远程小组软件开发过程(2):工具
工欲善其事,必先利其器,我们以 CSDN 技能树的分层构架和工具链构建为例子,展示投资工具链在软件开发中的好处。流畅的工具链,是软件开发团队效能的关键之一。
技能树功能描述
CSDN技能树是一个在线的领域技术学习社区,我们以最新发布的“网络技能树”为例,先简单介绍下它的核心功能。
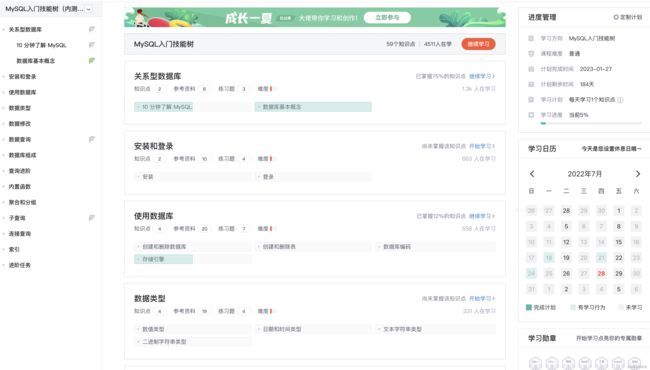
技能树首页左侧包含了技能树的章/节结构,中间展示了用户在每个章节的学习进度,右侧则是技能树的用户答题榜单和技能树贡献者榜单。我们点开“路由表的工作原理”一节,可以看到每个节是一个“节社区”,每个“节社区”由“参考资料”、“练习题”、“交流讨论”、“我的笔记”四个频道构成。
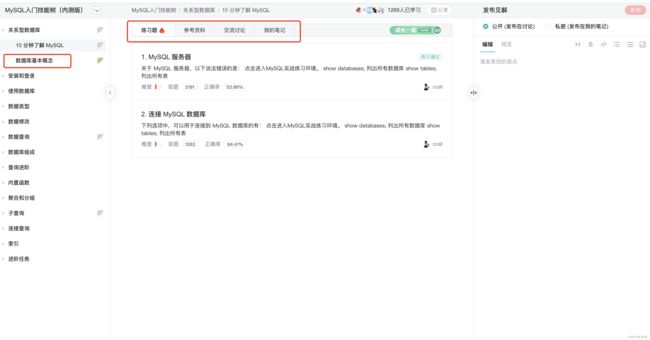
其中:
- 章/节结构,需要由人来编辑创建,每一节是一个小社区,对应着“参考资料”、“练习题”、“交流讨论”、“笔记”四个频道。
- 参考资料可以通过算法匹配合适的资料。
- 练习题需要人来编辑创建,每个练习题的创建者会展示在习题信息上。
- 每个练习题在交流讨论区里有一个对应的讨论贴
- 我的笔记频道是用户在该节上的私密笔记,数据发布到了用户在CSDN上的个人私密社区。
练习题视图和答题页面如下:
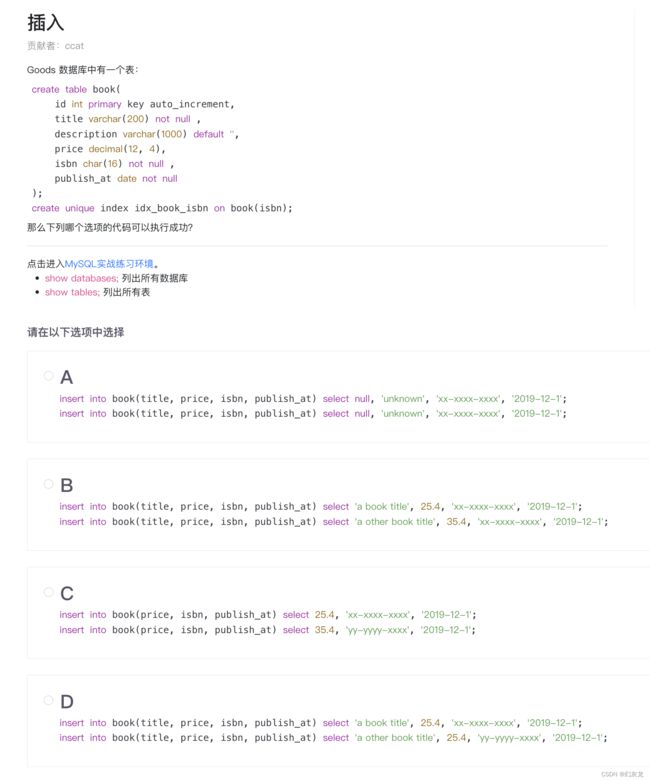
技能树构架分层分析
为了说明工程构建上的设计,需要先对CSDN技能树的构架有一个基础的了解,技能树工程开发在构架上分为3层来解除耦合:
- 后端:
- 技能树数据层服务
- 用户业务层服务
- 前端
- 技能树社区前端
其中,技能树数据层服务大体上包含一组核心API:
- 资源创建
- 创建技能树章/节骨架数据
- 创建技能树节社区数据
- “节社区”创建API:
- 创建一个“节社区”,该“节社区”包含“参考资料”、“练习题”、“交流讨论”、“笔记”四个频道。
- 但是每个频道的数据都是空的。
- “节社区”创建API:
- “节社区”下频道帖子资源创建
API- 通过AI算法匹配并挂载参考资料
- 挂载习题
- 创建习题讨论贴
- 创建笔记贴
- 资源查询
- 获取技能树章/节骨架
API- 完整的章/节结构数据
- 每个节所对应的“节社区”信息和频道信息。
- 获取技能树章/节骨架
- 获取指定节的频道数据
API- 获取节的参考资料数据
- 获取节的习题信息
- 获取节的交流讨论贴
- 获取节的笔记贴
其中,技能树用户业务层服务提供:
- 转发技能树数据层接口
- 记录用户在“节社区”里的交互数据
- 浏览/阅读参考资料进度
- 答题进度
- 笔记
- 合成用户在技能树上的学习进度
- 每节的学习进度
- 整个技能树的学习进度
- 学习榜单
上述是技能树社区的大致构架分层,我们不打算把每层在工程上如何做“编译/构建”都展开讲,我们会屏蔽知识,重点放在“技能树数据层”来重点展示工程上如何做好“编译/构建”。
其中,“技能树数据层”又分为两大部分:
- 技能树数据服务。
- 技能树数据处理管道。
我们分别讲解这两部分如何做好“编译/构建”工作。
技能树数据服务的编译/构建
正如前面提到的,技能树数据服务按顺序,分别在如下几个维度来建立规范化的编译/构建
源代码管理
项目采用git做源代码版本管理,项目的源代码包含三个分支:
- 开发分支
dev - 测试分支
test - 正式分支
pro
通常来说,test分支代码从 dev 分支单线合并过来,然后去测试服务器上测试,测试通过后才能合并到pro分支,合并路线只能是:dev->test->pro.
环境配置
项目的环境配置采用阿波罗配置中心服务:https://gitcode.net/mirrors/ctripcorp/apollo/-/blob/master/docs/zh/README.md
项目为不同环境配置了3套不同的配置
- 开发环境配置
- 测试环境配置
- 生产环境配置
不同环境配置,主要配置了不同环境下依赖的数据库、缓存、仓库…等各种账号信息。以及一些不同环境下服务功能的开关配置等。配置会做一些访问限制,杜绝不同环境的配置被错误的使用,例如:
- 开发环境的配置只能在内网被访问。
- 测试和线上环境不能在开发环境访问。
服务器集群配置
项目编译和构建之后,最终是要运行的。在理解项目的其他配置之前,首先需要理解项目运行的服务器配置。
技能树服务的服务器包含了三类:
- 开发环境主机
- 用户可以在自己本机完成许多开发环境的代码编写和自测。
- 但是服务背后总是有数据的,每个人机器上都配置一套数据会带来很多数据同步的问题。因此在内网会有一个开发机器,部署开发环境的公共数据库。
- 在开发机上,主要跑的是dev分支的源代码,只允许使用开发环境配置。
- 测试环境服务器
- 有些团队会使用内网的一台机器作为测试环境服务器。但是这会带来一些和云主机不同的环境问题,从而隐藏
BUG。技能树数据服务使用一台低配的云主机来做测试环境服务器来规避这个问题,j尽早发现问题。 - 技能树服务内部是一个简明的微服务构架,每个主机上拉的代码都是同构的,在不同的主机上可以按需指定参数启动不同的分组子服务,每个分组子服务也可以启动多个实例。但是在测试服务器上会把全部子服务做为一个大的分组,强制只启动一个实例。
- 这样做的目的是:如果这些服务全部合并在一起在一个低配版的主机上不能支持组内测试和提供给其他团队测试联调,那么它一定隐藏了性能问题,需要被解决。
- 在测试服务器上,只能跑
test分支代码,只允许使用测试环境配置。
- 有些团队会使用内网的一台机器作为测试环境服务器。但是这会带来一些和云主机不同的环境问题,从而隐藏
- 生产环境集群
- 生产环境服务器有多台,每台机器上都有完整的代码。
- 按需运行指定的分组服务。
- 在生产环境服务器上,只能跑
pro分支代码,只允许使用正式环境配置。
- 预发布服务器
- 事实上,生产环境集群服务器,会按需预留一台做预发测试,一般是和做离线任务的服务器共用,避免影响线上环境。
微服务管理
微服务代码的组织方式,可能每个服务都是一个独立的project,每个project都需要独立的git仓库,每个服务都需要独立的编译/构建/部署。这种碎片式的方式会带来开发和源代码管理上的碎片化。
我们做微服务管理的方式和通常的做法有一些差异,但是是一种便利的方式。我们在一个git仓库里管理好整个系统的微服务。
代码上的组织是这样的:
- 代码有一组公共类库、基础组件。
- 每个子服务一个独立的文件夹。
- 每个子服务内部有分组路由,子服务+具体分组构成了一个最终的微服务。
- 每个子服务有一个入口,根据命令行参数和配置决定要启动哪个分组路由。
这样的方式,我们可以灵活组合满足各种不同需求的微服务。通过仔细设计的命令行参数,可以精确地启动目标微服务。
这种方式的优点是:
- 集中式管理系统的所有微服务代码,避免碎片化。
- 可以按需精细控制启动哪个微服务。
命令行设计(1):config+options
根据上面的讨论,环境上有3个维度:
- 代码分支(
dev/test/pro) - 环境配置(
dev/test/pro) - 服务器(
dev/test/pro)
它们构成了如下的组合:
| config | 代码分支 | 环境配置 | 服务器 | 允许运行 |
|---|---|---|---|---|
| dev | dev | dev | dev | yes |
| test | test | test | test | yes |
| pro | pro | pro | pro | yes |
我们让程序都是通过命令行启动的。这样通过指定命令行参数--config 来指定:
--config dev: 此时启动的时候会使用dev环境配置,只能在开发机器使用,严格来说也要检查代码的分支是否是dev,但是有时候我们会需要在开发环境跑下test和pro分支的代码是否正常。--config test: 此时启动的时候会使用test环境配置,只能在测试服务器使用,同时检查代码的分支是否是test。--config pro: 此时启动的时候会使用pro环境的配置,只能在正式服务器使用,同时检查代码的分支是否是pro。
命令行—config 指定的环境配置会被解析到一个叫config的key-value字典。而命令行的其他参数会被解析到一个叫 options 的key-value字典里。这样,程序启动后有两个重要的配置信息,构成了程序运行的控制上下文:
- 来自配置中心的
config - 来自命令行选项的
options
命令行设计(2): 路由
根据上面的讨论,微服务需要通过命令行来精细控制。这是怎么做到的呢?事实上,我们设计了一种有层次的命令行参数指定方式,直接通过例子说明,假设程序是 xxx,下面的例子说明了给xxx程序传递的命令和行为,以开发环境配置为例:
- 启动包含全部服务的分组:
python main.py server.main --clusetr dev
- 启动技能树主服务:
python main.py server.skill_tree.main --clusetr dev
- 启动技能树的匹配专用的服务:
python main.py server.skill_tree.match --clusetr dev
可以看到我们通过指定 aaa.bbb.ccc.ddd 这样的格式,可以让命令行程序精细指定启动哪一个粒度的服务。我们把这个叫做“使用.分隔的命令行路由”
实际上,有了命令行路由,我们顺便解决了很多场景的控制问题:
- 如何组织单元和模块测试代码?
- 把测试代码有层级的分文件夹组织好。
- 通过约定格式和动态构建路由,可以在命令行下便利地指定启动哪个测试
- 例子:
python main.py test.skill_tree.basic.test_get_tree_namepython main.py test.skill_tree.view.test_get_tree_namepython main.py test.tag.test_classfier
- 添加一个测试代码只需在对应目录下创建代码,添加含有
test_xxx(config, options)签名风格的测试函数即可。 - 同时,我们加了一个
always_run的定时服务,定时调用api单元测试程序并根据情况通过机器人发送警告信息。
- 如何组织AI程序的数据集管理和模型管理。
- 在技能树服务里,内部需要管理机器学习/深度学习的数据集和模型
- 通过命令路由,就可便利地组织,配合
—config即可控制不同环境的数据管理。 - 数据集管理例子:
- 构建某个数据集:
python main.py dataset.minist.build - 上传某个数据集:
python main.py dataset.minist.upload - 下载某个数据集:
python main.py dataset.minist.download
- 构建某个数据集:
- 模型管理例子:
- 训练某个模型:
python main.py model.tag.train - 上传某个数据集:
python main.py model.tag.download - 下载某个数据集:
python main.py model.tag.upload
- 训练某个模型:
包管理
每个技术栈都有对应的管理软件。例如 python 的包管理器是 pip,就是在项目根目录下配置一个requirements.txt的配置文件,里面指定好各种依赖的包版本,然后使用pip install -r requirements.txt来在不同环境安装依赖包即可。
但是这里有一个痛点问题:python 的依赖包解析问题。例如:
A包依赖B包,B包内部依赖C包D包依赖C包
此时,A间接依赖的C包,和D依赖的C包的版本要求可能不同,因此在包配置多了之后,可能出现包管理软件无法正确解析包版本依赖的问题。有时候这是隐性的问题:在你的开发机器上由于某种巧合,包配置并没有在你的机器上产生包依赖冲突。但是上线的时候,发现服务器上总是不能正确解析包依赖。
因此,项目要需要针对不同的技术栈,使用对应的包冲突解决方式。一种典型的方式就是“预先检查”。例如,python提供了一个叫做“pip-compile”的工具。你可以配置一个包依赖输入文件requirements.in,通过pip-compile requirements.in来预先检查,工具会告诉你哪些包版本冲突了,详细告诉你冲突来自哪里。于是开发者可以通过精细调整顺序和版本,来解决冲突。完整解决冲突后,工具会生成一个安全的requirements.txt文件。这样就避免了你在线上环境需要解决包依赖问题。这也是一个“编译问题”:确保通过编译来提前解决线上环境的冲突问题。
当然,如果使用了docker,这些问题也就在虚拟化层就解决了。但是虚拟化有性能损耗,并非所有开发目前都适合。有时候 keep it simple是最合适的。
技能树数据管道的编译/构建
技能树除了内部的服务,还有另外一个重要的部分是,由社区贡献者共同构建每个领域的技能树。我们是怎么做到外部贡献者贡献的数据和内部服务之间的无缝集成呢?
首先,我们建立了一个“技能森林”的索引仓库:
https://gitcode.net/csdn/skill_tree
但是每个具体领域的技能树独立一个编辑仓库,例如这个网络技能树的开放构建仓库:
https://gitcode.net/csdn/skill_tree_network
通过每个领域技能树独立一个编辑仓库的方式,解除了不同技能树设计编辑的解耦。外部用户会通过在VSCode里,用约定的格式编辑技能树的章/节目录结构,并且在节目录下按模版添加选择题习题markdown文件

社区贡献者,在对应的领域技能树编辑仓库里,可以放心的提交,因为仓库的数据没有被使用之前是静态的数据:只是由git仓库有版本地管理。这是技能树在社区用户“构建”这个步骤提供的解决方案:使用一套经过设计的模版,可以在VSCode里便利地构建,安全地提交。
每个技能树编辑仓库下,提供了一个python 构建脚本 main.py. 这个脚本的作用是:
- 为每个章/节,生成一个
config.json文件,同时为每个config.json生成一个node_id。 - 为每个习题
markdown文件xxx.md生成一个同名的xxx.json文件,同时生成习题的id: exercises_id - 生成技能树的骨架元数据:tree.json
这么做有什么好处呢?大部分情况下,生成的id是不会被编辑者改动的。因此用户重命名文件和文件夹、移动文件和文件夹,文件id都是存在的。我们的工具链就可以根据这些id在内部做匹配,从而做到文件文件夹的位置变动跟踪。这些跟踪就可以进一步在安全的管道里,通过内部的技能树服务API,同步到数据库。
如果在核心章节习题都提交的差不多的时候。技能树的结构数据(章/节、习题)就会被技能树管道工具来处理。技能树管道工具目前是一个内部仓库,会在内部提供一组操作命令:
- 在开发环境导入网络技能树仓库数据,这里会对node_id/exercises_id做校验
python main.py skill_tree.debug.network.import --cluster dev
- 在开发环境下调用技能树服务的api来创建节社区相关的资源(社区/频道):
python main.py skill_tree.debug.network.section.init --cluster dev
- 在开发环境下调用技能树服务的api来发送节社区的讨论交流频道帖子
python main.py skill_tree.debug.network.section.post --cluster dev
- 在开发环境下调用技能树服务的api来创建骨架和同步习题数据
python main.py skill_tree.debug.network.sync --cluster dev
- 在开发环境下调用技能树服务的api来触发AI算法挂载参考资料到节上
python main.py skill_tree.debug.network.mount --cluster dev
- 在开发环境下调用业务层api来通知业务数据层更新技能树数据,将变动上线到前端
python main.py skill_tree.debug.network.deploy --cluster dev
其中命令路由的第二个子路由debug表示,这是在测试环境调试技能树。如果测试环境数据都没有问题,就可以对生产环境重复上述过程。例如:
python main.py skill_tree.release.network.import --cluster pro
注意,管道工具的 --cluster 依然是用来控制管道工具的环境配置依赖,里面配置了每个不同技能树相关的账号依赖等重要信息。有了 cluster 参数,为什么还需要在命令路由里有 debug/release 区分呢?这个是为了
- 将
dev/test环境合并看成一个debug测试维度。 - 将
pro环境看成是release环境。
构建中的重要的元数据,都会在管道工具仓库里保存并提交到git。便于后续的更新操作对数据的校验、去重。
可以看到每个子命令内部,都会有相关的访问技能树数据服务api的操作。管道工具的每个子命令对各种数据格式转换、资源创建等做了细致的错误处理。其基本原则是遇错就立刻退出,而不是隐藏BUG。
如果在开发/测试环境,管道工具将社区贡献者一起贡献的技能树数据成功的转换、构建、并成功的在测试环境预览界面上完成验证。那么就可以去预发环境上再测试下,最后在正式环境上完成构建/编译和部署。
自动化
到目前为止,我们并没有提到“自动化”。一方面我们在项目实践中是根据需求按需演化,不同阶段需要解决不同的问题。全流程的自动化编译/构建/部署/上线并非是一个急需问题,我们目前的方式在实践中:
- 有着足够好的对编译/构建的环境的解决。
- 有着足够好的不同粒度数据集、模型、服务、管道操作控制。
工程上的两个重要的部分流程和工具,我们对源码、仓库、服务、数据、模型的组织是反碎片化的,工具是半自动化的。有着良好的命令行设计,自动化只是在自动化系统里把这些命令集成进去而已。
小结
本节我们对项目中的工具链设计做了分析。实际上,工具链的设计体现了我们对项目的分层构架的理解,对程序、数据、环境、树状结构API的理解。工具解决工程中繁杂的碎片问题,从而软件开发团队可以规避大量的碎片问题,流畅地迭代。