机器学习分析预测新冠数据,实现GUI界面
机器学习分析预测新冠数据,实现GUI界面
- 前言
-
- 简介
- 效果图预览
- 整体思路
- 整体代码
- 参考资料引用
前言
这次小项目主要是对前段时间学习成果的一次集中展现,新人博主,欢迎指导。
简介
本代码通过分析近88天的疫情数据,将确诊病例数、在国家、地区两个维度进行了可视化展示,并且使用多项式回归和logistic回归对未来的确诊人数进行预测,本代码,使用到了numpy 、panda和datetime处理数据,sklearn建立相应的数学模型, matplotlib绘制图, tkinter制作GUI界面。
time_series_covid19_confirmed_global.csv文件记录了截止到4月19日的新型肺炎确诊情况 最新数据源文件
效果图预览
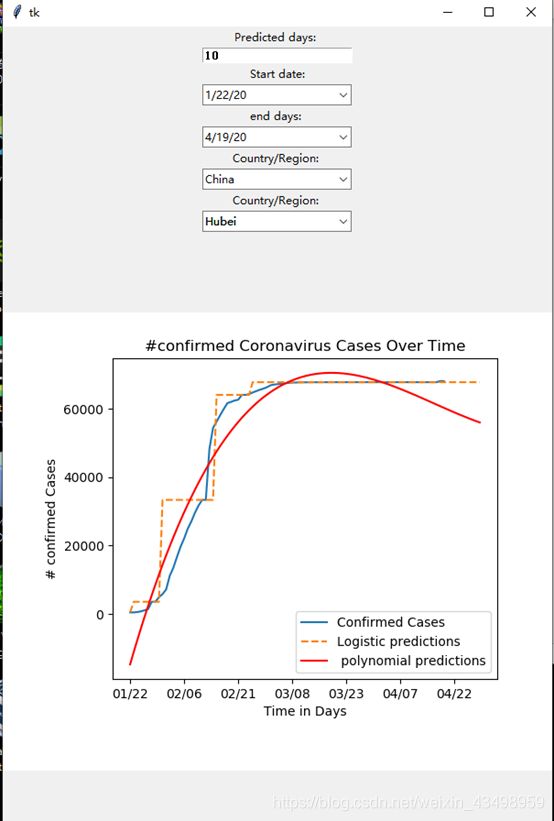
在GUI界面选择预测的天数,起止时间,地区可以得出分析预测图像。
整体思路
-
获取数据源
使用SVN从Github上面一个项目仓库CSSEGISandData/COVID-19,下载了一个包含地区维和时间维的确诊患者数量.csv文件。
SVM使用教程连接
四月份下载的数据文件 -
处理数据
首先读取.csv文件,转为DataFrame格式。按GUI界面选择的参数截取数据,如:中国-湖北-1月22日-4月19日。先按国家属性做行截取,得到33行各省市数据。再按省属性做行截取,得到一行湖北数据。再按起止时间做列截取,得纯患者人数行DateFrame格式。把时间段转换成时间序列[1,2,3……88],把患者人数转换成List结构。 -
进行回归分析
自变量为时间,因变量为患者数,用多种模型尝试进行拟合。简单线性回归、支持向量回归,拟合效果很差,舍弃。最后留下了效果好的:多项式回归和logistic回归。对应输入的预测天数,反馈出预测图像。 -
制作GUI界面
用tk的标签,输入条,下拉框,画布控件组成。其中两个下拉选项框,负责选择国家和选择的,做了嵌套功能,只有选了中国才能有武汉选项。具体实现方法是在国家选择事件触发一个函数,这个函数会把省选项删除,代入国家参数重新显示一个省选项。在选择完地区成后会触发更新预测图函数,即先把已有的图删除,再重新画一个。
整体代码
import pandas as pd
import numpy as np
import datetime
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression,LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib
from matplotlib.pyplot import MultipleLocator
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
from matplotlib.figure import Figure
import tkinter as tk
from tkinter import ttk
pd.set_option('display.max_columns',1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth',1000)
# .csv包含93列:Province/State表示省份,Country/Region表示国家,Lat,Long分别表示经纬度,后面每一列分别表示具体日期(1月22日-4月19日)
confirmed_global_path = 'C:\\Users\\chao\\csse_covid_19_time_series\\time_series_covid19_confirmed_global.csv'
confirmed_global_df = pd.DataFrame(pd.read_csv(confirmed_global_path))
cols = confirmed_global_df.keys()#列名
dates = confirmed_global_df.loc[:, cols[4]:].keys()#提取日期列名(1月22日-4月19日)
global start_date,end_date
start_date=0
end_date=88
matplotlib.use('TkAgg')
window = tk.Tk()
window.geometry("600x900")
label4=tk.Label(window, text='Predicted days: ')
label4.pack()
entry4=tk.Entry(window,width=20,font=("宋体", 10, 'bold'))
entry4.pack()
label3=tk.Label(window,text='Start date:')#截取开始时间
label3.pack()
def go_Country3(*args): # 处理事件,*args表示可变参数
global start_date
start_date=list(dates).index(comboxlist3.get())
# 构造下拉列表
comvalue3 = tk.StringVar() # 窗体自带的文本,新建一个值
comboxlist3 = ttk.Combobox(window, textvariable=comvalue3) # 初始化
comboxlist3["values"] = list(confirmed_global_df.loc[:, cols[4]:].keys())#日期列(1月22日-4月19日)
comboxlist3.current(0) # 选择第一个
comboxlist3.bind("<>" , go_Country3) # 绑定事件,(下拉列表框被选中时,绑定go()函数)
comboxlist3.pack()
label5=tk.Label(window, text='end days: ')#截取结束时间
label5.pack()
def go_Country5(*args): # 处理事件,*args表示可变参数
global end_date
end_date = list(dates).index(comboxlist5.get())
# 构造下拉列表
comvalue5 = tk.StringVar() # 窗体自带的文本,新建一个值
comboxlist5 = ttk.Combobox(window, textvariable=comvalue5) # 初始化
comboxlist5["values"] = list(confirmed_global_df.loc[:, cols[4]:].keys())#日期列(1月22日-4月19日)
comboxlist5.current(88) # 选择第一个
comboxlist5.bind("<>" , go_Country5) # 绑定事件,(下拉列表框被选中时,绑定go()函数)
comboxlist5.pack()
label2 = tk.Label(window, text='Choose a Province/State: ')
label1 = tk.Label(window, text='Choose a Country/Region: ')
label1.pack()#显示选择国家标签
def go_Country1(*args): # 处理事件,*args表示可变参数
global confirmed_Province_df,Country_Province_df
Province=comboxlist1.get() # 选中的值
confirmed_Province_df = Country_Province_df[Country_Province_df["Province/State"] == Province]
print_file()
def go_Country(*args): # 处理事件,*args表示可变参数
global confirmed_Province_df,Country_Province_df,label2,comboxlist,comboxlist1
Country=comboxlist.get() # 选中的国家值
Country_Province_df = confirmed_global_df.loc[confirmed_global_df["Country/Region"] == Country]#对应的省份选项
scatter3.get_tk_widget().pack_forget()#删除上次的结果
label2.pack_forget()#删除上次的省份列表
comboxlist1.pack_forget()
if len(Country_Province_df)==1:
confirmed_Province_df=Country_Province_df
print_file()
else:
label2 = tk.Label(window, text='Country/Region: ')
label2.pack()
comvalue1 = tk.StringVar() # 窗体自带的文本,新建一个值
comboxlist1 = ttk.Combobox(window, textvariable=comvalue1) # 初始化
comboxlist1["values"] = list(Country_Province_df.iloc[:, 0])
comboxlist1.current(0) # 选择第一个
comboxlist1.bind("<>" , go_Country1) # 绑定事件,(下拉列表框被选中时,绑定go()函数)
comboxlist1.pack()
# 构造国家下拉列表
comvalue = tk.StringVar() # 窗体自带的文本,新建一个值
comboxlist = ttk.Combobox(window, textvariable=comvalue) # 初始化
comboxlist["values"] = sorted(list(set(confirmed_global_df.iloc[:, 1])))#去重并排序国家名称列
comboxlist.current(0) # 选择第一个
comboxlist.bind("<>" , go_Country) # 绑定事件,(下拉列表框被选中时,绑定go()函数)
comboxlist.pack()
# new Country/Region label and input box
# 构造省份下拉列表
comvalue1 = tk.StringVar() # 窗体自带的文本,新建一个值
comboxlist1 = ttk.Combobox(window, textvariable=comvalue1) # 初始化
comboxlist1.bind("<>" , go_Country1)
# 输出预测图像
def print_file():
global start_date,end_date
days_in_future = int(entry4.get())#预测天数
future_forcast = np.array([i for i in range(end_date - start_date + days_in_future)]).reshape(-1, 1)#未来预测序数列
first='1/22'
first_day = datetime.datetime.strptime(first, '%m/%d')
future_forcast_dates = []
for i in range(len(future_forcast)):
future_forcast_dates.append((first_day + datetime.timedelta(days=i+start_date)).strftime('%m/%d'))
adjusted_dates = future_forcast_dates[:-days_in_future]#矫正后日期star-end,eg:'1/22','1/23'……
dates_array = np.array([i for i in range(end_date-start_date)]).reshape(-1, 1)#开始到结束日准确序数列[1,2,3,……]
confirmed_Province_array = np.array(confirmed_Province_df.iloc[:, start_date+4:end_date+4]).reshape(-1, 1)#准确患者人数列
print(confirmed_Province_array)
# 将从1月22号的人员确诊数据分成0.9的训练集,0.1的测试集
X_train_confirmed, X_test_confirmed, y_train_confirmed, y_test_confirmed = train_test_split(dates_array,confirmed_Province_array, test_size=0.1, shuffle=False)
Logistic=LogisticRegression(C = 5, penalty = 'l2')
Logistic.fit(X_train_confirmed,y_train_confirmed)
Logistic_pred = Logistic.predict(future_forcast)
# 多项式回归
poly_reg = PolynomialFeatures(degree=3)
x_poly = poly_reg.fit_transform(X_train_confirmed)
linear_reg = LinearRegression()
linear_reg.fit(x_poly, y_train_confirmed)
global f, scatter3
f = Figure(figsize=(6, 5), dpi=100)
scatter3.get_tk_widget().pack_forget()
a = f.add_axes([0.2, 0.2, 0.7, 0.7])
scatter3 = FigureCanvasTkAgg(f, window)
line,=a.plot(adjusted_dates, confirmed_Province_array)
a.plot(future_forcast_dates, Logistic_pred, linestyle='dashed')
a.plot(future_forcast_dates, linear_reg.predict(poly_reg.fit_transform(future_forcast)), 'r')
xmajorLocator = MultipleLocator(15)
a.xaxis.set_major_locator(xmajorLocator)
a.set_title('#confirmed Coronavirus Cases Over Time')
a.set_xlabel('Time in Days')
a.set_ylabel('# confirmed Cases')
a.legend(['Confirmed Cases', 'Logistic predictions', ' polynomial predictions'])
scatter3.draw()
scatter3.get_tk_widget().pack(side=tk.TOP, expand=1)
f = Figure(figsize=(6, 5), dpi=100)
scatter3 = FigureCanvasTkAgg(f, window)
window.mainloop()
if __name__ == "__main__":
main()
参考资料引用
1.从GitHub上CSSEGISandData/COVID-19项目获取的数据源——超链接
2.关于2019nCoV新冠肺炎的建模(Ⅱ)—基于Logistic模型的疫情预测——超链接
3.新冠疫情现状分析及预测——基于线性回归、支持向量回归等数学模型——超链接