离线强化学习(Offline RL)系列1:离线强化学习原理入门
【更新记录】
OfflineRL推荐阅读
离线强化学习(Offline RL)系列4: (数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析
离线强化学习(Offline RL)系列4: (数据集)Offline数据集特征及对离线强化学习算法的影响
离线强化学习(Offline RL)系列3: (算法篇) AWAC算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) AWR(Advantage-Weighted Regression)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) CQL 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) TD3+BC 算法详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇) REM(Random Ensemble Mixture)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BEAR算法原理详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BCQ算法详解与实现
离线强化学习(Offline RL)系列2: (环境篇)D4RL数据集简介、安装及错误解决
离线强化学习(Offline RL)系列1: (原理篇)离线强化学习原理入门
离线强化学习(Offline RL)作为深度强化学习的子领域,其不需要与模拟环境进行交互就可以直接从数据中学习一套策略来完成相关任务,被认为是强化学习落地的重要技术之一。本文详细的阐述了强化学习到离线强化学习的发展过程,并就一些经典的问题进行了解释和说明。
1. 深度强化学习
1.1 深度强化学习简介
强化学习发展的特别早,但一直不温不火,其中Sutton老爷子早在1998年就写了强化学习领域的圣经书籍:An Introduction : Reinforcement Learning ,但也并未开启强化学习发展的新局面。直到2012年,深度学习广泛兴起,大规模的神经网络被成功用于解决自然语言处理,计算机视觉等领域,人工智能的各个方向才开始快速发展,强化学习领域最典型的就是2013年DeepMind公司的Volodymyr Mnih发表Playing Atari with Deep Reinforcement Learning(DQN技术),可以说开启了深度强化学习技术发展的新高潮,2015年该论文的加强版Human-level control through deep reinforcement learning 登上Nature, 以及2016年Nature上的AlphaGo: Mastering the game of Go with deep neural networks and tree search 充分证明了深度强化学习技术的发展潜力。
传统的强化学习和监督学习、非监督学的区别在于,后两者是通过从已标记(Label)和无标记的数据中学习一套规律(我们可以理解为学习一个函数表达式),而前者强化学习则是通过行为交互来学习一套策略,以最大化累计期望奖励,结构如图所示:
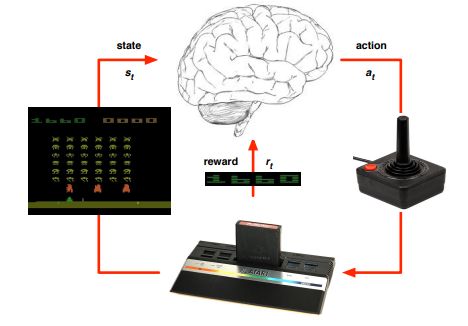
其学习过程可以归纳为通过agent获取环境状态 s s s, 根据自身学习到的知识做出action反馈给环境,并得到一个奖励,不断地迭代出一个可以一直玩游戏并且不会死的智能体。原理就是从一个四元组 < s , a , r , s ′ >
1.1.1 On-Policy和off-Policy区别
On-policy和Off-policy这两个词在强化学习领域非常重要,知乎上有很多关于其讨论强化学习中on-policy 与off-policy有什么区别?,最典型的莫过于李宏毅老师下棋形象例子解释,还可以从以下方式解释:
【补充】
两者在学习方式上的区别:
若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。
两者在采样数据利用上的区别:
On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。
Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。
其实最经典的莫过于Sutton老爷子Introduction中的解释:
原文: On-policy methods attempt to evaluate or improve the policy that is used to make decisions, whereas off-policy methods evaluate or improve a policy different from that used to generate the data.
此外莫过于Q-learning和sarsa算法的解释

最终总结一下两者的优缺点:
on-policy优点是直接了当,速度快,劣势是不一定找到最优策略。
off-policy劣势是曲折,收敛慢,但优势是更为强大和通用。
本文之所以解释On-policy或者off-policy的相关内容,目的在于后文讨论以下几个问题:
- 如何从采样轨迹(trajectory)中高效学习
- Off-policy采样效率高,收敛慢,仍然是最重要的解决问题方法
1.1.2 Online和Offline学习的本质
监督学习中通常利用已知(已标记)的数据进行学习,其本质是从数据中总结规律,这和人从学1+1=2基本原理一致,强化学习的过程也是如此,仍然是从数据中学习,只不过强化学习中学习的数据是一系列的轨迹{ < s 0 , a 0 , r 0 , s 1 > < s 1 , a 1 , r 1 , s 2 > , . . . , < s n − 1 , a n − 1 , r n − 1 , s n >
所以重点来了,这里的数据才是最关键的一部分,这也强化学习中Online和offline学习中的关键,
Online一方面是与环境有交互,通过采集数据学习、然后丢弃,而offline则是不用交互,直接通过采集到的轨迹数据学习,这也是off-policy到offline转换的重要原因。
1.2 落地应用的困难?
目前atari, mujoco物理引擎等各类游戏中的模拟数据很轻松拿到,这也就是目前强化学习在游戏领域非常成功的原因之一,也是各种state of the art刷榜的体现,因为游戏数据可以很轻松就100million,总结起来就是
有模拟器,易产生数据,好用!
但强化学习在落地过程中就可能遇到很多问题,比如下图这个大家伙,

总不可能让他产生100 million数据吧(不知道他的额定寿命是多少次),因此产生如下几个问题:
- 由于样本收集很困难,或者很危险。所以实时的和环境进行交互是不太可能的,那么可否有一种仅利用之前收集的数据来训练的方法去学习策略呢?
- 不管它是on-policy还是off_policy,我只要经验回放池中的交互历史数据,往大一点就是logg数据库中的数据(此处就不能探索exploration),去拟合函数是否可行?
- 仅利用轨迹数据学习的策略能否和Online算法的媲美?
所以有这样的方法吗?
答案:有,OfflineRL,此处有矿,赶紧来挖!
2. 离线强化学习
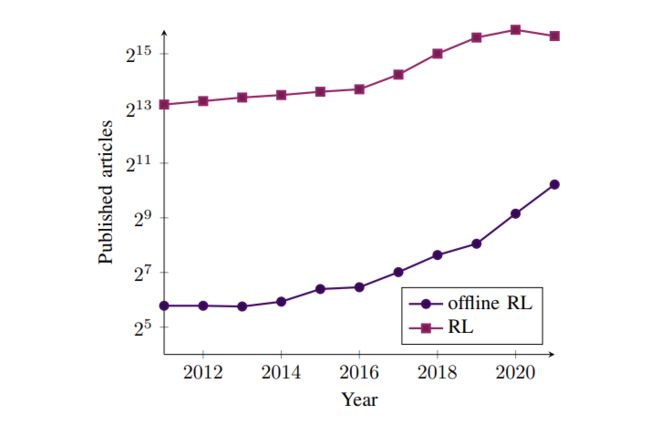
离线强化学习最初英文名为:Batch Reinforcement Learning [3], 后来Sergey Levine等人在其2020年的综述中使用了Offline Reinforcement Learning(Offline RL), 现在普遍使用后者表示。下图是离线强化学习近年来论文的发表情况,间接反应发展状态
2.1 离线强化学习原理
Offline RL 可以被定义为 data-driven 形式的强化学习问题,即在智能体(policy函数?)不和环境交互的情况下,来从获取的轨迹中学习经验知识,达到使目标最大化,其和Online的区别如图所示:
图片来源自:Offline Reinforcement Learning
后来Sergey在论文中归纳如下图所示:
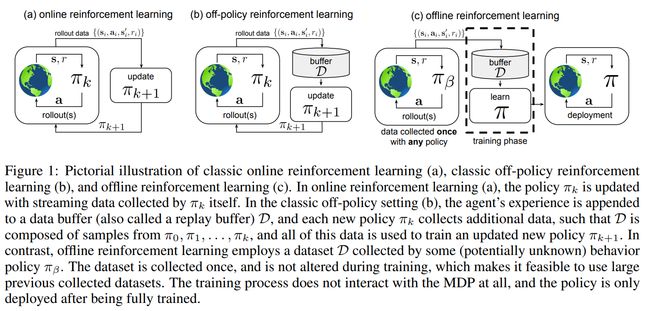
本质上,智能体是通过静态的数据集 < s t i , a t i , s t + 1 i , r t i >
J ( π ) = E τ ∼ p π ( τ ) [ ∑ t = 0 H γ r ( s t , a t ) ] J(\pi)=\mathbb{E}_{\tau \sim p_{\pi}(\tau)}\left[\sum_{t=0}^{H} \gamma r\left(s_{t}, a_{t}\right)\right] J(π)=Eτ∼pπ(τ)[t=0∑Hγr(st,at)]
2.2 离线强化学习分类及区别
2.2.1 如何判断 Offline RL
图中很明确的从数据可否store以及reused解释了是纯Online还是offline, 以及使用经验回放的NFQ等,其本质还是是否利用trajectory去学习优化模型。
备注:离线强化学习去学习数据可以使专家数据、预训练(Pre-Train)模型产生的数据、随机(random)数据等。
2.2.2 offline RL的分类

2.2.3 Offline RL&模仿学习的区别
模仿学习(Imitation Learning, IL) 是指通过从专家(通常指人类的决策数据 { τ 1 , τ 2 , … , τ m } \left\{\tau_{1}, \tau_{2}, \ldots, \tau_{m}\right\} {τ1,τ2,…,τm})提供的范例中学习,,每个决策包含状态和动作序列 τ i = < s 1 i , a 1 i , s 2 i , a 2 i , … , s n n i + 1 i > \tau_{i}=
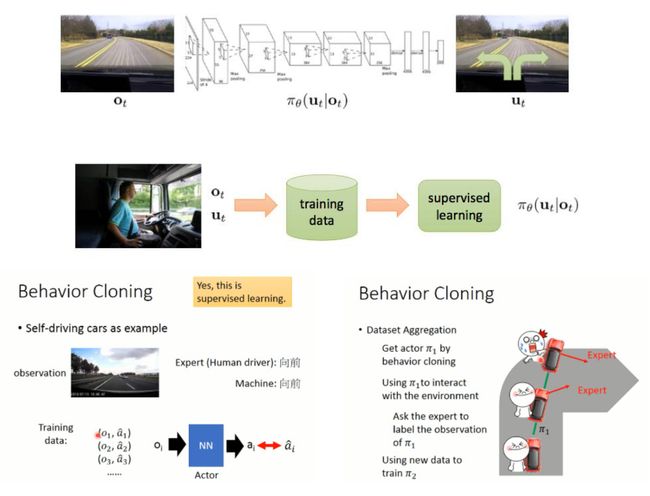
可能有人会问,模仿学习不也是从专家数据中学习一套策略吗?它和offline RL不就是一回事了?其实它们与息息相关,但有几个关键的区别:
- Offline RL 算法(到目前为止)建立在标准的off-policy深度强化学习算法之上,这些算法倾向于优化某种形式的贝尔曼方程或TD误差。
- 大多数 IL 问题假设有一个最优的,或者至少是一个高性能的提供数据的演示器,而Offline RL 可能必须处理高度次优(subopt)的数据。
- 大多数 IL 问题没有奖励函数。Offline RL 有奖励,而且可以事后处理和修改。
- 一些 IL 问题需要将数据标记为专家与非专家。Offline RL 不做这个假设(可以是专家、已训练好的模型产生的轨迹,随机数据)。
2.3 离线强化学习很难学习的原因
2.3.1 无法探索(Explore)
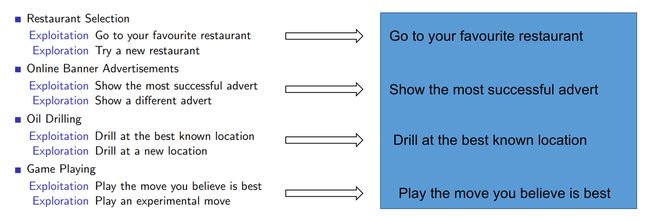
强化学习在与环境中交互学习的过程中,最关键的一个问题便是“Exploration vs Exploitation Dilemma”,
Exploration是为了收集更多信息(尝试一些不可能等),而Exploitation则根据当前信息做出最佳决策,正如Sliver总结的:

这两者可以说对一个算法的训练精度、速度等各方面有重要影响,而Offline RL算法中需要完全的依赖于静态数据集 D D D,但是没有办法提高exploration,因为不和环境进行交互,就无法知道探索得到的数据是否有效,是否有高质量的奖励反馈等,所以 Offline RL不可能通过探索发现高奖励的区域。而且,并没有办法解决此问题,这就变成了2.3.2中的经验最小化的问题了
2.3.2 数据质量(拟合与过拟合)
深度学习的成功可以归结为数据集(ImageNet等)的准确强大,offline RL也不例外,思考以下问题:
- 如果轨迹(数据)全部是专家数据,Offline RL算法会学习到好策略吗?
- 如果轨迹全是预训练好的模型(比如训练好的PPO模型)产生的,Offline RL算法会学习到好策略吗?
- 如果轨迹全是没有任何经验,而是随机产生的,Offline RL算法会学习到好策略吗?
- 如果轨迹是上述三种的混合,具体的比例多少才能训练出通用、高效的offline RL算法?
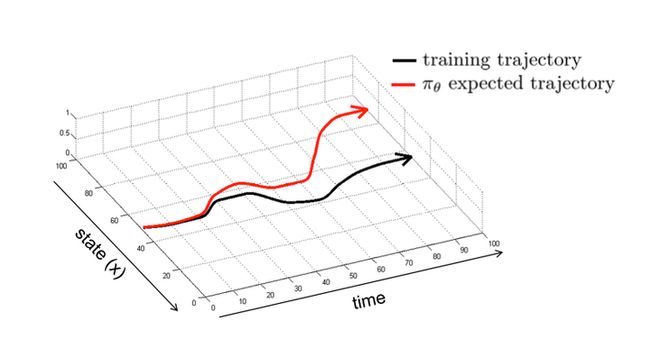
这个问题其实Fujimoto在2019年的时候就提到了(如图所示),但直到现在仍然对Offline RL算法的训练非常大的影响。

备注:
Final buffer: train a DDPG agent for 1 million time steps, adding N (0, 0.5) Gaussian noise to actions for high exploration, and store all experienced transitions.
Concurrent:train the off-policy and behavioral DDPG agents, for 1 million time steps. To ensure sufficient exploration, a standard N (0, 0.1) Gaussian noise is added to actions taken by the behavioral policy.
2.3.3 分布偏移(Distribution shift)
2.3.3.1 关于分布偏移
分布偏移(Distribution shift) 在监督学习中一般指的是训练分布与测试分布不同,在离线强化学习中指的是训练策略与行为策略不一致。(Distribution shifts, in which the training distribution differs from the testing distribution, training policy are inconsist:ent with behavioral policy in offline reinforcement learning.),下面我们进行解释
在监督学习中,训练一个模型通常追求经验风险最小化(Empirical Risk Minimization,ERM),即:
θ ← arg min θ E x ∼ p ( x ) , y ∼ p ( y ∣ x ) [ ( f θ ( x ) − y ) 2 ] \theta \leftarrow \arg \min _{\theta} E_{\mathbf{x} \sim p(\mathbf{x}), y \sim p(y \mid \mathbf{x})}\left[\left(f_{\theta}(\mathbf{x})-y\right)^{2}\right] θ←argθminEx∼p(x),y∼p(y∣x)[(fθ(x)−y)2]
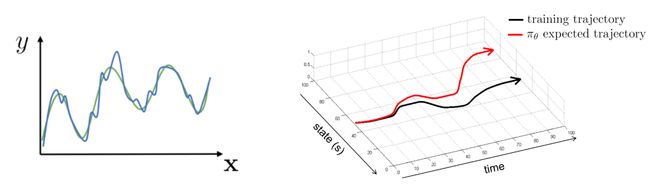
也就是让图中的左子图的平均损失函数最小化,那么这里就存在一个问题,给定一个最优的 x ∗ x^{*} x∗, 那么 f ( x ∗ ) f(x^{*}) f(x∗) 也是最优的吗?(注意这里: x ∼ p ( x ) , y ∼ p ( y ∣ x ) \mathbf{x} \sim p(\mathbf{x}), y \sim p(y \mid \mathbf{x}) x∼p(x),y∼p(y∣x))
- 如果 E x ∼ p ( x ) , y ∼ p ( y ∣ x ) [ ( f θ ( x ) − y ) 2 ] E_{\mathbf{x} \sim p(\mathbf{x}), y \sim p(y \mid \mathbf{x})}\left[\left(f_{\theta}(\mathbf{x})-y\right)^{2}\right] Ex∼p(x),y∼p(y∣x)[(fθ(x)−y)2], 则是最小的
- 如果 E x ∼ p ˉ ( x ) , y ∼ p ( y ∣ x ) [ ( f θ ( x ) − y ) 2 ] E_{\mathbf{x} \sim \bar{p}(\mathbf{x}), y \sim p(y \mid \mathbf{x})}\left[\left(f_{\theta}(\mathbf{x})-y\right)^{2}\right] Ex∼pˉ(x),y∼p(y∣x)[(fθ(x)−y)2], 则不是,因为对于普通的 p ˉ ( x ) ≠ p ( x ) \bar{p}(\mathbf{x}) \neq p(\mathbf{x}) pˉ(x)=p(x)
那么问题就变成了:如何在不同的 p ˉ ( x ) ≠ p ( x ) \bar{p}(\mathbf{x}) \neq p(\mathbf{x}) pˉ(x)=p(x) 下能够同样能够达到 E x ∼ p ( x ) , y ∼ p ( y ∣ x ) [ ( f θ ( x ) − y ) 2 ] E_{\mathbf{x} \sim p(\mathbf{x}), y \sim p(y \mid \mathbf{x})}\left[\left(f_{\theta}(\mathbf{x})-y\right)^{2}\right] Ex∼p(x),y∼p(y∣x)[(fθ(x)−y)2]
同样的情况,在Offline RL中obejctive函数则变成了:
min Q E ( s , a ) ∼ π β ( s , a ) [ ( Q ( s , a ) − ( r ( s , a ) + E a ′ ∼ π new [ Q ( s ′ , a ′ ) ] ) 2 ] \min _{Q} E_{(\mathbf{s}, \mathbf{a}) \sim \pi_{\beta}(\mathbf{s}, \mathbf{a})}\left[(Q(\mathbf{s}, \mathbf{a})- \left( r(\mathbf{s}, \mathbf{a})+E_{\mathbf{a}^{\prime} \sim \pi_{\text {new }}}\left[Q\left(\mathbf{s}^{\prime}, \mathbf{a}^{\prime}\right)\right] \right )^{2}\right] QminE(s,a)∼πβ(s,a)[(Q(s,a)−(r(s,a)+Ea′∼πnew [Q(s′,a′)])2]
其中的 π β \pi_{\beta} πβ 是我们从offline data中学习的策略, 而我们希望 π β ( a ∣ s ) = π new ( a ∣ s ) \pi_{\beta}(\mathbf{a} \mid \mathbf{s})=\pi_{\text {new }}(\mathbf{a} \mid \mathbf{s}) πβ(a∣s)=πnew (a∣s), 这样就可以达到学习目的了。
总结起来就是:别走偏了,每一步都尽量让两个分布之间距离最小化的问题,不然累计起来不知道走哪里(有点TRPO的感觉)
2.3.3.2 分布偏移对OfflineRL算法收敛的影响
对2.3.3.1中的定义 min Q E ( s , a ) ∼ π β ( s , a ) \min _{Q} E_{(\mathbf{s}, \mathbf{a}) \sim \pi_{\beta}(\mathbf{s}, \mathbf{a})} minQE(s,a)∼πβ(s,a) , 我们换种表达方式为 min Q ∑ t = 0 H \min _{Q} \sum_{t=0}^{H} minQ∑t=0H ,考虑时间步为 H H H 的情况下,在离线强化学习中误差上界和时间步之间是平方关系,直觉上造成这样的原因是因为,学习策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 可能会进入和训练分布差距很远的状态,这将导致 d π β ( s ) d^{\pi_{\beta}}(s) dπβ(s) 和 d π n e w ( s ) d^{\pi_{new}}(s) dπnew(s) 差距非常大。那么,当策略在 t t t 时刻遇到了分布之外(数据集中没见过)的状态时,策略在之后的 ( H − t ) (H-t) (H−t) 个时刻就有可能不断的犯错,所以累计误差 O ( H ) O(H) O(H),而且每一个时间步,都有可能进入分布外的状态,造成整体误差为 O ( H 2 ) O(H^{2}) O(H2), 这对于算法的收敛来说无异于雪上加霜,关于解决这个问题的BCQ、CQL等算法将来后续博客讲解!(by Sergey)
2.4 Offline RL 发展时间线
下面是一些2012年前的offline reinforcement learning算法,最新的算法将在后面博客中详解。
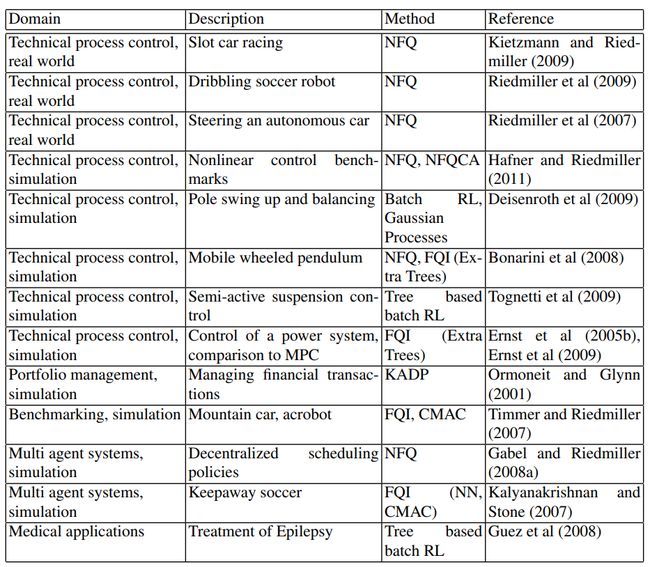
至此,关于offline RL的简介到这里,下一篇是关于offline RL 中常用(最典型)的数据集D4RL的安装过程以及其中遇到的一些坑,以及如何设计一个高效的Offline RL算法
离线强化学习(Offline RL)系列2: (环境篇)D4RL数据集简介、安装及错误解决
参考文献
[1] https://sites.google.com/view/offlinerltutorial-neurips2020/home
[2] 2nd Offline Reinforcement Learning Workshop
[3] Sascha Lange, Thomas Gabel, and Martin Riedmiller. batch reinforcement learning,2012
[4] Sergey Levine, Aviral Kumar, George Tucker, Justin Fu: “Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems”, 2020; arXiv:2005.01643.
[5] Sergey Levine, Offline Deep Reinforcement Learning Algorithms
[6] Rishabh Agarwal, Dale Schuurmans, Mohammad Norouzi: “An Optimistic Perspective on Offline Reinforcement Learning”, 2019, Proceedings of the 37th International Conference on Machine Learning, PMLR 119:104-114, 2020; arXiv:1907.04543.
[7] Offline (Batch) Reinforcement Learning: A Review of Literature and Applications
[8] Rafael Figueiredo Prudencio, Marcos R. O. A. Maximo, Esther Luna Colombini: “A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems”, 2022; arXiv:2203.01387.