非关系型数据库MongoDB的特点及安装
目录
一:认识MongoDB
二:MongoDB特性
2.1文档
2.2集合
2.3数据库
2.4数据模型
三:MongoDB的优缺点
3.1MongoDB优点
3.2MongoDB缺点
四:MongoDB适用场景和特点
4.1适用场景
4.1.1更高的写负载
4.1.2保证高可用性
4.1.3未来会有一个很大的规模
4.1.4使用基于位置的数据查询
4.1.5非结构化数据的爆发增长
4.1.6缺少专业的数据库管理员
4.2MongoDB特点
4.2.1实用性
4.2.2可用性和负载均衡
4.2.3扩展性
4.2.4数据压缩
4.2.5其他特性
4.3MongoDB不适用的应用场景
五:mongodb与redis的区别
5.1内存管理机制
5.2支持的数据结构
5.3数据量和性能
5.4性能
5.5可靠性
5.6数据分析
5.7事务支持情况
5.8集群
六:搭建MongoDB
6.1关闭系统防火墙和安全机制
6.2配置yum源仓库
6.3清除元数据缓存并且加载元数据缓存
6.4安装mongodb
6.5编辑配置文件,将监听端口修改为0.0.0.0监听所有
6.6开启mongod服务,进入mongodb,查看所有数据库
6.7生成第二个实例
6.8启动新实例
6.9检测mongod端口
6.10进入新实例
七:mongoDB数据库基本操作
7.1查看mongoDB版本
7.2查看服务器内数据库
7.3创建数据库
7.4创建集合(表)、查看集合
7.5查看集合数据
7.6在集合中插入数据
7.7查看指定条件数据信息
7.8查看每个字段的数据类型
7.9更改指定条件数据
7.10删除指定数据
7.11删除集合
7.12删除数据库
八:数据库导出导入、备份恢复操作
8.1导出
8.2导入
8.3数据备份
九:复制数据库
十: 克隆集合
10.1创建多实例的数据目录
10.2日志文件目录
10.3创建日志文件,并赋权777
10.4修改多实例配置文件
10.5启动这两个实例(开启mongod服务)
10.6开始克隆
十一:扩展
11.1创建管理用户
11.2进程管理
一:认识MongoDB

MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB服务端可运行在Linux、Windows或mac os x平台,支持32位和64位应用,默认端口为27017。
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
二:MongoDB特性
2.1文档
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
多个键及其关联的值有序地放在一起就构成了文档。
MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。

{“greeting”:“hello,world”}这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。
例如:{“greeting”:“hello,world”,“foo”: 3} 文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。{“foo”: 3 ,“greeting”:“hello,world”}
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
使用文档的优点是:
- 文档(即对象)对应于许多编程语言中的本机数据类型。
- 嵌入式文档和数组减少了对昂贵连接的需求。
- 动态模式支持流畅的多态性。
2.2集合
集合就是一组文档,类似于关系数据库中的表。
集合是无模式的,集合中的文档可以是各式各样的。例如,{“hello,word”:“Mike”}和{“foo”: 3},它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。
但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。
例如,对于一个博客系统,可能包括blog.user 和blog.article 两个子集合,这样划分只是让组织结构更好一些,blog 集合和blog.user、blog.article 没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB 推荐的方法。
2.3数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。
一个MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。
MongoDB 中存在以下系统数据库。
- Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
- Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。
- Config 数据库:当MongoDB 使用分片模式时,config 数据库在内部使用,用于保存分片的信息。
2.4数据模型
一个MongoDB 实例可以包含一组数据库,一个DataBase 可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。
一个Document包含一组field(字段),每一个字段都是一个key/value pair。
- key: 必须为字符串类型。
- value:可以包含如下类型。
- 基本类型,例如,string,int,float,timestamp,binary 等类型。
- 一个document。
- 数组类型。
三:MongoDB的优缺点
3.1MongoDB优点
- 面向文档存储(类JSON数据模式简单而强大)
动态查询
全索引支持,扩展到内部对象和内嵌数组
查询记录分析
快速,就地更新
高效存储二进制大对象 (比如照片和视频)
复制和故障切换支持
Auto- Sharding自动分片支持云级扩展性
MapReduce 支持复杂聚合
商业支持,培训和咨询
3.2MongoDB缺点
- 不支持事务(进行开发时需要注意,哪些功能需要使用数据库提供的事务支持)
- MongoDB占用空间过大 (不过这个确定对于目前快速下跌的硬盘价格来说,也不算什么缺点了)
- MongoDB没有如MySQL那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方
- 在32位系统上,不支持大于2.5G的数据(很多操作系统都已经抛弃了32位版本,所以这个也算不上什么缺点了,3.4版本已经放弃支持32 位 x86平台)
四:MongoDB适用场景和特点
4.1适用场景
4.1.1更高的写负载
默认情况下,对比事务安全,MongoDB更关注高的插入速度。如果你需要加载大量低价值的业务数据,那么MongoDB将很适合你的用例。但是必须避免在要求高事务安全的情景下使用MongoDB,比如一个1000万美元的交易
4.1.2保证高可用性
设置副本集(主-从服务器设置)不仅方便而且很快,此外,使用MongoDB还可以快速、安全及自动化的实现节点(或数据中心)故障转移
4.1.3未来会有一个很大的规模
数据库扩展是非常有挑战性的,当单表格大小达到5-10GB时,MySQL表格性能会毫无疑问的降低。如果你需要分片并且分割你的数据库,MongoDB将很容易实现这一点
4.1.4使用基于位置的数据查询
MongoDB支持二维空间索引,因此可以快速及精确的从指定位置获取数据
4.1.5非结构化数据的爆发增长
给RDBMS增加列在有些情况下可能锁定整个数据库,或者增加负载从而导致性能下降,这个问题通常发生在表格大于1GB(更是下文提到BillRun系统中的痛点——单表格动辄几GB)的情况下。鉴于MongoDB的弱数据结构模式,添加1个新字段不会对旧表格有任何影响,整个过程会非常快速;因此,在应用程序发生改变时,你不需要专门的1个DBA去修改数据库模式
4.1.6缺少专业的数据库管理员
如果没有专业的DBA,同时你也不需要结构化你的数据及做join查询,MongoDB将会是你的首选。MongoDB非常适合类的持久化,类可以被序列化成JSON并储存在MongoDB。需要注意的是,如果期望获得一个更大的规模,你必须要了解一些最佳实践来避免走入误区
4.2MongoDB特点
4.2.1实用性
MongoDB是一个面向文档的数据库,它并不是关系型数据库,直接存取BSON,这意味着MongoDB更加灵活,因为可以在文档中直接插入数组之类的复杂数据类型,并且文档的key和value不是固定的数据类型和大小,所以开发者在使用MongoDB时无须预定义关系型数据库中的”表”等数据库对象,设计数据库将变得非常方便,可以大大地提升开发进度
4.2.2可用性和负载均衡
MongoDB在高可用和读负载均衡上的实现非常简洁和友好,MongoDB自带了副本集的概念,通过设计适合自己业务的副本集和驱动程序,可以非常有效和方便地实现高可用,读负载均衡。而在其他数据库产品中想实现以上功能,往往需要额外安装复杂的中间件,大大提升了系统复杂度,故障排查难度和运维成本
4.2.3扩展性
在扩展性方面,假设应用数据增长非常迅猛的话,通过不断地添加磁盘容量和内存容量往往是不现实的,而手工的分库分表又会带来非常繁重的工作量和技术复杂度。在扩展性上,MongoDB有非常有效的,现成的解决方案。通过自带的Mongos集群,只需要在适当的时候继续添加Mongo分片,就可以实现程序段自动水平扩展和路由,一方面缓解单个节点的读写压力,另外一方面可有效地均衡磁盘容量的使用情况。整个mongos集群对应用层完全透明,并可完美地做到各个Mongos集群组件的高可用性
4.2.4数据压缩
自从MongoDB 3.0推出以后,MongoDB引入了一个高性能的存储引擎WiredTiger,并且它在数据压缩性能上得到了极大的提升,跟之前的MMAP引擎相比,压缩比至少可增加5倍以上,可以极大地改善磁盘空间使用率
4.2.5其他特性
相比其他关系型数据库,MongoDB引入了”固定集合”的概念。所谓固定集合,就是指整个集合的大小是预先定义并固定的,内部就是一个循环队列,假如集合满了,MongoDB后台会自动去清理旧数据,并且由于每次都是写入固定空间,可大大地提升写入速度。这个特性就非常适用于日志型应用,不用再去纠结日志疯狂增长的清理措施和写入效率问题。另外需要更加精细的淘汰策略设置,还可以使用TTL索引(time-to-live index),即具有生命周期的索引,它允许为每条记录设置一个过期时间,当某条记录达到它的设置条件时可被自动删除
在某些LBS的应用中,使用MongoDB也有非常巨大的优势。MongoDB支持多种类型的地理空间索引,支持多种不同类型的地理空间查询,比如intersection,within和nearness等
4.3MongoDB不适用的应用场景
在某些场景下,MongoDB作为一个非关系型数据库有其局限性。MongoDB不支持事务操作,所以需要用到事务的应用建议不用MongoDB,另外MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB
五:mongodb与redis的区别
MongoDB和Redis都是NoSQL,采用结构型数据存储。二者在使用场景中,存在一定的区别,这也主要由于二者在内存映射的处理过程,持久化的处理方法不同。MongoDB建议集群部署,更多的考虑到集群方案,Redis更偏重于进程顺序写入,虽然支持集群,也仅限于主-从模式
| 指标 | MongoDB(v2.4.9) | Redis(v2.4.17) | 比较说明 |
| 实现语言 | C++ | C/C++ | - |
| 协议 | BSON、自定义二进制 | 类Telnet | - |
| 性能 | 依赖内存,TPS较高 | 依赖内存,TPS非常高 | Redis优于MongoDB |
| 可操作性 | 丰富的数据表达、索引;最类似于关系数据库,支持丰富的查询语言 | 数据丰富,较少的IO | MongoDB优于Redis |
| 内存及存储 | 适合大数据量存储,依赖系统虚拟内存管理,采用镜像文件存储;内存占有率比较高,官方建议独立部署在64位系统(32位有最大2.5G文件限制,64位没有改限制) | Redis2.0后增加虚拟内存特性,突破物理内存限制;数据可以设置时效性,类似于memcache | 不同的应用角度看,各有优势 |
| 可用性 | 支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制 | 依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制;不支持自动sharding,需要依赖程序设定一致hash机制 | MongoDB优于Redis;单点问题上,MongoDB应用简单,相对用户透明,Redis比较复杂,需要客户端主动解决。(MongoDB 一般会使用replica sets和sharding功能结合,replica sets侧重高可用性及高可靠性,而sharding侧重于性能、易扩展) |
| 可靠性 | 从1.8版本后,采用binlog方式(MySQL同样采用该方式)支持持久化,增加可靠性 | 依赖快照进行持久化;AOF增强可靠性;增强可靠性的同时,影响访问性能 | MongoDB优于Redis |
| 一致性 | 不支持事物,靠客户端自身保证 | 支持事物,比较弱,仅能保证事物中的操作按顺序执行 | Redis优于MongoDB |
| 数据分析 | 内置数据分析功能(mapreduce) | 不支持 | MongoDB优于Redis |
| 应用场景 | 海量数据的访问效率提升 | 较小数据量的性能及运算 | MongoDB优于Redis |
5.1内存管理机制
Redis数据:全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的LRU 算法删除数据。MongoDB数据:存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘
5.2支持的数据结构
Redis支持的数据结构丰富,包括hash、set、list等 MongoDB数据结构比较单一,但是支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
5.3数据量和性能
当物理内存够用的时候,redis>mongodb>mysql当物理内存不够用的时候,redis和mongodb都会使用虚拟内存。 redis要开始虚拟内存,那很明显要么加内存条,要么你换个数据库了。 mongodb不一样,只要,业务上能保证,冷热数据的读写比,使得热数据在物理内存中,mmap的交换较少。mongodb还是能够保证性能
5.4性能
mongodb依赖内存,TPS较高;Redis依赖内存,TPS非常高。性能上Redis优于MongoDB
5.5可靠性
mongodb从1.8版本后,采用binlog方式(MySQL同样采用该方式)支持持久化,增加可靠性;Redis依赖快照进行持久化;AOF增强可靠性;增强可靠性的同时,影响访问性能。可靠性上MongoDB优于Redis
5.6数据分析
mongodb内置数据分析功能(mapreduce);而Redis不支持
5.7事务支持情况
Redis 事务支持比较弱,只能保证事务中的每个操作连续执行;mongodb不支持事务
5.8集群
MongoDB 集群技术比较成熟,Redis从3.0开始支持集群
六:搭建MongoDB
6.1关闭系统防火墙和安全机制
systemctl stop firewalld.service
setenforce 0
6.2配置yum源仓库
推荐使用yum源头安装方式,便于管理
vim /etc/yum.repos.d/mongodb-org.repo
[mongodb-org]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.6/x86_64
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.6.asc
6.3清除元数据缓存并且加载元数据缓存
yum clean all
yum makecache
6.4安装mongodb
yum -y install mongodb-org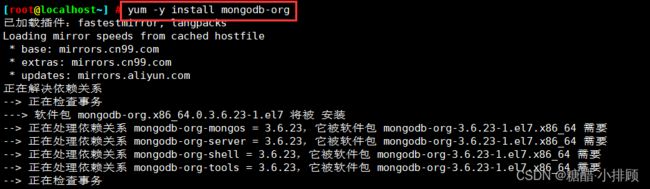
6.5编辑配置文件,将监听端口修改为0.0.0.0监听所有
vim /etc/mongod.conf
10 path: /var/log/mongodb/mongod.log #系统日志文件存放位置
14 dbPath: /var/lib/mongo #数据存储位置
24 pidFilePath: /var/run/mongodb/mongod.pid #进程管理,pid文件存放位置
25 timeZoneInfo: /usr/share/zoneinfo
26
27 # network interfaces
28 net:
29 port: 27017 #默认端口号
30 bindIp: 127.0.0.1 # Listen to local interface only, comment to listen on all interface s. #监听地址,监听所有人0.0.0.0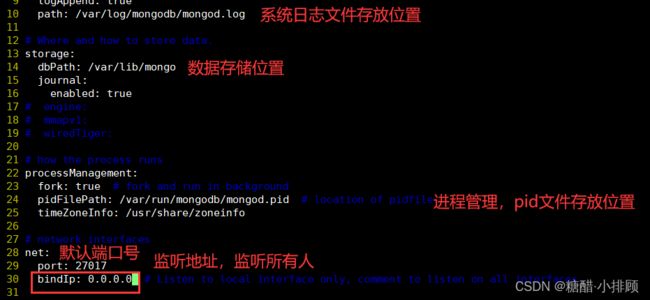
6.6开启mongod服务,进入mongodb,查看所有数据库
#开启mongod服务
systemctl start mongod.service
#进入mongodb
mongo
#查看所有数据库
show dbs
#退出
exit
6.7生成第二个实例
cd /etc
cp -p mongod.conf mongod2.conf
vim mongod2.conf

mkdir -p /data/mongodb
touch /data/mongodb/mongod2.log
mkdir -p /data/mongodb/mongo
6.8启动新实例
mongod -f /etc/mongod2.conf
6.9检测mongod端口
netstat -natp | grep mongod
6.10进入新实例
mongo --port 27018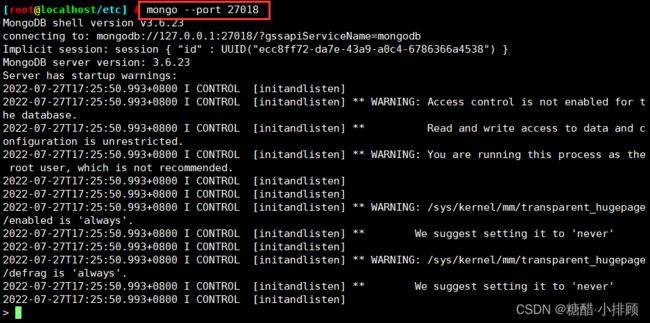
七:mongoDB数据库基本操作
7.1查看mongoDB版本
db.version()![]()
7.2查看服务器内数据库
show dbs
7.3创建数据库
mongoDB数据库创建直接使用use即可,如果不在库内创建集合,退出时自动删除该库
use school![]()
7.4创建集合(表)、查看集合
是json格式,以键值对方式存储
db.createCollection('集合名') #此时show dbs,school库就会出现
#查看集合
show tables
或
show collections
7.5查看集合数据
db.集合名.find()
#条件可写在()内,不写默认查看全部,一页最多显示20条,按it继续查看7.6在集合中插入数据
在集合中插入数据,json格式,键值对,字符串加双引号
db.abc.insert({"id":1,"name":"zhangsan","hobby":"talk"})
db.abc.find()
#循环插入,+号可以连接字符串,直接将+号后面的内容转换为字符串衔接
for(i=2;i<=100;i++) db.abc.insert({"id":i,"name":"zhangsan"+i,"hobby":"talk"+i})
db.abc.find()7.7查看指定条件数据信息
#横向查看指定条件数据信息
db.abc.find({"id":1})
#竖向查看指定条件数据信息
db.abc.findOne({"id":1})
7.8查看每个字段的数据类型
#查看每个字段的数据类型,例:可以为第一条数据加一个别名
a=db.abc.findOne({"id":1})
typeof(a.id)
typeof(a.name)
typeof(a.hobby)
-------------------------
> typeof(a.id)
number
> typeof(a.name)
string
> typeof(a.hobby)
string
-------------------------7.9更改指定条件数据
db.abc.update({"id":10},{$set:{"name":"tomcat"}})
-------------------------
> db.abc.find({"id":10})
{ "_id" : ObjectId("60707e5cc0f72922431300e6"), "id" : 10, "name" : "tomcat", "hobby" : "talk10" }
-------------------------7.10删除指定数据
db.adc.remove({})7.11删除集合
例:先创建一个新的集合,我们之前的abc后面要用
db.createConllection('qwe')
show tables
show collections
db.qwe.drop()7.12删除数据库
#删除数据库,首先进这个要删的数据库,然后db.dropDatabase()
例:
use myschool
db.createCollection('wawa')
show dbs
db.dropDatabase()
show dbs八:数据库导出导入、备份恢复操作
8.1导出
===============
导出 mongoexport
===============
exit
#命令行模式下,-d指定数据库,-c指定数据表,-o表示输出
mongoexport -d school -c abc -o /opt/lic.json
#此时cat /opt/lic.json,你会发现空的
cat /opt/lic.json
#因为,正常情况都是默认端口27017的库优先级高,所以指定端口不要忘
mongoexport --port 27018 -d school -c abc -o /opt/lic.json
cat /opt/lic.json8.2导入
===============
导入 mongoimport
===============
#导入的库和表都可以不存在
mongoimport --port 27018 -d wajueji -c qwe --file /opt/lic.json
#验证
mongo --port 27018
show dbs
use wajueji
show tables
db.qwe.find()
===============
指定条件 导出
===============
exit
#-q指定条件,eq等于、ne不等于、gt大于、lt小于、ge大于等于、le小于等于,都可以使用
mongoexport --port 27018 -d school -c abc -q '{"id":{"$eq":10}}' -o /opt/10.json
cat /opt/10.json8.3数据备份
==============
数据备份
==============
mkdir /backup
#使用mongodump -d指定要保存的库,同理-c指定要保存的库中表
mongodump --port 27018 -d school -o /backup
cd /backup
ls
cd school
ls
保存的类型:bson
=============
恢复还原
=============
mongorestore --port 27018 -d lic --dir=/backup/school九:复制数据库
例:
mongo --port 27018
#将school数据库复制为share数据库
db.copyDatabase("school","share")
show tables
show collections十: 克隆集合
10.1创建多实例的数据目录
例:
exit
#再创建两个实例,后面要用到
#创建多实例的数据目录
mkdir -p /data/mongodb/mongodb{13,4}
10.2日志文件目录
mkdir -p /data/mongodb/logs10.3创建日志文件,并赋权777
cd /data/mongodb/logs
touch mongodb{3,4}.log
chmod 777 *10.4修改多实例配置文件
cd /etc
cp -p mongod.conf mongod3.conf
cp -p mongod.conf mongod4.conf
vim mongod3.conf
10 path: /data/mongodb/logs/mongodb3.log
14 dbPath: /data/mongodb/mongodb3
29 port: 27019
vim mongod4.conf
10 path: /data/mongodb/logs/mongodb4.log
14 dbPath: /data/mongodb/mongodb4
29 port: 2702010.5启动这两个实例(开启mongod服务)
#启动这两个实例(开启mongod服务)
mongod -f /etc/mongod3.conf
mongod -f /etc/mongod4.conf
#查看端口
netstat -natp | grep mongod
tcp 0 0 0.0.0.0:27019 0.0.0.0:* LISTEN 33082/mongod
tcp 0 0 0.0.0.0:27020 0.0.0.0:* LISTEN 33693/mongod
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN 1122/mongod
tcp 0 0 0.0.0.0:27018 0.0.0.0:* LISTEN 2378/mongod
10.6开始克隆
#开始克隆
#这里进入27019
mongo --port 27019
#克隆来自192.168.137.20:27018服务中的school库中的abc表
db.runCommand({"cloneCollection":"school.abc","from":"192.168.137.20:27018"})
#验证
show dbs
use school
show tables
db.abc.find()十一:扩展
11.1创建管理用户
mongoDB中自带一个admin库
在这个库中创建
例:
use admin
#创建用户,用户名:root,密码:123123,身份:管理员
db.createUser({"user":"root","pwd":"123123","roles":["root"]})
show tables
#使用db.auth("root","123123")进行验证,成功返回1,失败返回0
11.2进程管理
db.currentOp()
"opid" : 26345,
#其中一大段中,关注opid,如果想结束这个进程就,db.killOp(26345)即可
#但是关闭这个进程不代表退出数据库,相当于将当前进程初始化释放,关了之后又开启了,相当于一个优化操作