elasticsearch压力测试工具之ESrally使用说明
微信公众号:运维开发故事,作者:wanger
ESrally介绍
esrally是elastic search官方用于对ES集群进行压力测试的工具,使用esrally可以为我们构建不同版本集群,构造不同的参数和数据来进行压力测试,并且可以对产生的压测结果进行比较,rally顾名思义是拉力赛的意思,esrally的一些名词也都与拉力赛有关。
github地址:https://github.com/elastic/rally
ESrally安装
环境要求
python3.8 pip3
jdk8
git 1.9+
python3.8安装
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make libffi-devel
wget https://www.python.org/ftp/python/3.8.2/Python-3.8.2.tar.xz
tar -xvJf Python-3.8.2.tar.xz
mkdir /usr/local/python3
cd Python-3.8.2/
./configure --prefix=/usr/local/python3
make && make install
ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3
git 2.22安装
由于yum安装的git版本默认为1.8,因此我需要编译安装较新版本的git,如果已通过yum安装过git,可以使用yum remove git卸载
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker
cd /tmp
wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.22.0.tar.gz
tar xzf git-2.22.0.tar.gz
cd git-2.22.0
make prefix=/usr/local/git all
make prefix=/usr/local/git install
echo "export PATH=$PATH:/usr/local/git/bin" >> /etc/bashrc
source /etc/bashrc
jdk安装
rpm -ivh jdk-8u221-linux-x64.rpm
esrally安装
python3 -m pip install esrally
vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_221-amd64/jre
export PATH=$PATH:/usr/local/python3/bin/:/usr/local/git/bin JAVA_HOME
source /etc/profile
配置ESrally
用于定义一些数据的配置,可以选择把结果存储到已有的ES中进行分析
esrally configure
配置完成后,将会覆写ESrally的配置文件/root/.rally/rally.ini
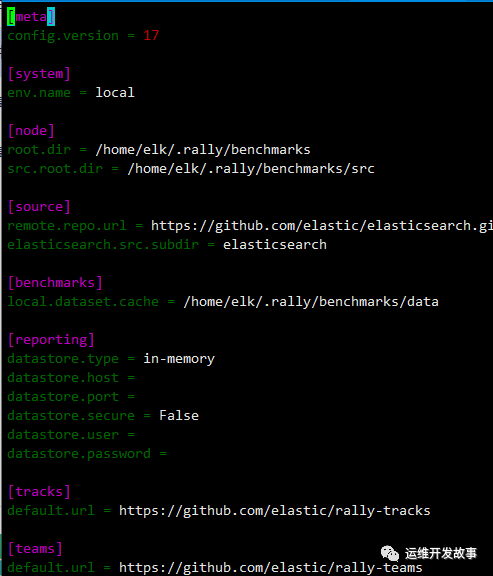 ESrally名词解释
ESrally名词解释
track
赛道的意思,用于构建不同的数据和策略进行压测,track.json定义压测的数据集,以geonames/track.json为例
{% import "rally.helpers" as rally with context %}
{
"version": 2,
"description": "POIs from Geonames",
"data-url": "http://benchmarks.elasticsearch.org.s3.amazonaws.com/corpora/geonames",
"indices": [
{
"name": "geonames",
"body": "index.json"
}
],
"corpora": [
{
"name": "geonames",
"base-url": "http://benchmarks.elasticsearch.org.s3.amazonaws.com/corpora/geonames",
"documents": [
{
"source-file": "documents-2.json.bz2",
"document-count": 11396503,
"compressed-bytes": 265208777,
"uncompressed-bytes": 3547613828
}
]
}
],
"operations": [
{{ rally.collect(parts="operations/*.json") }}
],
"challenges": [
{{ rally.collect(parts="challenges/*.json") }}
]
}
当我们开始用esrally开始比赛的时候,会先根据base-url和source-files构建链接从亚马逊下载数据,下载测试数据的速度很慢,我们可以提前下好离线数据来进行测试,测试数据存放在/home/elk/.rally/benchmarks/data/geonames目录下,indices定义了索引名和索引的具体设置,通过index.json文件可以查看
{
"settings": {
"index.number_of_shards": {{number_of_shards | default(5)}},
"index.number_of_replicas": {{number_of_replicas | default(0)}},
"index.store.type": "{{store_type | default('fs')}}",
"index.requests.cache.enable": false
},
"mappings": {
"dynamic": "strict",
"_source": {
"enabled": {{ source_enabled | default(true) | tojson }}
},
"properties": {
"elevation": {
"type": "integer"
},
"name": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"geonameid": {
"type": "long"
},
"feature_class": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"location": {
"type": "geo_point"
},
"cc2": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"timezone": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"dem": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"country_code": {
"type": "text",
"fielddata": true,
"fields": {
"raw": {
"type": "keyword"
}
}
},
"admin1_code": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"admin2_code": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"admin3_code": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"admin4_code": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"feature_code": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"alternatenames": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"asciiname": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"population": {
"type": "long"
}
}
}
}
operations目录下定义了压测的具体操作,包括索引的写入、更新、段合并、各种查询,每个操作都可以构建不同的参数,
{
"name": "index-append",
"operation-type": "bulk",
"bulk-size": {{bulk_size | default(5000)}},
"ingest-percentage": {{ingest_percentage | default(100)}}
},
{
"name": "index-update",
"operation-type": "bulk",
"bulk-size": {{bulk_size | default(5000)}},
"ingest-percentage": {{ingest_percentage | default(100)}},
"conflicts": "{{conflicts | default('random')}}",
"on-conflict": "{{on_conflict | default('index')}}",
"conflict-probability": {{conflict_probability | default(25)}},
"recency": {{recency | default(0)}}
},
{
"name": "default",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
}
}
},
{
"name": "term",
"operation-type": "search",
"body": {
"query": {
"term": {
"country_code.raw": "AT"
}
}
}
},
{
"name": "phrase",
"operation-type": "search",
"body": {
"query": {
"match_phrase": {
"name": "Sankt Georgen"
}
}
}
},
{
"name": "country_agg_uncached",
"operation-type": "search",
"body": {
"size": 0,
"aggs": {
"country_population": {
"terms": {
"field": "country_code.raw"
},
"aggs": {
"sum_population": {
"sum": {
"field": "population"
}
}
}
}
}
}
},
{
"name": "country_agg_cached",
"operation-type": "search",
"cache": true,
"body": {
"size": 0,
"aggs": {
"country_population": {
"terms": {
"field": "country_code.raw"
},
"aggs": {
"sum_population": {
"sum": {
"field": "population"
}
}
}
}
}
}
},
{
"name": "scroll",
"operation-type": "search",
"pages": 25,
"results-per-page": 1000,
"body": {
"query": {
"match_all": {}
}
}
},
{
"name": "expression",
"operation-type": "search",
"body": {
"query": {
"function_score": {
"query": {
"match_all": {}
},
"functions": [
{
"script_score": {
"script": {
"source": "abs(ln(abs(doc['population']) + 1) + doc['location'].lon + doc['location'].lat) * _score",
"lang": "expression"
}
}
}
]
}
}
}
},
{
"name": "painless_dynamic",
"operation-type": "search",
"body": {
"query": {
"function_score": {
"query": {
"match_all": {}
},
"functions": [
{
"script_score": {
"script": {
"source": "Math.abs(Math.log(Math.abs(doc['population'].value) + 1) + doc['location'].lon * doc['location'].lat)/_score",
"lang": "painless"
}
}
}
]
}
}
}
},
{
"name": "decay_geo_gauss_function_score",
"operation-type": "search",
"body": {
"query": {
"function_score": {
"query": {
"match_all": {}
},
"gauss": {
"location": {
"origin": "52.37, 4.8951",
"scale": "500km",
"offset": "0km",
"decay" : 0.1
}
}
}
}
}
},
{
"name": "decay_geo_gauss_script_score",
"operation-type": "search",
"body": {
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "decayGeoGauss(params.origin, params.scale, params.offset, params.decay, doc['location'].value)",
"params": {
"origin": "52.37, 4.8951",
"scale": "500km",
"offset": "0km",
"decay" : 0.1
}
}
}
}
}
},
{
"name": "random_script_score",
"operation-type": "search",
"body": {
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "randomScore(100, '_seq_no')"
}
}
}
}
},
{
"name": "large_terms",
"operation-type": "search",
"param-source": "pure-terms-query-source"
},
{
"name": "desc_sort_population",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
},
"sort" : [
{"population" : "desc"}
]
}
},
{
"name": "asc_sort_population",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
},
"sort" : [
{"population" : "asc"}
]
}
},
{
"name": "desc_sort_geonameid",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
},
"sort" : [
{"geonameid" : "desc"}
]
}
},
{
"name": "asc_sort_geonameid",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
},
"sort" : [
{"geonameid" : "asc"}
]
}
}
challenge指定了压测时执行的task,不同的track包含一个或多个challenge,“name”: "append-no-conflicts"表示默认的challenge为append-no-conflicts,执行esrally list tracks可以查看不同track支持的challenge,default为true时,为默认执行的challenge,schedule定义了执行的任务列表
{
"name": "append-no-conflicts",
"description": "Indexes the whole document corpus using Elasticsearch default settings. We only adjust the number of replicas as we benchmark a single node cluster and Rally will only start the benchmark if the cluster turns green. Document ids are unique so all index operations are append only. After that a couple of queries are run.",
"default": true,
"schedule": [
{
"operation": "delete-index"
},
{
"operation": {
"operation-type": "create-index",
"settings": {{index_settings | default({}) | tojson}}
}
},
{
"name": "check-cluster-health",
"operation": {
"operation-type": "cluster-health",
"index": "geonames",
"request-params": {
"wait_for_status": "{{cluster_health | default('green')}}",
"wait_for_no_relocating_shards": "true"
}
}
},
{
"operation": "index-append",
"warmup-time-period": 120,
"clients": {{bulk_indexing_clients | default(8)}}
},
{
"name": "refresh-after-index",
"operation": "refresh"
},
{
"operation": {
"operation-type": "force-merge",
"request-timeout": 7200
}
},
{
"name": "refresh-after-force-merge",
"operation": "refresh"
},
{
"name": "wait-until-merges-finish",
"operation": {
"operation-type": "index-stats",
"index": "_all",
"condition": {
"path": "_all.total.merges.current",
"expected-value": 0
},
"retry-until-success": true,
"include-in-reporting": false
}
},
{
"operation": "index-stats",
"warmup-iterations": 500,
"iterations": 1000,
"target-throughput": 90
},
{
"operation": "node-stats",
"warmup-iterations": 100,
"iterations": 1000,
"target-throughput": 90
},
{
"operation": "default",
"warmup-iterations": 500,
"iterations": 1000,
"target-throughput": 50
},
{
"operation": "term",
"warmup-iterations": 500,
"iterations": 1000,
"target-throughput": 150
},
{
"operation": "country_agg_uncached",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 3.6
},
{
"operation": "country_agg_cached",
"warmup-iterations": 1000,
"iterations": 1000,
"target-throughput": 100
},
{
"operation": "scroll",
"warmup-iterations": 200,
"iterations": 100,
"#COMMENT": "Throughput is considered per request. So we issue one scroll request per second which will retrieve 25 pages",
"target-throughput": 0.8
},
{
"operation": "expression",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 2
},
{
"operation": "painless_static",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.5
},
{
"operation": "painless_dynamic",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.5
},
{
"operation": "decay_geo_gauss_function_score",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1
},
{
"operation": "decay_geo_gauss_script_score",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1
},
{
"operation": "field_value_function_score",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.5
},
{
"operation": "field_value_script_score",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.5
},
{
"operation": "random_function_score",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.5
},
{
"operation": "large_filtered_terms",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.1
},
{
"operation": "large_prohibited_terms",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 1.1
},
{
"operation": "desc_sort_geonameid",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 6
},
{
"operation": "asc_sort_geonameid",
"warmup-iterations": 200,
"iterations": 100,
"target-throughput": 6
}
]
},
{
"name": "append-fast-with-conflicts",
"description": "Indexes the whole document corpus using a setup that will lead to a larger indexing throughput than the default settings. Rally will produce duplicate ids in 25% of all documents (not configurable) so we can simulate a scenario with appends most of the time and some updates in between.",
"schedule": [
{
"operation": "delete-index"
},
{
"operation": {
"operation-type": "create-index",
"settings": {%- if index_settings is defined %} {{index_settings | tojson}} {%- else %} {
"index.refresh_interval": "30s",
"index.number_of_shards": {{number_of_shards | default(6)}},
"index.translog.flush_threshold_size": "4g"
}{%- endif %}
}
},
{
"name": "check-cluster-health",
"operation": {
"operation-type": "cluster-health",
"index": "geonames",
"request-params": {
"wait_for_status": "{{cluster_health | default('green')}}",
"wait_for_no_relocating_shards": "true"
}
}
},
{
"operation": "index-update",
"warmup-time-period": 45,
"clients": {{bulk_indexing_clients | default(8)}}
},
{
"operation": {
"operation-type": "force-merge",
"request-timeout": 7200
}
},
{
"name": "wait-until-merges-finish",
"operation": {
"operation-type": "index-stats",
"index": "_all",
"condition": {
"path": "_all.total.merges.current",
"expected-value": 0
},
"retry-until-success": true,
"include-in-reporting": false
}
}
]
}
car
用于定义不同配置的ES实例,我们可以定义堆内存大小,垃圾回收器,既然是赛车,那就可以改装,我们可以自定义不同配置的car,执行命令esrally list car可查看所有的赛车,配置在/home/elk/.rally/benchmarks/teams/default/cars/v1目录下
 race
race
表示某一次的压测,并且可以指定赛道和赛车配置,不指定则使用默认配置,race结果存储在/home/elk/.rally/benchmarks/races目录下,执行命令esrally list races可查看以往比赛结果
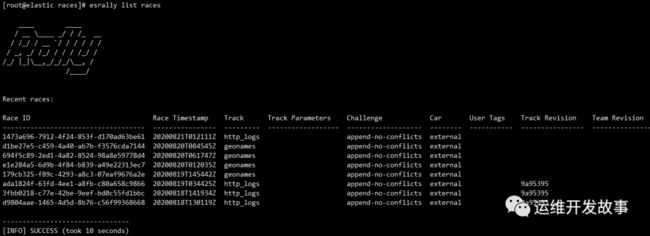 并且可以对不同的race进行比较
并且可以对不同的race进行比较
esrally compare --baseline=d1be27e5-c459-4a40-ab7b-f3576cda7144 --contender=694f5c89-2ed1-4a82-8524-98a8e59778d4
 pipeline
pipeline
就是定义以何种方式来构建这个集群,通过esrally list pipelines可查看所有的pipeline

-
from-sources-complete :表示从源代码构建ES, --revision参数可以指定一个ES的修订版本,默认为最新版本、
-
from-sources-skip-build :表示如果之前已经通过源码构建过一次相同版本的ES了,那么本次将不再进行构建,这样可以节省测试的时间
-
from-distribution:esrally将下载正式的ES发行版来进行测试, --distribution-version 参数可以指定ES版本,最低支持1.7.5
-
benchmark-only :将对已有的ES集群进行压测,–target-hosts参数可以指定ES集群地址
ESrally压测实例
测试5.4.3、6.4.3与7.8.1版本之间的写入性能差异
使用非root用户运行,并且保证内存够用,这里我是用geonames赛道进行测试,使用默认的car为1gb堆内存,为了快速测试,可以将测试数据和ES二进制包提前下到指定的目录下,ES二进制包存储在/home/elk/.rally/benchmarks/distributions目录下,测试数据存放在/home/elk/.rally/benchmarks/data/geonames目录下
esrally race --distribution-version=5.4.3 --track=geonames --user-tag="version:5.4.3" --include-tasks="type:bulk"
esrally race --distribution-version=6.4.3 --track=geonames --user-tag="version:6.4.3" --include-tasks="type:bulk"
esrally race --distribution-version=7.8.1 --track=geonames --user-tag="version:7.8.1" --include-tasks="type:bulk"
压测过程可以通过/home/elk/.rally/logs.log查看
 对压测结果进行比较
对压测结果进行比较
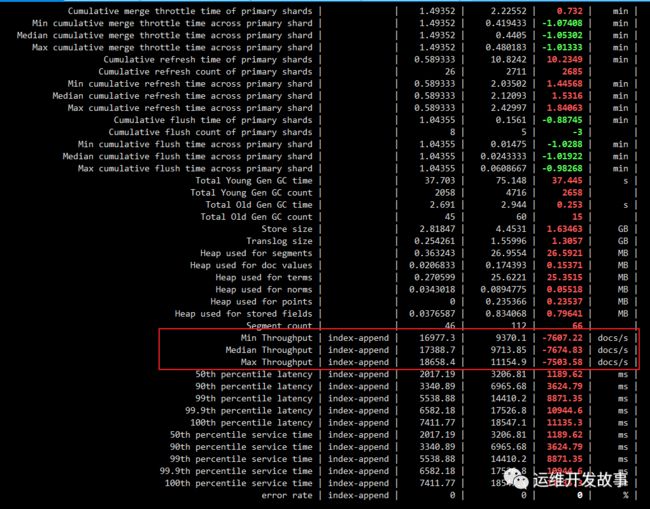
比较7.8.1与5.4.3的写入差异
esrally compare --baseline=27265e6e-566a-4a47-a0d9-1fd2f8830041 --contender=66086ef0-5834-4743-a870-fd9c0bb41688
 可以看到5.4版本的写入性能差别还是很大的
可以看到5.4版本的写入性能差别还是很大的
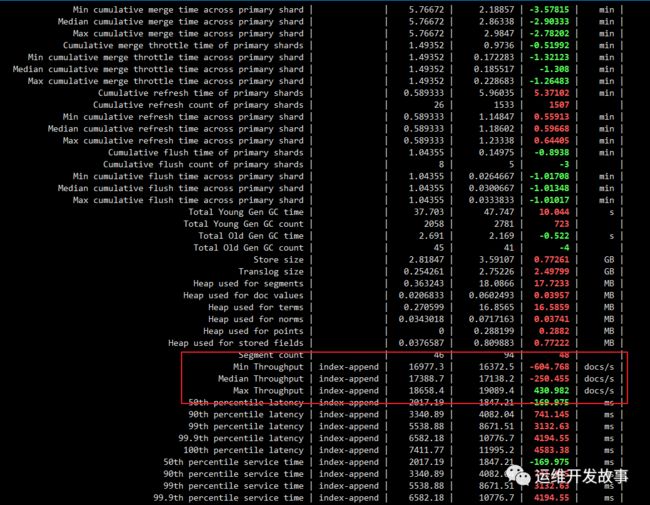
 再看一下6.4.3与7.8.1的差异,写入性能差别不是很大
再看一下6.4.3与7.8.1的差异,写入性能差别不是很大
esrally compare --baseline=27265e6e-566a-4a47-a0d9-1fd2f8830041 --contender=b02fb6fe-824f-48ee-beb5-ab2ca2ad4bbc
 测试x86_64平台与arm平台的性能差异
测试x86_64平台与arm平台的性能差异
环境
阿里云2v4g 志强Platinum 8269CY CPU 2.50GHz x86_64
华为云2v4g 鲲鹏920 CPU 2.6GHz arm平台
两台云主机的ES配置均相同,2G堆内存,系统参数相同
开始测试
还是要提前下好测试数据,这个测试周日跑了一天,结果截图没保存,可能配置太低了,结果差别不是很大,而且不是在同一台机器上跑的,没法使用esrally compare进行比较
esrally race --pipeline=benchmark-only --target-hosts=172.16.0.95:9200 --track=http_logs --offline
esrally race --pipeline=benchmark-only --target-hosts=172.26.214.32:9200 --track=http_logs --offline
中间遇到的问题
开始压测之后,报不能进入比赛,pid文件不可用
 之后查看了相关race的日志,发现内存不够用了,因为之前已经跑了一个ES实例了,导致了我内存不足,把之前的ES实例关掉即可解决
之后查看了相关race的日志,发现内存不够用了,因为之前已经跑了一个ES实例了,导致了我内存不足,把之前的ES实例关掉即可解决
 参考链接:https://esrally.readthedocs.io/en/stable/quickstart.html
参考链接:https://esrally.readthedocs.io/en/stable/quickstart.html
- END -
公众号:运维开发故事
github:https://github.com/orgs/sunsharing-note/dashboard
爱生活,爱运维
如果你觉得文章还不错,就请点击右上角选择发送给朋友或者转发到朋友圈。您的支持和鼓励是我最大的动力。喜欢就请关注我吧~

扫码二维码
关注我,不定期维护优质内容
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。
........................