PyTorch深度学习入门 || 系列(五)——逻辑回归
文章目录
- 0 写在前面
- 1 sigmoid函数
- 2 逻辑回归示例
- 2.1 plt.scatter()函数参数设置
- 3 模型定义
-
- 3.1 sigmoid()函数说明
- 4 优化器和损失函数
- 5 train()和draw()函数
-
- 5.1 torch.max(input, dim)
- 6 完整代码
0 写在前面
- 线性回归和非线性回归,它们的输出都是连续的。而逻辑回归的输出是二元离散,为了方便数字表达和计算,我们把这两种分类的结果分别记作0和1.
1 sigmoid函数
- sigmoid函数的定义域为R,但是值域在(0, 1)。


2 逻辑回归示例
- 首先初始化一下数据,
x = torch.cat((data0, data1), ).type(torch.FloatTensor),是把data0和data1合并起来,得到1000*2个数据,对y的操作同理。 - 分片操作:
x.numpy()[:, 0],是取出所有行的第0个元素。
import torch
import matplotlib.pyplot as plt
cluster = torch.ones(500, 2) # 500行 2列
data0 = torch.normal(4*cluster, 2)
data1 = torch.normal(-4*cluster, 2)
label0 = torch.zeros(500) # .size() 是[500]
label1 = torch.ones(500)
x = torch.cat((data0, data1), ).type(torch.FloatTensor)
y = torch.cat((label0, label1), ).type(torch.LongTensor)
plt.scatter(x.numpy()[:, 0], x.numpy()[:, 1], c=y.numpy(), s=10, lw=0, cmap='RdYlGn')
plt.show()
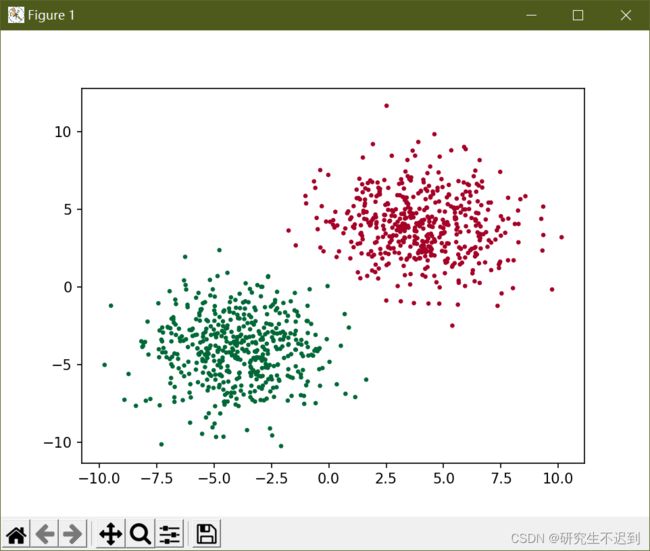
2.1 plt.scatter()函数参数设置
x: x轴数据
y: y轴数据
s: 散点大小
c: 散点颜色
marker: 散点形状
cmap: 指定特定颜色图,该参数一般不用,有默认值
alpha: 散点的透明度
linewidths: 散点边框的宽度
edgecolors: 设置散点边框的颜色
- 为了查看不同参数的效果,我依次添加了①散点大小②散点边框的宽度③指定特定颜色图④散点颜色




3 模型定义
- 在初始化__init__()函数中定义了一个线性层,设置输入输出为2,2。
- 在forward函数中,首先让输入经过线性层,然后在经过一个sigmoid激活层。将数据映射到0-1的范围中。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(2, 2)
def forward(self, x):
x = self.linear(x)
x = torch.sigmoid(x)
return x
net = Net().cuda()
inputs = x.cuda()
target = y.cuda()
3.1 sigmoid()函数说明
- 将输入映射到(0,1)之间。

4 优化器和损失函数
- 优化器采用随机梯度下降,SGD
- 由于这是一个分类问题,所以使用交叉熵作为损失函数
optimizer = optim.SGD(net.parameters(), lr=0.02)
criterion = nn.CrossEntropyLoss()
5 train()和draw()函数
5.1 torch.max(input, dim)
输入:
input是一个tensordim是一个max索引维度,0表示每列的最大值,1表示每行的最大值。== 换种解释方法:0表示按照第0维,1表示按照第1维,…N表示是第N维。这里的维度肯定是不能超出input的维度的。比如说input是356,那么N只能取0,1,2
输出:
- 函数会返回两个tensor,第一个
tensor表示最大值,第二个tensor表示最大值的索引。
可以使用中括号来指定,返回的是0还是1
output = torch.max((output), 1)[1] 这里返回的就是索引值(tensor)
6 完整代码
- 可以直接运行!
import torch
import matplotlib.pyplot as plt
from torch import nn, optim
cluster = torch.ones(500, 2) # 500行 2列
data0 = torch.normal(4*cluster, 2)
data1 = torch.normal(-4*cluster, 2)
label0 = torch.zeros(500) # .size() 是[500]
label1 = torch.ones(500)
x = torch.cat((data0, data1), ).type(torch.FloatTensor) # 把data0和data1合并起来,得到1000*2
y = torch.cat((label0, label1), ).type(torch.LongTensor)
# plt.scatter(x.numpy()[:, 0], x.numpy()[:, 1], c=y.numpy(), s=10, lw=0, cmap='RdYlGn')
# plt.show()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(2, 2)
def forward(self, x):
x = self.linear(x)
x = torch.sigmoid(x)
return x
net = Net().cuda()
inputs = x.cuda()
target = y.cuda()
optimizer = optim.SGD(net.parameters(), lr=0.02)
criterion = nn.CrossEntropyLoss()
def draw(output): # 需要将output(GPU)转化为(cpu)
output = output.cpu()
plt.cla()
output = torch.max((output), 1)[1] # 表示返回output中每行的序号
# pred_y = output.data.numpy().squeeze() # 压缩维度是1的维度(其实也没必要)
pred_y = output.data.numpy()
target_y = y.numpy()
plt.scatter(x.numpy()[:, 0], x.numpy()[:, 1], c=pred_y, s=10, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y)/1000.0
plt.text(1.5, -4, 'Accuracy=%s' % (accuracy), fontdict={'size':20, 'color':'red'})
plt.show()
def train(model, criterion, optimizer, epochs):
for epoch in range(epochs):
output = model(inputs)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 40 == 0:
draw(output)
train(net, criterion, optimizer, 100)