出行大数据项目一
出行大数据一
1、项目概述
-
随着人们对出行的需求日益增加,出行的安全问题,出行的便捷问题等问题日益突出,特别是安全出行是我们每个人都迫切需要的,为了增加出行的编辑,提高出行的安全,对我们乘车的细节以及发生点我们迫切的需要及时知道,为此特地通过大数据的手段来处理我们海量的出行数据。
-
做到:
- 订单的实时监控,
- 乘车轨迹的的细节回放,
- 虚拟车站的科学制定,
- 出行迁途的细节过程,
- 订单报表的大屏展示,
- 用户乘车行为统计
- 用户画像等功能,
实现用户的出行统计,制定用户的的“杀熟”策略等。
2、技术架构选型
数据主要分为两部分:
- 第一部分为日志数据,主要是司机端APP每隔一定时间上报经纬度坐标信息,以日志数据的形式进行打印到日志服务器。
- 第二部分数据为业务库数据,主要是存储在mysql,通过分库的形式将各个不同城市的数据存储在不同的业务库里面。
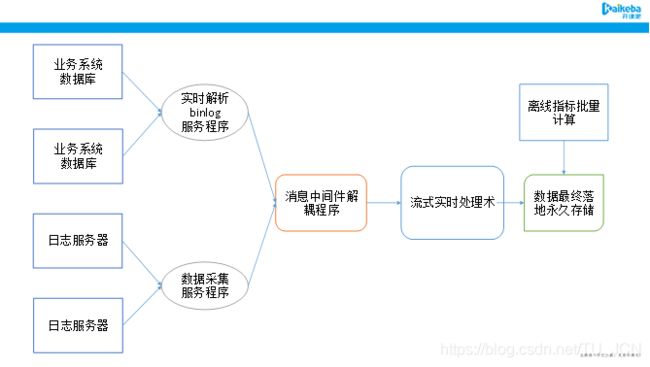
2.1、数据采集功能如何技术选型
数据采集框架很多,包括sqoop, datax, flume, logstash, maxwell, canal等各种数据采集框架适用场景不同,功能描述如以下表格。
| 采集框架名称 | 主要功能 |
|---|---|
| Sqoop | 大数据平台和关系型数据库的导入导出 |
| datax | 大数据平台和关系型数据库的导入导出 |
| flume | 擅长日志数据的采集和解析 |
| logstash | 擅长日志数据的采集和解析 |
| maxwell | 常用作实时解析mysql的binlog数据 |
| canal | 常用作实时解析mysql的binlog数据 |
2.2、消息中间件的技术选型
市面上成熟的消息中间件技术框架也有很多,主要有以下各种消息中间件
| 开源MQ | 概述 |
|---|---|
| 1.RabbitMQ | LShift 用Erlang实现,支持多协议,broker架构,重量级 |
| 2.ZeroMQ | AMQP最初设计者iMatix公司实现,轻量消息内核,无broker设计。C++实现 |
| 3.Jafka/Kafka | LinkedIn用Scala语言实现,支持hadoop数据并行加载 |
| 4.ActiveMQ | Apach的一种JMS具体实现,支持代理和p2p部署。支持多协议。Java实现 |
| 5.Redis | Key-value NoSQL数据库,有MQ的功能 |
| 6.MemcacheQ | 国人利用memcache缓冲队列协议开发的消息队列,C/C++实现 |
2.3、实时流式处理技术选型
流式处理技术已经非常成熟,且各大框架都有提供很多种选择,以下是各种流式处理技术选型技术对比
| 框架名称 | 框架介绍 |
|---|---|
| Storm | Twitter公司开源提供,早期的流失计算框架,基本已经退出大数据的舞台 |
| SparkStreaming | 当下最火热的流失处理技术之一 |
| Flink | 流式计算 |
| Blink 流式计算 | 阿里二次开发的Flink框架 |
2.4、数据永久存储技术框架选型
数据永久存储框架也有很多,比较常见的例如Hbase,kudu,HDFS等
| 框架名称 | 主要用途 |
|---|---|
| HDFS | 分布式文件存储系统 |
| Hbase | Key,value对的nosql数据库 |
| Kudu | Cloudera公司开源提供的类似于Hbase的数据存储 |
2.5、数据离线计算框架技术选型
离线统计的框架也非常多,主要就是基于各种OLAP场景的应用计算
| 框架名称 | 基本介绍 |
|---|---|
| MapReduce | 最早期的分布式文件计算系统 |
| hive | 基于MR的数据仓库工具 |
| impala | 号称当前大数据领域最快的sql on hadoop框架,内存消耗特别大 |
| SparkSQL | 基于spark,一站式解决批流处理问题 |
| FlinkSQL | 基于flink,一站式解决批流处理问题 |
| druid | 针对时间序列数据提供低延迟的数据写入以及快速交互式查询的分布式OLAP数据库 |
| kylin | 基于Hbase实现的预计算 |
| presto | 分布式SQL查询引擎,用于查询分布在一个或多个不同数据源中的大数据集 |
| clickHouse | 俄罗斯开源提供的一个OLAP分析框架 |
3、日志数据格式说明
现在主要用到成都数据以及海口数据,针对成都以及海口数据字段说明如下
成都轨迹数据格式说明:一共5个字段
一共五个字段,字段详情参见下表,字段之间使用逗号隔开。
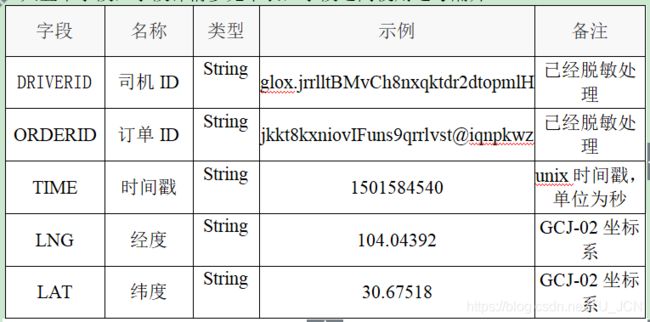
注意:上区域的中所体现的OD数据是相比全城是很小的量,不能反映全城的供需情况
目前得到的轨迹数据中可以看到时间不是按照递增的方式进行排列,在进行数据处理时需要先对数据按照时间进行升序排列(轨迹点的产生的时间是递增的,从时间的角度才能看出轨迹的运行规律),排序后便于在地图上进行轨迹的呈现.
海口订单数据格式说明:一共24个字段
海口订单数据一共24个字段,字段之间使用\t制表符分开,字段详情参见下表
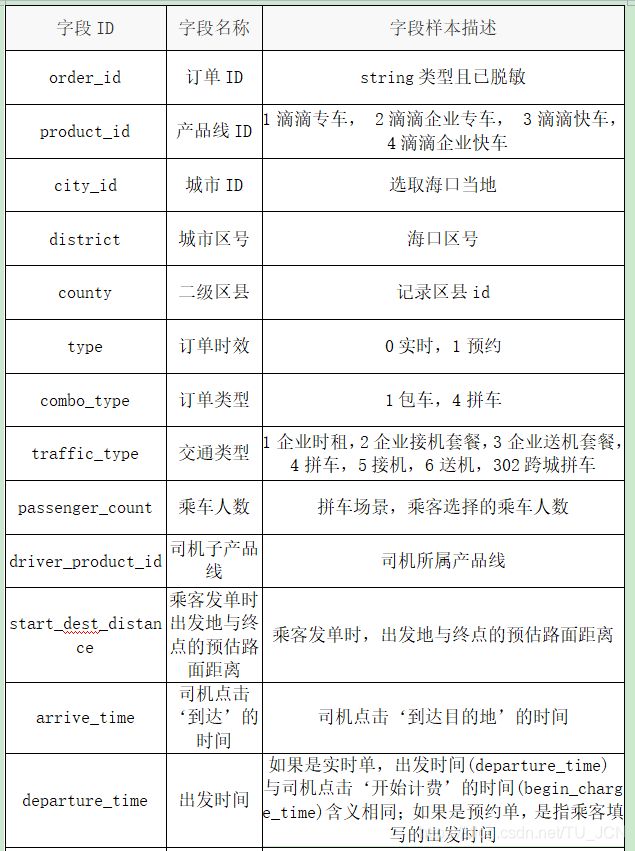
开放城市:海口
开放范围:2017年5月1日 - 2017年10月31日
数据内容:上述时间范围内的海口市每天订单数据,包含订单的起终点经纬度以及订单类型、出行品类、乘车人数的订单属性数据。其中所有涉及个人信息的数据都经过了匿名化处理。
- 保留起终点经纬度小数点后四位,可能导致与真实环境坐标存在偏差,误差范围大概在十几米到几十米左右。
- 针对独门独户上下车点进行技术脱敏处理,将上下车点漂移到小区门口或街道上。
4、项目构建
-
1、 构建父工程travel项目
- 第一步:创建maven父工程travel,
创建maven顶级父工程travel,并导入jar包
- 第一步:创建maven父工程travel,
-
2、构建子模块travel_common模块,用于存放工具类
-
第一步:创建common模块,用于存放工具类
-
第二步:travel_common模块添加maven依赖坐标
在travel_common模块下添加坐标依赖 -
第三步:travel_common模块添加相应工具类
将java以及scala以及config.properties等相应工具类拷贝到travel_common模块当中去 -
第四步:更改config.properties当中的IP地址
将config.properties当中的IP地址全部更改替换成为自己的对应的IP地址
-
-
3、构建travel-web模块
继续构建我们的travel-web模块用于展示我们的web界面- 第一步:在父工程下面添加子模块travel_web
在travel父工程下面构建travel_web子模块 - 第二步:添加pom.xml坐标
- 第三步:拷贝资源文件以及web模块代码
将我们附件当中的资源文件以及web模块的代码拷贝到工程当中来
将我们的静态资源页面拷贝到resources路径下 - 第四步:启动travel_web项目并访问
构建好的travel_web项目主要是用于我们的数据界面展示,我们可以启动web模块,并访问页面
- 第一步:在父工程下面添加子模块travel_web
-
4、构建travel_spark模块
- 构建travel_spark子模块,用于实现首页概览,订单监控,轨迹监控,虚拟车站,用户数据,热力图等功能模块的开发
- 第一步:在父工程travel下面添加子模块travel_spark
- 第二步:添加pom.xml坐标依赖
- 第三步:拷贝资源文件夹以及scala和java辅助代码
- 将我们的辅助代码拷贝到对应的目录下,将对应的java代码,scala代码以及对应的目录下
5、日志数据回放模块
通过回放我们的成都以及海口数据,使用flume采集我们的日志数据,然后将数据放入到kafka当中去,通过sparkStreaming消费我们的kafka当中的数据,然后将数据保存到hbase,并且将海口数据保存到redis当中去,实现实时轨迹监控以及历史轨迹回放的功能

为了模拟数据的实时生成,我们可以通过数据回放程序来实现订单数据的回放功能,主要数据参见课件当中的数据,我们这里主要使用到了成都以及海口的数据来实现数据的回放
第一步:上传数据到服务器
将海口数据上传到node01服务器的/kkb/datas/sourcefile这个路径下
node01执行以下命令创建文件夹,然后上传数据
mkdir -p /kkb/datas/sourcefile
将成都数据上传到node02服务器的/kkb/datas/sorucefile这个路径下
node02执行以下命令创建文件夹,然后上传数据
mkdir -p /kkb/datas/sourcefile
第二步:通过脚本回放数据
使用课件当中的FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar这个jar包来实现数据的读取然后写入到另外一个文件当中去
将FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar 这个jar包上传到node01服务器的/home/hadoop路径下去
在node01服务器的/home/hadoop/bin路径下创建shell脚本,用于数据的回放
cd /home/hadoop/bin
vim start_stop_generate_data.sh
#!/bin/bash
scp /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar node02:/home/hadoop/
#休眠时间控制
sleepTime=1000
if [ ! -n "$2" ];then
echo ""
else
sleepTime=$2
fi
case $1 in
"start" ){
for i in node01 node02
do
echo "-----------$i启动数据回放--------------"
ssh $i "source /etc/profile;nohup java -jar /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar /kkb/datas/sourcefile /kkb/datas/destfile $2 > /dev/null 2>&1 & "
done
};;
"stop"){
for i in node02 node01
do
echo "-----------停止 $i 数据回放-------------"
ssh $i "source /etc/profile; ps -ef | grep FileOperate-1.0-SNAPSHOT-jar | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
给脚本赋予执行权限
cd /home/hadoop/bin
chmod 777 start_stop_generate_data.sh
第三步:通过flume来采集数据
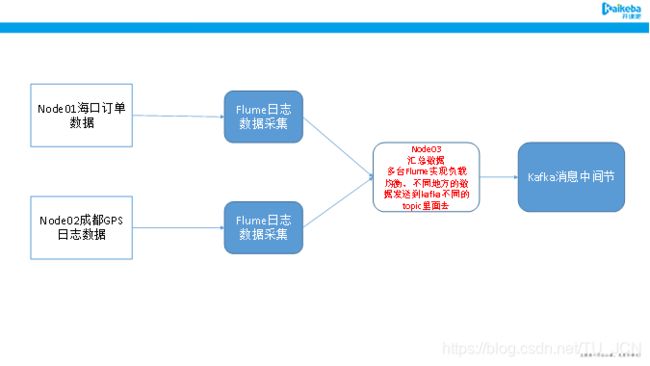
node01开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/haikou.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
#a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
#a1.sinks.k1.topic = hai_kou_gps_topic
#a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
#a1.sinks.k1.batchSize = 20
#a1.sinks.k1.requiredAcks = 1
#a1.sinks.k1.producer.linger.ms = 1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
node02开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/chengdu.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = cheng_du_gps_topic
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
#a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
#a1.sinks.k1.topic = cheng_du_gps_topic
#a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
#a1.sinks.k1.batchSize = 20
#a1.sinks.k1.requiredAcks = 1
#a1.sinks.k1.producer.linger.ms = 1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
node03开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume2kafka.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
#定义sink
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
flume监听的文件数据发送到此kafka的主题当中
a1.sinks.k1.topic = %{type}
a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.producer.linger.ms = 1
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第四步:开发flume启动停止脚本
node01执行以下命令开发flume的启动停止脚本
cd /home/hadoop/bin/
vim flume_start_stop.sh
#!/bin/bash
case $1 in
"start" ){
for i in node03 node02 node01
do
echo "-----------启动 $i 采集flume-------------"
if [ "node03" = $i ];then
ssh $i "source /etc/profile;nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume2kafka.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
else
ssh $i "source /etc/profile;nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume_client.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
fi
done
};;
"stop"){
for i in node03 node02 node01
do
echo "-----------停止 $i 采集flume-------------"
ssh $i "source /etc/profile; ps -ef | grep flume | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
chmod 777 flume_start_stop.sh
第五步:创建kafka的topic
node01执行以下命令创建kafka的topic
cd /kkb/install/kafka_2.11-1.1.0/
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 9 --topic cheng_du_gps_topic
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 9 --topic hai_kou_gps_topic
第六步:启动订单回放脚本以及fume采集脚本
node01执行以下命令启动订单回放脚本
cd /home/hadoop/bin/
sh start_stop_generate_data.sh start 3000
node01启动flume采集数据脚本
cd /home/hadoop/bin/
sh flume_start_stop.sh start
第七步:消费kafka数据,验证数据进入到kafka当中
node01执行以下命令消费kafka当中的数据
cd /kkb/install/kafka_2.11-1.1.0/
bin/kafka-console-consumer.sh --topic cheng_du_gps_topic --zookeeper node01:2181,node02:2181,node03:2181
bin/kafka-console-consumer.sh --topic hai_kou_gps_topic --zookeeper node01:2181,node02:2181,node03:2181
6、轨迹监控模块
轨迹监控模块业务说明:对于正在出行的订单,我们需要将数据保存起来,实时的实现订单轨迹的监控回放。
数据处理过程:
- 通过sparkStreaming实现消费kafka当中的数据,然后将海口以及成都数据全部都保存到Hbase对应的表当中去。
- 将海口数据的GPS位置经纬度信息保存到redis当中去,实现实时轨迹监控以及历史轨迹回放等功能。
- 通过Hbase的海口数据,实现虚拟车站的统计功能。
- 自主维护sparkStreaming消费kafka的offset值。
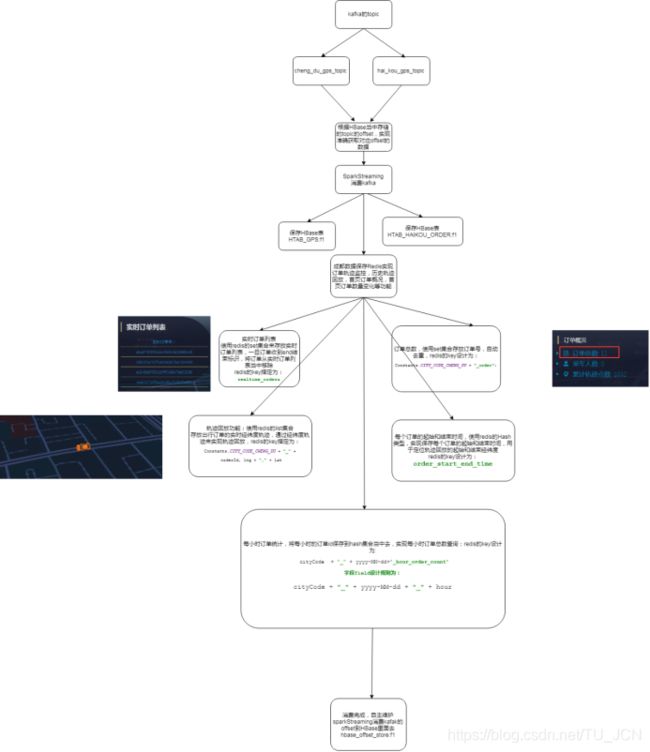
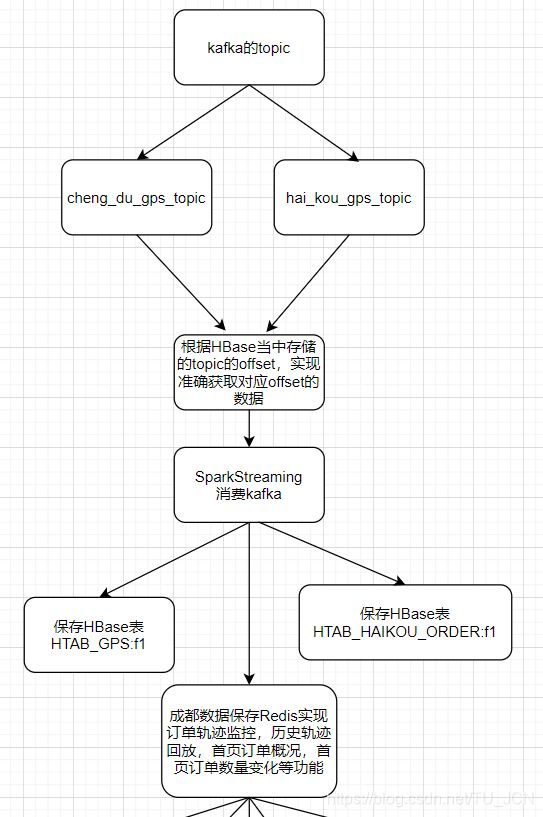
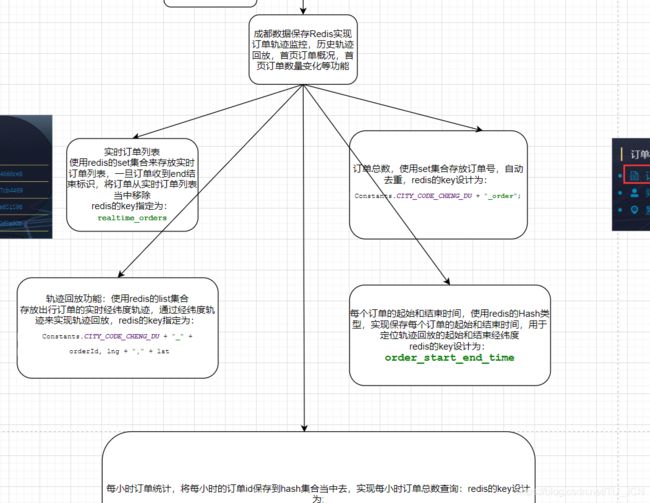
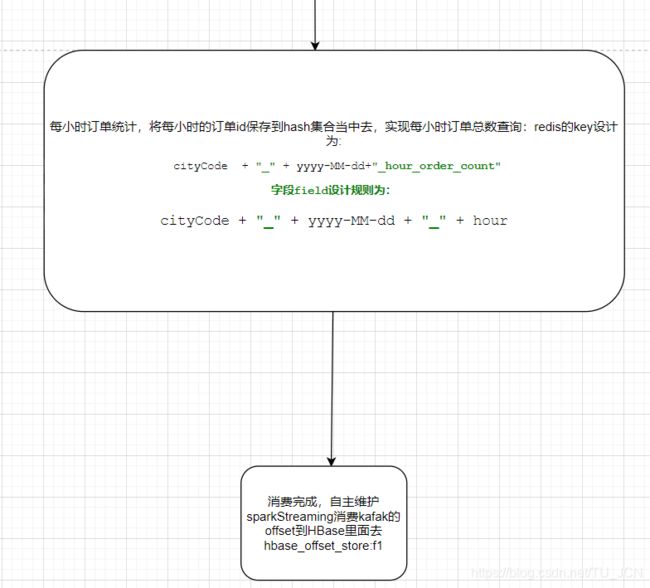
6.1、开发轨迹监控模块
通过sparkStreaming程序消费kafak当中的成都以及海口的数据,并将数据保存到redis和hbase当中去,实现实时轨迹监控模块的功能。
在travel_spark模块的scala下面的com.travel.programApp这个package下面,创建scala的object代码StreamingKafka
import com.travel.common.{ConfigUtil, Constants, HBaseUtil, JedisUtil}
import com.travel.loggings.Logging
import com.travel.utils.HbaseTools
import org.apache.hadoop.hbase.client.{Admin, Connection}
import org.apache.hadoop.hbase.{HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
object StreamingKafka extends Logging{
def main(args: Array[String]): Unit = {
val brokers = ConfigUtil.getConfig(Constants.KAFKA_BOOTSTRAP_SERVERS)
val topics = Array(ConfigUtil.getConfig(Constants.CHENG_DU_GPS_TOPIC),ConfigUtil.getConfig(Constants.HAI_KOU_GPS_TOPIC))
val conf = new SparkConf().setMaster("local[1]").setAppName("sparkKafka")
val group:String = "gps_consum_group"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> group,
"auto.offset.reset" -> "latest",// earliest,latest,和none
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val context: SparkContext = sparkSession.sparkContext
context.setLogLevel("WARN")
// val streamingContext = new StreamingContext(conf,Seconds(5))
//获取streamingContext
val streamingContext: StreamingContext = new StreamingContext(context,Seconds(1))
val result: InputDStream[ConsumerRecord[String, String]] = HbaseTools.getStreamingContextFromHBase(streamingContext,kafkaParams,topics,group,"(.*)gps_topic")
/**
* 将数据保存到HBase当中去,以及将成都的数据,保存到redis里面去
*/
result.foreachRDD(eachRdd =>{
if(!eachRdd.isEmpty()){
eachRdd.foreachPartition(eachPartition =>{
val connection: Connection = HBaseUtil.getConnection
val jedis: Jedis = JedisUtil.getJedis
//判断表是否存在,如果不存在就进行创建
val admin: Admin = connection.getAdmin
if(!admin.tableExists(TableName.valueOf(Constants.HTAB_GPS))){
val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_GPS))
htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY))
admin.createTable(htabgps)
}
if(!admin.tableExists(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER))){
val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER))
htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY))
admin.createTable(htabgps)
}
eachPartition.foreach(record =>{
//保存到HBase和redis
val consumerRecords: ConsumerRecord[String, String] = HbaseTools.saveToHBaseAndRedis(connection,jedis, record)
})
JedisUtil.returnJedis(jedis)
connection.close()
})
//更新offset
val offsetRanges: Array[OffsetRange] = eachRdd.asInstanceOf[HasOffsetRanges].offsetRanges
//result.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) //将offset提交到默认的kafka的topic里面去保存
for(eachrange <- offsetRanges){
val startOffset: Long = eachrange.fromOffset //起始offset
val endOffset: Long = eachrange.untilOffset //结束offset
val topic: String = eachrange.topic
val partition: Int = eachrange.partition
HbaseTools.saveBatchOffset(group,topic,partition+"",endOffset)
}
}
})
streamingContext.start()
streamingContext.awaitTermination()
}
}
6.2、浏览器界面访问轨迹监控模块
以上代码将成都以及海口数据保存到了Hbase当中去,并且将海口数据的经纬度数据保存到了redis当中去,我们就可以通过浏览器web界面访问轨迹回放模块,查看轨迹监控的功能模块。
7、虚拟车站功能模块
先来熟悉两个关于地理单词的用法
- longitude:经度,范围值。经度0°——180°(东行,标注E)0°——180°(西行,标注W)
- latitude:维度 0°——90°N、0°——90°S
通过经纬度可以用来干什么:可以通过经纬度推断出地址,可以通过地址推断出经纬度,而且可以通过经纬度进行电子地图划分。
http://www.gpsspg.com/maps.htm
7.1、虚拟车站实现思路
1.虚拟车站如何实现?
最终要在界面上显示的车站位置重要的信息就是经纬度,而我们拿到的订单数据中包含核心数据(订单ID,起始经纬度)。
2.可以把乘客经常上车的位置作为虚拟车站,比如一个十字路口,上车的人比较多(也就是起点经纬度在十字路口比较集中,比如在十字路口乘车订单数在10个以上,或者20个以上时),那我们就可以在这个十字路口设置一个虚拟车站位置。按照这样的思路是可以实现功能的,但会有个问题是如何统计哪些位置的起点经纬度比较集中并且数量达到一个基数(业务中判定一个地点作为虚拟车站的条件)。
3.对于起点比较集中的位置我们可以把地图划分为无数相等的格子,比如划分成大正方形(长X宽都是10米范围内,并且这个范围内的起点表多,那么我们就可以在这个格子中设置一个虚拟车站,可以取格子中经度和维度最小或者最大的点作为虚拟车站最后在界面上显示),这是geohash的做法
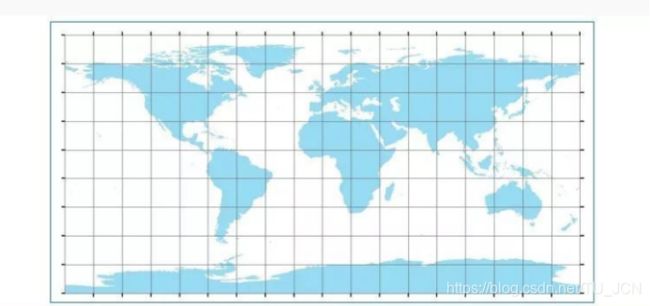
但是geohash一类的矩形算法,有以下两个显著的缺陷:
1、在不同纬度的地区会出现地理单元单位面积差异较大的情况。
2、在常用的地理范围查询中,基于矩形的查询方法,存在8邻域到中心网格的距离不相等的问题。
3.针对以上第二点,我们可以使用uber公司开源的h3算法可以解决我们的业务问题.
uber h3算法介绍
http://www.sohu.com/a/294377304_326074
https://uber.github.io/h3/#/
https://www.jianshu.com/p/e42d903dce38

H3,是一个六边形分层索引网格系统,也是最近几年实现数据聚合的主要趋势,在h3出现之前大部分情况采用的是geohash算法,墨卡托投影,还有一些其他投影技术,比如google s2.地理索引
六边形网格与周围网格的距离有且仅有一个,而四边形存在两类距离,三角形有三类距离:
7.2、如何实现虚拟车站的统计
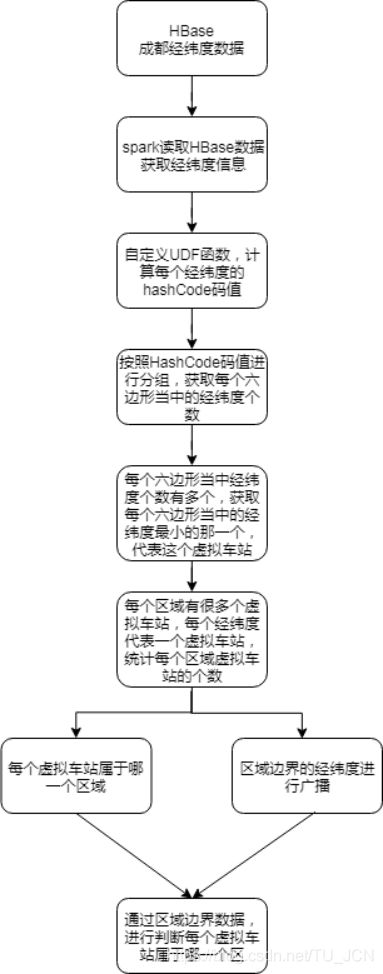
7.3、相关代码
package com.travel.programApp
import com.travel.common.{Constants, District}
import com.travel.utils.{HbaseTools, SparkUtils}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.locationtech.jts.geom.{Point, Polygon}
import org.locationtech.jts.io.WKTReader
import scala.collection.mutable
object SparkSQLVirtualStation {
def main(args: Array[String]): Unit = {
val conf = new SparkConf
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.setMaster("local[1]").setAppName("sparkHbase")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//设置日志级别,避免出现太多日志信息
sparkSession.sparkContext.setLogLevel("WARN")
//hbase配置
val hconf: Configuration = HBaseConfiguration.create()
hconf.set("hbase.zookeeper.quorum", "node01,node02,node03")
hconf.set("hbase.zookeeper.property.clientPort", "2181")
hconf.setInt("hbase.client.operation.timeout", 3000)
val hbaseFrame: DataFrame = HbaseTools.loadHBaseData(sparkSession,hconf)
//将dataFrame注册成为一张表
hbaseFrame.createOrReplaceTempView("order_df")
//获取虚拟车站,每个虚拟车站里面所有的经纬度坐标点只取一个最小的
val virtual_rdd: RDD[Row] = SparkUtils.getVirtualFrame(sparkSession)
//广播每个区域的经纬度边界
val districtsBroadcastVar: Broadcast[java.util.ArrayList[District]] = SparkUtils.broadCastDistrictValue(sparkSession)
//将每个区域的边界转换成为一个多边形,使用Polygon这个对象来表示,返回一个元组(每一个区域封装对象District,多边形Polygon)
//判断每个虚拟车站,是属于哪一个区里面的
val finalSaveRow: RDD[mutable.Buffer[Row]] = virtual_rdd.mapPartitions(eachPartition => {
//使用JTS-Tools来通过多个经纬度,画出多边形
import org.geotools.geometry.jts.JTSFactoryFinder
val geometryFactory = JTSFactoryFinder.getGeometryFactory(null)
var reader = new WKTReader(geometryFactory)
//将哪一个区的,哪一个边界求出来
val wktPolygons: mutable.Buffer[(District, Polygon)] = SparkUtils.changeDistictToPolygon(districtsBroadcastVar, reader)
eachPartition.map(row => {
val lng = row.getAs[String]("starting_lng")
val lat = row.getAs[String]("starting_lat")
val wktPoint = "POINT(" + lng + " " + lat + ")";
val point: Point = reader.read(wktPoint).asInstanceOf[Point];
val rows: mutable.Buffer[Row] = wktPolygons.map(polygon => {
if (polygon._2.contains(point)) {
val fields = row.toSeq.toArray ++ Seq(polygon._1.getName)
Row.fromSeq(fields)
} else {
null
}
}).filter(null != _)
rows
})
})
//将我们的数据压平,然后转换成为DF
val rowRdd: RDD[Row] = finalSaveRow.flatMap(x =>x)
//将数据保存到HBase里面去
HbaseTools.saveOrWriteData(hconf,rowRdd,Constants.VIRTUAL_STATION)
}
}
7.4、运行代码,查看hbase当中出现表
将虚拟车站的数据,都保存到了Hbase的VIRTUAL_STATIONS这个表当中去,然后将该表当中的数据通过phoenix来进行映射,使用javaWeb程序去查询phoenix当中的数据
7.5、使用phoenix映射Hbase当中的表
node02进入phoenix客户端,然后创建Hbase当中的表映射
cd /kkb/install/apache-phoenix-4.14.0-cdh5.14.2-bin/
bin/sqlline.py node01:2181
create view VIRTUAL_STATIONS(
"ROWKEY" varchar primary key ,
"f1"."CITY_ID" varchar,
"f1"."DISTRICT_NAME" varchar,
"f1"."STARTING_LNG" varchar,
"f1"."STARTING_LAT" varchar
) as select * from VIRTUAL_STATIONS;
8、业务数据库功能模块
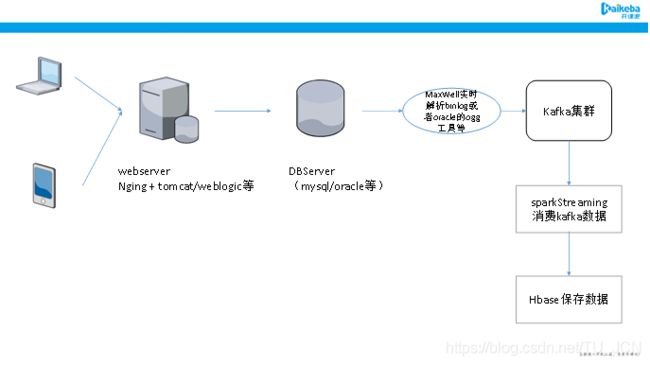
前面我们已经通过flume采集日志数据,包括订单日志数据,以及经纬度上报信息数据。
先,将数据接入到kafka当中去,通过sparStreaming来消费kafka的数据,实现将数据保存到Hbase以及redis当中,实现了数据的实时处理,
然后,对hbase当中的数据,通过spark程序读取,并进行处理,计算我们的虚拟车站结果。
到此为止,已经实现了日志数据的采集和处理等功能模块,
那么,接下来通过业务库实时解析数据,实现订单的实时解析。
8.1、涉及到的业务数据库表介绍
这里我们主要涉及到四张数据库表,分别是司机表,乘客表,订单表以及司管方表,我们的数据分析主要以这四张表为基础,对业务库当中的数据进行脱敏之后对我们的数据进行分析。
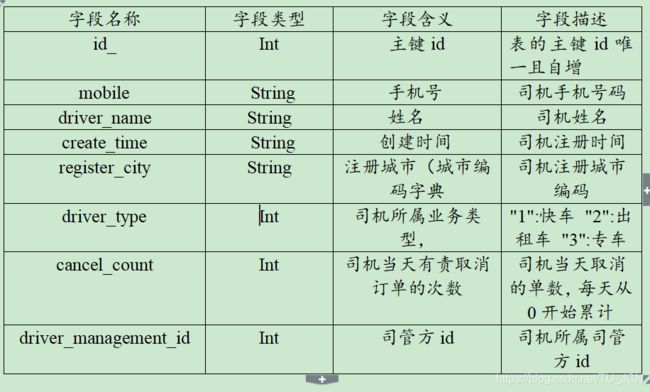
司机表driver_info具体字段以及字段含义见下表
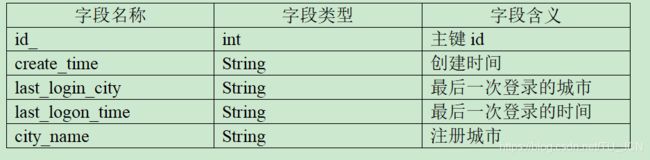
乘客表renter_info具体字段以及字段含义见下表
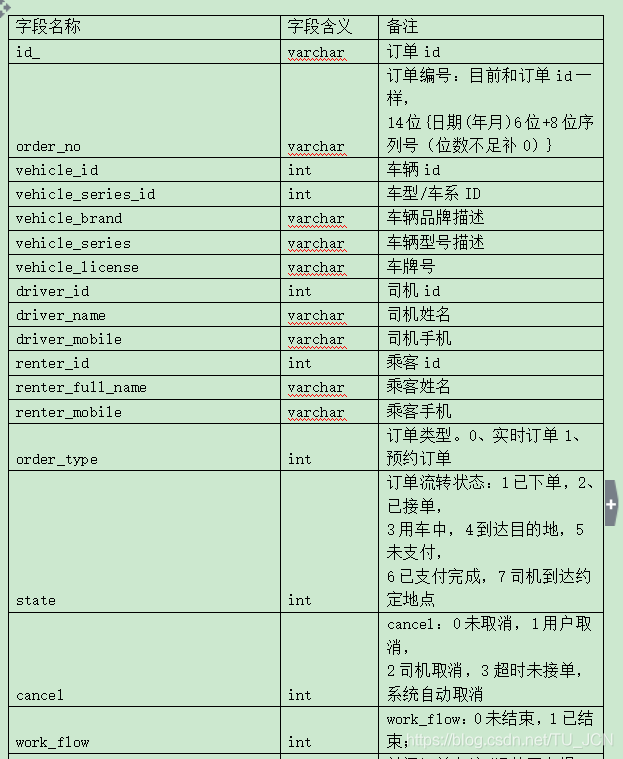
订单表order_info_201907具体字段以及字段含义见下表
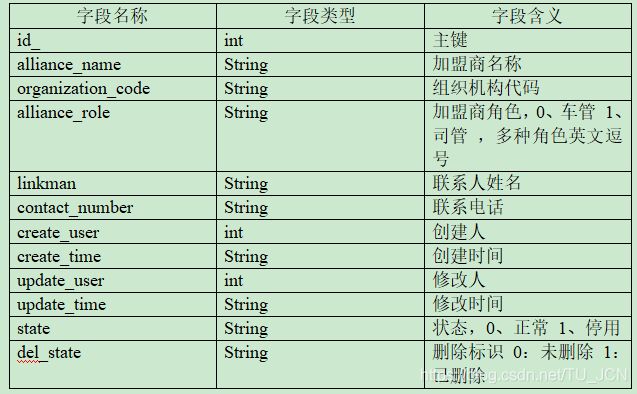
司管方表opt_alliance_business具体字段以及字段含义见下表
8.2、业务库订单数据回放
实现实时binlog进入kafka
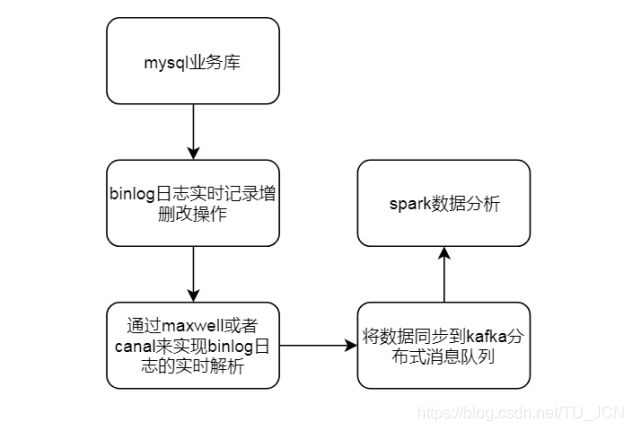
通过模拟订单数据回放,实现我们的订单数据实时解析,参见课件资料当中的业务库数据资料,实现业务库当中的数据回放功能,通过maxwell实现解析binlog,并将binlog数据接入到kafka当中去。
第一步:开发maxwell配置
node03执行以下命令开发maxwell配置文件
cd /kkb/install/maxwell-1.22.1
vim travel.properties
log_level=INFO
producer=kafka
kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
host=node03.kaikeba.com
user=maxwell
password=123456
producer_ack_timeout = 600000
port=3306
######### output format stuff ###############
output_binlog_position=ture
output_server_id=true
output_thread_id=ture
output_commit_info=true
output_row_query=true
output_ddl=false
output_nulls=true
output_xoffset=true
output_schema_id=true
######### output format stuff ###############
kafka_topic= veche
kafka_partition_hash=murmur3
kafka_key_format=hash
kafka.compression.type=snappy
kafka.retries=5
kafka.acks=all
producer_partition_by=primary_key
############ kafka stuff #############
############## misc stuff ###########
bootstrapper=async
############## misc stuff ##########
############## filter ###############
filter=exclude:*.*, include: travel.order_info_201904,include: travel.order_info_201905,include: travel.order_info_201906,include: travel.order_info_201907,include: travel.order_info_201908,include: travel.order_info_201906,include: travel.order_info_201910,include: travel.order_info_201911,include: travel.order_info_201912,include: travel.renter_info,include: travel.driver_info ,include: travel.opt_alliance_business
############## filter ###############
第二步:创建kafka的topic
node01执行以下命令创建kafka的topic
cd /kkb/install/kafka_2.11-1.0.1/
bin/kafka-topics.sh --create --topic veche --partitions 3 --replication-factor 1 --zookeeper node01:2181,node02:2181,node03:2181
第三步:将数据上传到mysql所在机器
由于我的mysql安装在node03服务器,所以我将数据资料上传到node03服务器的/kkb/datas/dbdatas 这个路径下(mysql安装在哪一台,就将数据上传到哪一台服务器的/kkb/datas/dbdatas这个路径下)
mkdir -p /kkb/datas/dbdatas
第四步:开发maxwell以及数据回放脚本
在mysql所在的集群的/home/hadoop/bin路径下创建数据回放脚本,由于我的mysql安装在node03服务器,所以我这个脚本也在node03服务器上面执行
mkdir -p /home/hadoop/bin/
cd /home/hadoop/bin/
vim maxOrder.sh
#!/bin/bash
case $1 in
"start" ){
nohup /kkb/install/maxwell-1.21.1/bin/maxwell --daemon --config /kkb/install/maxwell-1.21.1/travel.properties 2>&1 >> /kkb/install/maxwell-1.21.1/maxwell.log &
echo $#
/usr/bin/mysql -h$2 -u$3 -p$4 < /kkb/datas/dbdatas/createdb.sql
if [ $# -lt 6 ];
then
echo "请分别传入启动还是停止,mysql连接主机名,mysql连接用户名,mysql连接密码,数据路径,插入数据休眠时间(毫秒值)"
exit
fi
source /etc/profile
nohup java -jar /kkb/datas/dbdatas/db.jar $2 $3 $4 $5 $6 >/dev/null 2>&1 &
};;
"stop"){
ps -ef | grep Maxwell | grep -v grep |awk '{print $2}' | xargs kill
ps -ef | grep db.jar | grep -v grep |awk '{print $2}' | xargs kill
};;
esac
第五步:启动数据回放脚本以及kafka消费端,确认数据进入kafka
node03执行以下命令启动数据回放脚本
cd /home/hadoop/bin/
sh maxOrder.sh start localhost root 123456 /kkb/datas/dbdatas 3000
如果需要停止maxwell以及数据插入,执行以下命令即可
cd /home/hadoop/bin/
sh maxOrder.sh stop
node01执行以下命令启动kafka的消费者
cd /kkb/install/kafka_2.11-1.0.1
bin/kafka-console-consumer.sh --topic veche --zookeeper node01:2181
8.3、提前创建Hbase表
通过解析kafka当中的binlog数据,将所有的表数据保存到对应的Hbase表当中去,我们需要考虑到Hbase表的预分区的操作,提前创建hbase的对应的表,并考虑我们的rowkey的设计,实现数据的均匀的分区,避免Hbase数据的倾斜。
在travel_spark模块下src/main/java路径下,创建java文件CreateHbaseTableInit.java来实现Hbase表的提前创建
package com.travel.hbase;
import com.travel.common.Constants;
import com.travel.utils.HbaseTools;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class CreateHbaseTableInit {
public static void main(String[] args) throws Exception {
Connection hbaseConn = HbaseTools.getHbaseConn();
CreateHbaseTableInit createHbaseTableInit = new CreateHbaseTableInit();
/**
* syn.table.order_info="order_info"
* syn.table.renter_info="renter_info"
* syn.table.driver_info="driver_info"
* syn.table.opt_alliance_business="opt_alliance_business"
*/
String[] tableNames = new String[]{"order_info","renter_info","driver_info","opt_alliance_business"};
for (String tableName : tableNames) {
createHbaseTableInit.createTable(hbaseConn,Constants.DEFAULT_REGION_NUM,tableName);
}
hbaseConn.close();
}
public void createTable(Connection connection,int regionNum,String tableName) throws IOException {
Admin admin = connection.getAdmin();
if(admin.tableExists(TableName.valueOf(tableName))){
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
}
/* //HBase自带的分区工具类,自动帮我们进行分区
//获取到的是16进制的字符串
RegionSplitter.HexStringSplit spliter = new RegionSplitter.HexStringSplit();
byte[][] split = spliter.split(8);
//适合rowkey经过hash或者md5之后的字符串
RegionSplitter.UniformSplit uniformSplit = new RegionSplitter.UniformSplit();
byte[][] split1 = uniformSplit.split(8);*/
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(Constants.DEFAULT_DB_FAMILY);
hTableDescriptor.addFamily(hColumnDescriptor);
byte[][] splitKey = getSplitKey(regionNum);
admin.createTable(hTableDescriptor,splitKey);
admin.close();
}
public byte[][] getSplitKey(int regionNum){
byte[][] byteNum = new byte[regionNum][];
for(int i =0;i<regionNum;i++){
String leftPad = StringUtils.leftPad(i+"",4,"0");
byteNum[i] = Bytes.toBytes(leftPad + "|");
}
return byteNum;
}
}
8.4、通过sparkStreaming来解析kafka数据进入hbase
通过maxwell来解析mysql的binlog日志,实现了实时捕获mysql数据库当中的数据到kafka当中,然后我们就可以通过sparkStreaming程序来实现
在travel_spark模块下的src/main/scala路径下,创建package
com.travel.programApp,然后在这个package下面创建scala的object文件StreamingMaxwellKafka.
用于实现解析kafka当中的json格式的数据,保存到Hbase当中去。
import com.travel.common.{ConfigUtil, Constants}
import com.travel.utils.{HbaseTools, JsonParse}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Try
object StreamingMaxwellKafka {
def main(args: Array[String]): Unit = {
val brokers = ConfigUtil.getConfig(Constants.KAFKA_BOOTSTRAP_SERVERS)
val topics = Array(Constants.VECHE)
val conf = new SparkConf().setMaster("local[4]").setAppName("sparkMaxwell")
val group_id:String = "vech_group"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> group_id,
"auto.offset.reset" -> "earliest",// earliest,latest,和none
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val context: SparkContext = sparkSession.sparkContext
context.setLogLevel("WARN")
// val streamingContext = new StreamingContext(conf,Seconds(5))
//获取streamingContext
val ssc: StreamingContext = new StreamingContext(context,Seconds(1))
val getDataFromKafka: InputDStream[ConsumerRecord[String, String]] = HbaseTools.getStreamingContextFromHBase(ssc,kafkaParams,topics,group_id,"veche")
getDataFromKafka.foreachRDD(eachRdd =>{
if(!eachRdd.isEmpty()){
val catchResult = Try{
eachRdd.foreachPartition(eachPartition =>{
//每个分区获取一次连接
val conn = HbaseTools.getHbaseConn
eachPartition.foreach(eachLine =>{
//获取到每条数据
val jsonStr: String = eachLine.value()
//(表名称 , bean)
val parse: (String, Any) = JsonParse.parse(jsonStr)
HbaseTools.saveBusinessDatas(parse._1,parse,conn)
})
HbaseTools.closeConn(conn)
})
}
//每个分区更新数据
/* eachRdd.foreachPartition(eachPartition =>{
val list: List[ConsumerRecord[String, String]] = eachPartition.toList
val finalResult: ConsumerRecord[String, String] = list(list.size - 1)
val endOffset: Long = finalResult.offset() //结束offset
val topic: String = finalResult.topic
val partition: Int = finalResult.partition
HbaseTools.saveBatchOffset(group_id,topic,partition+"",endOffset)
})*/
//更新offset
val offsetRanges: Array[OffsetRange] = eachRdd.asInstanceOf[HasOffsetRanges].offsetRanges
getDataFromKafka.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) //将offset提交到默认的kafka的topic里面去保存
for(eachrange <- offsetRanges){
val startOffset: Long = eachrange.fromOffset //起始offset
val endOffset: Long = eachrange.untilOffset //结束offset
val topic: String = eachrange.topic
val partition: Int = eachrange.partition
HbaseTools.saveBatchOffset(group_id,topic,partition+"",endOffset)
}
}
})
ssc.start()
ssc.awaitTermination()
}
}