【TiDB】txt文档导入数据库,这样做真的很高效
目录
-
- 一、前言
- 二、TiDB 集群的准备
-
- 1、避免写热点
-
- 1.1针对新表的数据插入,我们可以在创建表结构的时候,增加两个参数
- 1.2对于导入追加数据的场景,已有表结构并有历史数据时,需要手动切分region
- 2、避免大事务导致的 OOM
- 三、文件导入测试
-
- 1.导入工具的选择
-
- 1.1 Navicat
- 1.2 load data
- 1.3 Lightning
- 2.数据准备
- 3.TiDB 集群准备
- 4\. 测试结果
- 5\. 测试结果分析
- 四、总结
一、前言
在项目中,我们经常会遇到数据导入的需求,例如把 txt 或者 csv 文件中的数据导入到 TiDB 集群当中。这本来是一件简单的事,直到某个银行项目中,客户给导入数据的时间,限制了一个非常短的期限,无形中让我增加了一些压力。我这才考虑到,在某些业务中,这类以文件的方式下发的数据,是要在极短的时间内,完成数据库导入工作的。所以我才着手研究该如何更快、更加安全的把数据导入到 TiDB 中。
二、TiDB 集群的准备
在导入数据之前,TiDB 当然是需要准备一下啦~
万一出现写热点,或者事务过大导致导入过慢、甚至失败,进而导致规定时间内,数据没有导入完成,那岂不是尴了大尬。。。
1、避免写热点
在大量数据插入场景中,大概率会出现写热点的情况,针对这种情况,我们必须提前做好对应。
1.1针对新表的数据插入,我们可以在创建表结构的时候,增加两个参数
-
SHARD_ROW_ID_BITS

-
pre_split_regions

示例:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
) shard_row_id_bits = 4 pre_split_regions = 4;
1.2对于导入追加数据的场景,已有表结构并有历史数据时,需要手动切分region
我们可以使用 split-table-region 的方法来处理写热点的问题。
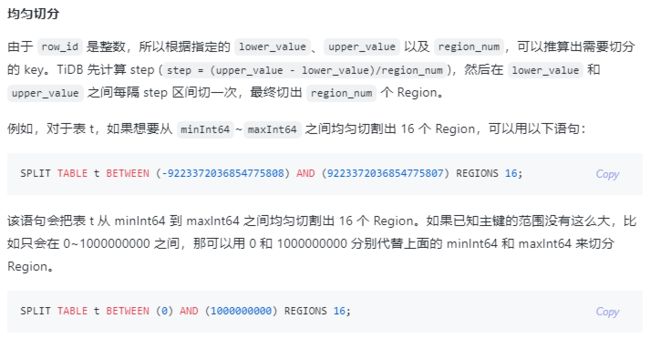
需要注意的是,建表语句增加了 shard_row_id_bits 和 pre_split_regions 参数后,需要尽快开始向目标表导入数据,不然分割的空 region 可能会被 merge,导致出现写热点的问题。
解决好写热点问题之后,还需要考虑大量数据的插入,可能导致 TiDB 出现 OOM 的情况。
2、避免大事务导致的 OOM
在 TiDB 集群中,插入数据时,每条数据都会占用 tidb-server 节点的内存,当一个事务中插入的数据量过大,就会导致 tidb-server 节点使用过大的内存,出现 OOM 的情况。要解决大事务的问题,需要开启一下几个参数:
-
在拓扑文件中加入:
enable-batch-dml: true -
SET @@GLOBAL.tidb_dml_batch_size = 20000; -
SET @@SESSION.tidb_batch_insert = 1;
这三个参数需要配合使用,表示在一个 insert 的事务中,TiDB 会在内部把一个 insert 的大事务,按 20000 条数据拆分成一个个小事务分批提交,这样就很好的避免了 tidb-server 节点 OOM 的情况,但是这样做会有一定的问题:无法保证 TiDB 的原子性和隔离性要求,所以不推荐。这个需要大家根据自己的实际情况进行选择。
三、文件导入测试
1.导入工具的选择
1.1 Navicat
有非常好的交互界面,用户学习成本几乎是0,直接可以上手导入数据,Navicat 内部会对文件中的数据分批执行,速度也不慢,但是只能在windows系统中操作。
1.2 load data
Mysql 中的常规批量导入方式,可以指定十六进制分隔符,TiDB 中除 LOAD DATA...REPLACE INTO 语法之外,LOAD DATA 语句应该完全兼容 MySQL。
1.3 Lightning
非常推荐的一款逻辑批量导入数据的工具,直接把数据转换成键值对,并插入到 TiKV 中,所以这样导入数据理论上是最快的,但是使用 lightning 也有一些不方便的地方,比如多次导入需要频繁修改配置文件,文件名称必须是“库名.表名”的形式,不能导入 txt 文件数据,如果导入失败需要手动修改 TiKV 集群为普通模式等等。
2.数据准备
这次测试我准备了四个不同数据量的 csv 文件,文件大小在 100MB 到 11GB :
表结构为:
CREATE TABLE `sbtest` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) /*T![clustered_index] NONCLUSTERED */,
KEY `k_1` (`k`)
) shard_row_id_bits = 4 pre_split_regions = 4 ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
3.TiDB 集群准备
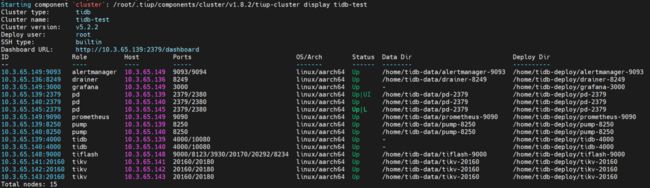
每台机器配置都是 8 vCore,32G内存,千兆带宽。配置有限,所有测试都在这个集群环境中进行测试。
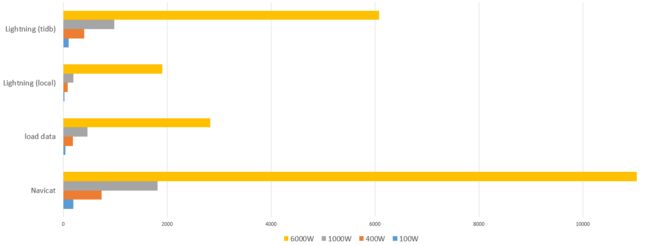
4. 测试结果
| Navicat | load data | Lightning (local) | Lightning (tidb) | |
|---|---|---|---|---|
| 100W | 195.91(秒) | 42.23(秒) | 24.76(秒) | 103.14(秒) |
| 400W | 732.47(秒) | 180.99(秒) | 87.01(秒) | 399.44(秒) |
| 1000W | 1811.8(秒) | 463.42(秒) | 190.71(秒) | 978.6(秒) |
| 6000W | 11041.87(秒) | 2831.83(秒) | 1908.05(秒) | 6081.39(秒) |
5. 测试结果分析
1、除了用 Lightning 的 local 模式导入数据,其他导入方式或多或少都会有写热点出现。
2、使用 Navicat 导入数据,对磁盘资源消耗要远远高于其他方式,且速度是最慢的。
3、load data 的导入方式,对现有资源消耗并不高,想提高导入效率,只能手动并行导入数据。
4、Lightning 的 local 模式导入数据速度最快,对集群的资源消耗最小。
5、Lightning 的 tidb 模式对资源的消耗与 load data 的导入方式相似,但是效率低于 load data 的导入方式。
6、导入过程中,TiDB 集群使用内存无异常,均未出现 OOM 的情况。
7、单个文件太大,会影响 Lightning 的 local 模式对文件的处理效率。
8、Lightning 的 local 模式对 Lightning 所在机器的 CPU、硬盘和集群网络要求较高。
9、Lightning 读取文件名时,文件名的大小写要与目标表的表名完全一致,否则 Lightning 会报错。
四、总结
-
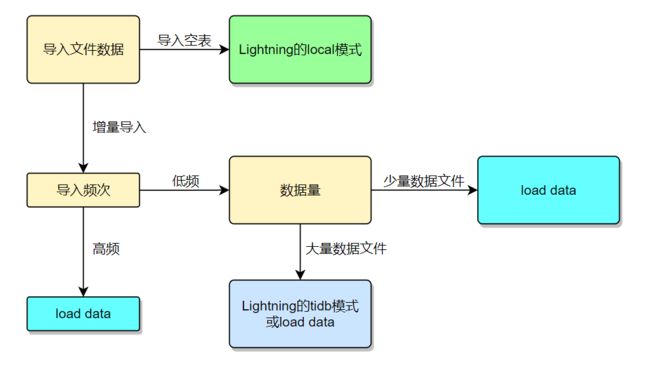
Lightning 限制较多,但是功能也是最全的,local 模式的导入速度吊打其他导入工具。
-
load data 支持 txt 文件数据的导入,而且也能自定义一些常规参数,比如字段分隔符等,导入速度仅次于 Lightning 的 local 模式。基于 load data 开发一个符合业务需求的脚本,要比直接用 Lightning 开发简单的多。
-
针对需要用到 Lightning 的功能,而且是增量数据导入的话,建议使用 Lightning 的 tidb 模式。
-
Navicat 只推荐给初学者导入少量数据使用。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,后台回复TiDB,加入TiDB技术交流群!