最终完成后还会生成一个最终的权重文件,我们要使用的就是这个
将验证集结果可视化
在visualize.py代码的41行需要做如下修改
![]()
因为我们此时需要带入的是val验证集,不是train训练集
在visualize.py的终端中输入如下指令:
python visualize.py --dataset csv --csv_classes --csv_val --model 跟前面一样,要把对应csv,还有权重文件.pt的绝对路径改进去
然后就会有结果出来了


