Java集合之Set——HashSet详解
Java集合之Set——HashSet详解
简介
HashSet是Set接口的一个实现类,底层是一个HashMap;HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。HashSet中元素都是无序的(即存取顺序不一致);HashSet没有下标选取,只能通过增强for循环或者迭代器取出元素;HashSet是非同步的;HashSet的iterator方法返回的迭代器是fail-fast的。
源码解读
继承关系
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
结构图:
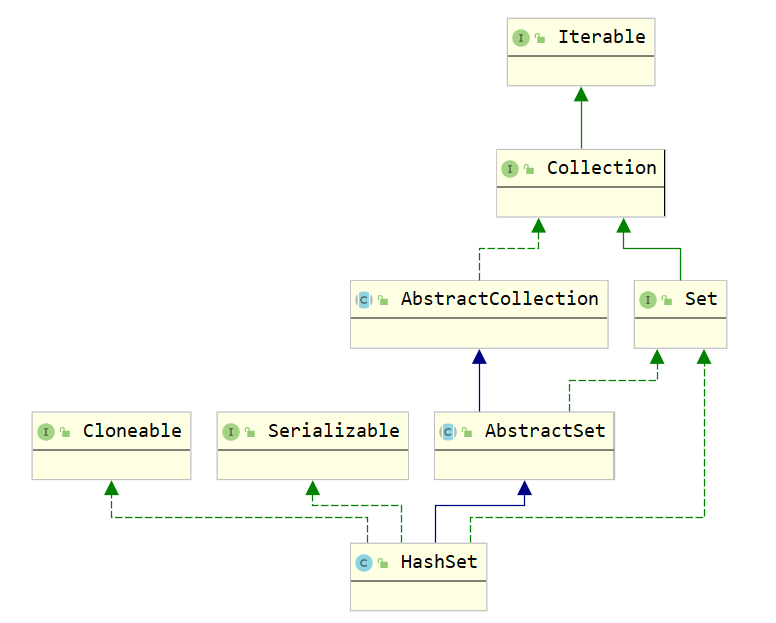
Set接口:Set接口和List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格;HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。
成员变量
仅介绍部分。
HashSet的底层由一个HashMap实现,其定义为:
private transient HashMap<E,Object> map;
构造方法
public HashSet(),无参构造方法;public HashSet(Collection c),构造一个包含指定集合中元素的新集合。public HashSet(int initialCapacity, float loadFactor)、public HashSet(int initialCapacity),这两个是根据HashMap的构造放来来定义的;HashSet(int initialCapacity, float loadFactor, boolean dummy),定义map为一个LinkedHashMap。
主要展示第二个,其余没太多好说:
public HashSet(Collection<? extends E> c) {
//HashMap的默认加载因子是0.75,构造一个足以包含指定集合中元素的初始容量的HashMap
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
分析
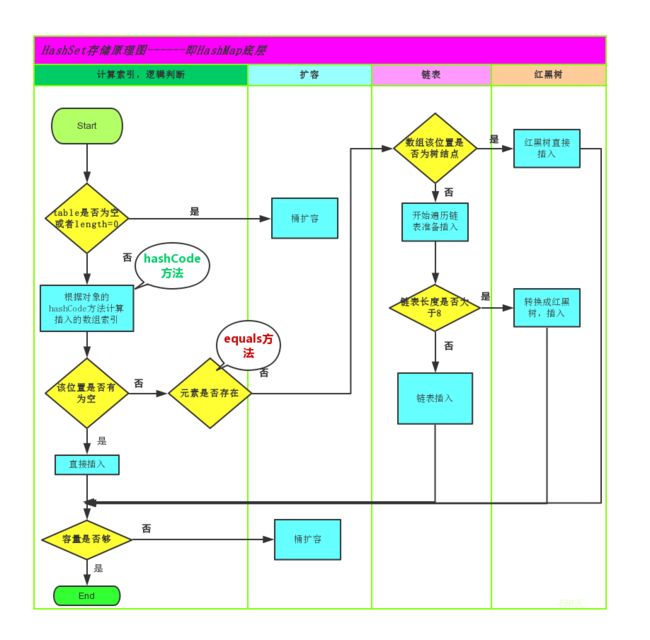
常用方法没什么好说,这里主要说一下HashSet是如何保证集合中元素唯一的。
主要是依赖于hashCode与equals两个方法,通过这两个方法可以判断元素是否重复。
当你想集合中新添加元素时,HashSet会使用对象的hashCode来寻找元素应加入的位置(应存储在HashMap中table的位置)
- 如果该位置没有元素,则假设对象没有重复出现,然后插入元素;
- 否则然后再通过
equals方法来判断该位置下是否存在元素与插入元素相等,如果无则插入集合,有则认为集合中已存在该元素。
具体流程图如下
注意:所有类hashCode与equals方法均继承于Object类,默认情况下一个对象的hashCode值与其逻辑地址有关,对于两个对象,即便内容全部相等,但是其地址不同,所以哈希值肯定不同;而对于equals方法,默认比较的也是其地址值,情况与哈希值比较相同。
所以在不重写这两个方法的情况下,我们很难得到正确的、我们想要的情况,所以我们需要对方法进行重写,对于标准库中的类它们都已经默认被重写过了(如String等),我们需要注意的是我们自定义的类,下面看一个实例:
自定义类(此时没有重写hashCode与equals方法):
public class Student {
private String sno;
private String sname;
private boolean male;
public Student(String sno, String sname, boolean male) {
this.sno = sno;
this.sname = sname;
this.male = male;
}
public Student() {
}
public void setSno(String sno) {
this.sno = sno;
}
public void setSname(String sname) {
this.sname = sname;
}
public void setMale(boolean male) {
this.male = male;
}
public String getSno() {
return sno;
}
public String getSname() {
return sname;
}
public boolean isMale() {
return male;
}
@Override
public String toString() {
return "Student{" +
"sno='" + sno + '\'' +
", sname='" + sname + '\'' +
", male=" + male +
'}';
}
}
调试函数
public class Set_stu {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student());
set.add(new Student());
set.add(new Student("1005", "John", true));
set.add(new Student("1005", "John", true));
System.out.println(set);
}
}
运行结果
[Student{sno='1005', sname='John', male=true},
Student{sno='null', sname='null', male=false},
Student{sno='null', sname='null', male=false},
Student{sno='1005', sname='John', male=true}]
显然没有得到我们预想中的结果。
重写方法之后(所添加的代码,可用编译器自动生成)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
if (male != student.male) return false;
if (sno != null ? !sno.equals(student.sno) : student.sno != null) return false;
return sname != null ? sname.equals(student.sname) : student.sname == null;
}
@Override
public int hashCode() {
int result = sno != null ? sno.hashCode() : 0;
result = 31 * result + (sname != null ? sname.hashCode() : 0);
result = 31 * result + (male ? 1 : 0);
return result;
}
此时调试结果
[Student{sno='null', sname='null', male=false},
Student{sno='1005', sname='John', male=true}]
此时便得到了正确结果。
补充
LinkedHashSet:HashSet保证元素唯一,但是元素存放进去是没有顺序的(即存取顺序不一致),如果需要保证有序,在HashSet下面有一个子类LinkedHashSet ,它是链表和哈希表组合的一个数据存储结构。
演示案例
public class LinkedHashSet_stu {
public static void main(String[] args) {
String[] arr = new String[]{"bbb", "aaa", "eeee"};
List<String> list = new ArrayList<>();
Collections.addAll(list, arr);
Set<String> set = new HashSet<>(list);
LinkedHashSet<String> linkedSet = new LinkedHashSet<>(list);
System.out.println(set);
System.out.println(linkedSet);
}
}
调试结果
[aaa, bbb, eeee]
[bbb, aaa, eeee]