Mysql数据库基本操作(六)多表查询-内连接查询,外连接查询
数据准备
use mydb3 ;
--创建部门表
create table if not exists dept3 (
deptno varchar (20) primary key , --部门号
name varchar (20 )--部门名字
);
--创建员工表
create table if not exists emp3 (
eid varchar (20) primary key , --员工编号
ename varchar(20), --员工名字
age int, --员工年龄
dept_id varchar(20)--员工所属部门
);----这里先不创建外键,方便我们解锁更多查询
insert into dept3 values ( '1001','研发部');
insert into dept3 values ( '1002','销售部');
insert into dept3 values ( '1003','财务部');
insert into dept3 values ( '1004','人事部');
insert into emp3 values ( '1','乔峰',20,'1001') ;
insert into emp3 values ( '2','段誉',21, '1001');
insert into emp3 values ( '3','虚竹',23, '1001');
insert into emp3 values ( '4','阿紫',18, '1001') ;
insert into emp3 values( '5','扫地僧',85, '1002');
insert into emp3 values ( '6','李秋水',33,'1002') ;
insert into emp3 values ( '7','鸠摩智',50,'1002') ;
insert into emp3 values ( '8','天山童姥',60, '1003');
insert into emp3 values ( '9','慕容博',58,'1003') ;
insert into emp3 values ( '10','丁春秋',71,'1005');
部门表:(dept)
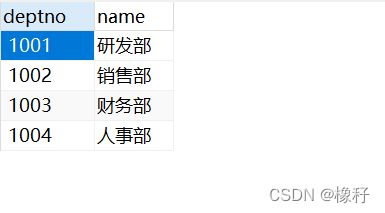
员工表:(emp)
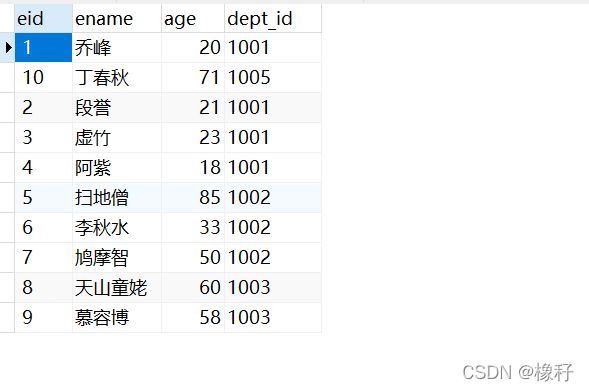
一,交叉连接查询与内连接查询
1,交叉连接查询
交叉连接查询即形成一个笛卡尔集的过程,查询语句是select *from dept3 , emp3 ;当然也可以多表查询不止两个表。后面要讲的内连接查询即是在形成的笛卡尔集上加上条件过滤的一个查询。现在先来看看笛卡尔集是什么。
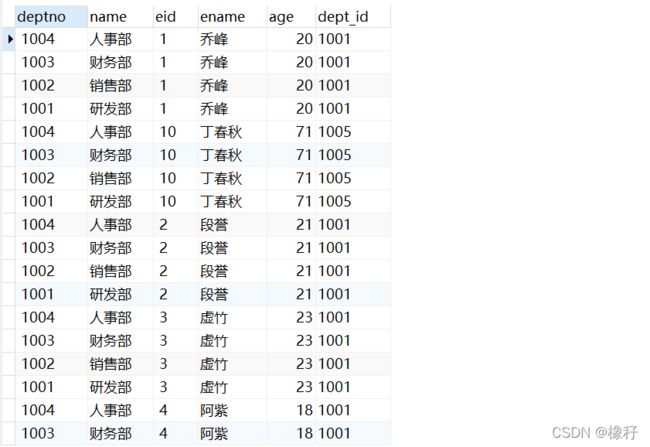
最后形成的结果在我的navicat上面要拖动才能能够显示全,所以此次截图只截图了一半,事实上他最终形成了4*9=36条数据,这是因为部门表里有4条记录,员工表里有9条记录,交叉连接查询就是第一个表中的每一条记录都和另一个表中的每一条记录去做匹配,最终形成了这样的查询结果,仔细分析一下不难发现,其实形成的这么多条记录对于我们是没什么用的,只有加上一些条件过滤以后才能够形成对我们真正有用的数据。接下来的内连接查询就是加上了一个过滤条件。这个过滤条件实际上就是两张表天生就有的关联字段,具体可以继续看下面。
2,内连接
2.1 隐式内连接
前面介绍了,内连接就是在交叉连接查询的基础上个过滤条件,这个过滤条件实际上就是两张表天生就有的关联字段,就比如使用这两个表,我们要显示所有员工的部门信息。即完美结合两张表的信息。那我们就可以在交叉连接这两个表的基础上,定义一个过滤条件为:左表的deptno字段=右表的dept_id字段。为什么我们只能定义这个过滤条件?因为这两张表设计之初就应该是员工表作为从表,从表的字段dept_id受限制于主表部门表的deptno字段。只不过我们创建表的时候没有人为地添加外键罢了。也正是因为两张各有一个字段是对应的,我们在实际应用中才有将这两个表连接起来的必要!这样的话查询语句就为select * from dept3,emp3 where dept3.deptno=emp3.dept_id;这就是内连接查询。
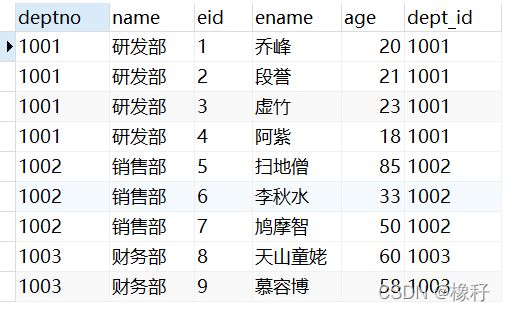
细心的朋友可能发现,员工表中的李秋水哪去了?其实仔细观察两个表不难发现,李秋水的dept_id为1005,但是部门表当中没有deptno为1005的部门,所以李秋水自然就被过滤了。除此之外,更细心的同学还能发现:部门表里面的人事部哪去了?因为员工表中没有人事部的员工,所以形成的内连接整张表自然没有人事部。
试验进行到这里我们已经完美的结合两张表了,这就是内连接。(当然忽略李秋水与人事部)
2.1.1内连接以后继续应用连接好的整张表
到了这里我们就可以基于完美结合的这一张表做更细致的查询了,比如再增添一些查询条件,再增添一些查询结果的限制group by,order by啥的,相信这不难理解。比如:
1)输出研发部的所有员工select * from dept3,emp3 where dept3.deptno=emp3.dept_id and name='研发部';这里就是在原来的基础上再加了name='研发部'而已。或者再将研发部的所有员工按照年龄大小降序排列也不难书写select * from dept3,emp3 where dept3.deptno=emp3.dept_id and name='研发部' order by age desc;
2)输出乔峰所在的部门select enname,name from dept3,emp3 where dept3.deptno=emp3.dept_id and name='乔峰';这里也不过就是在原来的基础上加了name='乔峰'这一个条件而已,另外这里我们只显示姓名和部门名,不显示其他信息,相信同学们应该能够理解。
2.2 显式内连接
前面已经讲了隐式内连接的理解步骤以及作用,其实显示内连接的理解步骤以及作用一模一样,区别仅仅就在于书写语句不一样罢了,比如前文所讲的输出研发部所有员工这一sql,隐式内连接的sql语句为:select * from dept3,emp3 where dept3.deptno=emp3.dept_id and name='研发部';而显示内连接的sql语句为:select * from dept3 inner join emp3 on dept3.deptno=emp3.dept_id and name='研发部';仔细观察,不难发现,**后一句sql的表连接关键字为inner join,而隐式内连接直接是一个“,”号。除此之外,条件语句的关键字也从where换成了on。**区别仅仅就这么大而已。
需要注意的是,显式内连接的表连接关键字inner join中的inner关键字可以省略。select * from dept3 join emp3 on dept3.deptno=emp3.dept_id and name='研发部';
二,外连接查询
外连接分为左外连接(left outer join)、右外连接(right outer join),满外连接(full outer join)outer关键字可以省略
注意:oracle里面有full join,可是mysql对full join支持的不好。我们可以使用union来达到目的。
首先让我们来讲外连接的定义:大家应该明白内连接就是在笛卡尔集+两张表设计之初就有的关联条件下形成的一整张连接表。将上面内连接的查询结果放下来如下:
但正如前面所说,部门表当中因为有人事部不存在员工,所以内连接好的一整张大表里没有人事部,而员工表中因为李秋水不在部门表的任何一个部门中,所以内连接好的一整张大表里也没有李秋水。那现在我就有两个问题
1)我们能不能要求连接好的这一整张大表里人事部也显示出来呢?即显示出所有部门的信息。即使人事部并没有员工。——这个可以用左外连接解决(将部门表放左边)。
2)或者要求这一整张大表里面李秋水的信息也显示出来,即显示出所有员工表的信息,即使李秋水没有对应的部门。——这个可以用右外连接解决(将员工表放右边)
左外连接/右外连接演示
解决第一个问题的左外连接语句如下:select * from dept3 left join emp3 on dept3.deptno=emp3.dept_id;注意关键字join与on,最终的结果如下:
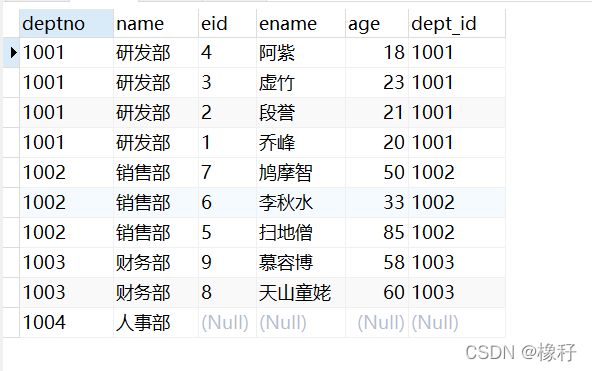
可以看到这一整张连接表比内连接表多了人事部这一行。保证了左表(部门表)的所有信息在这一整张连接表中都有体现。
解决第二个问题的右外连接语句如下:select * from dept3 right join emp3 on dept3.deptno=emp3.dept_id;注意关键字join与on。最后的查询结果如下:

如图,右外连接保证了最后形成的一整张连接表中包含了所有右表(员工表)的所有信息。
看到这里相信大家对左外连接以及右外连接都有了一个直观的感受,满外连接的用处相信大家也能猜个大概了,那就是最终形成的一整张连接表中包含了左表以及右表中的所有信息。sql语句如下:
select * from dept3 left outer join emp3 on dept3.deptno = emp3.dept_id
union
select * from dept3 right outer join emp3 on dept3.deptno = emp3.dept_id;
可以看到,满外连接的语句就是利用union关键字将左外连接以及右外连接语句合在一起了而已,最终查询结果如下:
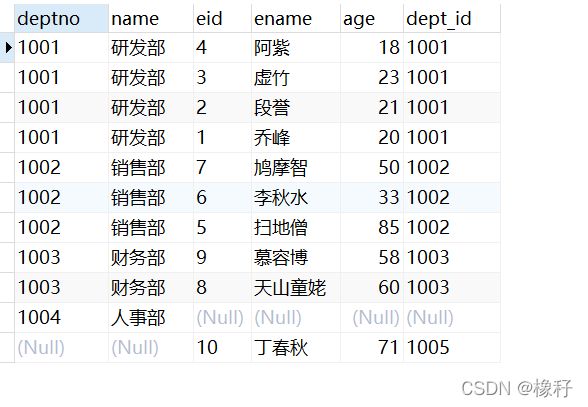
外连接以后继续应用连接好的整张表
同前面介绍的内连接以后可以继续基于完美结合的这一张表做更细致的查询一样,外连接以后形成的整张表自然也是可以继续做更细致的查询。相信这不难理解。