菜鸟学Kubernetes(K8s)系列——(三)关于Service、Ingress
菜鸟学Kubernetes(K8s)系列——(三)关于Service、Ingress
| Kubernetes系列文章 | 主要内容 |
|---|---|
| 菜鸟学Kubernetes(K8s)系列——(一)关于Pod和Namespace | 通过本文你将学习到: (1)什么是Pod,为什么需要它、如何创建Pod、Pod的健康检查机制(三种探针) (2)什么是标签、标签选择器 (3)什么是Namespace、他能做什么、如何创建它等等 |
| 菜鸟学Kubernetes(K8s)系列——(二)关于Deployment、StatefulSet、DaemonSet、Job、CronJob | 通过本文你将学习到: (1)什么是Deployment,如何创建它、它的扩缩容能力是什么、自愈机制,滚动升级全过程、如何进行回滚 (2)什么是ReplicaSet、它和Deployment的关系是什么 (3)动态扩缩容能力(HPA)、蓝绿部署、金丝雀部署 (4)什么是DaemonSet/Job/CronJob、它们的功能是什么、如何创建使用等等 |
| 菜鸟学Kubernetes(K8s)系列——(四)关于Volume卷(PV、PVC、StorageClass等) | 通过本文你将学习到: (1)什么是Volume卷、它的几种类型(emptyDir、hostPath、NFS)、这几种类型是使用方式 (2)什么是PV-PVC、为什么要用他们、他们是怎么协作的、如何使用PV-PVC (3)动态配置持久卷是什么,它是怎么工作的、如何实现动态的分配PV等等 |
| 菜鸟学Kubernetes(K8s)系列——(五)关于ConfigMap和Secret | 通过本文你将学习到: (1)什么是ConfigMap,如何创建它、它能用来做什么事情、在实战中怎么使用ConfigMap (2)什么是Secret,如何创建它,怎么使用它等等 |
| 菜鸟学Kubernetes(K8s)系列——(七)关于Kubernetes底层工作原理 | 通过本文你将学习到: (1)Kubernetes的核心组件:Etcd、Api-Server、Scheduler、Controller-Manager、Kubelet、Kube-proxy的工作方式,工作原理。 (2)Kubernetes集群中核心组件的协作方式、运行原理。 |
| 菜鸟学Kubernetes(K8s)系列——(番外)实现Deployment的动态扩缩容能力(HPA) | 通过本文你将学会实现Deployment的动态扩缩容能力(HPA) |
| 菜鸟学Kubernetes(K8s)系列——(番外)安装Ingress-Nginx(工作原理) | 通过本文你将学会安装Ingress-Nginx |
七、Service
就微服务而言,部署一个微服务肯定会产生很多个Pod,不仅集群内的这些Pod之间需要进行相互通信,而且还要对集群外部的客户端的HTTP请求做出响应。
Pod需要一种寻找其他Pod的方法来使用其他Pod提供的服务,不像在没有Kubernetes的世界,系统管理员要在用户端配置文件中明确指出服务的精确的IP地址或者主机名来配置每个客户端应用,但是同样的方式在Kubernetes中并不适用,因为:
- Kubernetes在Pod启动前会给已经调度到节点上的Pod分配IP地址,因此客户端不能提前知道提供服务的Pod的IP地址
- Pod是短暂的,他们随时都可能会杀死,然后重启,因此每个Pod的IP是不固定的。
- 水平伸缩意味着多个Pod可能会提供相同的服务,每个Pod都有自己的IP地址,但是客户端只想通过一个IP来访问到这些Pod
为了解决这一问题(Pod的IP不固定、相同Pod的IP不唯一,无法提供同一的对外暴露方式),Kubernetes提供了一种资源类型——Service!
1、什么是Service?
Service是一种为一组功能相同的Pod提供单一不变的接入点的资源。当Service存在时,他的IP地址和端口不会改变。客户端
通过这个IP+端口建立连接,这些连接会被路由到提供该服务的任意一个Pod上。通过这种方式,客户端不需要知道每个单独的提供服务的Pod的地址。
从下图中可以很清楚的看到Service处于K8s集群中个那一层面:
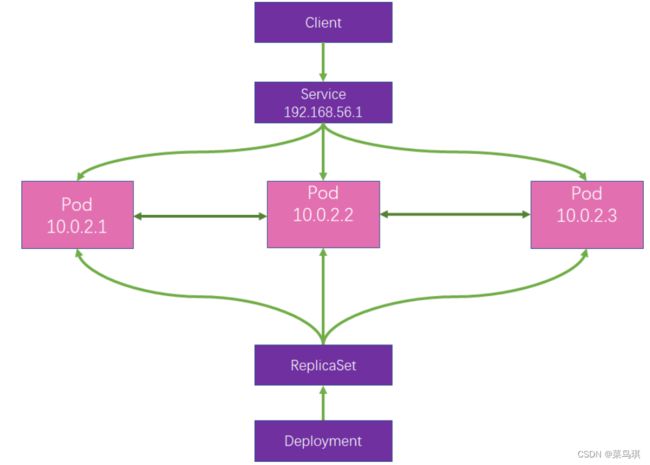
2、Service怎么找到Pod的?
前面提到过我们可以在Pod上打一个标签,Service就是通过Pod的标签来选择哪些Pod是由他来管理的。当Service接收到一个请求后,他会将请求负载均衡到他所选择的Pod中的任意一个。
apiVersion: v1
kind: Service
metadata:
name: service-test
namespace: default
spec:
selector:
app: tomcate ### 具有app:tomcate标签的Pod都属于该Service
ports:
- port: 80 ### 访问当前service的80
targetPort: 8080 ### 派发到Pod的8080
上面这个资源的含义是:在default名称空间下创建了一个名叫service-test的服务,它会把在80端口接收到的请求路由到具有app:tomcate标签的任意一个Pod的8080端口上。
创建完这个资源后(kubectl apply -f test-service.yaml),我们可以发现这个被创建的Service(kubectl get service)被分配了一个内部集群IP,我们可以在集群内部访问这个IP的80端口,进而访问到他所管理的Pod。但是我们通常不仅仅是想在集群内部可以访问他,有时候也需要在集群外部访问它。具体实现会在后面说到。
3、Service对外暴露端口
前面的例子中我们指定了一个port,这个port表示这个Service要对外暴露的端口。一个Service是可以对外暴露多个端口的,比如,我们的Pod要监听两个端口:8080和8443,那么我们可以使用一个服务从80和443分别转发至Pod的8080和8443端口。但是,需要注意的是,如果要为一个Service创建多个端口,就必须给每个端口指定名称,如下:
apiVersion: v1
kind: Service
metadata:
name: service-test
namespace: default
spec:
selector:
app: tomcat ### 具有app:tomcate标签的Pod都属于该Service
ports:
- name: http
port: 80 ### 访问当前service的80
targetPort: 8080 ### 派发到Pod的8080
- name: https
port: 443
targetPort: 8443
3.1 使用端口命名
我们知道,上面指定的targetPort是Pod暴露的端口号,这时我们有个问题,如果Pod要将原本对外暴露的8080端口改为8888,那这时我们还得把Service中的8080改为888,是不是很麻烦,而且还有可能出错,你看,我就少写了一个8。那有什么办法呢?
我们可以在Pod中为他要暴露的端口起一个名字,然后在Service中引用这个名字就行了。如下:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
labels:
app: ng
spec:
containers:
- name: ng
image: nginx
ports:
- name: http ### 端口8080被命名为http
containerPort: 80
- name: https ### 端口8443被命名为https
containerPort: 8443
---
apiVersion: v1
kind: Service
metadata:
name: service-test
spec:
selector:
app: ng
ports:
- name: http
port: 80
targetPort: http ### 将80端口映射到容器在红被称为http的端口
- name: https
port: 443
targetPort: https ### 将443端口映射到容器在红被称为https的端口
4、服务发现
我们知道创建一个Service后就可以通过一个稳定的IP+端口访问到Pod。那么客户端Pod是怎么知道Service的IP+端口呢?是不是需要先创建服务,然后手动查找Service的IP,然后将这个IP传给客户端Pod的配置项呢?当然不是,Kubernetes为客户端Pod提供了发现Service的IP+port的方式。
4.1 通过环境变量发现服务
在Pod开始运行时,Kubernetes会初始化一系列的环境变量指向现在存在的服务。如果你创建的Service早于客户端Pod的创建,Pod上的进程可以根据环境变量获取服务的IP+端口。
从下面我们可以看到,在test-pod-02这个Pod中执行env指令,查看环境变量中记录了我们集群中所有Service的IP和Port
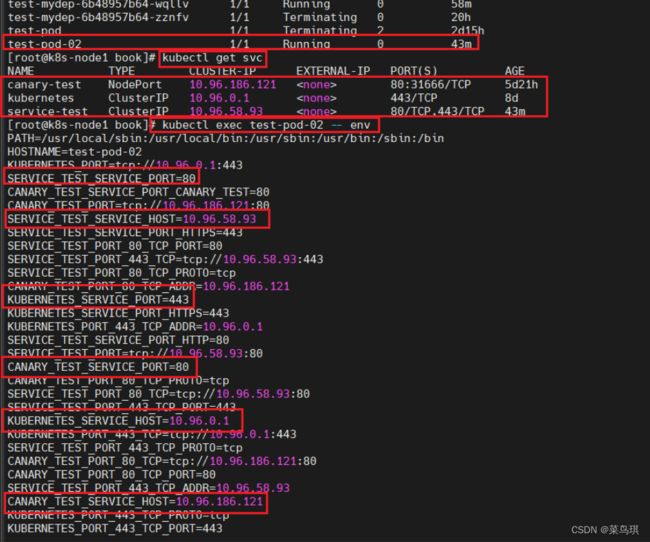
环境变量是获取服务IP和端口的一种方式,为什么不用DNS域名呢?
在Kubernetes中是存在一个DNS服务器的,我们可以通过DNS来获取所有服务的IP地址
4.2 通过DNS发现服务
我们发现,在kube-system命名空间下存在着一个名为dns的Pod。顾名思义,这个Pod运行着一个DNS服务,在集群中的其他Pod都被配置成使用其作为DNS(Kubernetes通过修改每个容器的/etc/resolv.conf文件实现的)。运行在Pod上的进程DNS查询都会被Kubernetes自身的DNS服务器响应,该服务器知道系统中运行的所有服务。
注意:Pod是否使用内部的DNS服务器是根据pod中spec的dnsPolicy属性来决定的。
![]()
每个服务从内部DNS服务器中获取一条DNS信息,客户端的Pod在知道服务名称的情况下可以通过全限定域名(FQDN)来访问。
全限定域名(FQDN)
FQDN指的是由:服务名称.服务所在名称空间名.集群域后缀组成的(eg:service-test.default.svc.cluster.local)
注意:
通过FQDN访问时仍然需要指明端口号。
必须要在一个存在的Pod中才能使用 FQDN 来访问其他的Pod
如果两个需要通过FQDN访问的Pod在同一个Namespace下,那么可以省略命名空间和集群域后缀(default.svc.cluster.local)
5、 将服务暴露给外部客户端
前面自始至终我们都是在集群内部是访问不同的Pod,但是,通常情况下,我们需要在集群外部去访问某一个Pod,这时该怎么办呢?
5.1 Service的三种对外暴露方式
在Service资源的定义中的type可选值如下,代表三种不同的服务暴露方式:
- ClusterIP(默认): 为当前Service分配或者不分配(不分配的情况后面会说)集群IP,负载均衡一组Pod。
- 他的缺点是只能在集群内进行互相访问(这就是我们前面创建的Service,没有指定type时,默认就是ClusterIP类型)
- NodePort:外界可以使用 机器IP+暴露的nodePort端口 访问。
- nodePort端口由kube-proxy开在机器上的(集群中的每台机器都会开放这个端口!)
- 机器IP+暴露的NodePort 流量会先来到kube-proxy,然后再转到service的port,再转到Pod中容器的targetPort
- LoadBalancer:使用云提供商的负载均衡器向外部暴露服务。 负载均衡器可以将流量重定向到跨所有节点的节点端口。客户端通过负载均衡器的IP连接到服务。
5.2 创建一个NodePort的Service
apiVersion: v1
kind: Service
metadata:
name: test-nodeport
spec:
selector:
app: test
type: NodePort ### 指定NodePort类型的Service
ports:
- port: 80 ### Service集群IP的端口号
targetPort: 8080 ### Service管理的Pod的目标端口号
nodePort: 31666 ### 节点IP开放的端口号,如果不指定,Kubernetes会随机指定一个

这时我们创建出的Service是这样的,我们可以通过两种方式访问到他所管理的Pod
- 通过Service集群IP+Port:10.96.186.121:80
- 通过集群任意节点IP+Port:192.168.56.100:31666(或者192.168.56.101:31666等,都可以。因为他在集群中的所有节点上都开了这个端口)
如下图,展示了我们从客户端访问Service的IP,然后请求被路由的方式:
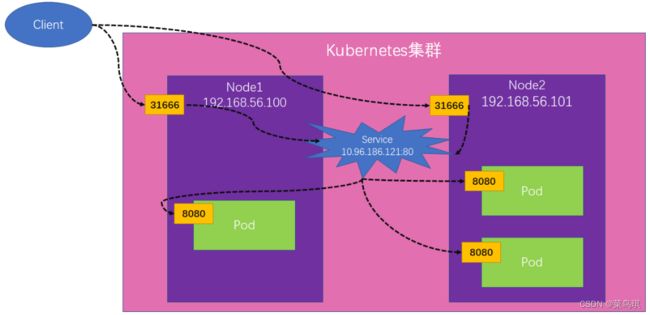
当我们从客户端发送一个请求(192.168.56.100:31666),这个请求会被转到Service,然后Service在负载均衡到任意一个Pod的8080端口上。
八、Ingress
1、为什么需要Ingress?
-
Service可以使用NodePort暴露集群外访问端口,但是性能低下,不安全
我们知道部署k8s时,是需要关闭防火墙的,主要原因是k8s的很多服务会以NodePort方式映射出去,这样对于宿主机来说是非常的不安全的,而Ingress可以避免这个问题,只需要将Ingress自身服务映射出去,就可代理后端所有的服务,则后端服务不需要映射出去。
-
Service只能进行简单的负载均衡,它是工作在四层网络模型上,而Ingress是工作在七层网络模型上的,在七层网络模型的应用层可以进行复杂的负载、限流等各种高级功能。
-
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
-
我们可以使用Ingress作为整个集群统一的入口,配置Ingress规则转到对应的Service
2、为什么不用Nginx,而要用Ingress?
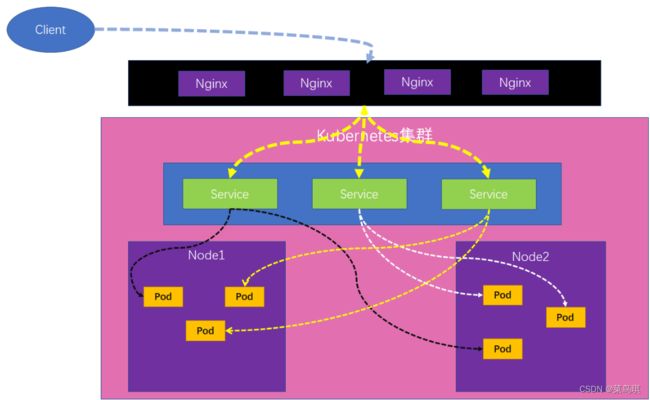
前面说了为什么需要Ingress其实是为了说明用Service的不好之处,这里拿Nginx和Ingress来比较其实是不太严谨的,等看了后面的知识就知道为什么不严谨了,这里先就说成是Ingress吧。
我们知道不能使用Service的NodePort方式直接对外暴露服务,一个原因是不安全,一个是功能有限。那么就需要一个网关来提供统一的访问入口,实现更多复杂的功能,我们首先能想到的就是用Nginx来做。
我们可以在这个Nginx上配置各种的规则,把流量转给后台集群。当然,我们知道如果并发量高了,一台Nginx肯定是不够用的,可能需要一个Nginx集群,那这时我们就要写很多个Nginx的配置文件。而且,如果一台Nginx上的配置改了,其他的Nginx上的配置也得手动同步修改。这样真的很麻烦,所以K8s就引入了ingress-nginx。
3、Ingress-Nginx
在介绍Ingress资源提供的功能之前,必须强调,只有Ingress控制器在集群中运行,Ingress资源才能正常工作。Ingress控制器会有许多种类,下面主要介绍一下Ingress自己实现的Ingress-Nginx控制器。
3.1 Ingress-Nginx原理
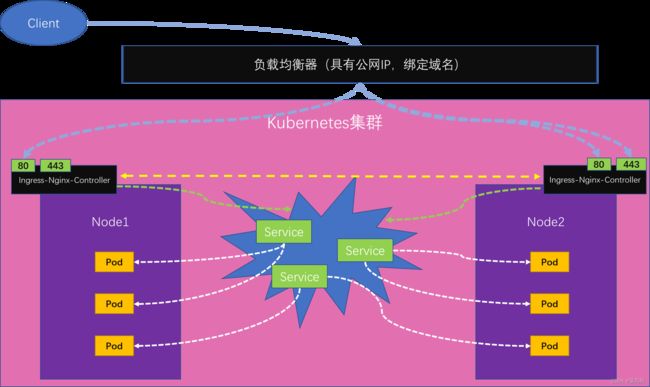
在K8s集群中,首先建议,每个Service不要用NodePort形式(后面会介绍到无头Service),这样集群中的所有Service都不占用机器端口,这样Service对外就是安全的。但是这样外部就没法访问我们了。所以,以Ingress对外暴露服务的方式就产生了!
K8s官方就推荐安装一个Ingress-controller,他会在每个节点上部署一个ingress-nginx-controller的Pod(其实也不一定要每个节点上都装),这个Pod中运行了一个Nginx,这些Pod可以访问到各个节点中的Service(注意:他们之间的nginx.conf配置文件是自动同步的),然后他们对外暴露的是80和443端口。前面这些K8s集群中的东西都是在内网中部署的,然后在这些ingress-nginx-controller前还会有一个负载均衡器来将请求负载均衡到不同的ingress-nginx-controller上,这个负载均衡器是有公网IP的,而这个负载均衡器又和K8s集群在同一私网,同时他有域名,所以以后请求只需要到达这个负载均衡器,然后他在将这个请求动态的路由到某个节点的前置网关ingress-nginx-controller,这个ingress-nginx-controller再来判断请求应该到达哪个Service(这个转发规则是通过Ingress资源中的rules来配置的),Service服务再负载均衡转到相应的Pod中。
所以,以前我们在nginx中配置的nginx.conf现在等于是抽取到Ingress资源中进行配置了。我们配置完Ingress后它会被转为nginx.conf信息写入到ingress-nginx-controller中运行的Nginx的/etc/nginx.conf文件中。当我们更新Ingress以后,他会同步更新各个ingress-nginx-controller中的nginx.conf配置文件,同时reload使其生效。各个节点上部署的ingress-nginx-controller
这些Pod中运行的Nginx容器中的nginx.conf配置文件(后面会对这个配置文件进行解释)
3.2 Ingress-Nginx安装
详情戳这里>>>
4、通过Ingress访问Service
4.1 简单的Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: hello-ingress
namespace: default
spec:
rules:
- host: zhangaoqi.com ### 指定监听的主机域名
http: ### 指定请求的路由规则
paths:
- path: /
pathType: Prefix ### 匹配规则———前缀匹配,由上面的path指定,现在这种就表示只要访问http://zhangaoqi.com/,请求就会来到这里
backend: ### 指定路由的后台服务的Service名
service:
name: canary-test ### kubernetes集群的svc名称
port:
number: 80 ### service中指定的port端口号
拓展:
pathType
Prefix:基于以/分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由/分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。Exact:精确匹配 URL 路径,且区分大小写。ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的pathType处理或者与Prefix或Exact类型作相同处理。
这个Ingress就相当于我们以前写的nginx配置
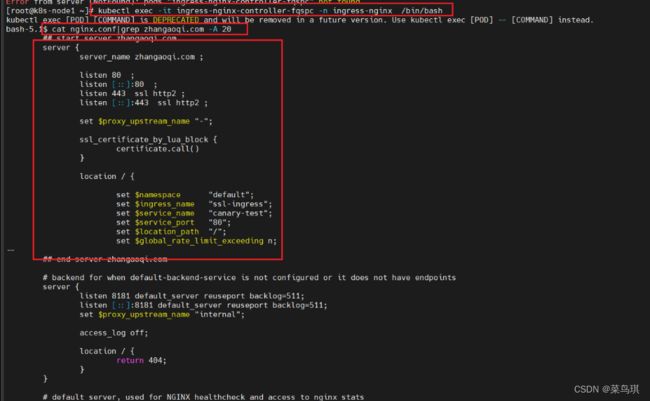
我们可以进入到一个ingress-nginx的pod中去查看他的nginx.conf配置文件:cat nginx.conf|grep zhangaoqi.com -A 20(查看nginx.conf从zhangaoqi.com后开始的20行信息)
注意:我们去另一个Pod中查看nginx.conf配置文件,会发现他们的内容都是一样的,我们每修改一次Ingress配置都会同步修改这个nginx.conf中的信息。
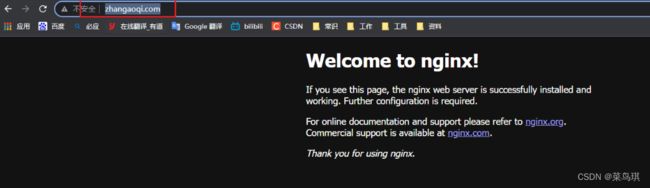
如果我们想测试效果,那还需要在我们的windows主机上修改hosts文件,添加一条信息:192.168.56.100 zhangaoqi.com
这样就可以在windows上访问zhangaoqi.com了。(测试,没有公网域名,只能这样简单测了)
4.2 路径重写
Rewrite功能经常被用于前后分离的场景
前端给服务器发送 / 请求映射前端地址
后端给服务器发送 /api 请求来到对应的服务。但是后端服务没有 /api的起始路径,所以需要ingress-controller自动截串
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: ## 写好annotion nginx.ingress.kubernetes.io/rewrite-target: /$2 ### 表示只保留哪一部分 name: rewrite-ingress-02 namespace: default spec: rules: ## 写好规则 - host: zhangaoqi.com http: paths: - backend: service: name: canary-test port: number: 80 path: /api(/|$)(.*) pathType: Prefix ### 我们只要访问 http://zhangaoqi.com/api/xxx ,它会将请求重写为http://zhangaoqi.com/xxx
4.3 限速
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-test
namespace: default
annotations: ##注解
nginx.ingress.kubernetes.io/limit-rps: "1" ### 开启限速功能,限制每秒只能访问一次
spec:
rules:
- host: zhangaoqi.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: canary-test
port:
number: 80
4.4 会话保持
第一次访问,ingress-nginx会返回给浏览器一个Cookie,以后浏览器带着这个Cookie,保证访问总是抵达第一次访问的Pod;
测试:
部署一个三个Pod的Deployment并设置Service:
## 部署一个三个Pod的Deployment并设置Service apiVersion: v1 kind: Service metadata: name: session-affinity namespace: default spec: selector: app: session-affinity type: ClusterIP ports: - name: session-affinity port: 80 targetPort: 80 protocol: TCP --- apiVersion: apps/v1 kind: Deployment metadata: name: session-affinity namespace: default labels: app: session-affinity spec: selector: matchLabels: app: session-affinity replicas: 3 template: metadata: labels: app: session-affinity spec: containers: - name: session-affinity image: nginx编写具有会话保持的ingress:
### 利用每次请求携带同样的cookie,来标识是否是同一个会话 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: session-test namespace: default annotations: nginx.ingress.kubernetes.io/affinity: "cookie" ### 开启 会话保持 功能 nginx.ingress.kubernetes.io/session-cookie-name: "zhangaoqi-session" ### 指定cookie的名称(可选) spec: rules: - host: zhangaoqi.com http: paths: - path: / pathType: Prefix backend: service: name: session-affinity port: number: 80
4.5 配置TLS
-
生成证书(这里是方便自己测试生成的证书,也可以去阿里云申请官方证书或者购买权威的证书进行配置)
### 在k8s上执行下面的命令,他会生成两个文件:tls.cert、tls.key。如果购买权威机构的,那么他们会提供这两个文件 openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.cert -subj "/CN=zaq.com/O=zaq.com" ### 接下来创建secret,保存这个k8s证书 kubectl create secret tls zaq-tls --key tls.key --cert tls.cert
-
配置Ingress——使用证书
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ssl-ingress namespace: default spec: tls: - hosts: - zhangaoqi.com ### 他将接收来自zhangaoqi.com主机的TLS连接 secretName: zaq-tls ### 这里需要指定secret,从这个secret中获取之前创立的私钥和证书 rules: - host: zhangaoqi.com http: paths: - path: / pathType: Prefix backend: service: name: canary-test port: number: 80配置好证书,访问域名,就会默认跳转到https;

拓展:证书分为DV、OV、EV,他们的权威性是DV<OV<EV
4.6 金丝雀发布——Ingress版本
以前可以使用k8s的Service配合Deployment进行金丝雀部署。原理是根据selector标签选择器实现的:
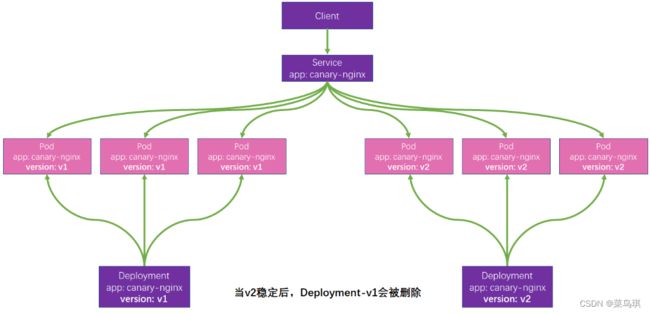
缺点:
- 不能自定义灰度逻辑,比如指定用户进行灰度
现在可以使用Ingress进行灰度。他的原理是通过在请求头上加key-value来确定将请求转到哪个Service:
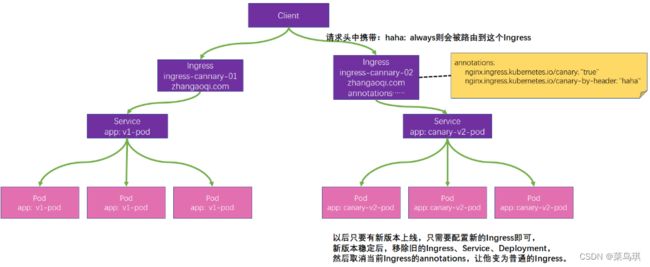
实战示例:
-
部署两个service版本。v1版本返回nginx默认页,v2版本返回 11111
## 使用如下文件部署两个service版本。v1版本返回nginx默认页,v2版本返回 11111 apiVersion: v1 kind: Service metadata: name: v1-service namespace: default spec: selector: app: v1-pod type: ClusterIP ports: - name: http port: 80 targetPort: 80 protocol: TCP --- apiVersion: apps/v1 kind: Deployment metadata: name: v1-deploy namespace: default labels: app: v1-deploy spec: selector: matchLabels: app: v1-pod replicas: 1 template: metadata: labels: app: v1-pod spec: containers: - name: nginx image: nginx --- apiVersion: v1 kind: Service metadata: name: canary-v2-service namespace: default spec: selector: app: canary-v2-pod type: ClusterIP ports: - name: http port: 80 targetPort: 80 protocol: TCP --- apiVersion: apps/v1 kind: Deployment metadata: name: canary-v2-deploy namespace: default labels: app: canary-v2-deploy spec: selector: matchLabels: app: canary-v2-pod replicas: 1 template: metadata: labels: app: canary-v2-pod spec: containers: - name: nginx image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nginx-test:env-msg -
配置Ingress,实现灰度发布
-
下面这是V1版本时配置的Ingress
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-cannary-01 namespace: default spec: rules: - host: test.canary.com http: paths: - path: / ### 如果以前这个域名下的这个路径相同的功能有配置过,以最后一次生效 pathType: Prefix backend: service: name: v1-service ### 来到v1版本的service port: number: 80 -
当发布了V2版本了,这时再来配置一个v2版本的Ingress(V1版本的就不用再管了)
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-cannary-02 namespace: default annotations: nginx.ingress.kubernetes.io/canary: "true" ### 代表该Ingress就是金丝雀版本 nginx.ingress.kubernetes.io/canary-by-header: "haha" ### 这个值是自定义的,表示的是请求头的key ### 当请求中的请求头是 haha=always,那么流量就会路由到金丝雀版本 ### 当请求中的请求头是 haha=never,那么流量就永远不会被路由到金丝雀版本 # nginx.ingress.kubernetes.io/canary-by-header-value: "test" 如果请求头的value不想使用always和never,那也可以使用该标签自定义这个请求头的value值。(表示haha=test)还有其他相关配置可参考官方文档 spec: rules: - host: test.canary.com http: paths: - path: / ### 如果以前这个域名下的这个路径相同的功能有配置过,以最后一次生效 pathType: Prefix backend: service: name: canary-v2-service ### 来到v2版本的service port: number: 80
-
4.7 举一反三
想要加什么功能就加什么annotations即可,具体参考https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/
5、headless服务
headless服务和普通Service的区别就是他是一个无头的Service,也就是为这个Service设置clusterIP为Node + type为ClusterIP的配置,这样创建出来的Service是不会有Service集群IP的。在集群内部,我们仍然可以通过这个Service的FQDN来访问他所管理的Pod,但是如果在集群外部,我们根本没有办法访问这个Service,因为这个Service根本就没有分配任何IP。

这里有个小点需要注意一下:
这个headless服务和普通Service基本上没什么区别,他也管理一组Pod。但是他在进行负载均衡时是通过DNS的轮询机制实现的,而不是通过服务代理来实现的。
在生产环境一般建议将Service设置为headless类型的,然后再通过Ingress去对外暴露他,这样做可以保证后端服务的安全性。
apiVersion: v1
kind: Service #定义一个负载均衡网络
metadata:
name: stateful-tomcat
labels:
app: stateful-tomcat
spec:
ports:
- port: 8123
name: web
targetPort: 8080
clusterIP: None
type: ClusterIP
# ClusterIP:集群内能用这个ip、service域名能访问
## 当ClusterIP搭配clusterIP: None使用;表示不要分配集群ip。headless;无头服务。稳定的域名,使用这种方式是不能在浏览器进行访问的。如果还想访问,那么可以使用后面的Ingress
selector:
app: stateful-tomcat
6、NetworkPolicy
我们知道k8s中不同命名空间的资源是隔离的,但是网络是没有隔离的,各个Pod之间网络是互通的。这就会出现一个问题:如果我们测试环境连接的数据库访问到了生产环境的数据库(不同环境是在不同的命名空间下的),那不就影响到了生产环境了吗。为了让不同名称空间的网络不互通,可以使用NetworkPolicy进行隔离
NetworkPolicy可以指定Pod间的网络隔离策略,它可以定义谁能访问谁,谁不能访问谁。
6.1 一些属性信息
一个概念:
出战(Egress)规则:我们访问别人(一般默认开启所有的)
入站(Ingress)规则:别人访问我们(一般主要设置入站规则)
- spec.podSelector:Pod选择器,通过他选中的Pod就被隔离起来了
- spec.podSelector.matchLabels:通过他的值来具体指定Pod的标签
- spec.policyTypes:指定 通过Pod选择器 选择的Pod的入站和出战规则
- 他有两个值:Ingress、Egress
- spec.ingress:指定入站白名单(也就是指定谁能访问我)
- spec.ingress.from(数组,可以设置多组)
- spec.ingress.from.ipBlock(数组,可以设置多组):指定一个可以访问上面通过spec.podSelector被选中的Pod的子网范围
- spec.ingress.from.namespaceSelector(数组,可以设置多组):指 只有这里被选中的Namespace下的Pod才能访问上面通过spec.podSelector被选中的Pod
- spec.ingress.from.podSelector(数组,可以设置多组):指 只有这里被选中的Pod才能访问上面通过spec.podSelector被选中的Pod
- spec.ingress.ports:指定被选中Pod的端口
- spec.ingress.from(数组,可以设置多组)
- spec.egress:指定出站白名单(也就是指定我能访问谁)
- spec.egress.to(数组,可以设置多组)
- spec.egress.to.ipBlock(数组,可以设置多组)
- spec.egress.to.namespaceSelector(数组,可以设置多组):
- spec.egress.to.podSelector(数组,可以设置多组)
- spec.egress.ports:指定被选中Pod的端口
- spec.egress.to(数组,可以设置多组)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector: ### 选中指定Pod
matchLabels:
role: db ### 选中的标签是role:db的Pod会被隔离起来
policyTypes: ## 定义上面Pod的入站出站规则
- "Ingress"
- "Egress"
ingress: ## 定义入站白名单
- from:
- ipBlock:
cidr: "192.168.0.0/16" ### 指默认从192.168.0.0 - 192.168.255.255的pod可以访问被隔离的Pod
except: ### 但是除过下面的范围
- "192.168.0.0/24" ### 192.168.1.0 - 192.168.1.255
- namespaceSelector:
matchLabels:
project: myproject ### 指 只有标签是project:myproject的namespace才能访问标签是role:db的Pod
- podSelector:
matchLabels:
role: frontend ### 指 只有标签是role:frontend的Pod才能访问标签是role:db的Pod
### 注意上面的写法,ipBlock、namespaceSelector、podSelector,他们各自前面都有一个短横线- ,这时:这三个关系是并集的关系,也就是说他们三个共同选择出来的Pod都能访问上面指定被隔离的Pod。而如果他们三个共同只有一个短横线-,这时:他们的关系就成了交集的关系,也就是必须同时满足三个条件的Pod才能访问被隔离的Pod
ports:
- protocol: TCP
port: 6379
egress: ## 定义出站白名单
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
因此,例子中的
NetworkPolicy对网络流量做了如下限制:
- 隔离了
default名称空间中带有role=db标签的所有 Pod 的入方向网络流量和出方向网络流量- Ingress规则(入方向白名单规则):
- 当请求方是如下三种来源当中的任意一种时,允许访问
default名称空间中所有带role=db标签的 Pod 的6379端口:
- ipBlock 为
192.168.0.0/16网段,但是不包括192.168.0.0/24网段- namespaceSelector 标签选择器,匹配标签为
project=myproject- podSelector 标签选择器,匹配标签为
role=frontend- Egress规则(出方向白名单规则):
- 当如下条件满足时,允许出方向的网络流量:
- 目标端口为
5978- 目标 ipBlock 为
10.0.0.0/24网段
未完,待续>>>
参考:Kubernetes in Action