Hadooop-Yarn
文章目录
- 一、Yarn资源调度器概述
-
- 1. Yarn基础架构
- 2. Yarn工作机制
- 二、Yarn调度器和调度算法
-
- 1. 先进先出调度器(FIFO)
- 2. 容量调度器(Capacity Scheduler)
- 3. 公平调度器(Fair Scheduler)
-
- 1)公平调度器与容量调度器的区别
- 2)公平调度器队列资源分配方式
-
- a. FIFO策略
- b. Fair策略
- c. DRF策略
- 三、Yarn常用命令
-
- 1. yarn application 查看任务
- 2. yarn logs 查看日志
- 3. yarn applicationattempt 查看尝试运行的任务
- 4. yarn container 查看容器
- 5. yarn node 查看节点状态
- 6. yarn rmadmin 更新配置
- 7. yarn queue 查看队列
- 四、Yarn核心参数
-
- 1. ResourceManager相关
- 2. NodeManager相关
- 3. Container相关
- 4. 案例1:参数配置
- 5. 案例2:容量调度器多队列
-
- 1)需求
- 2)配置多队列的容量调度器
- 3)刷新队列并查看
- 4)向Hive队列提交任务
- 5)任务优先级
- 6. 案例3:公平调度器案例
-
- 1)需求
- 2)配置多队列的公平调度器
- 3)测试提交任务
- 五、Tool接口
一、Yarn资源调度器概述
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
1. Yarn基础架构
YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件构成。
-
ResourceManager(RM):整个集群资源(内存、CPU等)的老大 -
NodeManager(NM):单个节点服务器资源老大 -
ApplicationMaster(AM):单个任务运行的老大 -
Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、 磁盘、网络等。

2. Yarn工作机制

- MR 程序提交到客户端所在的节点。
- YarnRunner 向 ResourceManager 申请一个 Application。
- RM 将该应用程序的资源路径返回给 YarnRunner。
- 该程序将运行所需资源提交到 HDFS 上。
- 程序资源提交完毕后,申请运行 mrAppMaster。
- RM 将用户的请求初始化成一个 Task。
- 其中一个 NodeManager 领取到 Task 任务。
- 该 NodeManager 创建容器 Container,并产生 MRAppmaster。
- Container 从 HDFS 上拷贝资源到本地。
- MRAppmaster 向 RM 申请运行 MapTask 资源。
- RM 将运行 MapTask 任务分配给另外两个 NodeManager,另两个 NodeManager 分别领取任务并创建容器。
- MR 向两个接收到任务的NodeManager发送程序启动脚本,这两个 NodeManager 分别启动 MapTask,MapTask 对数据分区排序。
- MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器,运行 ReduceTask。
- ReduceTask 向 MapTask 获取相应分区的数据。
- 程序运行完毕后,MR 会向 RM 申请注销自己。
二、Yarn调度器和调度算法
目前,Hadoop 作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.3.1 默认的资源调度器是 Capacity Scheduler。CDH 框架默认调度器是 Fair Scheduler。
具体设置详见:yarn-default.xml 文件
<property>
<description>The class to use as the resource scheduler.description>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
1. 先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
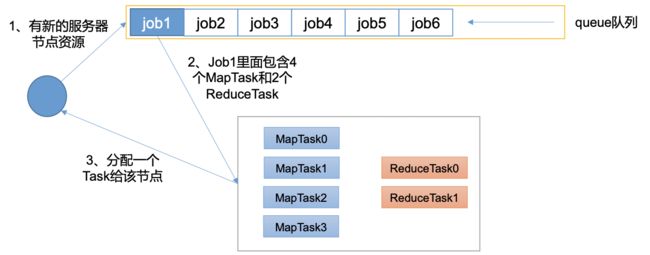
优点:简单易懂
缺点:不支持多队列,生产环境很少使用
2. 容量调度器(Capacity Scheduler)
Capacity Scheduler 是Yahoo开发的多用户调度器。
- 多队列:每个队列可配置一定的资源量,每个队列采用 FIFO 调度策略。
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。

-
队列资源分配
从 root 开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源。
-
作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源。
-
容器资源分配
按照容器的优先级分配资源;如果优先级相同,按照数据本地性原则:
- 任务和数据在同一节点
- 任务和数据在同一机架
- 任务和数据不在同一节点也不在同一机架
3. 公平调度器(Fair Scheduler)
Fair Schedulere 是 Facebook 开发的多用户调度器。
1)公平调度器与容量调度器的区别
与容量调度器相同点:
- 多队列:支持多队列多作业
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点:
-
核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比例大的缺额:

公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫缺额
-
每个队列可以单独设置资源分配方式
容量调度器:FIFO、DRF
公平调度器:FIFO、FAIR、 DRF
2)公平调度器队列资源分配方式
a. FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
b. Fair策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到 1/2 的资源;如果三个应用程序同时运行,则每个应用程序可得到 1/3 的资源。
具体资源分配流程和容量调度器一致:
- 选择队列
- 选择作业
- 选择容器
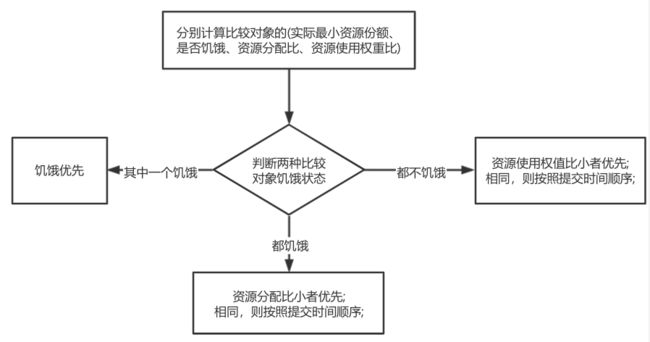
以上三步,每一步都是按照公平策略分配资源:
- 实际最小资源份额:mindshare = Min(资源需求量,配置的最小资源)
- 是否饥饿:isNeedy = 资源使用量 < mindshare(实际最小资源份额)
- 资源分配比:minShareRatio = 资源使用量 / Max(mindshare, 1)
- 资源使用权重比:useToWeightRatio = 资源使用量 / 权重
案例1:多条队列资源分配

案例2:一条队列中作业资源的分配:

c. DRF策略
DRF (Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是 Yarn 默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在 YARN 中,我们用 DRF 来决定如何调度:
假设集群一共有 100 CPU 和 10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB) 。
则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的,B是 CPU 主导的,针对这种情况,我们可以选择 DRF 策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
三、Yarn常用命令
Yarn 状态的查询,除了可以在 ResourceManager所有机器IP:8088 页面查看外,还可以通过命令操作。常见的命令操作如下所示:
1. yarn application 查看任务
列出所有 Application:
yarn application -list
根据Application状态过滤: (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
# yarn application -list -appStates Kill 掉 Application:
# yarn application -kill 2. yarn logs 查看日志
查询 Application 日志:
# yarn logs -applicationId 查询 Container 日志:
# yarn logs -applicationId -containerId
yarn logs -applicationId application_1612577921195_0001 -containerId container_1612577921195_0001_01_000001
3. yarn applicationattempt 查看尝试运行的任务
列出所有Application尝试的列表:
# yarn applicationattempt -list 打印 ApplicationAttemp 状态:
# yarn applicationattempt -status 4. yarn container 查看容器
列出所有 Container:
# yarn container -list 打印 Container 状态:
注:只有在任务跑的途中才能看到container的状态
# yarn container -status 5. yarn node 查看节点状态
列出所有节点:
yarn node -list -all
6. yarn rmadmin 更新配置
重新加载队列配置:
yarn rmadmin -refreshQueues
7. yarn queue 查看队列
打印队列信息:
# yarn queue -status 四、Yarn核心参数

1. ResourceManager相关
yarn.resourcemanager.scheduler.class:配置调度器,默认容量调度器
yarn.resourcemanager.scheduler.client.thread-count:ResourceManager处理调度器请求的线程数量,默认50
2. NodeManager相关
yarn.nodemanager.resource.detect-hardware-capabilities:是否让yarn自己检测硬件进行配置,默认false
yarn.nodemanager.resource.count-logical-processors-as-cores:是否将虚拟核数当作CPU核数,默认false
yarn.nodemanager.resource.pcores-vcores-multiplier:虚拟核数和物理核数乘数,例如:4核8线程,该参数就应设为2,默认1.0
yarn.nodemanager.resource.memory-mb:NodeManager使用内存,默认8G
yarn.nodemanager.resource.system-reserved-memory-mb:NodeManager为系统保留多少内存
以上二个参数配置一个即可
yarn.nodemanager.resource.cpu-vcores:NodeManager 使用CPU核数,默认8个
yarn.nodemanager.pmem-check-enabled:是否开启物理内存检查限制 container,默认打开
yarn.nodemanager.vmem-check-enabled:是否开启虚拟内存检查限制 container,默认打开
yarn.nodemanager.vmem-pmem-ratio:虚拟内存物理内存比例,默认2.1
3. Container相关
yarn.scheduler.minimum-allocation-mb:容器最最小内存,默认1G
yarn.scheduler.maximum-allocation-mb:容器最最大内存,默认8G
yarn.scheduler.minimum-allocation-vcores:容器最小CPU核数,默认1个
yarn.scheduler.maximum-allocation-vcores:容器最大CPU核数,默认4个
4. 案例1:参数配置
-
需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。
-
需求分析:
1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster,平均每个节点运行10个 / 3台 ≈ 3个任务(4 3 3) -
修改
yarn-site.xml配置参数如下:<property> <name>yarn.resourcemanager.scheduler.classname> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue> property> <property> <name>yarn.resourcemanager.scheduler.client.thread-countname> <value>8value> property> <property> <name>yarn.nodemanager.resource.detect-hardware-capabilitiesname> <value>falsevalue> property> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-coresname> <value>falsevalue> property> <property> <name>yarn.nodemanager.resource.pcores-vcores-multipliername> <value>1.0value> property> <property> <name>yarn.nodemanager.resource.memory-mbname> <value>4096value> property> <property> <name>yarn.nodemanager.resource.cpu-vcoresname> <value>4value> property> <property> <name>yarn.scheduler.minimum-allocation-mbname> <value>1024value> property> <property> <name>yarn.scheduler.maximum-allocation-mbname> <value>2048value> property> <property> <name>yarn.scheduler.minimum-allocation-vcoresname> <value>1value> property> <property> <name>yarn.scheduler.maximum-allocation-vcoresname> <value>2value> property> <property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> property> <property> <name>yarn.nodemanager.vmem-pmem-rationame> <value>2.1value> property> -
分发配置。
注意:如果集群的硬件资源不一致,要每个 NodeManager 单独配置
-
重启 yarn ,并且执行 wordcount 程序。
# 重启,在ResourceManager所有节点上执行 sbin/stop-yarn.sh sbin/start-yarn.sh hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output -
查看 Yarn 任务执行页面:http://hadoop103:8088/cluster/apps
查看任务:

各节点配置:

查看队列配置:

5. 案例2:容量调度器多队列
调度器默认就 1 个 default 队列,不能满足生产要求。因此需要创建多个队列:
- 按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
- 按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
创建多队列的好处:
- 防止 bug 把所有资源全部耗尽。
- 实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
1)需求
需求1:default 队列占总内存的 40%,最大资源容量占总资源 60%,hive 队列占总内存的 60%,最大资源容量占总资源 80%。
需求2:配置队列优先级
2)配置多队列的容量调度器
在 capacity-scheduler.xml 中配置如下:
-
修改 default 队列的默认配置:
<property> <name>yarn.scheduler.capacity.root.queuesname> <value>default,hivevalue> <description> The queues at the this level (root is the root queue). description> property> <property> <name>yarn.scheduler.capacity.root.default.capacityname> <value>40value> property> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacityname> <value>60value> property> -
增加 hive 队列的配置:
<property> <name>yarn.scheduler.capacity.root.hive.capacityname> <value>60value> property> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factorname> <value>1value> property> <property> <name>yarn.scheduler.capacity.root.hive.maximum-capacityname> <value>80value> property> <property> <name>yarn.scheduler.capacity.root.hive.statename> <value>RUNNINGvalue> property> <property> <name>yarn.scheduler.capacity.root.hive.acl_submit_applicationsname> <value>*value> property> <property> <name>yarn.scheduler.capacity.root.hive.acl_administer_queuename> <value>*value> property> <property> <name>yarn.scheduler.capacity.root.hive.acl_application_max_priorityname> <value>*value> property> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetimename> <value>-1value> property> <property> <name>yarn.scheduler.capacity.root.hive.default-application-lifetimename> <value>-1value> property>
3)刷新队列并查看
分发配置文件,然后重启 Yarn 或者执行 yarn rmadmin -refreshQueues 刷新队列,就可以看到两条队列:

4)向Hive队列提交任务
-
hadoop jar 的方式
# -D表示运行时改变参数值 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount -D mapreduce.job.queuename=hive /input /output -
打jar包的方式
默认的任务提交都是提交到 default 队列的。如果希望向其他队列提交任务,需要在 Driver 中声明:
public class WcDrvier { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); //设置参数 conf.set("mapreduce.job.queuename","hive"); //1. 获取一个Job实例 Job job = Job.getInstance(conf); ...... //6. 提交Job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
5)任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn 将所有任务的优先级限制为 0,若想使用任务的优先级功能,须开放该限制。
-
修改
yarn-site.xml文件,增加以下参数<property> <name>yarn.cluster.max-application-priorityname> <value>5value> property> -
分发配置,并重启Yarn
-
执行任务,指定优先级
# 正常启动任务 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 5 2000000 # 启动任务时指定优先级 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi -D mapreduce.job.priority=5 5 2000000 # 修改正在执行的任务的优先级。 # yarn application -appID-updatePriority 优先级 yarn application -appID application_1611133087930_0009 -updatePriority 5
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 5 2000000
- 求 pi(圆周率)值,采用 Quasi-Monte Carlo 算法来估算 PI 的值:https://blog.csdn.net/qq_20545159/article/details/50445560
- 参数1:运行map任务次数
- 参数2:每个map任务投掷次数
6. 案例3:公平调度器案例
1)需求
创建两个队列,分别是 test 和 test2(以用户所属组命名)。期望实现以下效果:若用户提交任务时指定队列,则任务提交到指定队列运行;若未指定队列,test 用户提交的任务到 root.group.test 队列运行,test2 提交的任务到 root.group.test2 队列运行(注:group 为用户所属组)。
公平调度器的配置涉及到两个文件,一个是 yarn-site.xml,另一个是公平调度器队列分配文件 fair-scheduler.xml(文件名可自定义)。
- 配置文件参考资料:https://hadoop.apache.org/docs/r3.3.1/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
- 任务队列放置规则参考资料:https://blog.cloudera.com/untangling-apache-hadoop-yarn-part-4-fair-scheduler-queue-basics/
2)配置多队列的公平调度器
-
修改
yarn-site.xml文件,加入以下参数<property> <name>yarn.resourcemanager.scheduler.classname> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedulervalue> <description>配置使用公平调度器description> property> <property> <name>yarn.scheduler.fair.allocation.filename> <value>/usr/local/hadoop-3.3.1/etc/hadoop/fair-scheduler.xmlvalue> <description>指明公平调度器队列分配配置文件description> property> <property> <name>yarn.scheduler.fair.preemptionname> <value>falsevalue> <description>禁止队列间资源抢占description> property> -
配置
fair-scheduler.xml<allocations> <queueMaxAMShareDefault>0.5queueMaxAMShareDefault> <queueMaxResourcesDefault>4096mb,4vcoresqueueMaxResourcesDefault> <queue name="test"> <minResources>2048mb,2vcoresminResources> <maxResources>4096mb,4vcoresmaxResources> <maxRunningApps>4maxRunningApps> <maxAMShare>0.5maxAMShare> <weight>1.0weight> <schedulingPolicy>fairschedulingPolicy> queue> <queue name="test2"> <minResources>2048mb,2vcoresminResources> <maxResources>4096mb,4vcoresmaxResources> <maxRunningApps>4maxRunningApps> <maxAMShare>0.5maxAMShare> <weight>1.0weight> <schedulingPolicy>fairschedulingPolicy> queue> <queuePlacementPolicy> <rule name="specified" create="false"/> <rule name="nestedUserQueue" create="true"> <rule name="primaryGroup" create="false"/> rule> <rule name="reject" /> queuePlacementPolicy> allocations> -
分发配置并重启Yarn
sbin/stop-yarn.sh sbin/start-yarn.sh
3)测试提交任务
-
提交任务时指定队列,按照配置规则,任务会到指定的
root.test2队列hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi -Dmapreduce.job.queuename=root.test2 1 1 -
提交任务时不指定队列,按照配置规则,当使用 test 用户提交任务时,任务会到
root.test队列
五、Tool接口
以前执行自定义的 WordCount 代码时:
$ hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver /input /output1
现在期望可以动态传参,动态修改 Configuration 中的值,结果报错,误认为是第一个参数为输入路径。
$ hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver -Dmapreduce.job.queuename=root.test /input /output1
解决办法:使用 Tool 工具,自动过滤参数并动态修改
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountYarn implements Tool {
private Configuration conf;
//核心方法
@Override
public int run(String[] args) throws Exception {
//1. 获取Job
Job job = Job.getInstance(conf, "word count");
//2. 设置jar包路径
job.setJarByClass(WordCountYarn.class);
//3. 关联Mapper和Reducer
job.setMapperClass(TokenizerMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//4. 设置Mapper输出的KV类型,如果和最终输出的KV类型一致,可以不设置
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
//5. 设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. 设置输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//7. 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//8. 提交Job
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
//变量提出来防止多次创建
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//将一行字符串分词,按照" \t\n\r\f" :空格字符、制表符、换行符、回车符和换页符分词
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int run = ToolRunner.run(conf, new WordCountYarn(), args);
System.exit(run);
}
}
再次执行,发现可以动态指定参数:
$ yarn jar wc.jar com.atguigu.yarn.WorldCountYarn -Dmapreduce.job.queuename=root.test /input /output