PyG搭建GAT实现节点分类
目录
- 前言
- 模型搭建
-
- 1. 前向传播
- 2. 反向传播
- 3. 训练
- 4. 测试
- 实验结果
- 完整代码
前言
GAT的原理比较简单,具体请见:ICLR 2018 | GAT:图注意力网络
模型搭建
首先导入包:
from torch_geometric.nn import GATConv
模型参数:

- in_channels:输入通道,比如节点分类中表示每个节点的特征数。
- out_channels:输出通道,最后一层GCNConv的输出通道为节点类别数(节点分类)。
- heads:多头注意力机制中的头数。
- concat:如果为True,会将多个注意力机制的结果进行拼接,否则求平均。
- negative_slope:LeakyRELU的参数。
- add_self_loops:如果为False不再强制添加自环,默认为True。
- bias:默认添加偏置。
于是模型搭建如下:
class GAT(torch.nn.Module):
def __init__(self, in_feats, h_feats, out_feats):
super(GAT, self).__init__()
self.conv1 = GATConv(in_feats, h_feats, heads=8, concat=False)
self.conv2 = GATConv(h_feats, out_feats, heads=8, concat=False)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = F.softmax(x, dim=1)
return x
输出一下模型:
GAT(
(conv1): GATConv(3703, 64, heads=8)
(conv2): GATConv(64, 6, heads=8)
)
1. 前向传播
查看官方文档中GATConv的输入输出要求:
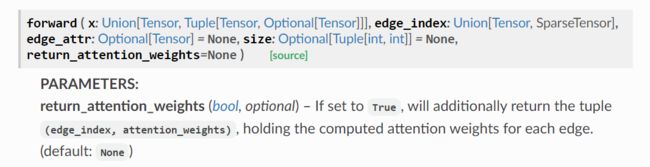
可以发现,GATConv中需要输入的是节点特征矩阵x和邻接关系edge_index,还有一个可选项edge_weight。因此我们首先:
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
此时我们不妨输出一下x及其size:
tensor([[0.0000, 0.1630, 0.0000, ..., 0.0000, 0.0488, 0.0000],
[0.0000, 0.2451, 0.1614, ..., 0.0000, 0.0125, 0.0000],
[0.1175, 0.0262, 0.2141, ..., 0.2592, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.1825, 0.0000],
[0.0000, 0.1024, 0.0000, ..., 0.0498, 0.0000, 0.0000],
[0.0000, 0.3263, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
device='cuda:0', grad_fn=<FusedDropoutBackward0>)
torch.Size([3327, 64])
此时的x一共3327行,每一行表示一个节点经过第一层卷积更新后的状态向量。
那么同理,由于:
self.conv2 = GATConv(h_feats, out_feats, heads=8, concat=False)
所以经过第二层卷积后:
x = self.conv2(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
此时得到的x的size应该为:
torch.Size([3327, 6])
即每个节点的维度为6的状态向量。
由于我们需要进行6分类,所以最后需要加上一个softmax:
x = F.softmax(x, dim=1)
dim=1表示对每一行进行运算,最终每一行之和加起来为1,也就表示了该节点为每一类的概率。输出此时的x:
tensor([[0.1607, 0.1727, 0.1607, 0.1607, 0.1607, 0.1846],
[0.1654, 0.1654, 0.1654, 0.1654, 0.1654, 0.1731],
[0.1778, 0.1622, 0.1733, 0.1622, 0.1622, 0.1622],
...,
[0.1659, 0.1659, 0.1659, 0.1704, 0.1659, 0.1659],
[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667],
[0.1641, 0.1641, 0.1658, 0.1766, 0.1653, 0.1641]], device='cuda:0',
grad_fn=<SoftmaxBackward0>)
2. 反向传播
在训练时,我们首先利用前向传播计算出输出:
out = model(data)
out即为最终得到的每个节点的6个概率值,但在实际训练中,我们只需要计算出训练集的损失,所以损失函数这样写:
loss = loss_function(out[data.train_mask], data.y[data.train_mask])
然后计算梯度,反向更新!
3. 训练
训练时返回验证集上表现最优的模型:
def train(model, data):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)
loss_function = torch.nn.CrossEntropyLoss().to(device)
scheduler = StepLR(optimizer, step_size=10, gamma=0.5)
min_epochs = 10
min_val_loss = 5
best_model = None
model.train()
for epoch in range(200):
out = model(data)
optimizer.zero_grad()
loss = loss_function(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
scheduler.step()
# validation
val_loss = get_val_loss(model, data)
if val_loss < min_val_loss and epoch + 1 > min_epochs:
min_val_loss = val_loss
best_model = copy.deepcopy(model)
print('Epoch {:03d} train_loss {:.4f} val_loss {:.4f}'.format(epoch, loss.item(), val_loss))
return best_model
4. 测试
我们首先需要算出模型对所有节点的预测值:
model(data)
此时得到的是每个节点的6个概率值,我们需要在每一行上取其最大值:
model(data).max(dim=1)
输出一下:
torch.return_types.max(
values=tensor([0.9100, 0.9071, 0.9786, ..., 0.4321, 0.4009, 0.8779], device='cuda:0',
grad_fn=<MaxBackward0>),
indices=tensor([3, 1, 5, ..., 3, 1, 5], device='cuda:0'))
返回的第一项是每一行的最大值,第二项为最大值在这一行中的索引,我们只需要取第二项,那么最终的预测值应该写为:
_, pred = model(data).max(dim=1)
然后计算预测精度:
correct = int(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())
acc = correct / int(data.test_mask.sum())
print('GCN Accuracy: {:.4f}'.format(acc))
实验结果
数据集采用Citeseer网络,训练200轮,分类正确率为71.5%。
完整代码
代码地址:GNNs-for-Node-Classification。原创不易,下载时请给个follow和star!感谢!!