压缩视频增强调研
从一个比赛说起
NTIRE 2021 视频质量增强竞赛 (Challenge on Quality Enhancement of Compressed Video)由瑞士苏黎世联邦理工学院(ETH Zurich)博士研究生 Ren Yang(本人)及导师 Dr. Radu Timofte 主办,为 NTIRE Workshop(CVPR 2021)的竞赛之一。这次比赛为CVPR贡献了很多优秀的论文,认真分析总结这次比赛优秀的视频增强网络是特别有必要的。
NTIRE 2021压缩视频质量增强挑战:赛有几个比赛的赛道,关于增强压缩视频的NTIRE 2021挑战赛的目标是:(一)提高视频质量增强的技术水平;(二)比较不同的解决办法;(三)推广新提议的LDV数据集;以及(四)研究更具挑战性的视频压缩设置上的质量增强。该比赛是整个2021年的相关挑战之一:非均匀去雾、使用双像素的散焦去模糊、深度引导图像重新照明、图像去模糊、多模态鸟瞰图像分类、学习超分辨率空间、压缩视频的质量增强(本报告)、视频超分辨率、感知图像质量评估、突发超分辨率。和高动态范围成像。
以前的视频增强的方法(2020年之前)
随着高质量,高分辨率视频的需求增加,为了在有限的带宽上传输更多数量的高分辨率视频,必须采用视频压缩来降低比特率。压缩视频不可避免的会带来伪影,并可能导致视频质量的退化,这是视频增强的必要性。在过去的几年,已经有大量的工作在这个方向,其中单帧质量增强方法是最先提出的,后来又有人提出多帧质量增强。此外,有的网络专注于提高压缩视频的感知质量,有网络专注于提高峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)的性能,以实现对未压缩视频的更高保真度。这些工作表明了这一研究领域的广阔前景。
IPB帧
视频压缩中,每帧都代表着一幅静止的图像。而在进行实际压缩时,会采取各种算法以减少数据的容量,其中IPB帧就是最常见的一种。
I帧:帧内编码帧(intra picture),I帧通常是每个GOP(MPEG所使用的一种视频压缩技术)的第一帧,经过适度地压缩,作为随机访问的参考点可以当成静态图像。I帧可以看做一个图像经过压缩后觉得产物,I帧压缩可以得6:1的压缩比而不会产生任何可觉察的模糊现象。I帧压缩可去掉视频的空间冗余信息,下面即将介绍P帧和B帧是为了去掉时间冗余信息。
P帧:前向预测编码在帧(predictive-frame),通过将图像序列中前面已编码帧的时间冗余信息去充分去除压缩传输数据量的编码图像,也成为预测帧。
B帧:双向预测内插编码帧(bi-directionalinterpolated prediction frame),既考虑源图像序列前面的已编码帧,又估计源图像序列后面的已编码帧之间的时间冗余信息,来压缩传输数据量的编码图像,也成为双向预测帧。
基于上面的定义,我们可以从解码的角度来理解IBP帧。
I帧自身可以通过视频解压算法解压成一行单独的完善的完整视频画面,所以I帧去掉视频帧在空间维度上的冗余信息。
P帧需要参考其前面一个I帧或者P帧来解码成一张完整的视频画面。
B帧则需要参考前一个I帧或者P帧及其后面一个P帧来生成后面一张完整的视频画面,所以P帧与B帧去掉是视频在时间维度上的冗余信息。
单帧视频增强
1.DSCNN网络

Ren Yang, Mai Xu, and Zulin Wang. Decoder-side HEVC quality enhancement with scalable convolutional neural network.In Proceedings of the IEEE International Conferenceon Multimedia and Expo (ICME), pages 817–822. IEEE,2017. 1, 2
DSCNN网络是在ARCNN网络的基础上提出的,经典的ARCNN网络有四层网络结构:提取特征、去噪、非线性映射(1x1的卷积,类似于全连接层)、重构。DSCNN中设计了一个具有两个子网络的可伸缩结构,这样,解码后的HEVC视频的质量增强可以根据不同的计算资源进行调整。DS-CNN包括DS-CNN-I和DS-CNN-B两个子网络,分别用于增强I帧和B/P帧的质量。实验结果表明了DS-CNN方法在提高HEVC的I /P帧和B/P帧质量方面的有效性。(I帧保留了最全的信息,I帧可以指导B/P帧的增强)。
2.QECNN网络
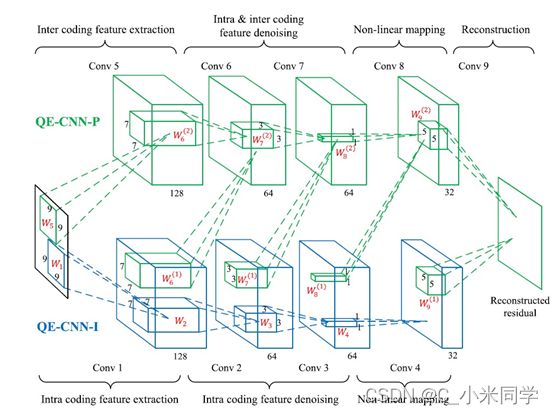
Ren Yang, Mai Xu, Tie Liu, Zulin Wang, and Zhenyu Guan.Enhancing quality for HEVC compressed videos. IEEETransactions on Circuits and Systems for Video Technology,2018. 1
我们可以看见,上面两个网络是同一个团队的,大同小异,QECNN也是在ARCNN网络上做出的改进,QE-CNN方法学习了QE-CNN-I和QE-CNN-P模型,分别降低了HEVC I和P/B帧的失真。该方法不同于现有的基于cnn的质量增强方法(以前只增强I帧,没有增强预测帧B/P帧),后者仅处理编码内失真,因此不适用于P/B帧。该方法能够有效提高HEVC视频的I帧和P/B帧的质量。唯一与DSCNN很大不同的是,为了将QE-CNN方法应用于时间约束的场景,该团队进一步提出了一种时间约束的质量增强优化(TQEO)方案。TQEO方案控制了QE-CNN的计算时间以满足一个目标,同时最大限度地提高了质量。实验结果表明,在不同的时间约束条件下,从时间控制精度和质量提高两个方面验证了TQEO方案的有效性。
3.DCAD网络
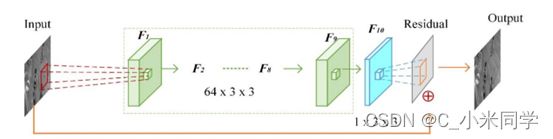
Tingting Wang, Mingjin Chen, and Hongyang Chao. Anovel deep learning-based method of improving coding efficiency from the decoder-end for HEVC. In Proceedings of the Data Compression Conference (DCC), pages 410–419.IEEE, 2017. 1, 2
DCAD是一种全端到端前馈网络,他同样是基于ARCNN网络改进得到,运行速度比基于压缩感知的方法快得多,编码效率也更高。对于一些后续计算机视觉任务的需求,DCAD还可以作为一个扩展选项来生成更高质量的输入视频。实验结果表明,该方法不仅可以提高I帧的编码效率,而且可以提高B帧和P帧的编码效率。
4.存在问题
单帧视频增强的网络相对简单,训练较快,但是预测效果较差,不能充分利用视频帧与帧之间的时序信息。现在主流的网络都是多帧视频增强。
多帧视频增强
1.MFQE1.0
在谈到多帧视频增强前,我们先来看一下,一个视频帧序列的PSNR。
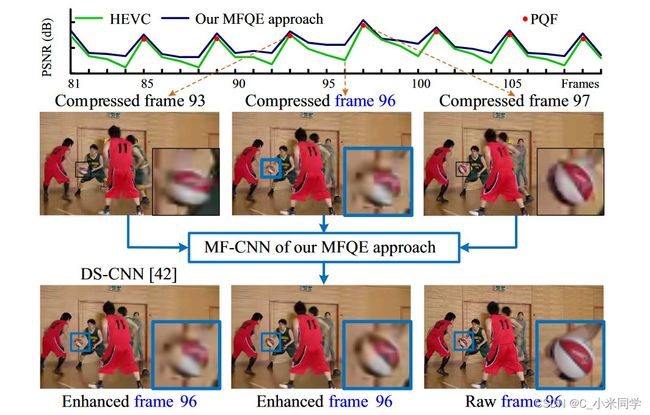
视频帧PSNR变化
通过上图,我们可以看见,一个视频帧序列的PSNR有一定的周期性变化,有的帧的PSNR高,有的又特别低,我们把高PSNR的帧称为高质量帧(PQF),低PSNR的帧称为低质量帧(非PQF)。MFQE网络的核心思想就是:通过两个PQF来增强一个非PQF帧。
那么,如何检测一个帧序列的PQF?端口向量机(SVM)作为一种检测PQF的无参考方法。然后,提出了一种新型的多帧CNN (MF-CNN)结构,该结构将当前帧和相邻的PQF作为输入。MF-CNN包括两个组成部分,即运动补偿子网(MC子网)和质量增强子网(QE子网)。
MC子网是用来补偿当前非PQF与其相邻PQF之间的运动的。该子网采用时空结构,用于提取和合并当前非PQF和补偿PQF的特征。最后,利用相邻PQF中的高质量内容,qsubnet可以提高当前非PQF的质量。
如上图所示,当前的非PQF(第96帧)和最近的PQF (第93帧和第97帧)被输入到我们MFQE方法的MF-CNN中。
因此,非PQF (第96帧)的低质量内容(篮球)可以在相同的内容上得到增强,但在相邻的PQF(第93帧和第97帧)中具有高质量。
此外,上图显示我们的MFQE方法也减轻了质量波动,因为非PQF的质量有了相当大的改善。

Ren Yang, Xiaoyan Sun, Mai Xu and Wenjun Zeng, "Quality-Gated Convolutional LSTM for Enhancing Compressed Video", in IEEE International Conference on Multimedia and Expo (ICME), 2019.
本文的主要贡献是:
(1)分析了各种视频编码标准压缩后的视频序列的帧级质量波动。
(2)我们提出了一种新的基于CNN的MFQE方法,该方法利用相邻的PQF来减少非PQF的压缩伪影。
2.STDF网络

给定一个2R + 1帧级联的压缩视频剪辑,首先采用偏移量预测网络生成可变形偏移量场。利用该偏移场(运动估计),进行时空变形卷积(运动、补偿),融合时间信息,生成融合的特征图。最后,利用QE网络计算增强残差映射,将残差映射重新添加到压缩后的目标帧中,得到最终的增强结果。上图展示了STDF网络的框架,它由一个时空变形融合(STDF)模块和一个质量增强(QE)模块组成。
STDF模块以目标帧和参考帧为输入,通过时空可变形卷积融合上下文信息,其中可变形偏移量由偏移量预测网络自适应生成。然后,通过融合特征映射,QE模块引入全卷积增强网络来计算增强结果。由于STDF模块和QE模块都是卷积的,所以我们统一的框架可以端到端进行训练。
3.MFQE2.0
MFQE2.0在MFQE1.0上的最大改变就是检测视频帧序列的PQF帧不同,MFQE2.0首先训练一个基于双向长短期记忆(BiLSTM)的模型作为一个无引用的方法来检测PQF。然后,提出了一种新型的多帧CNN (MF-CNN)结构,该结构将当前非PQF和相邻的PFQ作为输入,用于非PQF的质量增强。

4.存在问题
然而,以往方法的训练集规模是递增的,不同的方法也是在不同的测试集上进行测试的。也就是说,我可以以前的网络通过大量的压缩视频来训练,通过大数据来提升网络质量,其次,网络中,使用的训练数据是不一样的,在进行不同网络的横向比较时,不是很客观。
现在的压缩视频增强方法(2021年)
NTIRE 2021压缩视频质量增强的挑战赛上,出现了很多优秀的增强网络,他们几乎都是基于前面提的的网络的一个改进,在这次比赛中,引入了一个大规模多样化视频(LDV)数据集,这个数据集可以让让我们训练出更适合压缩视频增强的网络。在这次视频增强比赛中,又有三个赛道:Track 1和Track 2旨在增强HEVC在固定QP下压缩的视频Track 3旨在增强x265在固定比特率下压缩的视频。
这三条赛道共吸引了482人报名。在测试阶段,分别有12支队伍、8支队伍和11支队伍提交了track1、track2和track3的最终结果。
注意:Track 1和Track 3的质量增强目标是提高保真度(PSNR), Track 2的质量增强目标是提高感知质量。
以下是三个赛道前几名的排名情况。
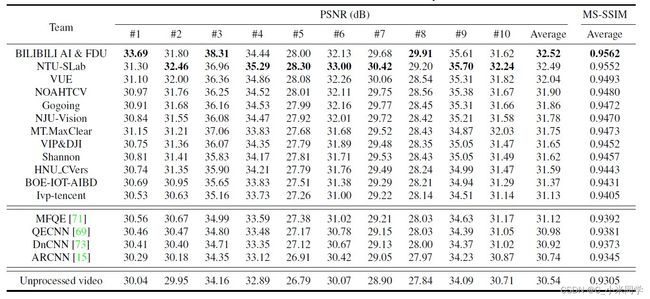
Table 1. The results of Track 1 (fixed QP, fidelity)
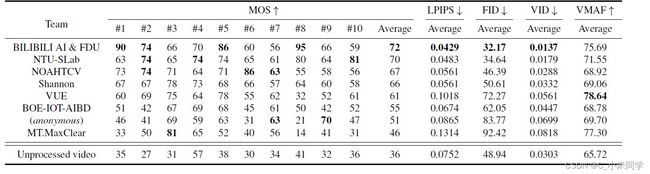
Table 2. The results of Track 2 (fixed QP, perceptual)

Table 3. The results of Track 3 (fixed bit-rate, fidelity)
1.LDV数据集

本文提出的LDV数据集中的视频示例,包含10类场景。左边的四列显示了NTRIE挑战中用于训练的部分视频。中间的两列是验证的视频。右边两列是测试视频,左边一列是Track1和Track 2的测试集,最右边一列是Track 3的测试集。
- LDV数据集包含240个视频,包含10类场景,即动物、城市、特写、时尚、人、室内、公园、风景、运动和车辆。
- 在LDV的240个视频中,快速动作视频48个,高帧率视频68个( 50),低帧率视频172个( 30)。
- 在75个LDV视频中,摄像机会有轻微的抖动(例如,用手持摄像机拍摄),而在LDV中有20个视频是在黑暗的环境中拍摄的,例如,在夜间或在光线不足的房间中。在NTIRE 2021的挑战中,我们将LDV数据集分为训练集、验证集和测试集,分别包含200个、20个和20个视频。
- 测试集进一步分为两组,每组10个视频,分别为固定QP (tracks 1和2)和固定比特率(Track 3)的轨道。
这20个验证视频由10个场景类别的视频组成,每个类别有两个视频。 - 每个测试集有一个来自每个类别的视频。每个测试集的20个验证视频中有9个帧率较高,每个测试集的10个视频中有4个帧率较高。验证集中有5个快动视频。在固定QP和固定比特率轨道的测试集中,分别有3个和2个快动视频。
2.BILIBILI AI & FDU Team

BILIBILI AI & FDU Team
作为初步步骤,他们首先解码比特流提取每帧的QP。
根据QP值,他们选择前4帧和后4帧作为参考帧,因此总共9帧(包括目标帧)被输入模型。
1)将目标帧的时间戳记为t,同时选取相邻的两帧(t-1和t+1);
2)然后将之前的3个峰值质量帧(Peak Quality Frames, PQFs)[71]和随后的3个PQFs作为额外的参考帧。
3)如果没有更多的参考帧,并且在前一部分或后一部分中选择的参考帧数少于4个,则重复填充最后选择的参考帧,直到总共有8个参考帧。他们将9帧(8个参考帧和1个目标帧)输入到时空变形融合(STDF)模块中,以捕获时空信息。然后STDF模块的输出被发送到质量增强(QE)模块。QE模块采用了来自C2CNet[17]的自适应WDSR-A-Block堆栈。
3. NTU-SLab Team
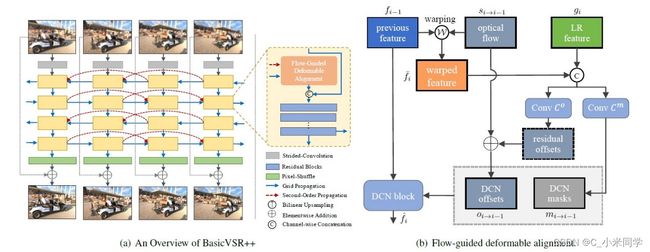
NTU-SLab Team
NTU-SLab团队针对这一挑战提出了BasicVSR++方法。BasicVSR++包含两项经过深思熟虑的修改,以改进BasicVSR的传播和对准设计。如上图所示,给定一个输入视频,首先利用残差块提取每帧的特征。这些特征然后在提出的二阶网格传播方案下传播,其中对齐是由提出的流动引导的可变形对齐执行。传播后,利用聚合的特征进行卷积和像素变换生成输出图像。
4. NOAHTCV Team

NOAHTCV Team
如上图所示,输入图像包括三帧,即当前帧加上前一帧和下一帧PQF (Peak Quality frames,峰值质量帧)。第一步包括一个共享的特征提取与剩余块堆栈,随后使用一个U-Net来联合预测三个输入的每个单独的偏移量。这样的偏移被用来隐式地对齐和融合特征。注意,这一步的监督没有任何损失。在初始特征提取和对齐后,他们使用一个具有共享权值的多头U-Net来处理每个输入特征,在编码器和解码器的每个尺度上,他们将U-Net特征与尺度相关的变形卷积融合,对U-Net的输出特征进行最后一次融合,最后对输出的融合特征进行一堆剩余块的处理,预测最终的输出。这个输出实际上是残留信息,添加到输入帧以产生增强的输出帧。
5. Ivp-tencent Team

Ivp-tencent Team
如上图所示,Ivp-tencent团队提出了一种块移除网络(BRNet)来减少压缩视频中的块伪影,以提高视频质量。受EDSR和FFDNe的启发,提出的BRNet首先使用mean shift模块(mean shift)对输入帧进行归一化,然后采用可逆的下采样操作(Pixel Unshuffle)对帧进行处理,将压缩后的帧分割成四个下采样的子帧。然后,将子帧馈送到如图17所示的卷积网络中,其中使用了8个剩余块。最后,他们使用上采样操作(Pixel Shuffle)和mean shift模块来重建增强的帧。值得注意的是,在所有 提出的方法中,Ivp-tencent的时间效率最高。它能够增强超过120帧每秒,所以它可能适用于高帧率的场景。个人认为,腾讯团队的这个模型非常有价值。